GIS境界データを使って分析(2. データ加工と地図表示:COLAB)
前回は政府当家窓口であるE-STATから日本の自治体の特定地域の境界データをとってくる例をお見せしました。
ここではとってきたデータの中身の確認と加工、地図表示をCOLABをつかってPYTHON環境で実施したいと思います。もっと高度なことをやる場合はCOLBA以外にもQGISなどのオープン無料で使えるツールを使う方法もありますし、頻繁に使うのであればそちらをお勧めします。
将来的に柔軟に自動化をする可能性を考えてあえてPYTHONで実験はしてます。(ただ本当に自動化できるか不明なため、本格的に環境構築まではしたくなかったおでCOLABを使って実施しました)
コラボのノートは以下に置いてあります。
コラボにあるセルをそのままですが、簡単な説明とともに紹介します。
まずは、とってきたSHAPEファイルをGDRIVEのどこかにアップロードします。
COLAB上でアップも可能ですが、この場合は毎回アップロードが必要になります。
[KANZAKI_DATA.ipynb]
まず必要かもしれないパッケージインストール
!pip install geopandas fiona pyproj rtree
!pip install mapclassify
そして必要なライブラリのインポート
from google.colab import drive
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
from google.colab import files
import folium
そして前回とってきた3つの市のSHAPEファイルセットをアップロードしましたので、そこにパスを指定します。
drive.mount('/content/drive')
#自分の環境に合わせて設定
shp_path1 = '/content/drive/My Drive/HYOGO/B002005212020DDSWC28442/r2kb28442.shp'
shp_path2 = '/content/drive/My Drive/HYOGO/B002005212020DDSWC28443/r2kb28443.shp'
shp_path3 = '/content/drive/My Drive/HYOGO/B002005212020DDSWC28446/r2kb28446.shp'
GISデータには地理座標系というものがありこれを意識する必要があります(でないと位置がずれることが起きます)私は、通常GPSでもつかわれる緯度経度の座標系に統一します。
# 読み込み
gdf1 = gpd.read_file(shp_path1)
gdf2 = gpd.read_file(shp_path2)
gdf3 = gpd.read_file(shp_path3)
# 各ファイルのCRSを確認
print("gdf1 CRS:", gdf1.crs)
print("gdf2 CRS:", gdf2.crs)
print("gdf3 CRS:", gdf3.crs)
