コールツリーやシーケンス図をテキストエディターで書く方法 〜 構造化ドキュメンテーション (3)
構造化ドキュメンテーション
- 第1回: アジャイルなノートの書き方入門
- 第2回: アジャイルに手順書を書くための 13のルール
- 第3回: 大規模プログラムの理解を助ける図を VSCode で素早く書く方法
- 第4回: 今日は何するんだっけ?思考をリードするチケット管理の書き方
プログラムを見渡す地図が欲しい
大規模なプログラムを担当するようになったとき、まず、システム全体のアーキテクチャの概要や図を読みたくなると思います。そこには各コンポーネントの役割や関係性やデータの流れの情報が書かれていますが非常にあいまいな情報です。サーバー、コンテナー、ライブラリ、データベース、クラス、モジュールなどのうちどれがコンポーネントであるかはそれぞれのシステムで違います。その状態からプログラマーはプログラムのコードや設定ファイルなどと対応させなければコーディングを始めることすらできません。
プログラムの規模が大きくなると目的のコードを探すだけでも大変になってきます。そんなときは全文検索(grep)をして関数などの定義にジャンプするのが基本です。しかし、探すことができても全体像まで理解することはできません。点と点が見つかっても点が線になりません。それでは総合的な設計や改良はできません。昔、goto 文だらけの スパゲティ コード と呼ばれるものがありましたが、クラスに分けすぎても同様の状態になってしまいます。
点が線になって理解するためには俯瞰して眺めることが必要です。俯瞰するとは、処理フローならジャンプする前の関数とジャンプした後の関数(と更にジャンプした後の関数…)が同じ画面に表示されているものを見ることです。そうすることで構造をイメージとして記憶します。ジャンプして場所が変わると脳内では別のイメージとして記憶されてしまいます。
ABC 順に並んだ API などのリストは、点が並んでいる状態です。名前が分かれば探しやすいですが「この近くにありそう」という探し方ができません。コール ツリー はご存知かと思いますが、関数の呼び出し順序に沿って処理をツリー状に並べていき、ツリーの葉先に向かうほど呼び出し先の関数を並べた図です。コールツリーは処理の順序や時系列に沿って並んでいるので「この近くありそう」という探し方ができます。時系列に並んだ情報は、エピソード記憶と呼ばれるものがあるように、覚えやすいです。また、ツリーの構造を見ると、直線的なリストを見るときよりも、空間的なイメージで覚えることができます。ただ、単に関数名をツリー状に並べただけでは覚えられません。記憶を助ける補足情報が必要です。
プログラムを表現する図といえば UML ですが、そこまでできなくても、コールツリーとデータ構造さえ表現できれば 8割はプログラムを表現できます。昔からプログラムは 「アルゴリズムとデータ構造」 と呼ばれていますが今でも有効です。クラスはその一部でしかありません。すべてをクラスに分けるよりシンプルになります(一部の設計要素はクラスにするほうがシンプルになるのでオブジェクト指向がオワコンというわけではありません)。
ここでは構造化ドキュメンテーションによるテキスト形式でのコールツリーとシーケンス図とデータ構造の図を説明します。Visual Studio Code (VSCode) を使った構造化ドキュメンテーションの応用なので、色が付いて見やすくなりますし、折りたたむことができますし、図から関連情報にジャンプすることや、任意の場所から図の中へジャンプすることもできます。テキスト形式なので Git でバージョン管理もできます。文書をバージョン管理することがコード以上に重要であることは最後に説明します。パワポやdraw.io などの図形エディターでは差分を見ることができません。Mermaid というテキスト形式で書けば UML の画像を生成することができますが、Mermaid のテキストは配置がバラバラなので少し情報が増えるだけで編集が難しくなっていきます。
