SORACOMで送る充実のラーメンライフ
はじめに
この記事は SORACOM Advent Calendar 2024 の18日目の記事です。
17日目の記事は、@n_mikuniさんのM5StickC PLUS・SORACOM・Alexaでゴミ捨て忘れを防止するでした。わたしも今年になってマンション(賃貸)から戸建て(中古)に引っ越したのでゴミ捨て忘れの問題は切実です。
さて、みなさんこんにちは三度の飯よりラーメンが好きなソリューションアーキテクトの井出です。
ちゃんとラーメン、食べてますか!?私はご多分に漏れずちゃんと食べています。
ふと、今年1年のスマートフォンに同期しているgoogle photo のラーメン画像を振り返ってみるとこんな感じになっていました。



ラーメン屋さんに行くとなると外出をしなければなりません。しかしながら、ソラコムは基本的にリモートワークのためあまり外出する機会が多くありません。
私は常々この貴重な外出の機会に後悔のないラーメンを食べたいと思っています。
このブログではSOARACOMとともに充実のラーメンライフを送る方法を3つご紹介します。
方法1. SORACOM UGに行く
SORACOM UGは読んで字のごとくSORACOMのユーザーグループのことで、業種や職業問わず、IoTやIoTプラットフォーム SORACOMについて関心を持った方、既に利用されている方、これからIoTを始める方が誰でも参加することが出来るコミュニティです。
日本全国、各地域別に活動されていてほぼ毎月どこかの地域(またはオンラインで)開催されます。と、いうことはこのイベントに参加することで、その地域の美味しいラーメンを食べることができるのです。
事実、私は2024年に開催されたUGのうち、以下のイベントに参加しました。
その時食べたラーメンとともに振り返ってみましょう
| 日付 | イベント名 | 場所 | ラーメン |
|---|---|---|---|
| 5/18 | SORACOM UG 四国 in 高松 | 高松 | |
| 7/26 | SORACOM UG 九州 #14 | 福岡 |  |
| 9/7 | 四国クラウドお遍路 2024 in 高知 & SORACOM UG四国 共催 | 高知 |  |
| 9/13 | SORACOM UG 東北 #1 in 秋田 | 秋田 |  |
| 9/14 | SORACOM UG 東北 #2 in 岩手 + JAWS-UG いわて共同開催 | 岩手 | |
| 11/2 | (仙台会場)SORACOM UG Explorer 2024 〜HUB-ing FUN! | 仙台 |  |
あれ、高松と岩手はラーメンの画像がないですね。どうなってるんや!!とお怒りの皆さん。
実は私、その場所でラーメンよりも推奨されている麺類があればまずはそちらを食べることにしています。
したがって、うどん県高松ではラーメンではなくうどんを4杯頂いています。この通り!

また、盛岡では皆さん御存知の三大麺(じゃじゃ麺、冷麺、わんこそば)をコンプリートしました。

ちなみに、わんこそばの記録は140杯で、これはちゃんとトレーニングすればもっと記録が伸ばせそうな手応えを得たので、また機会があれば挑戦した気持ちはありますが、次に盛岡に行ったときはラーメンを食べることにしたいと思っています。
来年もSORACOM UGに参加して美味しいラーメンを食べることと皆さんにお会いできることを楽しみにしています!
方法2. ソラコムに入社する、そして出社する
UGは土日祝日に開催されることが多いため、ご家庭の事情などで遠方での参加が難しい方もいらっしゃるでしょう。
そんな方におすすめなのがソラコムに入社することです。
前述の通り、ソラコムはリモートワークがメインとなるため一見あまり効率の良い方法ではないのですが、ソラコムに入社することでソラコムのオフィスに行く機会が増えます。
オフィスの所在地である赤坂見附近辺は美味しいラーメン屋さんが多いことで有名です。
つまり、ソラコムに入社することで出社の際には必ず美味しいラーメンを食べることができるということです。
赤坂見附で私がよく行くラーメン屋さんをご紹介します。
| No. | 店名 | ジャンル | ラーメン |
|---|---|---|---|
| 1 | 希須林 | 担々麺 |  |
| 2 | 一点張 | 札幌味噌ラーメン |  |
| 3 | 一刀家 | 横浜家系 |  |
| 4 | 和 | 博多とんこつ |  |
| 5 | 天下一品 | 天一 |  |
このラーメン屋さんはどれも美味しいので、ランチタイムに行くと並ぶことが多くあります。
このためこれらのラーメン屋さんのどれかに入れればいいなと思ってランチタイムに赤坂見附周辺を歩く際のルーティーンルートを作りましたので公開させていただきます。

