ソラカメで撮影した画像をAWSのサービスで解析する!
やりたいこと
ソラカメで撮影した画像をAWSのサービスを使って解析して表示する!

構成はこんな感じ

準備
必要なもの
- SORACOM アカウント
- ソラカメ関連
- ソラカメ(AtomCam2)
- Wifi環境
- ソラカメライセンス(常時録画ライセンス 7日間プラン)
ソラカメが初めての方はこちら(購入から設置まで)!
SORACOMのアカウント作成など
カバレッジタイプはJPで。
ソラカメの購入〜セットアップまで
実は最近はソラカメのセットアップにアプリを使わなくても良くなっていたりする。
ソラカメの設置
設置に関する知見はここにたくさん溜まっています。
- AWSアカウント
- Wordpressの環境
カメラチェック
何はともあれ、カメラが正常に動作しているか確認しましょう。
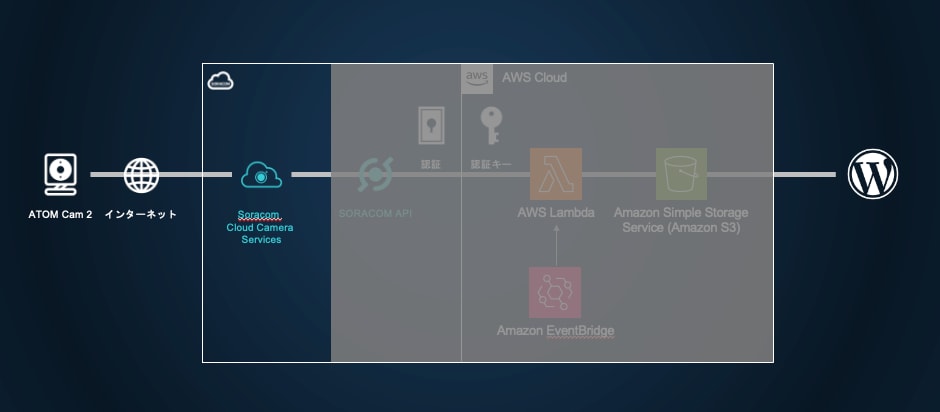
「ソラコムクラウドカメラサービス」 -> 「デバイス管理」
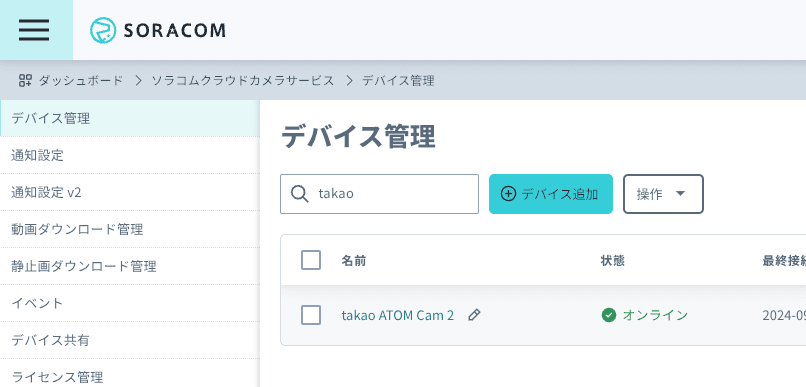
デバイスの一覧表示で、先ほど登録したカメラがオンラインになっていることを確認します。
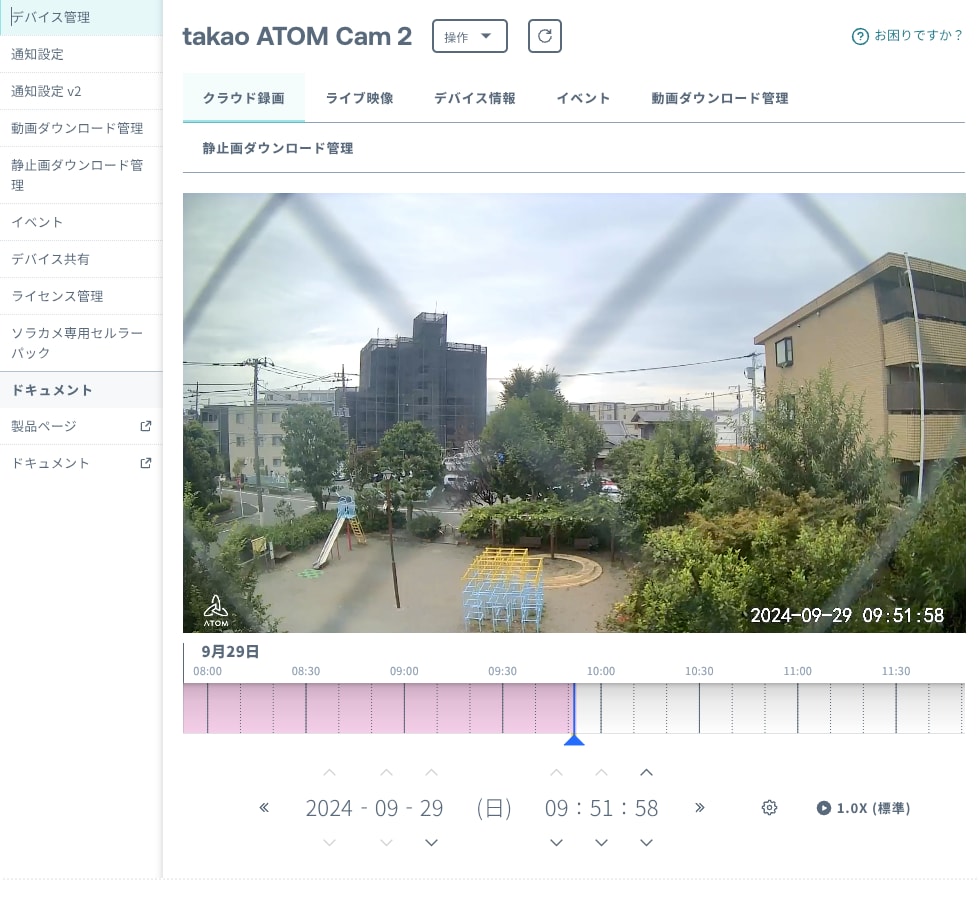
さらに、カメラの名前をクリックすると、カメラの映像が表示されます。
SORACOM APIキーを発行する
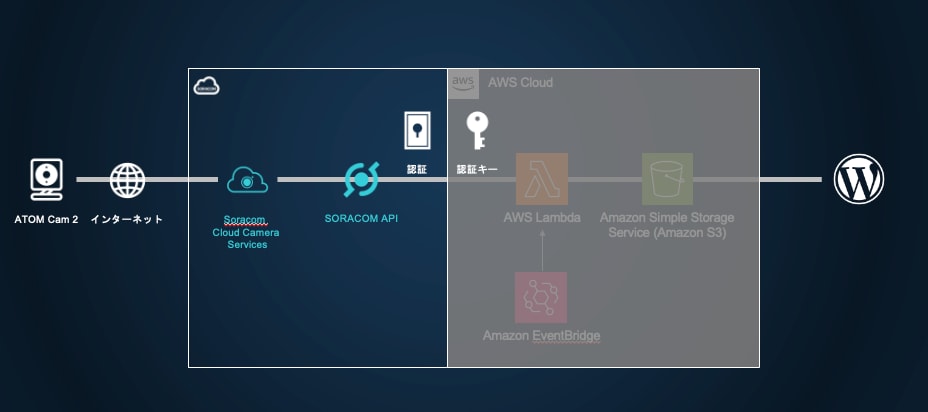
ソラカメの録画データから画像を取得するために、SORACOM APIを利用します。
APIを利用するためには、APIキーを発行する必要がありますので、以下の手順でAPIキーを発行しましょう。
