[AWS]⭐️重要:S3
はじめに
最近よく聞くS3についてまとめていこうと思います。課題の範囲でもあるしね〜〜
「Amazon S3」とは何??
オブジェクトストレージとは(&他のストレージ)
「オブジェクトストレージ」
「オブジェクトストレージ」は、それぞれのデータを「オブジェクト」単位で記憶するストレージ
各データにはメタデータ(メタデータは、データの特性、内容、構造、管理方法などを記述し、データの理解、検索、管理、利用を容易にするために使用される)を付けて管理。
レイテンシ(下記に記載)は高くなりますが、大容量ストレージの構築に向いています。
「ブロックストレージ」
「ブロックストレージ」は、データを「ブロック」の集合体として管理するストレージ
低いレイテンシが特徴
Amazon Elastic Block Store(EBS)は、ブロックストレージを採用しています。
「ファイルストレージ」
「ファイルストレージ」は、NFSやSMBなどのファイル共有プロトコルによってファイルを管理するストレージ。
ネットワークプロトコルが介在する分、レイテンシが高くなります。
Amazon Elastic File System(EFS)は、NFSを使用するファイルストレージです。
Amazon S3の特徴
-
容量無制限
保存できるデータ容量とオブジェクト数には制限がありません。
ただし、1つのオブジェクトサイズは最大5TBまでです。 -
高度な耐久性
S3に保存したデータは、99.999999999%(9×11)の耐久性を実現するよう設計されています。 -
使いやすい価格設定
容量単価の月額は、0.023ドル/1GBです(2020年3月・東京リージョンの標準ストレージの場合)。 -
スケーラブルで安定した性能
どのようなファイル数やサイズ、リクエスト数であっても一定性能を発揮できるように、複数のストレージクラスが用意されています。
このため、必要な性能やディスク容量などを考える必要がありません。 - 他のストレージと比較した場合、Amazon S3の1回のファイル転送時のレイテンシ(※)やスループットは性能的に突出しているわけではないけど、同時に複数ファイルを転送する際に性能が低下しにくいため、大規模なデータ配信を行うアプリケーションやサービスのストレージとして利用される。
-
S3の高い信頼性
Amazon S3に保存するデータは、最低3つのAZに自動的に保存されます。
また、1つのAZに保存されたファイルは、さらに複数のデバイス上に保存されます。
このため、どれか1つに障害が発生したとしても、使い続けることができる🦄すごーい🩵
[補足]
・以前はデータの更新や削除はすぐに上書きされず結果的に反映される結果整合性と言うモデル
・今は更新後すぐに最新バージョンのデータに反映されるようになる強い一貫性というモデル!
🔔 Amazon S3でよく使われる用語
-
バケット
オブジェクトの保存場所。AWSアカウント内に複数作成できる
バケット名は、必ずグローバルに一意(ユニーク)にする
バケット名は、バケット内のオブジェクトにアクセスする際のURLの一部として、そのまま利用できる -
オブジェクト
バケットに保存されているファイル本体のこと
1つのバケットに格納できるオブジェクト数は無制限、ファイルサイズは5TBまで -
キー
オブジェクトの識別子のこと
オブジェクト名は「バケット名+キー+バージョン」の組み合わせで、必ず一意になる -
メタデータ
オブジェクトに付属する属性情報。名前と値のセット
「システム定義メタデータ」と「ユーザー定義メタデータ」がある
Amazon S3のストレージクラス
Amazon S3のオブジェクトでは、オブジェクトへのアクセス頻度や冗長性に応じて、ストレージのクラスを選択できます。これによって、コストを抑えることができます。
S3のアーキテクチャ
アーキテクチャとは、システムやソフトウェアの全体的な構造や設計のこと
(S3がどのように構築され、データの保存とアクセスがどのように機能するかを示す設計図)
S3のアーキテクチャの流れ

S3のファイル操作
S3のファイル操作とは、Amazon S3を使ってクラウド上に保存されたデータやファイルに対して行う一連の操作のことを指す。
基本的なファイル動作

ロケーションとは
S3の「ロケーション」は、S3バケットのリージョン(地域)のこと。
AWS S3では、「リージョン」と「ロケーション」という用語はほぼ同じ意味。
- リージョン (Region) とは、AWSが世界中に設置したデータセンターのグループ
ap-northeast-1 (アジア太平洋北東部、東京)とか - ロケーション (Location) という用語は、具体的にはあまり使用されませんが、一般的にはバケットの物理的な場所やデータセンターの所在地を指すために使われることがあります。AWS S3の設定では「リージョン」を選択することで、この「ロケーション」を設定することになります。
バケットのリージョン設定いつするのか??