# WGS84(経緯度)に変換(EPSG:4326)
gdf1 = gdf1.to_crs(epsg=4326)
gdf2 = gdf2.to_crs(epsg=4326)
gdf3 = gdf3.to_crs(epsg=4326)
# 確認
print("変換後 gdf1 CRS:", gdf1.crs)
print("変換後 gdf2 CRS:", gdf2.crs)
print("変換後 gdf3 CRS:", gdf3.crs)
出力
gdf1 CRS: EPSG:4612
gdf2 CRS: EPSG:4612
gdf3 CRS: EPSG:4612
変換後 gdf1 CRS: EPSG:4326
変換後 gdf2 CRS: EPSG:4326
変換後 gdf3 CRS: EPSG:4326
そして3つのSHAPEファイルを統合します。1行でさくっとできます。中身も確認します。
# 属性+ジオメトリを結合
gdf = pd.concat([gdf1, gdf2, gdf3], ignore_index=True)
print(f"結合後の行数: {len(gdf)}") # → 合計行数
gdf.head()
いろいろ属性がでますが、最後の列にあるgeometryが実際の位置を定義した1つ以上のPOLYGONからなったGEOMETRYの集合になります。
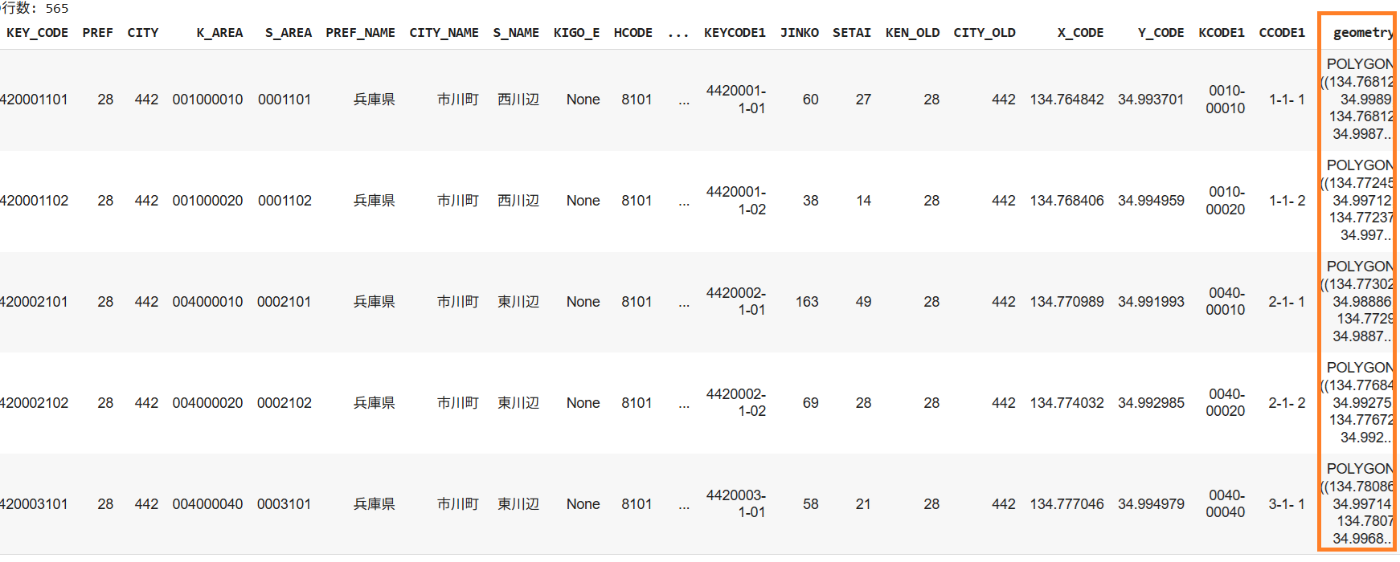
GEOMETRYだとわかりにくいのと大変なので実際にどのような形か3つの種類の表示を試します
geopandas.explore (ベースはfolium と mapclassify)
先ほど確認した項目の中で町名と場所をポップアップさせます
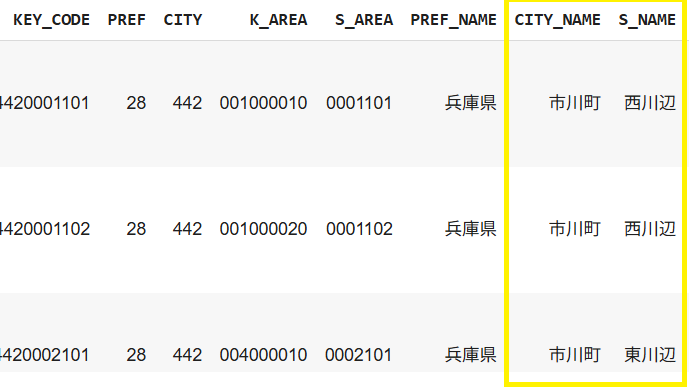
# KEY_CODE カラムをツールチップで表示
m = gdf.explore(
tooltip=["CITY_NAME", "S_NAME"], # リストで複数指定
popup=["CITY_NAME", "S_NAME"], # クリック時のポップアップも同様に
tiles="CartoDB positron",
zoom_start=10
)
# Jupyter/Colab 上で地図を表示
m
地図は以下のような表示になります。

MATPLOTLIB
単純にMATPLOTLIBで表示させることもできます。
fig, ax = plt.subplots(figsize=(8, 8))
gdf.plot(ax=ax, edgecolor='black', facecolor='none')
ax.set_title('GDF Kanzaki')
plt.show()
図は地味ですが緯度経度の場所がより分かりやすく表示されてます。

FOLIUM
ベースにOSMマップをいれつつ、地名をいれます。ただし地名は重なり合って、かなり醜いです。
デフォルトではZOOM値で表示非表示かコントロールできないようですが、JAVASCRIPTを埋め込めばできるかもしれません。
