Deep Learning資格試験 深層学習 CNN 代表的なモデル
はじめに
日本ディープラーニング協会の Deep Learning 資格試験(E 資格)の受験に向けて、調べた内容をまとめていきます。
物体認識モデル
AlexNet
- 2012 年に考案されたモデル(ILSVRC2012)
- 8 層
- 人が特徴量を設計せず、機械学習が特徴量を見つけ出す。
- ReLU を採用した(2010 年登場)
- Dropout を採用した(2012 年登場)
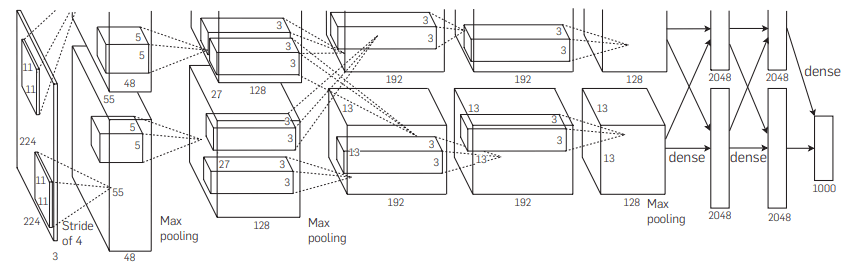
VGG
- 2014 年に考案されたモデル
- 19 層
- フィルタサイズ3 × 3の畳み込み層を複数積み重ねることで、少ないパラメータで大きなフィルタを使用した場合と同じ範囲を畳み込むことを提案したモデル
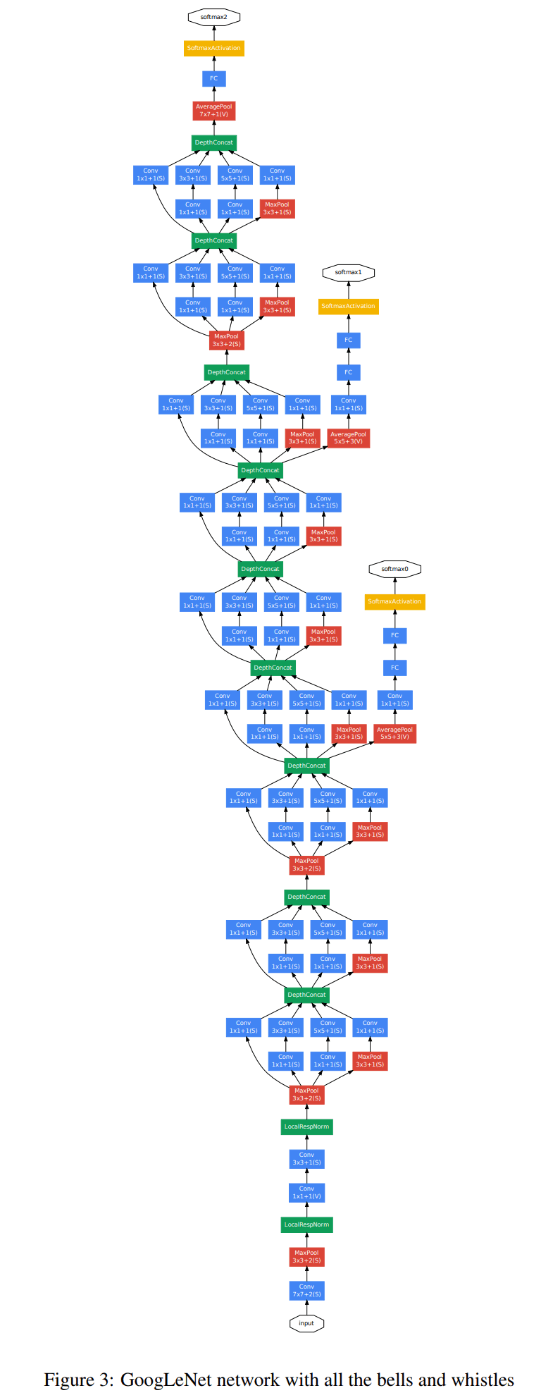
GoogLeNet
- 2014 年に考案されたモデル
- 22 層
- Global Average Pooling というプーリングの手法を採用している。各チャンネルの画素平均値を求め、それをチャンネルの平均値を要素とするベクトルに変換する。この結果は、次の演算でチャンネルごとの特徴量として計算されることにより、全結合層ですべての画素値を使う場合と比べて大幅に計算量を削減できる。
インセプションモジュール
- フィルタサイズの異なる畳み込みを並列に行って、その出力を足し合わせることで、複数のスケールの特徴を抽出することができるようになり、層を深くして複雑な特徴を表現できるようになった。
-
1 \times 1
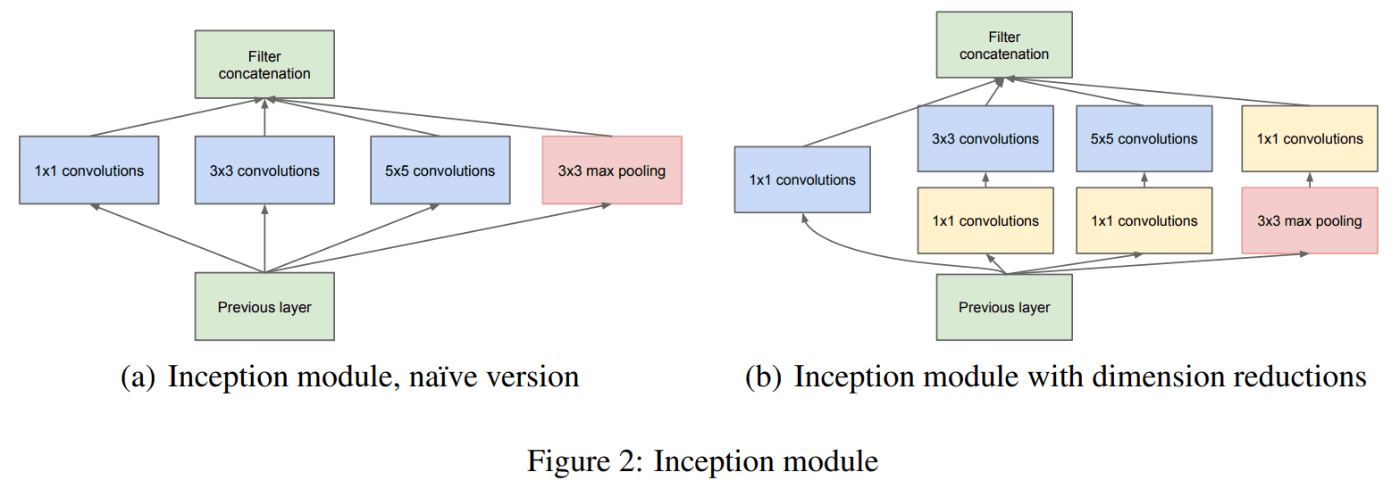
auxiliary classifiers
- ネットワークの途中で分岐させたサブネットワークで予測を行う補助的分類器といった工夫が導入されている。
- アンサンブル学習と同様の効果が得られるため、汎化性能の向上が期待できる。
GoogLeNet 全体
ResNet (Residual Network)
- 2015 年に考案されたモデル
- 152 層
- 特徴マップ同士を足し合わせるショートカット結合が特徴的なモデル
- 層を深くすると勾配消失が起こるが、ResNet は勾配消失が起こりにくい
- 浅い CNN で十分学習できてしまい、深い中間層が不要な場合、不要な層の重みが0になる。
- 入力時点の勾配が小さい場合、通常であればレイヤーを重ねていくほど勾配が消失してしまうが、identity mappingを通す事によってわずかな勾配の乗法も消失することなく残すがことができる。
identity mapping (Skip connection)
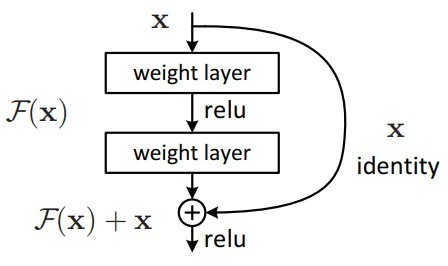
- 層が深いネットワークでも学習が進められる
DenseNet
- 恒等画像を介して特徴マップ同士を足し合わせるショートカット結合。
- あるブロック内ですでに作られた特徴マップ全てを対象する。

DenseNet と ResNet の違い
- DenseBlock では前⽅の各層からの出⼒全てが後⽅の層への⼊⼒として⽤いられる
