PuppeteerとCloud Functons for Firebaseでスクレイピング
Node.js v18、Puppeteer v22とCloud Functons for Firebase Gen2 環境でスクレイピングする最小構成を作ってみます。
GitHub にプロジェクト全体のコードが置いてあります。
インストール
Firebase プロジェクトの作成と firebase init までの作業は省略します。
npm i puppeteer puppeteer-chromium-resolver
スクレイピングするための puppeteer とローカルに Chromium をダウンロードしてインストール先のパスを動的に取得できるようになる puppeteer-chromium-resolver をインストールします。
Puppeteer は v19 から node_modules 内に Chromium をダウンロードしないように破壊的変更されたため、Cloud Functons for Firebase 上で実行時に Chromium が見つからないエラーが発生します。それを解決してくれるのが puppeteer-chromium-resolver です。
{
"functions": [
{
"source": "./",
"codebase": "default",
"ignore": [
"node_modules",
".git",
"firebase-debug.log",
"firebase-debug.*.log"
]
}
]
}
今回は、プロジェクトのディレクトリ直下に index.js を作成するので、source に ./ を指定しておきます。
スクレイピングの処理
プロジェクトのディレクトリ直下に index.js を作成します。
import {onRequest} from 'firebase-functions/v2/https'
import puppeteer from 'puppeteer-chromium-resolver'
export const scrape = onRequest({
// メモリは最低でも1GB推奨だがギリギリだと処理が中断することがあるため余裕を持たせておく
memory: '2GiB',
}, async (req, res) => {
// ローカルにインストールされたChromiumを解決する
const stats = await puppeteer()
// ブラウザを起動する
const browser = await stats.puppeteer.launch({
// Chromiumの実行パス
executablePath: stats.executablePath,
args: [
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--no-first-run',
'--no-sandbox',
'--no-zygote',
'--single-process',
],
// 古いヘッドレスモード(パフォーマンスがいい)
headless: 'shell',
})
// 新規ページを開く
const page = await browser.newPage()
// ページにアクセスする
await page.goto('https://zenn.dev/takamoso', {waitUntil: 'domcontentloaded'})
// ページタイトルを出力
res.send(await page.title())
// ブラウザを閉じる
await browser.close()
// レスポンスを返す
res.end()
})
Zenn の個人ページにアクセスして、ページのタイトルを出力する関数です。onRequest() 関数を使うときは必ず res.send('') や res.end() でレスポンスを返すようにします。また、Puppeteer の処理が終わったら、await browser.close() でブラウザを閉じる処理を書きます。これを忘れるとページがメモリ上に確保されたまま蓄積して行くので、メモリエラーになります。
npm run shell
> shell
> firebase functions:shell
✔ functions: Using node@18 from host.
Serving at port 8238
i functions: Loaded functions: scrape
⚠ functions: The following emulators are not running, calls to these services will affect production: firestore, database, pubsub, storage, eventarc
firebase > scrape()
npm run shell コマンドでエミュレーターが起動するので、scrape() と入力して関数を実行します。
RESPONSE RECEIVED FROM FUNCTION: 200, たかもそさんの記事一覧 | Zenn
こんな感じでレスポンスが返ってこれば成功です。
デプロイ
npm run deploy コマンドでデプロイします。
npm run deploy
本番環境でも実行されるかどうかを確認していきます。
Google Cloud Platformにアクセスして、左上のメニューから Cloud Functions をクリックします。
関数名の scrape をクリックします。
URL をクリックすると新規タブで関数が実行されます。
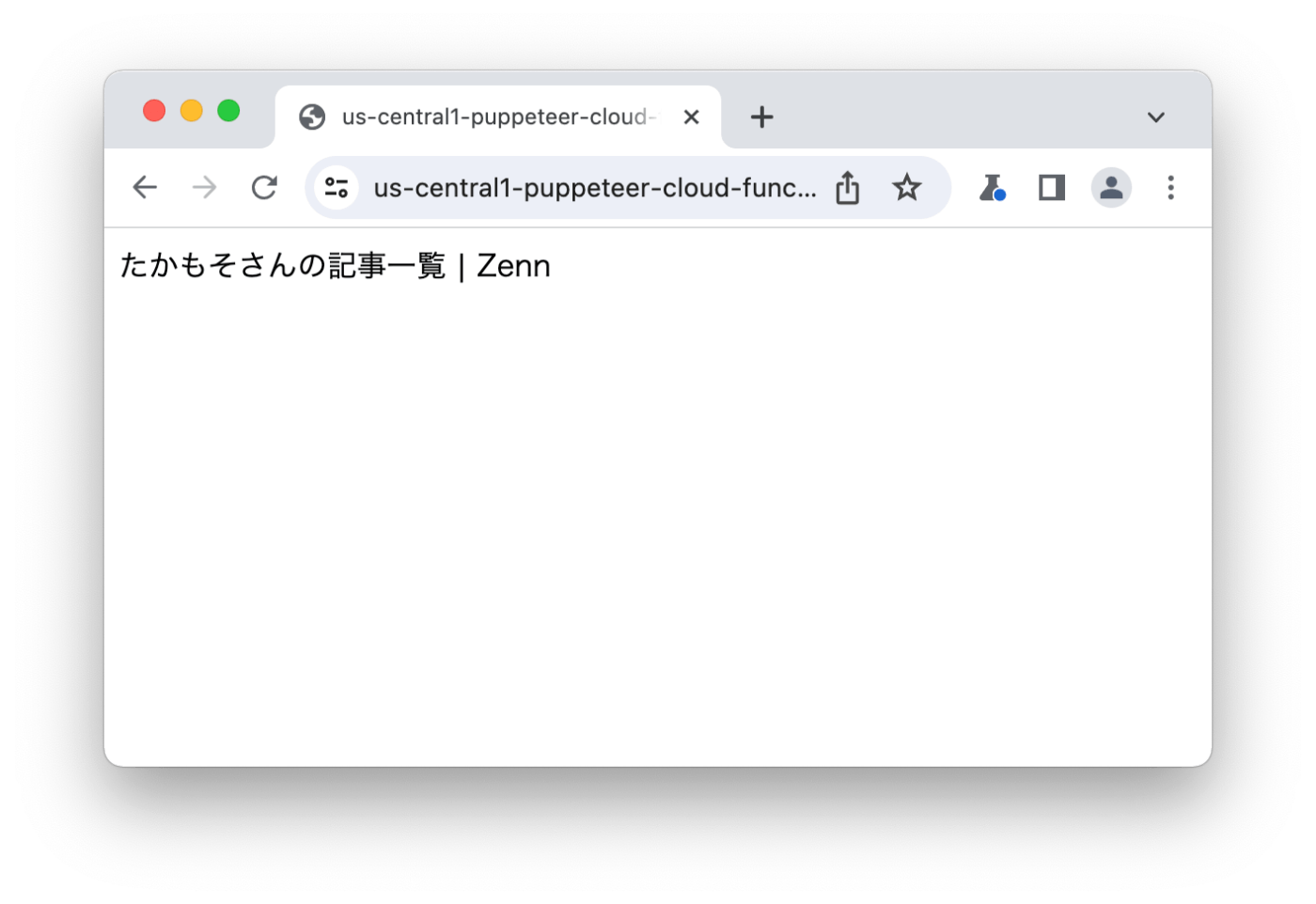
少し時間はかかりますが、ページタイトルが表示されれば成功です。
Discussion