-
右上のログインしているユーザー名(ルートユーザーであればメールアドレス、SAMユーザーであればSAMユーザー名)をクリックして出てくるメニューから、「セキュリティ」をクリック
-
「ユーザー」タブで「SAMユーザー作成」をクリック
-
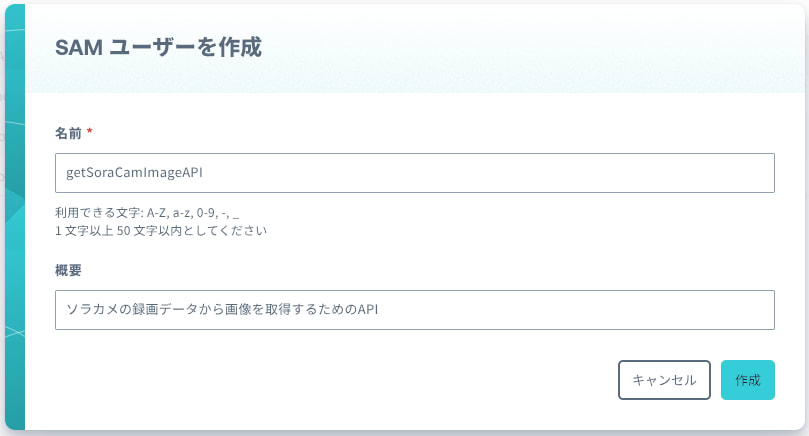
後で見たときに何をするためのSAMユーザーかわかるように名前をつけます。必要に応じて概要にも記載して「作成」をクリックします。
-
作ったSAMユーザーが一覧に表示されていることを確認して、名前をクリックします。
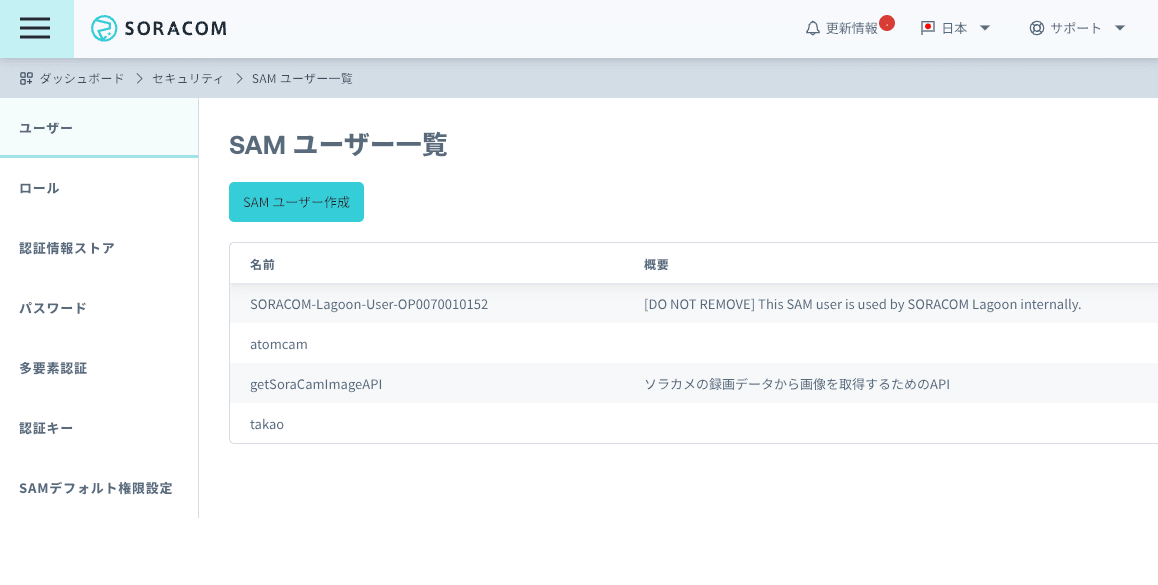
-
権限を設定します。
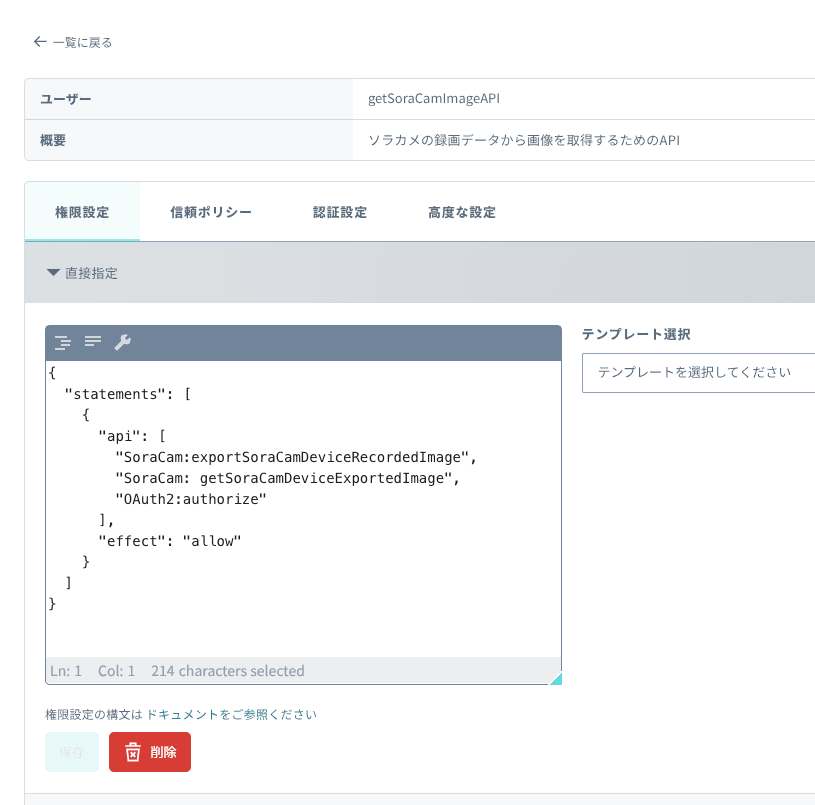