-
バケット作成時:
S3バケットを作成する際に、リージョンを選択します。このリージョンはバケットの物理的な場所を示し、バケットがどのデータセンターに存在するかを決定します。 -
リージョンの選択画面:
AWS Management ConsoleでS3バケットを作成するとき、リージョンを選択する画面があります。ここでバケットのリージョンを設定します。
S3へのアクセス方法

S3のアクセス管理
S3では、バケットやオブジェクトのアクセスを管理できます。
管理する方法には、「IAMポリシー」、「バケットポリシー」、「ACL」の3種類ある!
[ 補足 ] JSON形式??😗
今回で言うとIAMポリシー・バケットポリシーの記法方法!
目的: データを構造化して表現するための形式。
構造: キーと値のペアでデータを表現する。
{
"name": "Alice",
"age": 30,
"isEmployed": true
}
IAMポリシーの使用例
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowGroupToSeeBucketListInTheConsole",
"Action": ["s3:ListAllMyBuckets"],
"Effect": "Allow",
"Resource": ["arn:aws:s3:::*"]
}
]
}
-
Action
Actionは、GETやPUTなど実際の行動を設定するエレメントで、許可または拒否したいアクションを指定します。(複数アクションの指定も可能。)
今回はs3:ListAllMyBucketsを記述することで、自分のAWSアカウントの全バケットを表示できるようになります。
"Action":[
"ec2:StartInstances",
"ec2:StopInstances"
]
-
Effect
Effectエレメントでは、設定したい効果を、許可(Allow)または拒否(Deny)のいずれかで指定します。必須の要素です。 -
Resource
Resourceエレメントでは、ポリシーを適用したいバケットやオブジェクトを指定(複数指定も可能。)
リソース(対象物:オブジェクトなど)は、多くの場合、Amazonリソースネーム(ARN)を使って特定します。「ARN」は、アカウント内のAWSリソースを一意に識別するAWS共通の記法です。
AWSサービス名、リージョン、アカウント、リソース名などをコロンでつなげて記述します。
"Resource":"arn:aws:s3:::examplebucket/*"
-
Principal
Principalエレメントは、許可または拒否するプリンシパルを指定する。
「プリンシパル」とは、アクセス元のAWSアカウントやIAMユーザー、サーバーのこと。
"Principal": "*" を指定することで、インターネット上の全てのユーザーがアクセスできるようになります。
*今回のポリシーはIAMポリシーのサンプルのため、「Principal」の指定はしてない!
