MotionProで画像からアニメーション作った: 5.学習実行
前回は推論を最終的に一応クライアントサーバー型で実装するところまでまとめました。
HTML5+Javascriptで画像アップ、MotionProモデルの入力シャープに合わせてリサイズ、そしてマスクと軌跡を描いてダウンロードもできるし、直接APIサーバーに投げる機能をもたせました。
同時にバックではシンプルにFALSKでAPIを設定して、APACHEのPROXY機能をつかってHTTPS通信で一応この論文の実装をサービスできるようにしました。(WEBデザイン、コードの効率化、リファクタリング、JOBのQUEUEでのコントロールなど実運用となるともっと改善しなければいけないことは多数ありますが💦)
今回はサンプル学習データをダウンロードして学習コードを実行してみます。
私のGPUリソースに限界があるため本当に学習させるのは厳しいですが(1か月流し続ければもしかして....)学習データの構造と学習の手順、小さいGPUで実行するためおCONFIG YAMLの調整などを解説します。
もしまだインストールしてなければ以下のライブラリをインストールしておきます。
(motionpro)$ pip install huggingface_hub
**data_download.py
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="HiDream-ai/MotionPro",
local_dir="data", # 保存先ローカルフォルダ
local_dir_use_symlinks=False, # シンボリックリンクを使わず実ファイルで取得
allow_patterns=["data/*"], # data フォルダ内の全ファイルを対象
)
(motionpro)$ python data_download.py
するとサンプル学習データおよび学習データ作成ツール(これに関しては次回説明)がダウンロードされます。
(motionpro) root@ip-172-31-6-72:/opt/python3.10.16/MotionPro/data# tree -L 2
.
├── MC-Bench
│ ├── Fine_grained_control
│ └── object_control
├── MC-Bench.tar
├── dot_single_video
│ ├── checkpoints
│ ├── configs
│ ├── dot
│ ├── precess_dataset_with_dot_single_video_return_position.py
│ ├── process_dataset_with_dot_single_video_wo_vis_return_flow.py
│ ├── run_dot_single_video.sh
│ └── utils.py
├── folders
│ ├── 007401_007450_1018898026
│ ├── 046001_046050_1011035429
│ └── 188701_188750_1026109505
└── tars
└── p003_n000.tar
13 directories, 6 files
(motionpro) root@ip-172-31-6-72:/opt/python3.10.16/MotionPro/data# cd ..
(motionpro) root@ip-172-31-6-72:/opt/python3.10.16/MotionPro# tree -L 2 data
data
├── MC-Bench
│ ├── Fine_grained_control
│ └── object_control
├── MC-Bench.tar
├── dot_single_video
│ ├── checkpoints
│ ├── configs
│ ├── dot
│ ├── precess_dataset_with_dot_single_video_return_position.py
│ ├── process_dataset_with_dot_single_video_wo_vis_return_flow.py
│ ├── run_dot_single_video.sh
│ └── utils.py
├── folders
│ ├── 007401_007450_1018898026
│ ├── 046001_046050_1011035429
│ └── 188701_188750_1026109505
└── tars
└── p003_n000.tar
data/folders/007401_007450_1018898026
の中身ですが以下のように1つのvideo, 15のjpg, 15のnpyがあります。

これはvideo.mp4が元動画でそこから15のマスク画像とその軌跡データのセットになります。
次回説明しますが、この
** video.mp4の最初のフレーム画像と
** 15のDOTで作った光流 flow_*.npy(フレーム間の動き)
** DOTで作った光流と対になるマスク画像
でvideo.mp4を残りのフレームを再現するように学習します。
それではこれらを使って学習を実施します。
オリジナルのスクリプトですと一部不具合がありますので、若干修正をかけます。
また環境や目的に応じてconfigs/train_debug_from_folder.yaml
のbatch_sizeやmax_epochを調整ください。
この中で
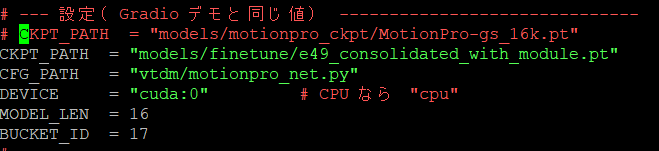
model:->params の
ckpt_path: models/motionpro_ckpt/MotionPro-gs_16k.pt
がベースとなる重みを指してます。これに対してFINETUNINGを実施することを意味します
また
trained_param_keys: [flow_blocks, flow_cond_, flow_gamma_, flow_beta_, lora]
はUNet の flow 系ブロック+LoRA など限られた部分のみを学習対象にする指定しています。
さらにconditioner_config:->params:->emb_models:で
is_trainable: False
なってますが、各エンコーダ類(OpenCLIP など)はこれで凍結させベースの表現は活かしつつ制御・順応部分だけ更新するようにしてます。
あと、train_ddp_spawn.pyの394行目の以下の部分をコメントしておきます。