直接指定で以下をコピペしてください。{ "statements": [ { "api": [ "SoraCam:exportSoraCamDeviceRecordedImage", "SoraCam:getSoraCamDeviceExportedImage", "OAuth2:authorize" ], "effect": "allow" } ] } -
「認証設定」のタブに移り、「認証キーを生成」作成します。
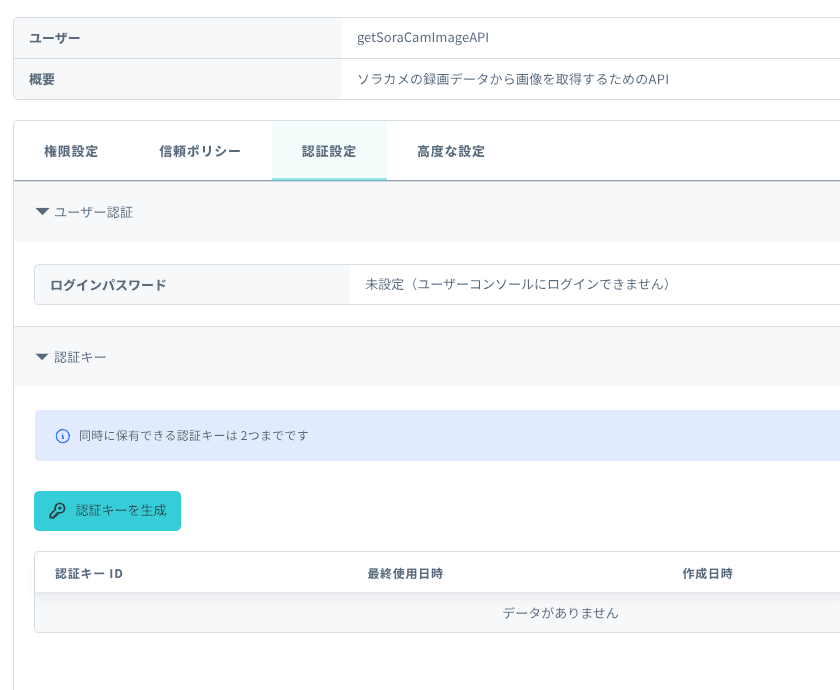
-
生成された認証キーをメモ帳などにコピーして保存しておきます。
画面を閉じてしまうと再度表示されないので注意してください。
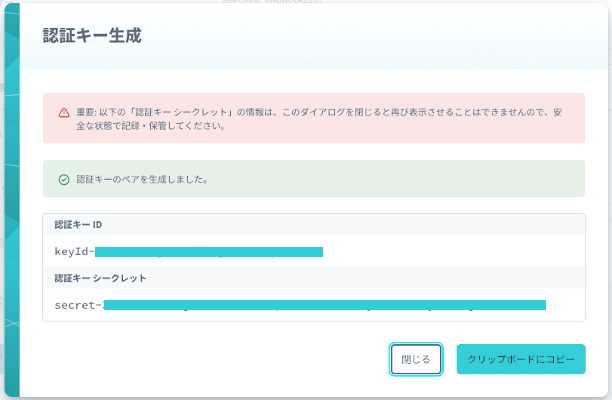
S3のバケットを作成する