# Base map
m = folium.Map(location=[34.8, 134.7], zoom_start=12, control_scale=True)
for _, row in gdf.iterrows():
# Polygons
folium.GeoJson(
row.geometry.__geo_interface__,
style_function=lambda feat: {
'fillColor': 'lightgray',
'color': 'black',
'weight': 1,
'fillOpacity': 0.5
}
).add_to(m)
# Labels
centroid = row.geometry.centroid
folium.map.Marker(
[centroid.y, centroid.x],
icon=folium.DivIcon(html=f"""<div style="font-size:10px; font-weight:bold">{row['S_NAME']}</div>""")
).add_to(m)
m
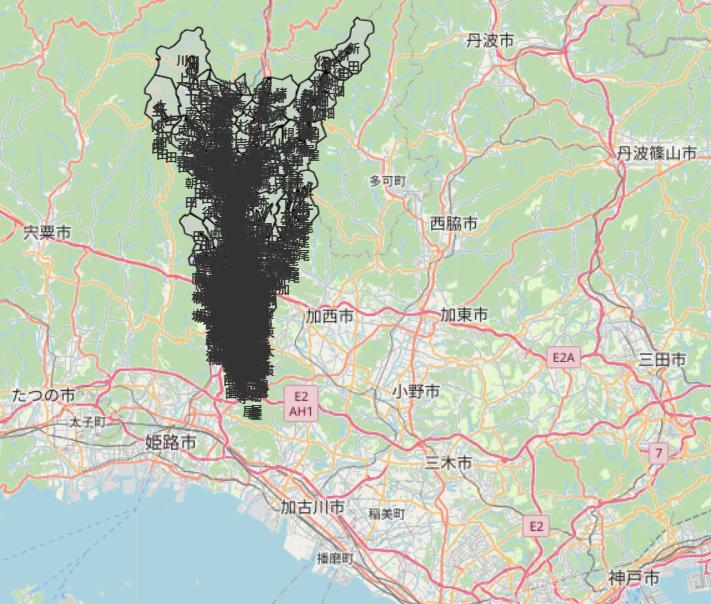
ZOOMが小さいとき
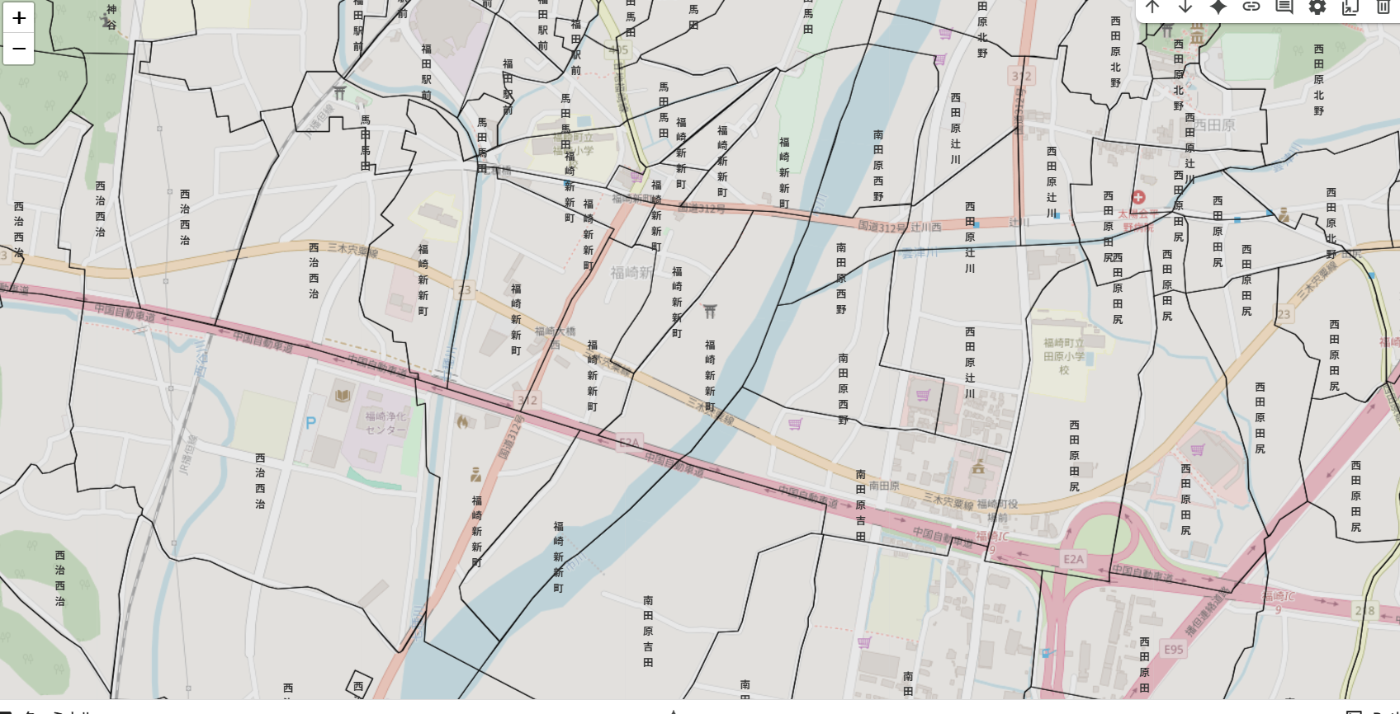
ZOOMを大きくした場合
最後にこれらのデータをダウンロードします。
# CSV に出力(ヘッダー付き、行番号は不要)
gdf.to_csv('kanzaki.csv', index=False, encoding='utf-8-sig')
files.download('kanzaki.csv')
# geometry 列は WKT(文字列)に変換
df = gdf.copy()
df['geometry'] = df['geometry'].apply(lambda geom: geom.wkt)
# Excel に書き出し(UTF-8 対応の engine=openpyxl)
excel_path = 'kanzaki.xlsx'
df.to_excel(excel_path, index=False, engine='openpyxl')
# ダウンロード
files.download(excel_path)
(POSTGRESQLやMYSQLなどある程度幾何データに対応したデータベースで高度な集計ができるそうなので、次回もし余裕があれば試したいと思います。)
SELECT 県,市,SUM(人口) as 市総人口,ST_Union(geom) AS 市の境界
FROM my_table GROUP BY 県, 市;
みたいなSQLで細かい境界を町、市や県といった単位で結合したり、
またST_AreaなどでPOLYGONから面積をもとめて自動で人口密度を県、市、町単位でSQLだけデータを読めるようです。(まだ速度的な性能は未知数でPYTHONから生データ読んで加工したほうが性能面でははやいかもしれません。)
Discussion