いままで体験した中で最高精度!すごいボイスクローン: INDEX-TTS
いままでCoqui-TTSとかOpen Voice とかいろいろやってきて声の特徴を移す実験やってきましたが、なかなか精度とパフォーマンスで使えそうなものがなかったですが、たまたまHUGGINGFACEチェックしていたらすごいの発見です!(最初は半信半疑)
2025年05月04日現在GITを見る限り現在も開発更新進行中のようです。
その名はINDEX-TTS、中国のAI会社がつくったみたですね。いろいろあっても中国のAI技術者は本当にすごいと改めて思えた瞬間でした。
上海が本社ですが東京にも支社があるみたいです!
ライセンスもAPACHEなんで多分商用利用もOK?
ただし残念ながら現在は英語と中国語しかサポートしてません。ライセンス的に問題なければこれを利用して日本語用のモデルを作るのに挑戦したいですね!
論文は以下にありますので技術的なことはここに書いてます。GANも使っているよう。
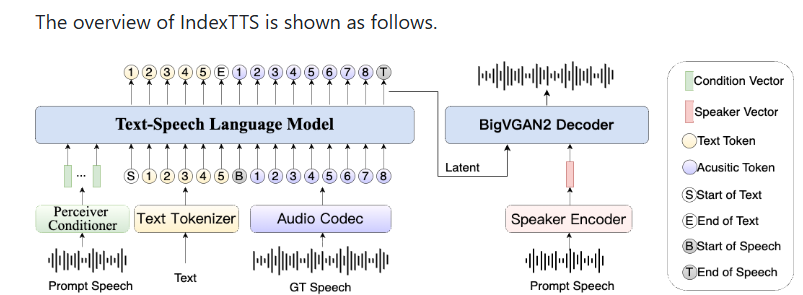
ここでは単純にインストール方法と、それをSTREAMLITででもしたもの作ったのでそれを、自分の実験でフランクリンルーズベルトというアメリカの大統領の声と画像を使いました。
(ドナルドトランプのほうがインパクトは強くて面白そうでしたが著作権の関係でそのままやるとまずそうなので、死後かなりたったフランクリンルーズベルトの画像と声の特徴からLIPSYNCしたデモしました)
このINDEX-TTSは以下の特徴があり、ただすごいです。
- 精度が高い
- でも軽い(しゃべる長さによりますが、16VRAMで十分10+秒程度で推論結果が出ます!)
- インストールがとてもシンプル
まあ、私のブログなんかみずに本家のやつみれば済むことですが、一応、環境設定したので書いておきます。ちなみに推奨されていたPYTHON3.10ではなくPYTHON3.11で実施しました。いずれPYTHON3.12でも一応確認して追記したいと思います。本家ではCONDAのようですが、私はパッケージをすべてPIPに統一したのでPYENVでやってます。
cd /opt/python3.11.1
pyenv virtualenv 3.11.11 index-tts
pyenv activate index-tts
#PYTORCH インストール
python -m pip install --upgrade pip
pip install torch torchvision torchaudio
展開したい場所に移動して、GIT CLONE
git clone https://github.com/index-tts/index-tts.git
cd index-tts
pip install -r requirements.txt
pip install deepspeed
CHECKPOINでモデルのダウンロード
huggingface-cli download IndexTeam/Index-TTS \
bigvgan_discriminator.pth bigvgan_generator.pth bpe.model dvae.pth gpt.pth unigram_12000.vocab \
--local-dir checkpoints
適当な声(英語)をinput.wavとして保存して、いかに移動
mkdir test_data
#その後test_data にinput.wavをおきます
全体的に機能しているかテスト
# Please put your prompt audio in 'test_data' and rename it to 'input.wav'
PYTHONPATH=. python indextts/infer.py
上記のテストが問題なければ、後はコマンドでテストでボイスクローン出来ます。
基本的に必要なのはしゃべらせたい内容と、特徴コピーしたい声のサンプルです。(私は30秒程度の音声を利用しました。)
indextts "Hello Zenn Dev User! Make Zenn Dev Great Again!" \
--voice reference_voice.wav \
--model_dir checkpoints \
--config checkpoints/config.yaml \
--output output.wav
先日ローカルな勉強会のLTでデモしたときに使った動画です
私の日本語アクセントはすべて取り除いて、流暢にしゃべってます。でもトーンは私のものです。
LIPSYNCにはSADTALKERというこれも少し古いLIPSYNCのオープンソース使ってます。
Coqui-TTSの記事もかいたあとLIPSYNCの比較記事も今度実験できたら書こうと思います!。
比較として、次回はOPENVOICE V2について実際事件はしてみました。これは日本語もサポートするのですが音声性については問題ないですが、今のところボイスクローンはいまいちです。
(2025/07/12 更新)
論文の中で比較しているCosyVoiceというものを試した記事です。
対応言語、精度(精度はINDEX-TTSと遜色なし)総合的にこちらのほうがいいかも。
Discussion