ソラカメの録画データから取得した画像を保存するためのS3バケットを作成します。
-
AWSマネジメントコンソールにログインし、S3を開きます。

-
「バケットを作成」をクリックします。

-
バケットタイプ:汎用、バケット名:任意の名前(例:soracam-image-bucket等。世界に一つだけの特別なオンリーワンの名前)を設定

-
オブジェクト所有者:ACL無効、「パブリックアクセスをすべてブロック」のチェックボックスを外し、warningのチェックボックスをいれます。

-
その他の項目はデフォルトのままにして「バケットを作成」をクリックします。

-
作成したバケットをクリックし、バケットのプロパティを確認します。


-
画像を保存しておくための「live-camera」フォルダを作成します。


「フォルダの作成」をクリックします。

-
バケットのプロパティの「アクセス許可」タブをクリックし、バケットポリシーの編集ボタンをクリックします。

-
パケットポリシーをポリシーの編集欄に以下のように設定します。

以下のJSONをコピペして、バケット名の部分を設定したものに書き換えましょう。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::世界に一つだけのバケット名/live-camera/*" } ] }保存して閉じます。
Lambda関数を作成する
SORACOM APIの認証を行い、ソラカメの録画データから画像を取得し、S3に保存するLambda関数を作成します。

ソラカメの録画データから画像を取得するためのLambda関数を作成します。
-
AWSマネジメントコンソールにログインし、Lambdaを開きます。
-
「関数の作成」をクリックします。