スタート地点は赤坂見附の駅にしています。これは午後出社の際に赤坂見附駅に到着してから昼食を取ってからオフィスに出社することができるように設定しています。という話と、午前中からオフィスにいた場合ちょっと大回りになってしまいますが、このあとラーメンを食べるわけなのでその準備運動として適切な運動をするためにこのようなルートを設定しています。
順序は前述のよく行くラーメン屋さんの表の順番と同じにしてあります。座席数やラーメンの種類などにより待ち時間が概ね長い順だと思っていただいても差し支えありません。
これだけだったらソラコムと協業してソラコムのオフィスにご来訪いただく機会を増やすだけでもいいのでは?と思うかもしれません。
もちろんそういった方法も大歓迎ですし、そのときはぜひSPS(SORACOM Partner Space)
にご登録いただければと思うのですが、入社がおすすめな理由はそれ以外にもあります。
ソラコムはコミュニケーションツールにslackを使っていて、slackには「#_ニックネーム」というtimesのようなチャンネルと「#ramen」チャンネルがあります。
「#_ニックネーム」にはかくメンバーの日々の生活が投稿されていて、その中にはその日にラーメンの画像やそれにまつわるポエムを投稿するメンバーも多くいます。
slackをお使いの方はご存知かと思いますが、reacji channeler という機能があり、ソラコム社内のslackでは誰かの投稿に「🍜」のreacjiで反応すると自動的にその投稿が「#ramen」に転送される仕組みになっていて、このチャンネルを購読していればソラコム社内に飛び交う無数のラーメン情報を効率よく手に入れることができます。
ある日の「#ramen」チャンネルの投稿は以下の通りです。

このように、reacji channeler により「#ramen」チャンネルに研修報告が転送されています。また、社員同士で一緒にラーメンを食べに行く待ち合わせのやり取りなどもされていることがわかると思います。
こういう感じでソラコムには充実のラーメンライフを送っているメンバーが多数います。
方法3. GPSマルチユニットとSORACOM Fluxを使ってラーメンの位置情報を取得する
べつに今の仕事を辞めてまでラーメンを食べるためにソラコムに入社する必要はないと思う方もいらっしゃるかと思います。
そんな方でも出先でラーメン屋さんを探す作業をもう少し効率てきにやりたいと思っている方は多いのではないでしょうか?
そんな方におすすめなのがGPSマルチユニットとSORACOM Fluxを使ってラーメンの位置情報を取得する方法です。このセクションではその具体的な方法についてご紹介します。
アドカレの技術ブログとしてはここからが本題です。
準備
- SORACOM アカウント
- GPSマルチユニットSORACOM Edition(バッテリー内蔵タイプ)スターターキット
- kintone
- slack
手順
1. GPSマルチユニットをセットアップします。
STEP 2: GPS マルチユニットに IoT SIM を挿入する
STEP 3: SORACOM ユーザーコンソールに GPS マルチユニット SORACOM Edition を登録する
STEP 4: 動作モードを SORACOM ユーザーコンソールで設定する
2. グループ設定をいじる
先ほど作成したグループで「SORACOM Air for セルラー設定」から