"Principal":{"CanonicalUser":"CloudFront Origin Identity Canonical User ID"},
バケットポリシーの使用例
AWSのCloudFront(S3に保存された画像や動画を高速に配信するためのサービス)というコンテンツ配信サービスに対して、S3バケット「examplebucket」内のすべてのファイルの読み取りを許可するポリシーです。
{
"Version":"2012-10-17",
"Id":"PolicyForCloudFrontPrivateContent",
"Statement":[
{
"Sid":" Grant a CloudFront Origin Identity access to support private content",
"Effect":"Allow",
"Principal":{"CanonicalUser":"CloudFront Origin Identity Canonical User ID"},
"Action":"s3:GetObject",
"Resource":"arn:aws:s3:::examplebucket/*"
}
]
}
- Actionには、オブジェクトを読み取るアクションが指定されています。
- Principalには、正規ユーザーID(難読化されたAWSアカウントID)を指定します。このIDは、- - CloudFrontのディストリビューションを表します
- Resourceのリソース指定部分には、バケット内の全オブジェクトを示す「examplebucket/*」が指定されています。
ポリシーの評価論理(優先順位)
IAMポリシーとバケットポリシー(ACL)では、以下のような評価論理になっています。
ブロックパブリックアクセス
実際のシステム運用では沢山バケット(データの収納場所)が作成されてアクセスされます。
それを防ぐために、Amazon S3には、アカウントレベルもしくはバケットレベルでバケットのパブリックアクセスを防止する「ブロックパブリックアクセス」機能があります。
-
ブロックパブリックアクセス