これで学習する準備はできましたので学習を実行します。
(motionpro)$ python train_ddp_spawn.py \
--base configs/train_debug_from_folder.yaml \
--train True \
--logdir all_results/train \
--scale_lr False
configs/train_debug_from_folder.yamlのbatch_sizeやmax_epochを調整ください。にもよりますが、デフォルト(batch_size=1, max_epoch=50)で24GB VRAM環境でだいたい30分でおわりました。試したいだけであれば、max_epachをもっと小さいあたいでもいいかもしれません。
私はデフォルト設定で 50 epochs回しましたが残念ながらあまりlossが減ってない気がします。
まあ、この程度の学習データ量で50 Epach程度でファインチューニングしても意味がないんだろうということでしょう。
[09/07 00:48:18 VTDM]: Epoch: 0, batch_num: 3
############################## Sampling setting ##############################
Sampler: EulerEDMSampler
Discretization: EDMDiscretization
Guider: LinearPredictionGuider
Sampling with EulerEDMSampler for 26 steps: 96%|█████████▌| 25/26 [00:33<00:01, 1.33s/it]
[09/07 00:49:02 VTDM]: [Epoch 0] [Batch 1/3 44.33 s/batch] [0.0 h/epoch] => loss: 0.342552
[09/07 00:49:06 VTDM]: [Epoch 0] [Batch 2/3 23.89 s/batch] [0.0 h/epoch] => loss: 0.205881
[09/07 00:49:09 VTDM]: [Epoch 0] [Batch 3/3 17.07 s/batch] [0.0 h/epoch] => loss: 0.119500
###中略
[09/07 02:01:10 VTDM]: Epoch: 49, batch_num: 3
############################## Sampling setting ##############################
Sampler: EulerEDMSampler
Discretization: EDMDiscretization
Guider: LinearPredictionGuider
Sampling with EulerEDMSampler for 26 steps: 96%|█████████▌| 25/26 [00:34<00:01, 1.38s/it]
[09/07 02:01:55 VTDM]: [Epoch 49] [Batch 1/3 44.73 s/batch] [0.0 h/epoch] => loss: 0.106723
[09/07 02:01:58 VTDM]: [Epoch 49] [Batch 2/3 23.94 s/batch] [0.0 h/epoch] => loss: 0.178157
[09/07 02:02:01 VTDM]: [Epoch 49] [Batch 3/3 17.10 s/batch] [0.0 h/epoch] => loss: 0.126265
結果はコマンドで指定したlogdir all_results/trainにタイムスタンプフォルダーで生成されます。
ここではDeep Speed 2 設定です。

そのため
checkpoints/epoch=.ckpt がディレクトリ(分割保存)になっていて、その中に
global_step/mp_rank_00_model_states.pt (分割された重み)
zero_to_fp32.py (分割→単一FP32にまとめるスクリプト)
ができあがります。これを推論や、さらにこれをベースに学習させるには1つにまとめる必要があります。親DIRECTORYに保存するフォルダーを作成してそこに統合したものを保存します。
(motionpro)$ mkdir -p ../e49_fp32
(motionpro)$ python zero_to_fp32.py . ../e49_fp32
すると、pytorch_model.bin がe49_fp32に作成されます。
さらにDRAGの形式に合わせるため以下のコマンドを実行します
(motionpro)$ python - <<'PY'
import torch, os, glob
out_dir = os.path.abspath('../e49_fp32')
bins = sorted(glob.glob(os.path.join(out_dir, 'pytorch_model*.bin')))
state = {}
for b in bins:
sd = torch.load(b, map_location='cpu')
state.update(sd)
dst = os.path.join(out_dir, 'e49_consolidated_with_module.pt')
torch.save({'module': state}, dst)
print('OK ->', dst, '| params:', len(state))
PY
するとe49_consolidated_with_module.ptが作成されました。
動作確認をしておきます。
(motionpro)$ python - <<'PY'
import torch
sd = torch.load('../e49_fp32/e49_consolidated_with_module.pt', map_location='cpu')
print(sd.keys()) # dict_keys(['module']) が出ればOK
print(len(sd['module'])) # パラメータ数の目安
PY
一応推論でもともとダウンロードした重みと入れ替えて推論で動作確認します。
e49_consolidated_with_module.ptをmodelsのフォルダーにもってきて、置き換えて推論を実行。
**mp_client.py
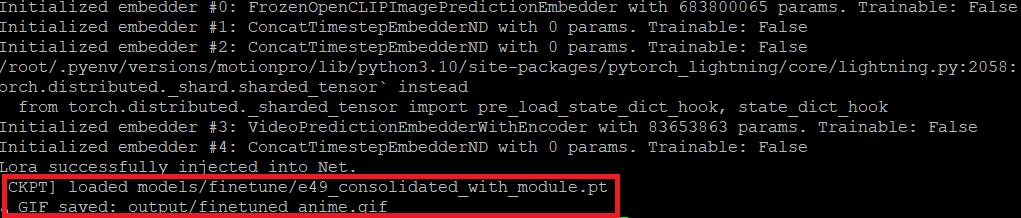
(motionpro)$ python mp_cli.py --img input/2509030157294498_image.png --mask input/2509030157294498_mask.png --traj input/2509030157294498_track.json --out output --gifname finetuned_anime.gif
出力の最後のスクショですが、学習(FINETUNING)したモデルを使って同じようにアニメが作られたことが確認できます。
奇抜な動画を作りたければ学習は必要かもしれません。(たとえば顔が時計周りに回るお化けなど、現在だとどうしても顔は回転ではなく水平移動になりますし風車は回転します。つまり学習された動画に引っ張られているようです)。
次回は学習データの作成と、構造を少し見てみようと思います。
Discussion