「バイナリパーサー」のトグルスイッチをONしてフォーマットに@gpsmultiunitを入力して保存します。

3. ラーメンDBを作る
食べログをスクレイピングして最強のラーメンDBを作ります。
スクレイピングのコードはこちらを用います。 中身は難しくないのでこのブログでの解説は割愛します。コメントを付けてあるので読んでみてください。
requirements.txtを参考に必要なライブラリをインストールした環境をご用意し実行ください。
このコードを実行すると食べログのラーメン百名店のデータがCSV形式で出力されます。
なお、ラーメン百名店は東京・大阪・東日本・西日本と4部門に別れているので、全部で400名店分のデータが出力されます。
次に、このCSVをkintoneにインポートします。
アプリストアから、CSVを読み込んで作成を選択して、ガンガン読み込んでいきます。


スクレイピングスクリプトが吐き出したcsvを選択して、インポートしていきます。
プレビューを見ながら文字コードを適切に選択しましょう。

できたら作成ボタンを押してアプリを作成します。

簡単ですね。これでラーメンの名店DBにクエリを投げる準備が整いました。
各フィールドの名称を半角英数字にしておきます。
今回のブログは各フィールドを以下のようなフィールドコードに設定しています。
| フィールド名 | フィールドコード |
|---|---|
| 店名 | name |
| エリア | station |
| 定休日 | teikyubi |
| 住所 | address |
| リンク | link |
APIトークンを発行します。
アプリの設定からAPIトークンを発行します。

今回は閲覧の権限のみを付与します。

これらの設定は、保存して「アプリの更新までやっておかないと反映されないので忘れずにやっておきましょう」

400名店のデータベースにクエリwebAPIでクエリが投げられるようになりました。
4. SORACOM Fluxのロジックを作成する
実はこのアプリ、8月頃から作り始めて9月のJAWS UG + SORACOM UG四国で軽く発表したものを今回大幅アップデートしました。
9月時点では、こんな感じのシンプルなものだったのですが、

何度もフィールドテストを重ねて、今回このような形になっています。じゃーん!

おそらくここまでfluxアプリを作り込んだ人は私の他にはほぼいないのではないかと思います。
それでは順番に見ていきます。
まずはじめの紫色のボックスが「GPSマルチユニットからのデータを受信する」ボックスです。これは先程セットアップしたGPSマルチユニットの所属するグループのunified endpointからデータを受信します。

その後、二手に分かれます。上段の分岐がどうなっているか見ていきましょう。
payload.lon == nullという条件式で、/v1/sims/${event.context.resource.simId}という、SORACOM APIを叩いています。これは、GPSマルチユニットからのデータに経度が含まれていない場合、基地局のIDから位置情報を割り出すための処理です。

したがって、この次のSORACOM APIアクションでは、
/v1/cell_locations?mcc=${payload.sessionStatus.cell.mcc}&mnc=${payload.sessionStatus.cell.mnc}&tac=${payload.sessionStatus.cell.tac}&eci=${payload.sessionStatus.cell.eci}
というGETリクエストが設定されています。まさにこれが、基地局のIDから位置情報を割り出すためのAPI処理です。
その次のrepublishアクションでは、unified endpointに来たGPSマルチユニットのデータと、基地局IDから割り出した位置情報をマージしています。