-
「一から作成」を選択、「関数名」を入力し、「ランタイム」は「Python 3.12」アーキテクチャは「arm」を選択し、「関数の作成」をクリックします。

-
関数のページに遷移したら、

-
「コードソース」に以下のコードをコピペします。
import json import os import time import datetime import urllib.request import urllib.parse import boto3 # 環境変数の取得 AUTH_KEY_ID = os.environ['authKeyId'] AUTH_KEY = os.environ['authKey'] DEVICE_ID = os.environ['device_id'] S3_BUCKET = 'バケット名' S3_FOLDER = 'live-camera' def lambda_handler(event, context): try: # 1. 認証してAPIキーとトークンを取得する auth_response = authenticate() api_key = auth_response['apiKey'] api_token = auth_response['token'] # 2. 画像のエクスポートをリクエストする export_id = request_image_export(api_key, api_token) # 3. エクスポートの進捗を確認する image_url = check_export_status(api_key, api_token, export_id) # 4. S3に画像を保存する save_image_to_s3(image_url) return { 'statusCode': 200, 'body': json.dumps('Image successfully saved to S3') } except Exception as e: return { 'statusCode': 500, 'body': json.dumps(f'Error: {str(e)}') } # 認証を行い、APIキーとトークンを取得 def authenticate(): url = 'https://api.soracom.io/v1/auth' headers = { 'Content-Type': 'application/json' } data = json.dumps({ 'authKeyId': AUTH_KEY_ID, 'authKey': AUTH_KEY }).encode('utf-8') req = urllib.request.Request(url, headers=headers, data=data, method='POST') with urllib.request.urlopen(req) as response: if response.status != 200: raise Exception(f'Authentication failed: {response.status}') return json.loads(response.read().decode('utf-8')) # 画像エクスポートをリクエストする def request_image_export(api_key, api_token): url = f'https://api.soracom.io/v1/sora_cam/devices/{DEVICE_ID}/images/exports' headers = { 'Content-Type': 'application/json', 'X-Soracom-API-Key': api_key, 'X-Soracom-Token': api_token } current_time = int(time.time() * 1000) # 現在のUNIXタイムスタンプ(ミリ秒) data = json.dumps({'time': current_time}).encode('utf-8') req = urllib.request.Request(url, headers=headers, data=data, method='POST') with urllib.request.urlopen(req) as response: if response.status != 200: raise Exception(f'Image export request failed: {response.status}') export_response = json.loads(response.read().decode('utf-8')) return export_response['exportId'] # エクスポートの進捗を確認する def check_export_status(api_key, api_token, export_id): url = f'https://api.soracom.io/v1/sora_cam/devices/{DEVICE_ID}/images/exports/{export_id}' headers = { 'Content-Type': 'application/json', 'X-Soracom-API-Key': api_key, 'X-Soracom-Token': api_token } retry_intervals = [1, 2, 4] # リトライの間隔 for interval in retry_intervals: req = urllib.request.Request(url, headers=headers, method='GET') with urllib.request.urlopen(req) as response: if response.status != 200: raise Exception(f'Check export status failed: {response.status}') status_response = json.loads(response.read().decode('utf-8')) # エクスポートが完了した場合はURLを返す if status_response['status'] == 'completed': return status_response['url'] # エクスポートが完了していない場合はリトライ time.sleep(interval) raise Exception('Image export not completed within allowed retries') # 画像をS3に保存する def save_image_to_s3(image_url): # 画像データを取得 req = urllib.request.Request(image_url, method='GET') with urllib.request.urlopen(req) as response: if response.status != 200: raise Exception(f'Failed to download image: {response.status}') image_data = response.read() # S3オブジェクト名を作成 (JST時刻) jst = datetime.timezone(datetime.timedelta(hours=9)) current_time = datetime.datetime.now(jst) object_name = current_time.strftime('%Y%m%d_%H%M.jpg') # S3に画像をアップロード s3_client = boto3.client('s3') s3_client.put_object( Bucket=S3_BUCKET, Key=f'{S3_FOLDER}/{object_name}', Body=image_data, ContentType='image/jpeg' ) -
環境変数を設定します。
設定タブをクリックし、「環境変数」をクリックした後、「編集」をクリックして以下の環境変数を設定します。

- authKeyId: 先ほど発行したSORACOM APIキーのID
- authKey: 先ほど発行したSORACOM APIキー
- device_id: ソラカメのデバイスID

-
入力したら、「保存」をクリックします。
-
「一般設定」タブをクリックし、「編集」をクリックして、タイムアウトを20秒に設定します。

-
「アクセス権限」タブをクリックし、「ロール名」をクリックして、ロールの編集画面に遷移します。

-
「許可を追加」をクリックし、「インラインポリシーを作成」をクリックします。

-
「JSON」をクリックし、以下のポリシーをコピペして「ポリシーの作成」をクリックします。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::世界に一つだけのバケット名/live-camera/*" } ] }
-
「ポリシーの作成」をクリックします。

-
「Deploy」をクリックして、Lambda関数をデプロイします。
-
「Test」をクリックして、適切なイベント名を入力してテストイベントを保存します。
(イベントJSONは編集不要です。)

-
「呼び出す」をクリックして、Lambda関数が正常に動作するか確認します。
以下のような表示が出てれば成功です。

画像をS3に保存するLambda関数を定期実行するEventBridgeルールを作成する
定期的にSORACOM APIを呼び出して画像を取得し、S3に保存するためのEventBridgeルールを作成します。
ついにすべての準備が整います。

-
関数のページから、「トリガーを追加」をクリックします。

-
「トリガーの追加」画面で、「イベントソースの選択」をクリックし、「Event Bridge(CloudWatch Events)」を選択します。

-
「新規ルールの作成」を選択し、「ルール名」を入力し、「スケジュール式」を入力し追加します。
例:rate(1 minute)(1分ごとに実行)