・ブロックパブリックアクセスを使うと、ACLやバケットポリシーでの設定にかかわらず、最優先でパブリックアクセスを禁止したり、パブリックアクセスの許可を設定できないように制御できる。
・既存のAWSアカウントとバケットに対して設定できます。また、新規に作成されるAWSアカウントとバケットは、この設定がデフォルトで有効になっている。
暗号化によるデータ保護
❶転送時のデータを保護する(暗号化担当:SSL)
ユーザーがS3にデータを送信する際、特別な設定をしなくてもSSLという暗号化プロトコルにより自動的にデータが暗号化されます。これにより、送受信中のデータが安全に保護されるので安心です。
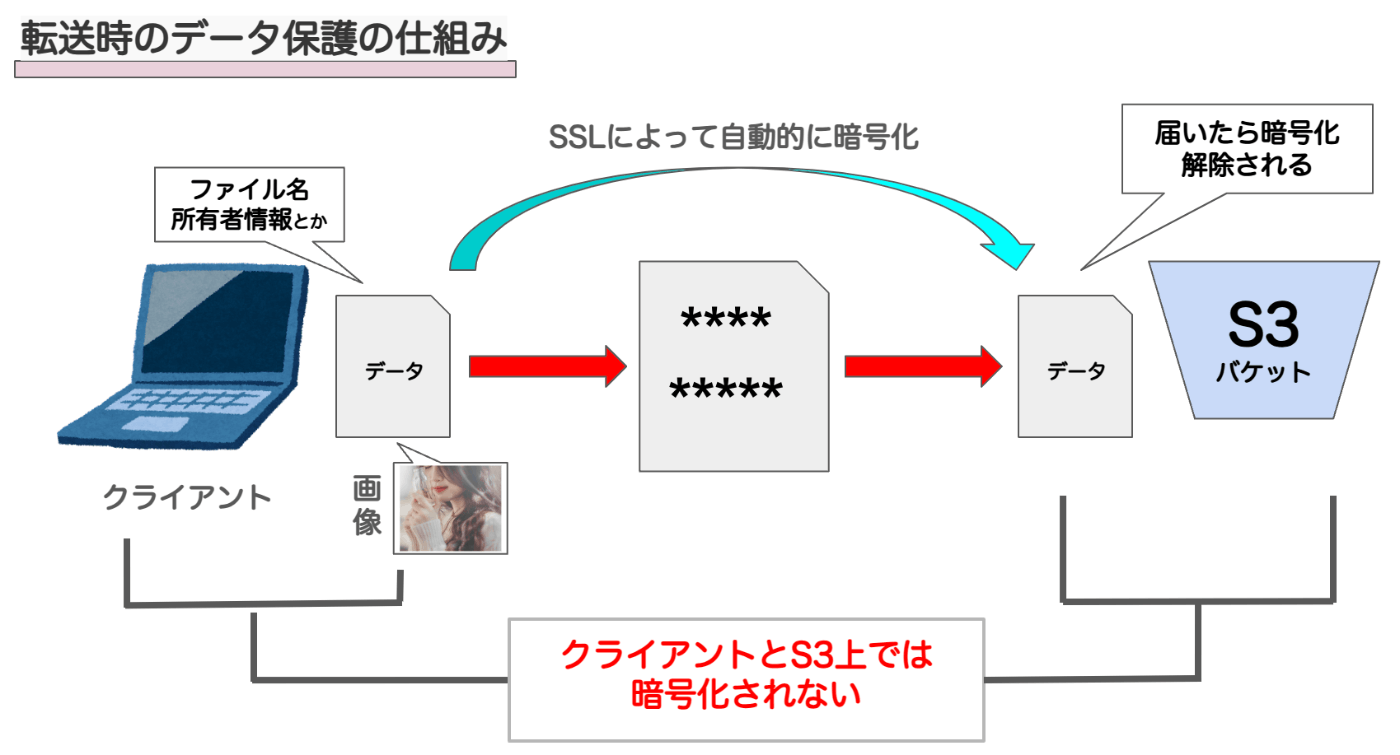
SSLとは
SSLはS3だけでなく、インターネット上の通信を保護するためのプロトコル(コンピュータネットワークでデータを送受信するための規則や手順のこと)で、他の多くのウェブサイトやオンラインサービスでも一般的に使われているもの🐥🐥
なんかS3だけに使う特別なもの感出してるけどそんなことなく色んな所で使われてるんかーーーい
❷保管時のデータを保護する(暗号化担当:S3)
保管時については、S3のサーバー側の暗号化を利用できる。
この機能は、クライアントがS3にデータをアップロードする際、S3に対してリクエストできます。
クライアントからアップロードされたデータをデータセンター内のディスクに保存する直前とこのデータのダウンロードがリクエストされ、クライアントがダウンロードする前にデータを復号化します。

ちなみに今まではこれしようとしたら設定が必要だったけど、2023年1月5日以降、新たに作成されるS3バケットにはデフォルトでサーバー側の暗号化が適用されるようになり、ユーザーが特別な設定をしなくても自動的に暗号化されるようになりました。
暗号化を確認する
- S3のダッシュボードで、任意のS3バケットを選択する
- [プロパティ]タブを選択し、[デフォルトの暗号化]の項を確認する

バケットキーは暗号化キータイプに[AWS Key Management Service キー (SSE-KMS)]を選択している時に関係があるもの