もともとはこの処理を入れていなかったのですが、私が普段生活している東京都内は地下鉄の移動も多く、駅降りてすぐに位置情報が手に入れられなければ電車を降りてすぐにラーメン屋さんに向かうことができません。
これでは困るので、なんとかして基地局IDから位置情報を割り出す方法を考えました。ただ、テストをして気付いたのですが、SORACOMプラットフォームが持っているセッションごとの基地局IDの情報はハンドオーバーなどでmodifiedとなる場合IDは更新されない作りになっています。
セッションのDelete/Createが発生するとIDは更新されるのですが、これのためにセッションを切りに行くというのはデバイスの電池消費の観点およびLTE網への負荷の観点からやるべきではない実装になります。
今後、GPS位置情報だけでなく基地局位置情報をデバイス側で取得し、ペイロードに乗せることができるデバイスを作れたときに改めて考えることにします。
下段の分岐については、デバイスからのデータが位置情報を含めて完全な状態できている場合の処理でそのままrepublishします。ただし、上川の分岐と排他的になるように、payload.lon != nullという条件式を設定しています。
この1段目のフローの最後にあるwebhookアクションでは2段目にあるAPI/マニュアル実行トリガーに割り当てたIncoming Webhook URLにPOSTリクエストを送信しています。
つまり、こういうことです。

このテクニックは現状のFluxで一度受け取ったデータを保持しつつ途中で取得した新しいデータと組み合わせってその後段で再利用しようと思った場合に使えるテクニックです。
それでは2段目のフローを見ていきます。

1段目の最後のwebhookのbodyの形式(=このトリガーに入ってくるbody)は以下のようなものになっています。
{
"devicedata": {
"lat": 35.75496,
"lon": 139.66188,
"bat": 3,
"rs": 0,
"temp": 25.6,
"humi": 37.1,
"x": 0,
"y": 64,
"z": -960,
"type": 0,
"binaryParserEnabled": true
},
"simdata": {
"resourceId": "44010xxxxxx52",
"resourceType": "Subscriber",
"imei": "3547xxxxxxxx145",
"imsi": "44010xxxxxxxx52",
"simId": "89811000xxxxxxxxxx5"
}
}
devicedataはGPSマルチユニットのペイロード相当のもの、simdataは一番はじめのIoTデバイストリガーのcontextに入っていたものです。contextには他に、グループ設定のメタデータや、デバイスタイプ、プロトコルタイプが書かれています。
eventのpayloadやcontextに入ったデータは、直後のアクションよりもさらに後段のアクションから参照できるようになります。今回、このような局面がいくつかあるので中間にwebhook アクションとIncoming Webhookを挟んでいきます。
続くSORACOM APIアクションはSIMのタグデータ取得を行うAPIです。
なぜこれを入れているかというと、SIMのタグ情報を書いたり読んだりすることで、ステートフルな動作を実現しようとしています。
ユーザーコンソールで言うと、SIM詳細のタグ情報のところです。これをFluxのAPIアクションで読み書きしていきます。

prev_locationと、prev_stationと、tsというタグを用意しています。これらをどう使うかは3段目のフローで説明します。
中段2段目はこのタグを読んで更に後段で再利用するためにまた、webhook アクションとIncoming Webhookを挟んでいきます。
3段目のフローを見ていきます。
大まかに説明すると、上半分が最寄り駅ベースで検索するフロー、下半分が位置情報から割り出した住所ベースで検索するフローになっています。