S3に保存された画像をwebアプリで表示する
-
下記からアプリ(zipファイル)をダウンロードします。
https://github.com/takao2704/public-zenn-docs/raw/refs/heads/main/files/soracam-viewer.zip -
AWS Amplifyを開きます。

-
アプリをデプロイしていきます。
「新しいアプリを作成」から「Gitなしでデプロイ」を選択して「次へ」。

-
zipファイルをアップロード
アプリケーションの名称(任意)を設定して、「ドラッグアンドドロップ」からファイルを選択してアップロードし、「保存してデプロイ」。
(1.のURLを直入力してもOKです。) -
デプロイが完了したら、URLをクリックしてアプリケーションにアクセスします。
-
S3バケット名とプレフィックスを入力して「表示」ボタンをクリックしたら画像が表示されることを確認します。
上段の枠内に画像が表示されたら成功です(下段はこれから作り込んでいきますのでまだ表示されません)

ソラカメの画像をAmazon Rekognitionで解析する
-
AWSマネジメントコンソールからLambda関数を作成
- ランタイム:
Python 3.13 - アーキテクチャ:
arm64
- ランタイム:
-
コードの追加
- 下記のLambda関数のコードをコピーペーストで貼り付け
import json
import boto3
import os
import urllib.parse
from datetime import datetime
from io import BytesIO
from PIL import Image, ImageDraw, ImageFont
# Python 3.13 ARM64用に最適化
# AWS サービスクライアントの初期化
REGION = 'ap-northeast-1' # 東京リージョン
s3_client = boto3.client('s3', region_name=REGION)
rekognition_client = boto3.client('rekognition', region_name=REGION)
# 環境変数
MIN_CONFIDENCE = float(os.environ.get('MIN_CONFIDENCE', 70.0)) # デフォルト信頼度閾値: 70%
OUTPUT_PREFIX = os.environ.get('OUTPUT_PREFIX', 'analyzed-images/') # 出力先ディレクトリ
# フォントサイズの設定
LABEL_FONT_SIZE = 24 # ラベルリスト用フォントサイズ
BOX_FONT_SIZE = 20 # バウンディングボックス用フォントサイズ
def lambda_handler(event, context):
try:
# S3イベントからバケット名とオブジェクトキーを取得
bucket = event['Records'][0]['s3']['bucket']['name']
object_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
print(f"Processing image: {object_key} from bucket: {bucket}")
# 画像の完全なS3パスを生成
s3_path = f"https://{bucket}.s3.{REGION}.amazonaws.com/{object_key}"
# S3から画像を取得
response = s3_client.get_object(Bucket=bucket, Key=object_key)
image_content = response['Body'].read()
# Rekognitionでラベル検出
rekognition_response = rekognition_client.detect_labels(
Image={
'S3Object': {
'Bucket': bucket,
'Name': object_key
}
},
MinConfidence=MIN_CONFIDENCE
)
# Rekognitionの結果を詳細にログ出力
print(f"Rekognition結果全体: {json.dumps(rekognition_response, indent=2, default=str)}")
# ラベルごとにInstancesの有無を確認
for label in rekognition_response['Labels']:
label_name = label['Name']
confidence = label['Confidence']
instances_count = len(label.get('Instances', []))
print(f"ラベル: {label_name}, 信頼度: {confidence:.1f}%, Instances数: {instances_count}")
# Instancesがある場合は詳細をログ出力
if instances_count > 0:
for i, instance in enumerate(label['Instances']):
if 'BoundingBox' in instance:
box = instance['BoundingBox']
print(f" Instance {i+1}: BoundingBox = {box}")
# PILで画像を開く
image = Image.open(BytesIO(image_content))
draw = ImageDraw.Draw(image)
# フォントの設定
# 古いPILバージョンとの互換性のため、try-exceptで処理
try:
# 新しいバージョンのPIL
label_font = ImageFont.load_default(size=LABEL_FONT_SIZE)
box_font = ImageFont.load_default(size=BOX_FONT_SIZE)
except TypeError:
# 古いバージョンのPIL - サイズ指定なしのデフォルトフォント
print("Warning: Using default font without size specification")
label_font = ImageFont.load_default()
box_font = ImageFont.load_default()
# 画像の幅と高さを取得
width, height = image.size
# 検出されたラベルとバウンディングボックスを描画
for label in rekognition_response['Labels']:
label_name = label['Name']
confidence = label['Confidence']
# バウンディングボックスがある場合は描画
for instance in label.get('Instances', []):
if 'BoundingBox' in instance:
box = instance['BoundingBox']
left = int(box['Left'] * width)
top = int(box['Top'] * height)
box_width = int(box['Width'] * width)
box_height = int(box['Height'] * height)
# 矩形を描画
draw.rectangle(
[(left, top), (left + box_width, top + box_height)],
outline='red',
width=3
)
# ラベル名と信頼度を描画
text = f"{label_name}: {confidence:.1f}%"
draw.text((left, top - 30), text, fill='red', font=box_font)
# 画像の上部に検出されたラベルの一覧を表示
y_position = 10
for label in rekognition_response['Labels']:
label_name = label['Name']
confidence = label['Confidence']
text = f"{label_name}: {confidence:.1f}%"
draw.text((10, y_position), text, fill='blue', font=label_font)
y_position += LABEL_FONT_SIZE + 10 # フォントサイズに合わせて間隔を調整
# 処理済み画像をバイトストリームに変換
output_image = BytesIO()
image.save(output_image, format='JPEG')
output_image.seek(0)
# 出力先のオブジェクトキーを生成
filename = object_key.split('/')[-1]
output_key = f"{OUTPUT_PREFIX}{filename}"
# 処理済み画像をS3にアップロード
s3_client.put_object(
Bucket=bucket,
Key=output_key,
Body=output_image,
ContentType='image/jpeg'
)
print(f"Processed image saved to: {output_key}")
return {
'statusCode': 200,
'body': json.dumps(f'Successfully processed image {object_key} and saved to {output_key}')
}
except Exception as e:
print(f"Error: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f'Error processing image: {str(e)}')
}
-
Pillowレイヤーの追加
- ZIPファイルをダウンロード
https://github.com/takao2704/public-zenn-docs/raw/refs/heads/main/files/pillow-layer.zip - 提供されたZIPファイル(
pillow-layer.zip)を使用して、カスタムレイヤーを作成