❸「クライアント側の暗号化」
データ送信以前に、クライアント(ユーザーやアプリケーション内)でデータを暗号化する方法!
クライアント側で暗号化を行うために必要なツールやライブラリのコストが発生するし運用も自分でしなきゃいけない&正直そんなんしなくても上記で書いた❶と❷で暗号化は出来る。
じゃあなんのメリットがあんねーーーん🐣
高いセキュリティを要求されたり医療情報や金融データなどの規制で、データの暗号化を厳密に求める場合は「クライアント側の暗号化」をする必要がある🪼
S3のWebサイトホスティング
そもそもWebサイトホスティングとは。。。??
Webサイトホスティングは、ネット上に自分のWebサイトを公開し、誰でもアクセスできるようにするためのサービス。
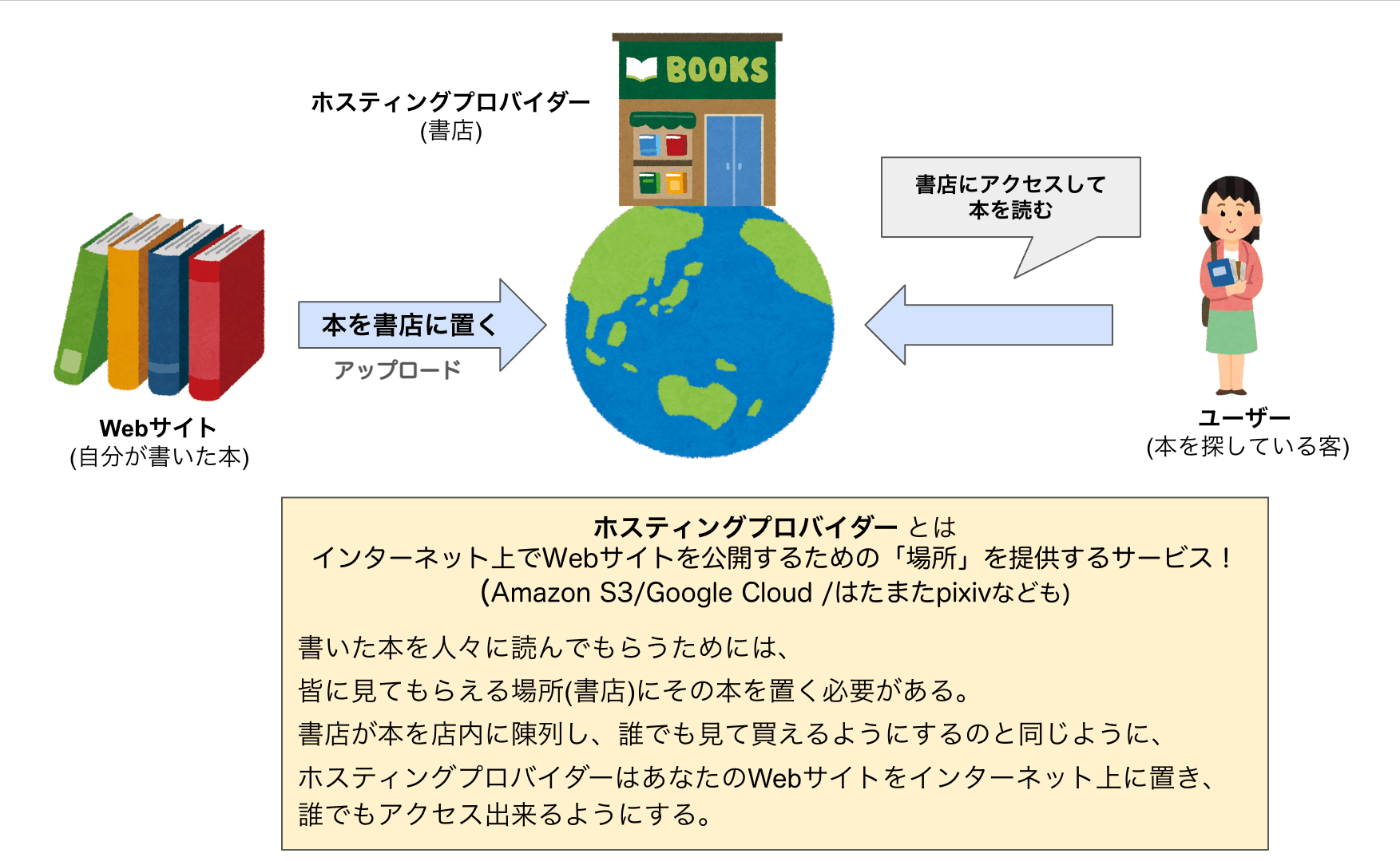
自分用解釈
例えば、Pixivのように、あなたが作成した作品(Webサイト)をインターネット上に公開するために、ホスティングプロバイダーを使ってその作品をアップロードします。すると、ユーザーはブラウザを通じてあなたのWebサイトにアクセスし、その内容を見ることができるようになります。
[やっと本題] S3のWebサイトホスティングとは??
S3は、静的Webサイトをホスティングするためのサービスです。
(例:情報が変わらない企業のウェブサイト等)
S3では、サーバーサイドでプログラムを実行する機能がないため、動的な処理が必要なWebサイト(ユーザーアカウント管理やデータベースアクセスなど)には対応できません。
(補足 :動的Webサイト内の静的ファイルだけをS3にホスティングし、APIなどで動的プログラムにして別サーバーにホスティングすることで、全体として動的Webサイトをホスティングすることは可能)
S3のバージョニング
-
一般的なバージョニングとは?
バージョニングとは、ファイルの変更をトラッキングして変更前と変更後のファイルを別々のバージョンとして格納し、比較や復元ができるようにする機能🧞♀️ -
じゃあS3のバージョニングって??