まず、最初のwebhookが何をしているか見てみましょう。
このAPIトリガーの次の分にあるwebhookアクションです。

URLには以下のようなアドレスとパラメータが設定されています。
https://nominatim.openstreetmap.org/reverse?format=geojson&lat=${payload.devicedata.lat}&lon=${payload.devicedata.lon}&zoom=9
これは逆ジオコーディングを行うAPIです。
逆ジオコーディングとは、緯度経度から住所を割り出すことを意味します。このAPIはOpenStreetMapのNominatimというサーバーでホストされたAPIを使っています。
openstreetmapおよびこのAPIを提供しているnominatimは商用利用を禁止していませんが、高頻度の利用や大規模の利用(2024年12月時点の規約ではNo heavy uses (an absolute maximum of 1 request per second)とのことです)をする場合は商用サービスを利用するか、自前でサーバーを立てて利用することを推奨しています。
今回のような、1回線程度の規模でGPSマルチユニットからのデータの送信頻度を抑えた方法であれば特に問題と思いますが大規模で利用することを考える場合は注意しましょう。
APIの仕様はこちらのサイトのとおりです.
末尾に zoom=9というパラメータがついているのがわかると思いますが、これは日本だと都道府県レベルの精度で住所を返してくれるようになります。
つまり、最初の分岐では今どこの都道府県にいるのかを見ていることになります。400名店分のラーメンデータベースのうち、東京と大阪で100名店ずつあるので密度が異なります。
また、東京・大阪のデータベースには最寄り駅が書いてあり、夏から続くフィールドテストの結果、住所(市区町村や町名などの情報)で探すよりも最寄り駅ベースで探すほうが効率が良いことが確認できているためにこのような設計になっています。
この逆ジオコーディングAPIの結果は以下のようになります。
今回はこのレスポンスのうち、features[0].properties.address.provinceに必ず都道府県名が入ってくるのでその値を見て条件分岐を行います。
{
"type": "FeatureCollection",
"licence": "Data © OpenStreetMap contributors, ODbL 1.0. http://osm.org/copyright",
"features": [
{
"type": "Feature",
"properties": {
"place_id": 241348419,
"osm_type": "relation",
"osm_id": 1543125,
"place_rank": 8,
"category": "boundary",
"type": "administrative",
"importance": 0.82108616521785,
"addresstype": "province",
"name": "東京都",
"display_name": "東京都, 日本",
"address": {
"province": "東京都",
"ISO3166-2-lvl4": "JP-13",
"country": "日本",
"country_code": "jp"
}
},
"bbox": [
135.8536855,
20.2145811,
154.205541,
35.8984245
],
"geometry": {
"type": "Point",
"coordinates": [
139.7638947,
35.6768601
]
}
}
]
}
都道府県が東京または大阪の場合はまず、上段の最寄り駅ベースで検索するフローに入ります。
分岐後の先頭のwebhookアクションになります。