コールツリー
シーケンス図

データ構造の図

コール ツリー YAML の書き方
コール ツリー はご存知かと思いますが、関数の呼び出し順序に沿って処理をツリー状に並べていき、ツリーの葉先に向かうほど呼び出し先の関数を並べた図です。
まずは、情報として有用な関数の関数名またはメソッド名を YAML のマッピング名(フィールド名)として描きます。
fillRelatedData:
IDE(統合開発環境)のブラウズ機能を使ったり コール スタック を見たりして、呼び出し元や呼び出し先の関数を探しながらコールツリーを書いていきます。ただし、内容を知る必要がない関数まで深掘りして書く必要はありません。必要性の有無は担当する内容や知識量によるため個人ごとに異なります
main:
fillRelatedData:
getBaseData:
setRelatedData:
ライブラリの中で何段も深く呼び出している重要でない部分は ...: で省略しても構いません。ただし、: だけに省略しないでください。VSCode のパンくずリストが表示されなくなってしまいます。
main:
...:
getBaseData:
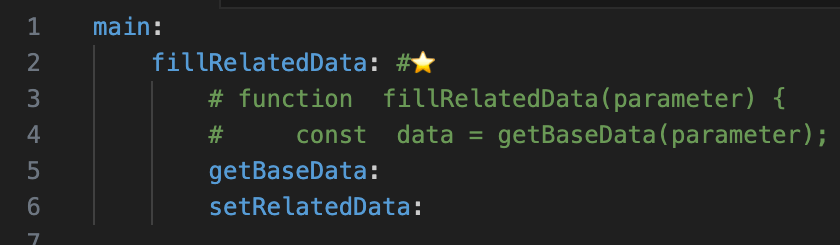
目立たせたい関数には、コメントで色つきの絵文字を付けるといいでしょう。
main:
fillRelatedData: #⭐️
getBaseData:
setRelatedData:
ここからは構造化ドキュメンテーション特有の書き方です。関数の処理内容を示すために、関数定義のコードの一部をコメントにコピーします。書く位置は、インデントを深くした位置に書きます。呼び出す関数のコードは、呼び出す関数のフィールド名の上の行に書きます。コメントは薄い色で表示されるため、関数名が主、コードが従であることが色の濃さからも分かります。
(色付き)
(色なしコピー用)
main:
fillRelatedData: #⭐️
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
getBaseData:
setRelatedData:
VSCode で複数行にコメントの記号 # を付けるときは、複数行を選択した状態で Ctrl + / を押します。
ただし、コードに空行があったらその空行を無くしてください。空行はブロックを分ける役割をしますが、断片をコピペするので、分け方が適切ではなくなります。また、Ctrl + / で # のインデントの深さが期待通りにならないのも理由です。後でインデントの深さを変える編集をするときは、Ctrl + / で一旦 # を削除します。
2つ目以降の関数 setRelatedData を呼び出すコードをコメントに書くときは、呼び出す関数のフィールド名のすぐ上の行に入れます。
main:
fillRelatedData: #⭐️
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
getBaseData:
# setRelatedData(data);
setRelatedData:
呼び出し先の関数から更に呼び出している関数の名前やコードは、インデントを深くした位置に書きます。
(色付き)
(色なしコピー用)
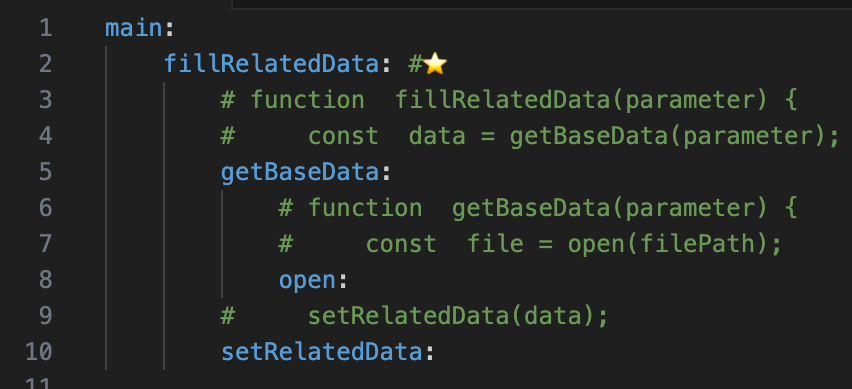
main:
fillRelatedData: #⭐️
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
getBaseData:
# function getBaseData(parameter) {
# const file = open(filePath);
open:
# setRelatedData(data);
setRelatedData:
ここまで書くと一見すると複雑に感じると思いますが、読んでいくとだんだん地図を見たときのように必要な情報が見渡せるようになります。地図でも初めて見るときはごちゃっと見えますから第一印象で判断しないほうがいいでしょう。
コールツリーを見るコツは、まずは関数名が書かれたフィールド名だけを見るように自分の目でフィルタリングします。つまり、フィールド名の色だけに注目しながら全体を見ます。呼び出し関係が見えてくるでしょう。ただ、関数名だけでは情報が少ないので、コメントにあるコードを読むことで具体的な関係が見えてきます。
関数名をクリックまたはダブルクリックすれば、呼び出し側のコードにある関数名も強調表示されるので、どのように呼んでいるかもすぐに分かります。

ライブラリの関数(上記の open)ついては、ライブラリの実装コードまでコールツリーに書くことは少ないと思いますが、ライブラリの関数名をフィールドに書くことで目立つようになりライブラリを意識するようになります。ライブラリの関数(open, read, write など)は、分かりやすく設計されていますし実績もありますし多くの人が知っているので、それを明示することはとても意味があることです。
open をフィールドに書かなかったらどうなるか見てみましょう。
_:
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
getBaseData:
# function getBaseData(parameter) {
# const file = open(filePath);
# setRelatedData(data);
setRelatedData:
コードのコメントにライブラリの関数名が書いてありますが、その関数は認識しずらくなりましたね。もちろん、ライブラリでなくても同様の目的でよひ関数の名前のフィールドだけ書いても構いません。
2つ目以降の関数 setRelatedData の呼び出しのコードが1つ目以前の関数呼び出しのコードと離れてしまって少し見にくくなったと感じるでしょう。そのときは、# がある位置(深さ)が同じであるものが、1つの関数定義となっているので、同じ深さに # がある行に注目します。VSCode などでは薄く縦の線が入るので同じ深さであることが分かりやすいです。
また、1つ目の関数 getBaseData を閉じると(foldingすると)、元の見た目に戻せます。ツリーを開閉できるのは大きなメリットですね。
main:
fillRelatedData: #⭐️
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
getBaseData:
# setRelatedData(data);
setRelatedData:
関数名のフィールドをまとめて、関数名のフィールドのすぐ上にコードが来ないような書きかたでも構いません。
_:
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
# setRelatedData(data);
getBaseData:
setRelatedData:
コメントに補足情報を書いても構いません。関連する資料へのリンクを書いても構いません。コメントのように書くとよいでしょう。typrm のタグを書くのも良いです。一部の人はコメントを少し編集するだけの Git commit を嫌いますが、そういった人からとやかく言われないためにコールツリーを書くのでも良いです。
_:
# function fillRelatedData(parameter) {
# const data = getBaseData(parameter);
# // DBサーバーが必要。http:...
# // #keyword: base data
コードを書くことでもう1つメリットが生まれます。それは、関数定義にすぐにジャンプすることができるようになることです。関数定義の最初の行全体(関数プロトタイプ)で全文検索すると他の部分が検索結果に出なくなり簡単に検索(ジャンプ)できます。関数名だけで検索すると、関数定義の部分だけでなく、関数呼び出しの部分まで大量に検索結果に出てきてしまい迷ってしまいます。
function fillRelatedData(parameter) {
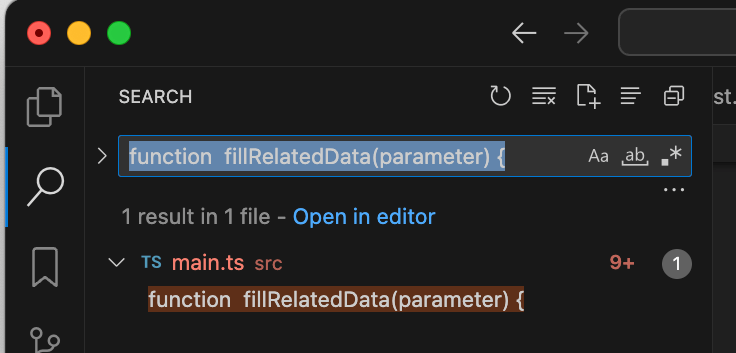
関数名だけでは別の場所にもヒットしてしまいます。もちろん do などの抽象的な名前のメソッドが多くある場合でも別の場所にヒットしてしまいますが、その場合はたいていクラス名が処理の名前になっているので(それが良いかは置いといて)、クラス定義の最初の行で全文検索します。
class FillRelatedData {
そのようなクラスのコードをコールツリーに書くときは、クラス名がある行もコメントに書きます。最近流行りの Sticky scroll で折りたたまれた感じですね。フィールドはメソッド名を書きますが、メソッド名だけでは分かりにくいときはクラス名を補足します。
do (FillRelatedData):
# class FillRelatedData {
# do() {
# const data = getBaseData(this.parameter);
コールツリーは ソース ファイル から自動生成することができますが、生成されたコールツリーはあまり読みやすくありません。なぜなら補足情報か少なすぎるからです。IDE のコールツリーは、1段ずつ開いていく必要があるため1段ごとに関数の意味を理解して選ばなければ、目的地に着きません。関数定義にジャンプするブラウジング機能も同様です。適切に関数名が付けられて適切に関数が構成されていればいいのですが殆どのプログラムはそうなっていません。中級者のコードになると謎の抽象的な関数が入って内部プラットフォーム効果(悪い効果)が発生してかなり難しくなります。
コールツリーは目的に応じてそれぞれ作ります。特定の ビジネス ロジック のコールツリー、サーバーとの通信についてのコールツリー、ライブラリの使い方についてのコールツリー、UI を初期化するときのロードや生成や生成後の処理のコールツリーなど、目的に応じてそれぞれ作ります。
コールツリーを書くと、設計が悪くてもリファクタリングしなくてもコードが理解できるようになります。
シーケンス図 YAML の書き方
シーケンス図はご存じかと思いますが、メッセージ(リスエストやハンドシェイクやデータなど)のやり取りを時系列で説明するための図です。
定義があるファイルのパスを書くと、多くの場合、フォルダーの名前からどのコンポーネントであるかが分かります。下記サンプルの #ref: は typrm のタグですが深い意味はなく URL や パス に付けているコメントです。少なくとも # を書いてパスをコメントにしないと YAML の文法エラーになります。
notify: #ref: ~/__Project__/app/notify.ts
そして下記の場合、app, storage, mailer がコンポーネント名です。
(色付き)

(色なしコピー用)
notify: #ref: ~/__Project__/app/notify.ts
getFromStorage: #ref: ~/__Project__/storage/db.ts
sendMail: #ref: ~/__Project__/mailer/send.ts
getAddress: #ref: ~/__Project__/storage/address.ts
このようにパスを書いて読めば、コンポーネントの種類に関する階層構造を知ることができます。フォルダーを開いて分類名と分類対象の一覧に相当するファイル名やフォルダー名の一覧を見ても、それがどういうものかが分かってないので「はぁそうですか」としかなりません。しかし、コンポーネントの所有に関する階層構造に近いコールツリーと同時に見ると種類の階層構造からどういうコンポーネントなのかをより詳しく理解できるようになります。たとえば CustomerList だけ見るより、その親フォルダーも見て UIBlock だったら CustomerList の ユーザー インターフェース の部品であることが想像できますし、DBSchema だったら CustomerList のデータベースであることが想像できます。
コンポーネントに対してインデントをかなり深く書くと、シーケンス図のようになります。縦線の文字 | を書いてもいいですが、書くとツリーの折りたたみができなくなりますし、インデントの深さを変える時に大変になるので書かないほうがいいでしょう。
notify:
getFromStorage:
sendMail:
getAddress:
さらに矢印の行のフィールドを挿入します。矢印を書くとコンポーネントの関係が明確になります。矢印とカッコの行は、YAML のフィールド名として書き、矢印とカッコ以外は書きません。矢印の左側のインデントの深さをコンポーネントに合わせれば、矢印の右側の位置が多少違っても見にくくなりません。さらに、矢印の右にコンポーネントの関係 (__From__->>__To__) を書くと分かりやすくなります。
notify:
---->> (app->>storage):
getFromStorage:
---------------->> (app->>mailer):
. sendMail:
<<---------- (mailer->>storage):
getAddress:
これにコードのコメントを追加すると次のようになります。
(色付き)
(色なしコピー用)
notify:
# function notify() {
# const data = getFromStorage();
---->> (app->>storage):
getFromStorage:
# function getFromStorage() {
# sendMail();
---------------------->> (app->>mailer):
. sendMail:
# function sendMail() {
# const address = getAddress();
<<---------- (mailer->>storage):
getAddress:
# function getAddress() {
よく見ると app->>mailer の矢印の下の行にピリオドがあります。これは YAML の文法エラーを回避するためのピリオドです。矢印の左端のインデント位置より深いインデントの行のうち、最も浅いインデントに合わせてピリオドを書く必要があります。別にピリオドである必要はありませんが他の文字より目立たないでしょう。
矢印の右の (__From__->>__To__) の書式は Mermaid に合わせています。右から左への矢印でも(矢印の根元->>矢印の先) の方向で書いてください。Mermaid の仕様だからです。Mermaid は、テキストから画像形式の図を生成するための記法の 1つですが、図を生成したいときは、コールツリーから Mermaid へそのままコピペして生成することができます。
sequenceDiagram
app->>storage: getFromStorage
app->>mailer: sendMail
mailer->>storage: getAddress
Mermaid のテキストはもちろん VSCode などの テキスト エディター で書くことができますが、そのテキストからコンポーネントの関係を理解しようとすると、矢印の前後のコンポーネント名をしっかり読まなければ理解できません。これが問題になるのはテキストを編集をするときです。たとえば、Mermaid が生成した画像の図を見ながら新しい矢印を追加するような編集はかなり難しいです。なぜなら、画像の図は位置関係を見てそのまま編集できるのに対し、Mermaid のテキストは矢印のリストの中から該当する名前を上から読みながら探してから編集することになるからです。また、新規作成するときは、コンポーネントの関係がまだ見えない状態で編集するのでそれもまた難しいです。
矢印の種類についてですが、使うコンポーネントの処理を実行するときに関数呼び出しではなくメッセージ送信などの場合もありますが、その違いはあまり意識して書き分けなくてもいいと思います。重要ならコメントで補足的に書けば十分です。
データ構造の書き方
YAML は元からデータ構造を表現するための記法なので、YAML の書き方を知っていればデータ構造を表現できますが、クラス図のようなオブジェクトの構造を表現するにはもう少し拡張したほうが良いです。
クラスを表現するときは属性と関連を分けたほうが理解しやすくなります。データベースで言えば、テーブルを表現するときに通常のカラムと外部キーを分けたほうが理解しやすくなります。
クラスや構造体は YAML のフィールド名にして目立たせます。属性はコメントで書き、ピリオドから始め、必要なら型を添えます。属性などは網羅する必要はありません。関連するグローバルな変数はピリオドから始めません。配列などの複数に関しては名前の後に [] を書きます。メソッドや派生属性は名前の後に () を書きます。関連は YAML のフィールドの親子関係で表現します。
(色付き)
(色なしコピー用)
Shop:
# .number
# .name
# .address
Accounting:
# .sales() currency
Staff[]:
# .number ID
# .name string
# .phone string[]
スーパー クラス や インターフェース は、名前を ( ) で囲みます。サブクラスは ^ から始めます。クラスの補足情報として スーパー クラス を添えるのも良いです。ジェネリクスは、T の部分を < > で囲みますが、T ではなくサンプル的なクラスを書きます。ファクトリー メソッド は <__Name__()> メソッドというより抽象的なデータに相当するので YAML のフィールドに書きます。