- RessidualBlock では前 1 層の⼊⼒のみ後⽅の層へ⼊⼒
DenseNet 詳細
Dense Block
出⼒層に前の層の⼊⼒を⾜しあわせる
- 層間の情報の伝達を最⼤にするために全ての同特徴量サイズの層を結合する
特徴マップの⼊⼒に対し、下記の処理で出⼒を計算
- Batch 正規化
- Relu 関数による変換
- 3 x 3 畳み込み層による処理
k をネットワークの growth rate と呼ぶ
- k が⼤きくなるほど、ネットワークが⼤きくなるため、⼩さな整数に設定するのがよい
Transition Layer
- CNN では中間層でチャネルサイズを変更し
- 特徴マップのサイズを変更し、ダウンサンプリングを⾏うため、Transition Layer と呼ばれる層で Dence block をつなぐ
正規化
Batch Norm
- ミニバッチに含まれる sample の同⼀チャネルが同⼀分布に従うよう正規化
- H x W x C の sample が N 個あった場合に、N 個の同⼀チャネルが正規化の単位
- RGB の 3 チャネルの sample が N 個の場合は、それぞれのチャンネルの平均と分散を求め正規化を実施 (図の⻘い部分に対応)。チャンネルごとに正規化された特徴マップを出⼒。
- Batch Normalization はニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制など効果がある。
- 問題点
- Batch Size が⼩さい条件下では、学習が収束しないことがあり、代わりに Layer Normalization などの正規化⼿法が使われることが多い。
Layer Norm
- それぞれの sample の全ての pixels が同⼀分布に従うよう正規化
- N 個の sample のうち⼀つに注⽬。H x W x C の全ての pixel が正規化の単位。
- RGB の 3 チャネルの sample が N 個の場合は、ある sample を取り出し、全てのチャネルの平均と分散を求め正規化を実施 (図の⻘い部分に対応)。特徴マップごとに正規化された特徴マップを出⼒
- ミニバッチの数に依存しないので、上記の問題を解消できていると考えられる。
Instance Nrom
- さらに channel も同⼀分布に従うよう正規化
- 各 sample をチャンネルを ごとに正規化
- コントラストの正規化に寄与・画像のスタイル転送やテクスチャ合成タスクなどで利用
物体検出モデル
MobileNet
-
スマートフォンのような計算資源が限られた環境下で利用するために
-
通常の畳み込みの代わりにデブスワイズ畳み込みと、ポイントワイズ畳み込みの2種類の畳み込みを採用している。
-
Depthwise Separable Convolution という⼿法を⽤いて計算量を削減している。通常の畳込みが空間⽅向とチャネル⽅向の計算を同時に⾏うのに対して、Depthwise Separable Convolution ではそれらを Depthwise Convolution と Pointwise Convolution と呼ばれる演算によって個別に⾏う。
-
Depthwise Convolition はチャネル毎に空間⽅向へ畳み込む。すなわち、チャネル毎に