それでは最寄り駅検索のwebhookアクションの中を見てみましょう。

アクションの実行条件文を見ると東京都または大阪府だった場合にこのアクションが動く様になっています。
リクエストのURLは以下のとおりです。
https://www.heartrails-express.com/api/json?method=getStations&x=${event.payload.devicedata.lon}&y=${event.payload.devicedata.lat}
利用しているAPIはこちらのサイトのものです。
利用規約によるとこちらも商用利用は禁止されていませんが、osm同様、大規模な利用をする場合は有料プランを検討するよう記載があります。
今回は概念実証ということで、このAPIを利用していきます。
APIの仕様は、 の最寄駅情報取得 API になります。
リクエストパラメータ
| パラメータ | 値 | 説明 |
|---|---|---|
| method | getStations (固定) | メソッド名 |
| x | double (必須) | 最寄駅の情報を取得したい場所の経度 (世界測地系) |
| y | double (必須) | 最寄駅の情報を取得したい場所の緯度 (世界測地系) |
ということで、このフローの先頭で、GPSマルチユニットから緯度経度のデータをその前のフローから大事にうけついでいますので、そのデータを使って最寄り駅を検索しています。
今回は使いませんでしたが、路線に関する情報なども取れて便利そうです。
レスポンスの中に今いる地点からの最寄り駅が入っているのでこれをうまく使っていく必要があります。
どうやら概ね2キロ圏内にある駅が出てくるような挙動で、何個も出る場合もあれば、出ない場合もありそうです。
ここに出てくる駅は最大限活用したいなと思いつつも、これまで色々試してきたところFluxは可変の長さの配列を扱うことが非常に難しいので、ちょっともったいないですが、最寄り駅of最寄り駅のresponse.station[0] の情報だけを扱うことにします。
秋葉原あたりだと、いろんな線路が交錯しているのですが、この例だとTXの秋葉原が一番近かったということで、ラーメン屋さんの検索に使われる駅は秋葉原駅と、新御徒町駅になります。
もし少し位置を移動して日比谷線の秋葉原駅が最も近かった場合は、秋葉原駅と仲御徒町駅と小伝馬町駅の3つが使われることになります。
{
"response": {
"station": [
{
"name": "秋葉原",
"prefecture": "東京都",
"line": "つくばエクスプレス線",
"x": 139.774273,
"y": 35.698889,
"postal": "1010028",
"distance": "80m",
"prev": null,
"next": "新御徒町"
},
{
"name": "秋葉原",
"prefecture": "東京都",
"line": "東京メトロ日比谷線",
"x": 139.775459,
"y": 35.698162,
"postal": "1010027",
"distance": "140m",
"prev": "仲御徒町",
"next": "小伝馬町"
},
{
"name": "秋葉原",
"prefecture": "東京都",
"line": "JR京浜東北線",
"x": 139.773288,
"y": 35.698619,
"postal": "1010028",
"distance": "170m",
"prev": "御徒町",
"next": "神田"
},
{
"name": "秋葉原",
"prefecture": "東京都",
"line": "JR総武線",
"x": 139.773288,
"y": 35.698619,
"postal": "1010028",
"distance": "170m",
"prev": "御茶ノ水",
"next": "浅草橋"
},
{
"name": "秋葉原",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.773288,
"y": 35.698619,
"postal": "1010028",
"distance": "170m",
"prev": "御徒町",
"next": "神田"
},
{
"name": "岩本町",
"prefecture": "東京都",
"line": "都営新宿線",
"x": 139.775866,
"y": 35.695534,
"postal": "1010032",
"distance": "430m",
"prev": "小川町",
"next": "馬喰横山"
},
{
"name": "末広町",
"prefecture": "東京都",
"line": "東京メトロ銀座線",
"x": 139.771713,
"y": 35.702972,
"postal": "1010021",
"distance": "500m",
"prev": "神田",
"next": "上野広小路"
}
]
}
}
この次のrepublishアクションでは、最寄り駅とその前後の駅3駅を配列にして、次のアクションに渡すようにしています。


"stations" : ["${payload.response.station[0].name}","${payload.response.station[0].prev}","${payload.response.station[0].next}"]というやつがそれです。
その次は二股に分岐しています。
上段の分岐はkintoneの400名店DBアプリにクエリを投げるアクションです。
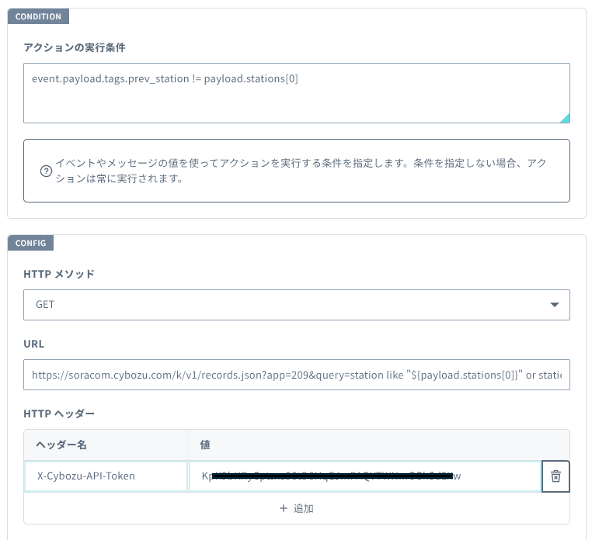
実行条件は、event.payload.tags.prev_station != payload.stations[0]となっておりAPIで取得した最寄り駅(先ほどrepublishアクションで作ったstationsという配列の最初の要素)がタグに書かれている前回の最寄り駅(タグに最寄り駅を書く処理はこの次で説明します)が異なる場合、つまり位置情報に変化があった場合にこのアクションが実行されるようにすることで同じ結果が連続で出力されることを抑制しています。
kintoneのAPIは、こちらのサイト
を参考にしています。
最初にkintoneへ設定したフィールドコードでこのようなクエリをつくります。最寄り駅とその両隣の駅に近い店舗が取得できるクエリです。
https://soracom.cybozu.com/k/v1/records.json?app=209&query=station like "${payload.stations[0]}" or station like "${payload.stations[1]}" or station like "${payload.stations[2]}" order by number asc limit 3
ヘッダーにはアプリのAPIトークンをヘッダ名X-Cybozu-API-Tokenで設定します。
分岐の下側はSORACOM APIアクションとなっています。