同じバケット内で1つのオブジェクトに対して変更履歴を保持(トラッキング[追跡・記録])し複数のバージョンを管理する機能。具体的には、オブジェクトが更新されるたびに新しいバージョンが作成され、古いバージョンも保存され続けます。
[自分用]S3っていつ使うん?笑 githubじゃあかんの??🧑💻
S3のバージョニングはGitHubに履歴を残すことと似ています。
どちらも変更履歴を管理し、過去のバージョンにアクセスできるようにする機能がある。
GitHubとの使い分け
- GitHubの適用範囲:
GitHubはソースコードのバージョン管理に特化しており、コードの変更履歴やバージョン管理に最適です。
チームでの共同開発やコードレビュー、プルリクエストの管理などに優れています。 - S3の適用範囲:
S3は静的ファイル(画像、動画、ドキュメントなど)の保存と配信に適しており、バージョニングを使うことでこれらのファイルの変更履歴を管理できます。
特に、非コードのファイルや大規模なデータセットのバージョン管理が必要な場合に有効です。
結論
GitHubはソースコードの管理に優れており、開発プロジェクトに最適です。
S3のバージョニングは、静的ファイルや非コードのデータのバージョン管理が必要な場合に有用です。
ライフサイクル管理
ライフサイクル管理とは???
バケット内のオブジェクトに対し、定期的に行うアクションを自動化できる機能👽
たとえば、ストレージクラスを変更したり、ファイルの削除などを自動化する。
以下のような目的で使用されます。とても便利な機能です。
- アプリケーションログなど参照期間が限られるファイルは、一定期間経過したら削除したい
- アクセス頻度の低くなった古いファイルやドキュメントは、一定期間経過したら、より安価なストレージクラスに変更したい
- アーカイブ目的で復元予定が低いデータは、定期的にGlacierにアーカイブさせたい。
ライフサイクルルールを設定する
ここでは、バージョニングが有効化されているバケットに対して、すべてのオブジェクトを対象に最新バージョン以外のバージョンを1日経過後に削除するルールを設定します。
- バケットの[管理]タブをクリックする
- [ライフサイクルルールを作成する]をクリックする
- ルール名入力、ルールスコープを選択で「すべてのオブジェクトに適応」をクリックする
フィルターも設定できますが、今回はすべてのファイルを対象とするため、フィルターの設定は行いません。