Shop:
(Accounting):
^FoodShopAccounting:
# .tax
CommonData:
# .sales()
Staff<FoodStaff>[]:
<CreateStaff()>:
FoodStaff:
SalesStaff:
書式:
class:
# .attribute int や str #ref: __PathOfToRefer__
class: #// .attribute #ref: ____
class2: #ref: __PathOfDefine__
# .attribute #ref: __PathOfToRefer__
# variable #ref: __PathOfToDeclare__
class[]: #// .attribute
class( super ): #// .attribute
(super): #// (.attribute)
memberClass: #// .memberAttribute
^subClass: #// .attribute
class< T >: #// .attribute or variable
<method()>:
class: #// variable
<factory>: #// .attribute
class: #// variable
構造化した図をポータルサイト的な specifications.yaml にまとめる
コールツリーやデータ構造を書いても、必要なときに見つけられなければ意味がありません。
必要なときに見つけられる条件は、大きく2つあります。最もよく使われる方法は全文検索です。ただ、キーワードを知っている必要があります。記憶力が必要です。複数の単語で検索するときに単語の順番が逆だったり、類似語を入力してしまったり言語が違ったりしたら見つかりません。typrm などの高度な検索ツールを使えば見つかるでしょう。
説明書に書かれるような機能リストやファイルリストなどから選ぶこともよく使われる方法です。公開している説明書と同じ構成のツリーを書いて、その中にコールツリーを書きます。同じ構成であれば、見やすい説明書から探して対応するコールツリーを探すことができます。
REST API の エントリー ポイント やユーザー操作のイベントなどからコールツリーを探すこともあります。この場合、時系列に発生しそうな API 呼び出しやイベントの順に並べると分かりやすくなります。
目的の文書を探すための構成をどのようにするかについても大きなトピックなので別の機会に説明しようと思います。
それらを書いたファイルは、specifications.yaml(仕様の YAML)という標準的な名前にすることで、ファイル自体も見つけやすくなります。
文書はすぐに腐り始めるけど、それでも書いたほうが役に立つ
構造化ドキュメンテーションで扱う文書は、対象となるものを説明する文書なので、対象(コード)が更新されれば、正しくない文書に変わってしまいます。その現象を文書が腐ると言う人もいます。コードは商品よりも頻繁に変更されるので腐り始めるのも早いです。なので同期が必要で、文書のバージョン管理は必須です。
よくサポートの文書の最後に「役に立ちましたか?」というアンケートがありますが、それは文章が腐ったことをユーザーに見つけてもらう手段でもあります。きちんと同期していればいいですが、多くの文書ファイルは Git ほどしっかりバージョン管理ができないので同期は難しいでしょう。文書を更新する必要が分かったらすぐでも後でも同期的に更新ができるのが構造化ドキュメンテーションによる図のメリットです。
文書はすぐ腐るから書かない、という考えの方もいると思いますが、多少腐ってもそれがヒントになって問題が解決することもあります。たとえば、古い情報でも構成をよく知っているから目的の関数がすぐに見つかり、最新版でも同じ関数名なら検索キーワードを得ることができます。
文書を更新しながらコードを見返すことで、コードの理解がより深まります。自分が書いたコードでも、時間が経つと忘れてしまうものです。文書の更新作業を通じて、コードを再確認することができるのです。文書を更新することで、コードの設計や構造について改めて考えるきっかけにもなります。文書化の過程で、コードの改善点に気づくこともあるでしょう。結果として、コードの品質向上にもつながります。最新の情報に更新された文書は、チームメンバーとの情報共有やコミュニケーションを円滑にします。新しいメンバーへの引継ぎ資料としても活用できます。問い合わせ対応などの際にも、的確な情報を提供できるようになります。文書の更新を習慣づけることは、一時的には負担に感じるかもしれません。しかし、長期的に見れば、コードの理解促進、品質向上、円滑なコミュニケーションなど、開発チーム全体の生産性アップに大きく貢献するはずです。
(最終節のみ Claude Opus AI の出力です)
Discussion