D_K \times D_K \times 1 H \times W \times C \times D_K \times D_K -
次に Depthwise Convolution の出⼒を Pointwise Convolution によってチャネル⽅向に畳み込む。すなわち、出⼒チャネル毎に
1 \times 1 \times M H \times W \times C \times M
Depthwise Convolution(デブスワイズ畳み込み)
- ⼊⼒マップのチャネルごとに畳み込みを実施
- 出⼒マップをそれらと結合 (⼊⼒マップのチャネル数と同じになる)
チャンネルごとに畳み込みをするため、チャンネル間の関連性は考慮されない。
入力マップ:
カーネル:
出力マップ:
出力マップの計算量は:
Pointwise Convolution(ポイントワイズ畳み込み)
- 1 x 1 conv とも呼ばれる (正確には 1 x 1 x c)
- ⼊⼒マップのポイントごとに畳み込みを実施
- 出⼒マップ(チャネル数)はフィルタ数分だけ作成可能 (任意のサイズが指定可能)
入力マップ:
カーネル:
出力マップ:
出力マップの計算量は:
通常の CNN との比較
CCN のパラメータ数
入力チャンネル数:
出力チャンネル数:
フィルタサイズの高さ:
フィルタサイズの幅:
パラメータ数:
デブスワイズ畳み込みのパラメータ数
パラメータ数:通常の畳み込みと比較して
ポイントワイズ畳み込みのパラメータ数
パラメータ数:
通常の畳み込みと比較して
R-CNN
- 2014 年に考案されたモデル
- 画像内に存在する複数の物体をそれぞれ個別に検出したい。
- CNN から出力された特徴マップを SVM に入力しカテゴリ識別を行い、回帰によって正確な領域の推定を行う。
- 特徴抽出の CNN、カテゴリ推定の SVM など各学習の目的ごとに別々に学習させる必要があるため、End-to-End 学習ができない。
- CNN の入力層のサイズは
227 \times 227pixel
Region Proposal(物体候補領域検出)
- 領域候補を取得するために Selective Search(選択的探索法)を用いる。
課題
- 候補領域の個数(~ 2K)分の CNN を計算するため、処理速度が遅い(Fast R-CNN で解決)
- 物体候補領域検出が Selective Search(選択的探索法)だと遅い(Faster R-CNN で解決)
Fast R-CNN
- 画像全体を複数回畳み込んで、特徴マップを生成し、得られた特徴マップを各候補領域の該当する部分に割り当てる(Multi-task loss を導入)
- 分類を行う層への入力を固定次元にするためにRoI Poolingを行っている。
Region Proposal(物体候補領域検出)
- 領域候補を取得するために Selective Search(選択的探索法)を用いる。
Faster R-CNN
- Faster R-CNN は、Region Proposal Network と Fast R-CNN の2つのモジュールから構成されている。
- 分類を行う層への入力を固定次元にするためにRoI Poolingを行っている。

