🦁
Deep Learning資格試験 深層学習 RNN 代表的なモデル

はじめに
日本ディープラーニング協会の Deep Learning 資格試験(E 資格)の受験に向けて、調べた内容をまとめていきます。
時系列モデル
エコーステートネットワーク
- RNN の重みを、入力の重み
U V W - 入力の重み
U V - 出力の重み
W - 勾配消失や勾配爆発が発生しなくなる。
スキップ接続
- 長期依存性の課題の対策
- 隠れ層を1時刻以上スキップさせた接続を追加する。
リーキーユニット(leaky unit)
- 隠れ層に線形結合を導入して、移動平均の効果を得る。
双方向 RNN
- 過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデル
- 実用例:文章の推敲や、機械翻訳等
LSTM
- RNN の課題
- 時系列を遡れば遡るほど、勾配が消失していく。
- 長い時系列の学習が困難。
- 時系列を遡れば遡るほど、勾配が消失していく。
- 解決策
- 前回の授業で触れた勾配消失の解決方法とは別で、構造自体を変えて解決したものが LSTM。
- 勾配爆発とは?
- 勾配が、層を逆伝播するごとに指数関数的に大きくなっていく。
CEC
- 勾配消失および勾配爆発の解決方法として、勾配が、1 であれば解決できる。
- CEC の課題
- 入力データについて、時間依存度に関係なく重みが一律である。
- ニューラルネットワークの学習特性が無いということ。
- 入力データについて、時間依存度に関係なく重みが一律である。
入力ゲートと出力ゲート
- 入力・出力ゲートの役割とは?
- 入力・出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列
W U - CEC の課題を解決。
- 入力・出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列
忘却ゲート
- LSTM の現状
- CEC は、過去の情報が全て保管されている。
- 課題
- 過去の情報が要らなくなった場合、削除することはできず、保管され続ける。
- 解決策
- 過去の情報が要らなくなった場合、そのタイミングで情報を忘却する機能が必要。
覗き穴結合 (peep hole)
- 課題
- CEC の保存されている過去の情報を、任意のタイミングで他のノードに伝播させたり、あるいは任意のタイミングで忘却させたい。
- CEC 自身の値は、ゲート制御に影響を与えていない。
- 覗き穴結合とは?
- CEC 自身の値に、重み行列を介して伝播可能にした構造。
GRU
- LSTM の課題
- LSTM では、パラメータ数が多く、計算負荷が高くなる問題があった。
- ⇒GRU
- LSTM では、パラメータ数が多く、計算負荷が高くなる問題があった。
- GRU とは?
- 従来の LSTM では、パラメータが多数存在していたため、計算負荷が大きかった。しかし、GRU では、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった構造。
- メリット
- 計算負荷が低い。
コード
python
import numpy as np
from my_functions import sigmoid #シグモイド関数
class GRU:
def __init__(self, Wx, Wh, b):
'''
Wx: 入力x用の重みパラメータ(3つ分の重みをまとめたもの)
Wh: 隠れ状態h用の重みパラメータ(3つ分の重みをまとめたもの)
b: バイアス(3つ分のバイアスをまとめたもの)
'''
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
"""
順伝播計算
"""
Wx, Wh, b = self.params
N, H = h_prev.shape
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
bhz, bhr, bhh = b[:H], b[H:2 * H], b[2 * H:]
z = sigmoid(np.dot(x, Wxz) + np.dot(h_prev, Whz) + bhz)
r = sigmoid(np.dot(x, Wxr) + np.dot(h_prev, Whr) + bhr)
h_hat = np.tanh(np.dot(x, Wxh) + np.dot(r * h_prev, Whh) + bhh)
h_next = z * h_prev + (1 - z) * h_hat
self.cache = (x, h_prev, z, r, h_hat)
return h_next
def backward(self, dh_next):
"""
逆伝播計算(省略)
"""
return dx, dh_prev
系列変換モデル
Seq2Seq
- Seq2seq とは?
- Encoder-Decoder モデルの一種を指す。
- 1文の一問一答に対して処理ができる、ある時系列データからある時系列データを作り出すネットワーク
- Seq2seq の具体的な用途とは?
