🦁
Deep Learning資格試験 深層学習 Transformer
はじめに
日本ディープラーニング協会の Deep Learning 資格試験(E 資格)の受験に向けて、調べた内容をまとめていきます。
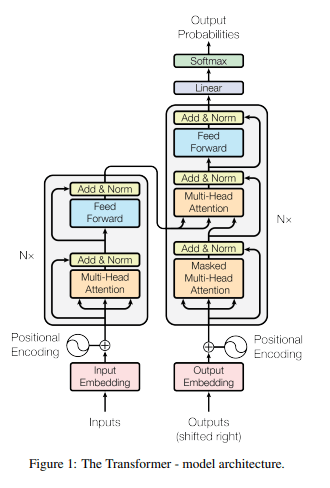
Transformer の仕組み
Transformer の概要
- 注意機構を主とする再帰構造を持たない
- Teacher Forcing:各位置までの部分的な正解系列を教師データにして学習
- 学習時はデコーダ側も並列処理可能
Attention は何をしているのか
- Attention は辞書オブジェクト
- query(検索クエリ)に一致する key を索引し、対応する value を取り出す操作であると見做すことができる。これは辞書オブジェクトの機能と同じである。
Transformer の長所
- 並列処理が可能で処理が早い
-
高性能
- 学習の高速化で大規模データでの学習が可能
- 自己注意機構により大域的な特徴(長距離の関連)を捉えられる
Transformer の短所
- 分からないことが多い
- 分析や調査の研究が盛んである
- 推論時は RNN デコーダの方が Transformer デコーダより高速
- RNN と比較して学習の制御が難しい?
- ハイパーパラメータに敏感(な気がする)
- バッチサイズを大きくしないと精度が出ない傾向
位置エンコーディング
- 再帰や畳み込みがない Transformer ブロックは系列情報(位置情報)を考慮できない
- 明示的に位置情報を与える機構
- 方法
- sin 関数と cos 関数で位置毎に固有のベクトルを与える(sinusoidal positional embeddings)
- 学習可能なパラメータ:位置情報を与える埋め込み行列を用意して学習する
注意機構
- 要素(単語)間の関連度を捉える仕組み
注意機構には二種類ある
ソース・ターゲット注意機構(Source Target Attention)
- Key、Value を一つの分散表現、Query を一つの分散表現からそれぞれ獲得してから計算を行う。
自己注意機構(Self-Attention)
- ひとつの分散表現から、Key、Value、Query の三つに分割してから計算を行う。
Position-Wise Feed-Forward Networks
- 位置情報を保持したまま順伝播させる
- 各 Attention 層の出力を決定
- 2層の全結合 NN
- 線形変換 →ReLu→ 線形変換
- 各 Attention 層の出力を決定
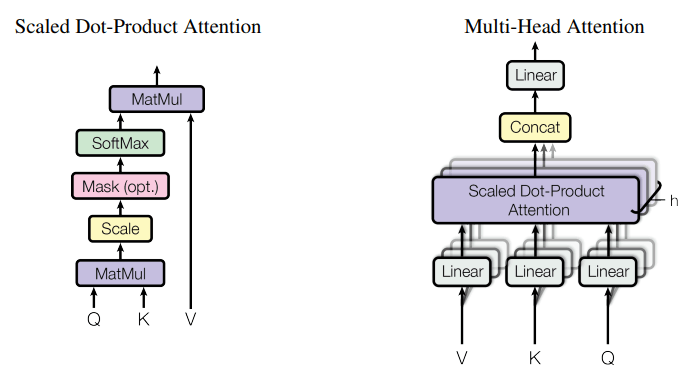
Scaled dot product attention(スケール・ドットプロダクト・アテンション)
- 全単語に関する Attention をまとめて計算する
- クエリ(
Q K V -
Q -
K -
V V=K
-
-
Q K V -
d_k -
d_k
-
softmax 関数に渡す値の分子
内積が並ぶことになる。内積は類似度を表す。
- 2つのベクトルが同じ向き:内積大
- 2つのベクトルが関係ない向き:0
- 2つのベクトルが逆の向き:内積マイナスの大
Multi-Head attention(マルチヘッド・アテンション)
- 重みパラメタの異なる8個のヘッドを使用
- エンコーダとデコーダの両方で使用される。
- エンコーダでは、クエリ、キー、バリューは、エンコーダの全て直前のエンコーダの出力から伝わってくる。このアテンションの事をSelf-Attentionという。
- デコーダでは、2種類のマルチヘッダ・アテンションがある。
- 1種類目は、セルフ・アテンションである。予測すべき単語の乗法が予測時に利用されないようにするため、マスクがかけられる。