Region Proposal(物体候補領域検出)
- 領域候補を取得するためにニューラルネットワークを用いる。(Region Proposal Network、RPN)
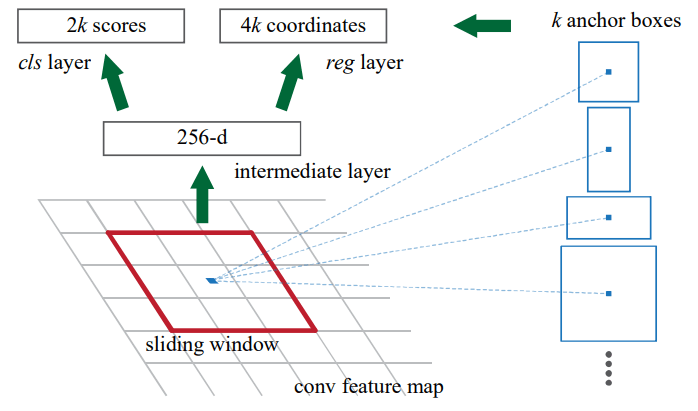
- 誤差関数にはAnchorが取り入れられている。
- 特徴マップを受け取る。
-
n \times n n = 3 - 畳み込みをした特徴マップをcls layerとreg layerへ渡す。
-
cls layerとreg layerの両方とも
1 \times 1 - reg layerは、バウンディングボックスの回帰を行う。
- cls layerは、物体である確率と物体でない確率を推定する。
- スライディング・ウィンドウは、ストライド1、パディングありで畳み込みを行うため、
H \times W - 各スライディング・ウィンドウには、
k - アンカーボックスは、それぞれ異なるスケール、アスペクト比を持つ矩形領域である。
- アンカーボックスの個数は、スライディング・ウィンドウ
H \times W k H \times W \times k - IoU が 0.7 以上で最大のアンカーボックスを物体のアンカーボックスとして、IoU が 0.3 未満の場合は背景のアンカーボックスとする。
-
reg layerは、アンカーボックスの中心の x 座標、y 座標、幅、高さの4つの値を出力するため、
4k -
cls layerは、物体である確率と背景である確率を出力するため、
2k
- R-CNN、Fast R-CNN からの改善点である。
YOLO
- 入力画像を複数の小領域に分割し、各小領域ごとにクラス分類とバウンディングボックスの位置や大きさなどの回帰を行う。
SSD
- 大きさの異なる複数の特徴マップを使ってクラス分類やバウンディングボックスの回帰を行う。
- 通常の CNN では出力層に近い特徴マップほど、差が小さくなる。
- [大きさの異なる複数の特徴マップ]とは、入力層に近い特徴マップと出力層に近い特徴マップを使用するという意味である。
- 入力層に近い特徴マップは小さな物体の検出に適しており、出力層に近い特徴マップは大きな物体の検出に適している。
セマンティックセグメンテーション
FCN(Fully Convolutional Network)
- 全結合層を使用せずに、畳み込み層とプーリング層で構成されている。
- プーリングで小さくなった特徴マップに転置畳み込みを適用することで、元の画像サイズの大きさまで拡大する。
SegNet
- 2016 年に提案されたモデル。
- 自己符号化器の CNN である。
- エンコーダ時に最大値プーリングで取得した値が、もともと存在していた位置を記憶しておき、値と位置の両方をデコーダ側へ伝達する。
- 特徴マップの値すべてを保持する必要があった FCN よりもメモリ効率が良くなった。
U-Net
- 自己符号化器型の構造を持ち、FCN や SegNet よりも高精度なセマンティックセグメンテーションである。
- デコーダはエンコーダから渡された特徴マップと前層から渡された特徴マップをチャンネル方向に結合し、転置畳み込みで拡大する。
Discussion