- 作成したレイヤーをLambda関数に追加
関数の設定画面の「コード」タブを開き、一番下までスクロールしてレイヤーの追加をクリック

- ZIPファイルをダウンロード
-
環境変数の設定
-
MIN_CONFIDENCE:70.0 -
OUTPUT_PREFIX:analyzed-images/S3に解析後の画像を保存する際のプレフィックス(ディレクトリ名)
-
-
メモリとタイムアウトの設定
- メモリ:
256 MB - タイムアウト:
30 秒
- メモリ:
-
IAMロールの設定
Lambda関数のIAMポリシーを更新して、S3とRekognitionへのアクセスを許可します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": "arn:aws:s3:::your-bucket-name/*" }, { "Effect": "Allow", "Action": [ "rekognition:DetectLabels" ], "Resource": "*" } ] } -
S3のバケットポリシーの更新
解析後の画像へアクセスできるように修正します。対象のプレフィックスを追加します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": [ "arn:aws:s3:::世界に一つだけのバケット名/live-camera/*", "arn:aws:s3:::世界に一つだけのバケット名/analyzed-images/*" ] } ] } -
S3のトリガーの設定
- lambda関数のトリガーを追加
- S3を選択
- バケット名を選択
- イベントタイプを「すべてのオブジェクト作成イベント」に設定
- プレフィックスに
live-camera/を指定 - サフィックスに
.jpgを指定 - 「保存」をクリック


画像を表示する
アプリに解析前と解析後の画像を表示する準備が整いました。
-
先ほどamplifyでデプロイしたアプリにアクセスします。
-
S3バケット名とプレフィックスを入力して「表示」ボタンをクリックします。
Discussion