- マスクがかけられた場所の値はソフトマックス関数に渡される前にm、
-\infy - 2種類目は、キーとバリューはエンコーダ、クエリはデコーダから伝わってくる。
Feed Forward Network
自然言語処理への応用(BERT)
BERT の概要
- Bidirectional Encoder Representation from Transformers: Transformer エンコーダを用いた NLP タスクのための事前学習モデル
- 様々な NLP タスクに適用可能で最高性能を達成
- マスク化言語モデル(Masked Language Model; MLM)と次文予測(Next Sentence Prediction; NSP)により学習
事前学習とファインチューニング
- 事前学習:大量の(正解ラベルが付いていない)データから予めモデルを学習
-
マスクされた単語を予測する問題と次の文かどうかを予測する問題を同時に解く -
マスクされた単語を予測する問題は多クラス分類問題 -
次の文かどうかを予測する問題は2クラス分類問題
-
- ファインチューニング:正解ラベル付き教師データを用いてタスクに応じて調整
順伝搬層の活性化関数
- gelu 関数 (Cf.Transformer では relu 関数)
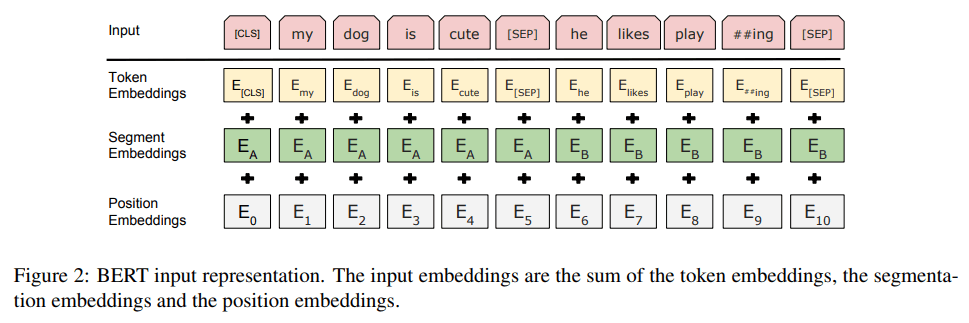
BERT の入力と埋め込み層
- 入力
- 事前学習時:2 文、ファインチューニング時:2 文または 1 文(タスクで異なる)
- 先頭に[CLS]トークン、文末に[SEP]トークンを挿入
- 埋め込み層
- 最初と後続のどちらの文に属するかを明示的に表す埋め込みを追加
マスク化言語モデル(MLM)
- 系列の一部をマスクしてマスクされている部分を予測
- 入力単語の 15%がマスク対象。マスク対象の 80%を[mask]トークンで置き換え、10%をランダムな単語に置き換え、10%はそのままにする。
- 次文予測(NSP)
- 2つの文が連続した文かを[CLS]トークンに基づき 2 値で予測
- 後続の文を 50%の確率で別の文に置き換え
- 2つの文が連続した文かを[CLS]トークンに基づき 2 値で予測
事前学習
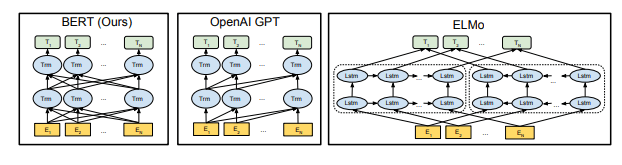
二種類のアプローチがある
Feature-based
特徴量抽出機として活用するためのもの
- 様々な NLP タスクの素性として利用される
- N-gram モデル[Brown et al., 1992]や Word2Vec[Malcov et al., 2013]など
- 文や段落レベルの分散表現に拡張されたものもある
- N-gram モデル[Brown et al., 1992]や Word2Vec[Malcov et al., 2013]など
- 最近では、ElMo[Peters et al., 2017, 2018]が話題に
- Context-Sensitive な素性を抽出
- 既存の素性に concat して使うことで複数の NLP タスクで SOTA
- QA, 極性分類, エンティティ認識
Fine-tuning
言語モデルの目的関数で事前学習する
- 事前学習の後に、使いたいタスクの元で教師あり学習を行う(すなわち事前学習はパラメタの初期値として利用される)
- 最近では、OpenAI GPT[Ralford et al. 2018]など。
- GLUE スコアで SOTA
- Transformer の Decoder だけを利用する
- 単方向接続モデル
BERT は、Fine-tuning アプローチの事前学習に工夫を加えた
- 双方向 Transformer
- tensor を入力とし tensor を出力