また、「オブジェクトの非現行バージョンを完全に削除」を選択し、日数に「1」と入力します
こうすることで、最新以外のバージョンを1日後に削除することができます。 - ルールを作成する
「ルールを作成する」をクリックすると、ライフサイクルルールが追加されます。 - 任意のファイルを数回アップロードしてバージョンを作成する
1日経過した後、以前のバージョンが削除されていることが確認できます。
S3の料金
Amazon S3は、実際に使った分のみ料金を支払うシステムで、最低料金の設定はありません。
S3の利用料金は、「ストレージ」、「リクエストとデータ取り出し」、「マネジメントとレプリケーション」、「データ転送」の4つで発生します。

1. ストレージの料金
ストレージの料金は、使用したストレージの容量と時間を元にストレージクラスごとに算出される。
AWSではこれを「ストレージ使用量」と呼んでいます。
ストレージ使用量は、月内の各日のストレージの使用容量を合計し、それを月の日数で割ったものです。
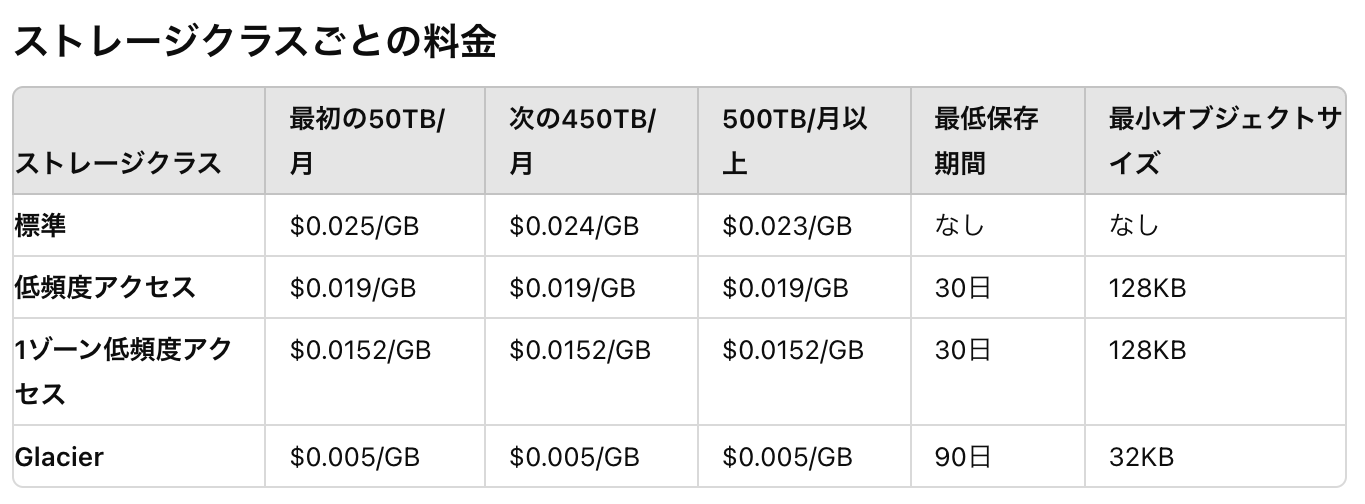
料金計算の例
要件
標準ストレージクラスで、3月の最初の15日間に100GB、残りの16日間に100TBを使用した場合
ストレージ使用量 = (100GB × 15日 + 100TB × 16日) / 31日 = 52,900GB
50TBはGBに直すと(50,000GB)だから52,900GBの場合2,900GB分超えてしまってる!!!
この場合50,000GB分は単価:$0.025/GBで計算して、
超えてる2,900GBは次の450TB/月に当たる単価$0.024/GBで計算する🤖ヘェ〜〜〜
たっけ〜〜〜〜〜なおい。ってことで
推奨事項
頻繁な更新や削除が多いファイル: 標準ストレージクラスの使用が推奨されます。
小さなオブジェクトが多数ある場合: 小さいオブジェクトが大量にある場合は、zipなどで1つのファイルにまとめてから保存すると、「リクエストとデータ取り出しの料金」の節約になる!
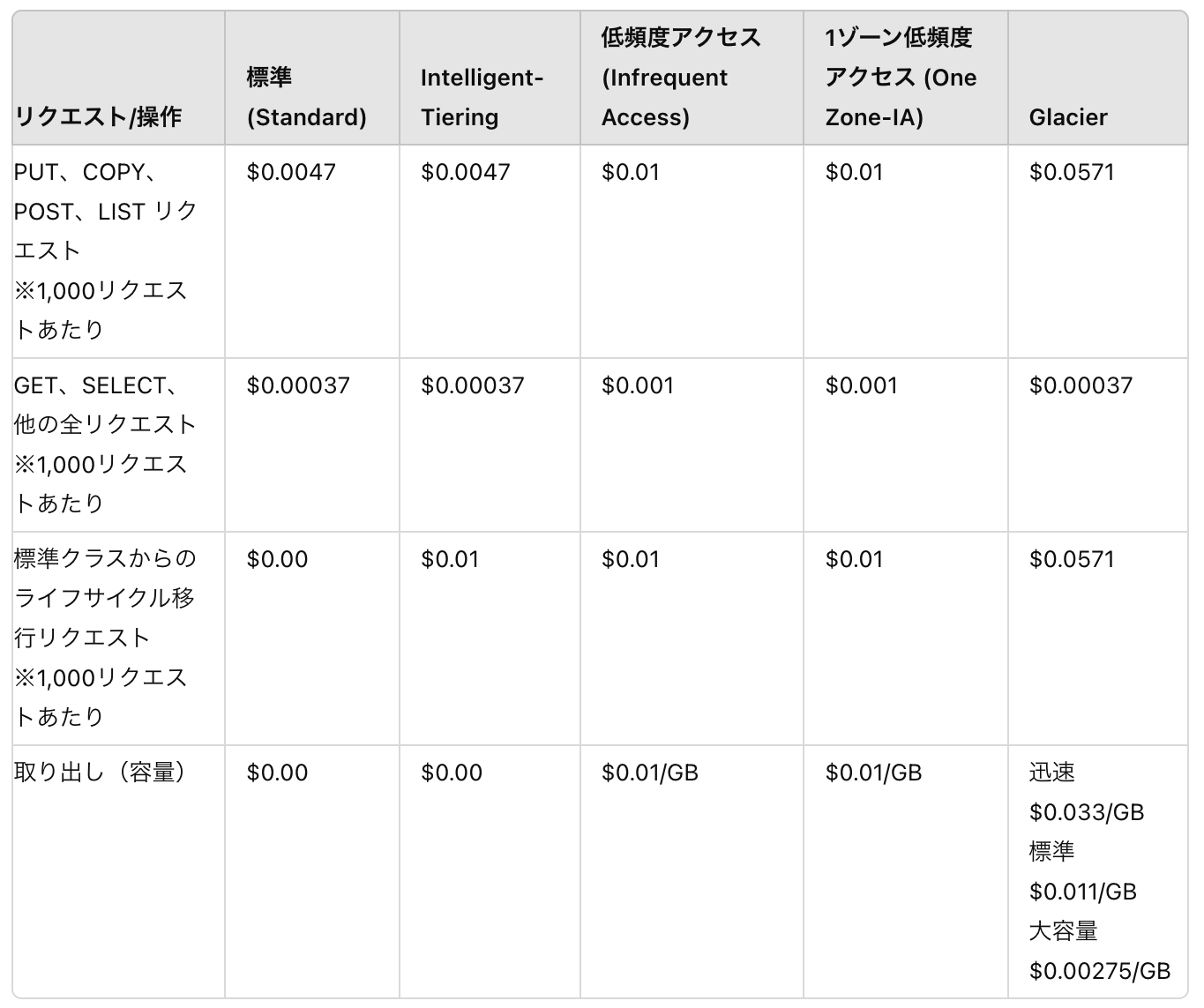
2. リクエストとデータ取り出しの料金
リクエストとデータ取り出しの料金は、リクエストを行った回数を元に計算されます。
リクエストの種類とストレージクラスによって、以下のように決まっています。