- 機械対話や、機械翻訳などに使用されている。
Encoder RNN
- ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造。
- Taking:文章を単語等のトークン毎に分割し、トークンごとの ID に分割する。
- Embedding :ID から、そのトークンを表す分散表現ベクトルに変換。
- Encoder RNN :ベクトルを順番に RNN に入力していく。
- vec1 を RNN に入力し、hidden state を出力。この hidden state と次の入力 vec2 をまた RNN に入力してきた hidden state を出力という流れを繰り返す。
- 最後の vec を入れたときの hidden state を final state としてとっておく。この final state が thought vector と呼ばれ、入力した文の意味を表すベクトルとなる。
Decoder RNN
- システムがアウトプットデータを、単語等のトークンごとに生成する構造。
- Decoder RNN:Encoder RNN の final state (thought vector) から、各 token の生成確率を出力していきます final state を Decoder RNN の initial state ととして設定し、Embedding を入力。
- Sampling: 生成確率にもとづいて token をランダムに選ぶ。
- Embedding:
2で選ばれた token を Embedding して Decoder RNN への次の入力とする。 - Detokenize:
1-3を繰り返し、2で得られた token を文字列に直す。
HRED
- Seq2seq の課題
- 一問一答しかできない
- 問に対して文脈も何もなく、ただ応答が行われる続ける。
- 一問一答しかできない
- HRED とは?
- 過去 n-1 個の発話から次の発話を生成する。
- Seq2seq では、会話の文脈無視で、応答がなされたが、HRED では、前の単語の流れに即して応答されるため、より人間らしい文章が生成される。
- Seq2Seq+ Context RNN
- Context RNN: Encoder のまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造。
- 過去の発話の履歴を加味した返答をできる。
- Context RNN: Encoder のまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造。
- 過去 n-1 個の発話から次の発話を生成する。
- HRED の課題
- HRED は確率的な多様性が字面にしかなく、会話の「流れ」のような多様性が無い。
- 同じコンテキスト(発話リスト)を与えられても、答えの内容が毎回会話の流れとしては同じものしか出せない。
- HRED は短く情報量に乏しい答えをしがちである。
- 短いよくある答えを学ぶ傾向がある。
- HRED は確率的な多様性が字面にしかなく、会話の「流れ」のような多様性が無い。
VHRED
- VHRED とは?
- HRED に、VAE の潜在変数の概念を追加したもの。
- HRED の課題を、VAE の潜在変数の概念を追加することで解決した構造。
- HRED に、VAE の潜在変数の概念を追加したもの。
VAE
オートエンコーダー(自己符号化器)
- オートエンコーダとは?
- 教師なし学習の一つ。 そのため学習時の入力データは訓練データのみで教師データは利用しない。
- オートエンコーダ具体例
- MNIST の場合、28x28 の数字の画像を入れて、同じ画像を出力するニューラルネットワークということになります。
- オートエンコーダ構造説明
- 入力データから潜在変数 z に変換するニューラルネットワークを Encoder 逆に潜在変数 z をインプットとして元画像を復元するニューラルネットワークを Decoder。
- メリット
- 次元削減が行えること。
Attention Mechanism
- seq2seq の課題: 長い文章への対応が難しい
- 文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく、仕組みが必要になる。
- 「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み。
- Attention というメカニズムによって、必要な情報だけに「注目」を向けさせることができます。
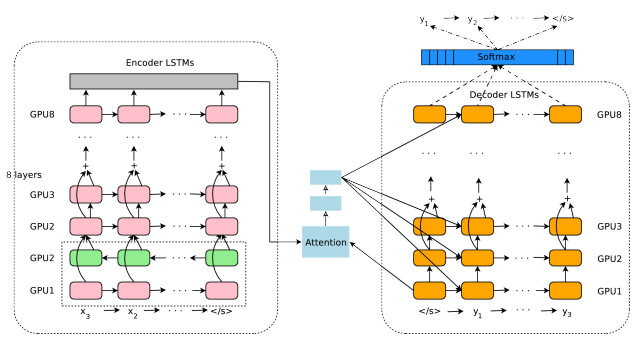
GNMT(Google Neural Machine Translation)
- 8層のエンコーダと8層のデコーダ層からなる深層 LSTM ネットワーク
- エンコーダの1層目は bi-LSTM、2~8層目は LSTM。3~8層目は Residual Connection。
- デコーダの1~8層目は LSTM。3~8層目は Residual Connection。
- アテンションには、エンコーダ側の最上層(第8層)とデコーダ側の最下層(第1層)を入力にしている。
- デコーダ側の最下層(第1層)を基にアテンションの計算を行うと、デコーダ側の2~8層に入力として使用される。
- 転移学習も進められており、ポルトガル語 ⇒ 英語、英語 ⇒ スペイン語のモデルから、ポルトガル ⇒ スペイン語の学習を行わず機械学習ができたと報告されている。(ゼロショット学習)
Discussion