アクションの実行条件は先ほどと同じで、位置情報に変化があった場合に実行されるようにしています。
実行するSORACOM APIはsimのタグ情報を書き換えるputSimTagsAPIとなっています。
したがって位置情報に変化があった場合に新しい最寄り駅を上書きするということをやっています。と、同時にprev_lobationというタグも書き換えています。
というのも、今回のフローは東京・大阪の場合は最寄り駅を探しに行きますが、もし最寄り駅の近くにラーメン屋さんがなかった場合は同じ区や隣の区を住所ベースで探したい(このあとでその処理が登場します)ため、東京大阪であっても住所ベースの検索が発生する可能性もあるのでこのタイミングで古い住所prev_locationを書き換えています。
ここまでで最寄り駅ベースのラーメン店が400名店データベースから抽出できているはずなので、slackに投稿していきます。

クエリの結果は当然JSONなので、slackに投稿するためには整形が必要です。
が、先程も言ったようにFluxは長さが未知の配列を扱うのが尋常じゃなく難しいので、この処理はLLMの力を借ります。

アクションの実行条件はpayload.records[0] != nullとなっていて、これはkintoneが返してくるレコードが0でなければ、つまりどこかしらの店舗が見つかった場合にこのアクションが実行されるようになっています。
あとはプロンプトです。こうしました。
雑にkntoneが返してきた全部のレコードをつっこんで店名と食べログのリンクを並べてくれ、余計な飾りは取ってねということを伝えています。
以下のJSONを解釈し、
最寄り駅名
店名 食べログへのリンクURLのテキストの形式で出力してください。
ただし、
- "```"などの余計な装飾は不要です。
- 最寄り駅名が同じ場合は2つ目以降は記載を省略してください
解釈するJSON
${payload}
という感じです。
このレスポンスは、以下のようなJSONで返ってくるので、
あとはこのpayload.textをslackに投稿させるだけです。
(秋葉原周辺の緯度経度を入れたときの結果です。)
{
"output": {
"text": "東京都 秋葉原駅\n麺処 ほん田 秋葉原本店 https://tabelog.com/tokyo/A1310/A131001/13246285/\nTokyo Style Noodle ほたて日和 https://tabelog.com/tokyo/A1310/A131001/13280086/"
},
"usage": {
"completion_tokens": 67,
"prompt_tokens": 849,
"total_tokens": 916,
"model": "gpt-4o",
"byol": false,
"service": "azure-openai",
"credit": 150
}
}
slack投稿のアクションが右にあるかと思ったらないぞ?と思った方、正解です。
実はLLMに整形をさせてその内容をslackに投稿するアクションの流れがこのあと更に2回、合計3回出てきます。当初は整形用LLMのAIアクション一個ずつにつき、slack投稿アクションが一個ずつつくようにしていたのですが、これをやるとチャンネルの和の上限値20を超えてしまったためこの部分だけ共通化しました。