3. マネジメント(とレプリケーションの)料金
『マネジメント』とはAWS S3のデータ管理やコスト管理を効率化するためのツール。
(レプリケーションはデータ複製の事だけどここには載ってない。え、なんで書いたん💩)
マネジメント(とレプリケーション)の料金の課金体系は、機能ごとに異なる。

機能の解説
-
S3 Inventory(インベントリ)
S3 Inventoryは、S3バケット内のオブジェクトを定期的にリストアップし、CSVやParquetなどの形式で出力する機能です。これにより、バケット内の全オブジェクトの状態やメタデータ(タグ、バージョン、暗号化状態など)を把握するのに役立ちます。 -
S3 Analytics - Storage Class Analysis
S3 Analyticsは、オブジェクトのアクセス頻度を分析し、どのストレージクラスが最適かを提案する機能です。たとえば、頻繁にアクセスされないオブジェクトを低頻度アクセスストレージクラスやGlacierに移動することでコストを削減するための判断材料を提供します。 -
S3 オブジェクトのタグ付け
S3オブジェクトにタグを付けて分類や整理を行う機能です。タグを使うことで、特定のオブジェクトを簡単に検索したり、アクセス管理やコスト管理を行いやすくなります。 -
S3 バッチオペレーション
S3バッチオペレーションは、大量のオブジェクトに対して一括で操作を行う機能です。例えば、多数のオブジェクトを一度にコピーしたり、削除したり、タグを付けたりすることができます。これにより、大規模なデータ処理を効率的に行うことができます。 -
S3 Intelligent-Tieringモニタリングおよびオートメーション
S3 Intelligent-Tieringは、オブジェクトのアクセスパターンを自動で監視し、アクセス頻度に応じて適切なストレージクラスに自動的に移動させる機能です。これにより、コストを最適化しつつパフォーマンスを維持できます。
4. データ転送
データ転送の料金は、S3バケットとクライアントがインターネット経由でデータ転送を行った場合にかかります。
また、AWS Direct Connect(AWSのサービスに専用線で接続するサービス)を経由する場合は、料金体系が異なります。
ンンンンンンんn〜〜〜〜〜〜〜〜〜〜〜〜〜
覚えるのは全然できなそう。。。。。。なれるのかなぁ
Discussion