- モデルの中に未来情報のリークを防ぐためのマスクが存在しない
- 従来のような言語モデル型の目的関数は採用できない(カンニングになるため)
- 事前学習タスクにおいて工夫する必要がある
ファインチューニング
画像処理への応用(ViT)
ViT の概要
- Vision Transformer: Transformer エンコーダを用いた画像処理モデル
- パッチを単語のように扱う
- 畳み込み演算を行わない
- 画像分類タスクで最高性能を達成(学習も早い(4 分の 1 程度))
埋め込み層
- パッチ埋め込み
e^{(patch)} e^{(pos)} - パッチ埋め込み:パッチ中の成分を平ら(1 次元)にしたベクトルを埋め込み行列で線形変換
- 位置埋め込み:位置情報を与える学習可能な埋め込み行列を使用(BERT と同じ)
ViT の Transformer ブロック
- Transformer エンコーダの Transformer ブロックとの違い
- 層正規化が自己注意機構/順伝搬層の前に位置
- 順伝搬層の活性化関数が gelu 関数(BERT と同じ)
出力層
- CLS トークンの特徴ベクトルをクラス数次元へと線形変換した後でソフトマックス関数を適用(BERT や Transformer デコーダで用いた出力層と同じ)
- 事前学習も画像分類タスクで行うが、クラスが異なるため事前学習時とファインチューニング時で出力層を変更
音声認識への応用(Conformer)
Conformer の概要
- Convolution-augmented Transformer: 畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)と Transformer エンコーダを組み合わせた音声認識モデル
- Transformer:大域的な特徴を捉えるのが得意
- CNN:局所的な特徴を捉えるのが得意
- LibriSpeech データに対する音声認識で最高性能を達成(2020 年 5 月時点)
- Conformer ブロックがメインの処理
- 注意機構と畳み込みが特徴
SpecAugment
- 音声認識のためのデータ増強方法
- スペクトログラムを編集して教師データを水増し
Convolution Subsampling
- 畳み込み演算とサブサンプリング(プーリング演算)
- サブサンプリング:時間方向の空間を小さくする(10ms→40ms)
- 学習パラメータはない
Dropout
- ある割合でランダムにノードを選択して消去して学習(選択したノードの入力(出力)を 0 にする)
- 過学習の防止、汎化性能の改善
Feed Forward Module
- 2層の順伝搬層
- 活性化関数は Swish 活性化関数
- &\beta&はハイパーパラメータでも学習させてもよい
Multi-Head Self-Attention Module
- 要素の位置情報を要素間の相対位置関係で捉える
Convolution module
- 幅が時間方向、縦がなし、チャンネルが特徴ベクトルの次元方向に対応画像より1次元少ないデータと捉えられる
Pointwise Convolution
- 空間方向(𝐻 と 𝑊)の計算は行わずにチャンネル方向で畳み込み
- 各時刻で特徴ベクトルの次元方向で畳み込み
1 次元 Depthwise Convolution
- Depthwise Convolution:チャンネル毎(チャネル方向の計算は行わず)に空間方向で畳み込み
- 特徴ベクトルの次元毎に時間方向で畳み込み
Gated Linear Unit(GLU)
W , B ,V ,C :パラメータ行列
Batch Normalization(バッチ正規化)
- バッチ毎に正規化することで学習効率を高める
- Cf.層正規化:要素毎に正規化
Discussion