あれ?webhookアクションじゃん!Fluxにはslackアクションがあるのになぜと思った方、何故だと思いますか?
Fluxで用意されているslackアクションはwebhookを使ってslackに投稿するもので、基本的にチャネルに直に投稿されてしまいます。
これも夏から続くフィールドワークのフィードバックの結果、いくら自分のチャネルとはいえラーメン屋が次々出てきたら荒れてしまうし、その結果チャネルの治安が悪化する可能性もあります。また、突然の大事な情報がラーメン屋さん情報で流されてしまうことも考えられます。
ということでできれば、同じ日のうちは同じスレッドにまとめて投稿したいという強い要望が湧いたため、webhookアクションでslack apiのchat.postMessageの方を使っています。
最後のslack投稿のあとのSORACOM APIアクションは、SIMのタグにslack投稿した際のスレッドのts値を書き込んでいます。これによって次回投稿するときにタグに書かれたtsを投稿するslack apiのbodyに指定すると、同じスレッドに書くことができるわけです。

最寄り駅ベースの検索のフローは以上です。
最寄り駅にラーメン屋さんがなかったときは、現在地が東京・大阪以外のときに実施している住所ベースで探すフローに入る必要があります。
ただし最初の分岐の判定は東京・大阪かそれ以外かなので、ここに戻ることはできないのでその途中に戻る形になります。
ここのwebhookは、位置情報から住所を割り出すAPIの直前のチャネルにあるincoming webhookを叩きます。

これをやるためには、位置情報から住所を割り出すAPIに東京大阪かそれ以外かの実行条件の判定をくっつけてはいけないので、このような形になっています。
またwebhookを叩くときは、それまで代々受け継がれてきたevent.payloadの値を拾ってきてもう一度bodyに入れてpostします。
まあちょっと何言ってるかわからないかもしれませんが要するに、こんなにフローを重ねているのになんで最初のマルチユニットが吐き出した緯度経度がまだこの辺のあくしょんでも使えるのか?ということです。
このあとの流れさっきとあまり変わりません。駅じゃなくて住所をキーに探しているだけです。
こんな感じです。

近接する自治体はこんな感じのプロンプトで聞いています。

ここでの返事はあえてJSONにして、その後のkintone APIのクエリのパラメータにではJSONのvalueを直接指定して検索をかけています。
はい、だいたいこんな感じです。
5. Demo
ダミーデータでデモしまーす。
新宿を東から西に横切ります。
| No. | 緯度 | 経度 |
|---|---|---|
| 1 | 35.687557 | 139.716952 |
| 2 | 35.687357 | 139.711755 |
| 3 | 35.689154 | 139.706418 |
| 4 | 35.689126 | 139.700994 |
| 5 | 35.683906 | 139.690741 |

結果:

まあ良さそうな仕上がりですね。
6. Futurework
気が向いたらやりたいことを書いておきます。
-
地下鉄などGPSの届かないところでの位置情報取得からのラーメン屋さんの検索
- GPSに加えて基地局のIDも送れるデバイス作りたい。BG770とかを狙っている。
-
ちょうどいいラーメン情報 as a Serviceへの課題
- 逆ジオコーディングAPI、駅情報API、ラーメンDBを安定的に商用利用できるAPIを探したり、DBを構築したり
-
フローの可読性向上
- Fluxのアプデに期待age
-
LLMでやっているところをロジックでやりたい
- slack投稿向けの整形処理はぶっちゃけLLM使う必要ないので、ロジックでやりたいFluxのアプデに期待age
-
ロジックの改善
- 本当に行ける範囲のラーメン屋さんをもれなくピックアップできるロジック
- 定休日や営業時間、場合によってはスープ切れなどの情報もリアルタイムに考慮してレコメンドに反映できるロジック
-
DBに入っているリストの更新、メンテナンス、ユーザー間でのレコメンド機能の追加
- 例えば社内で運用するなら
- 誰かがラーメン屋さんの食べログサイト情報をslackで投稿したらそれを自動的にスクレイピングしてDBに反映させる仕組み
- 写真を投稿したらその画像からどこのラーメン屋さん化を特定して食べログサイトに行ってスクレイピングしてDBに反映させる仕組み
- 例えば社内で運用するなら
来年もSORACOMで充実のラーメンライフを送りましょう!
ありがとうございました。
Discussion