Mini PC + 外付けGPUでローカルLLM環境を作った話
2025 アドベントカレンダーの記事です!
弊社シーエー・アドバンスでは、AIの活用を徹底するように号令がかかっています。
今回は、Local LLM を自宅で動かしてみたので、それについて記事をまとめます。
自宅で、Ollama を使って、LLMを動かしたりしたいと思っている方の参考になれば幸いです。
対象読者
- LLMに興味がある、ローカルでLLM動かしたい人
- ローカルLLMにどれぐらいお金がかかるか気になる人
- OCuLink の性能知りたい人
- 外付けGPUを検討している人
概要・構成要素
この記事を読むとどのように自宅でLLMを動かせるか雰囲気で理解できるかと思います(私も雰囲気でしか理解していません)
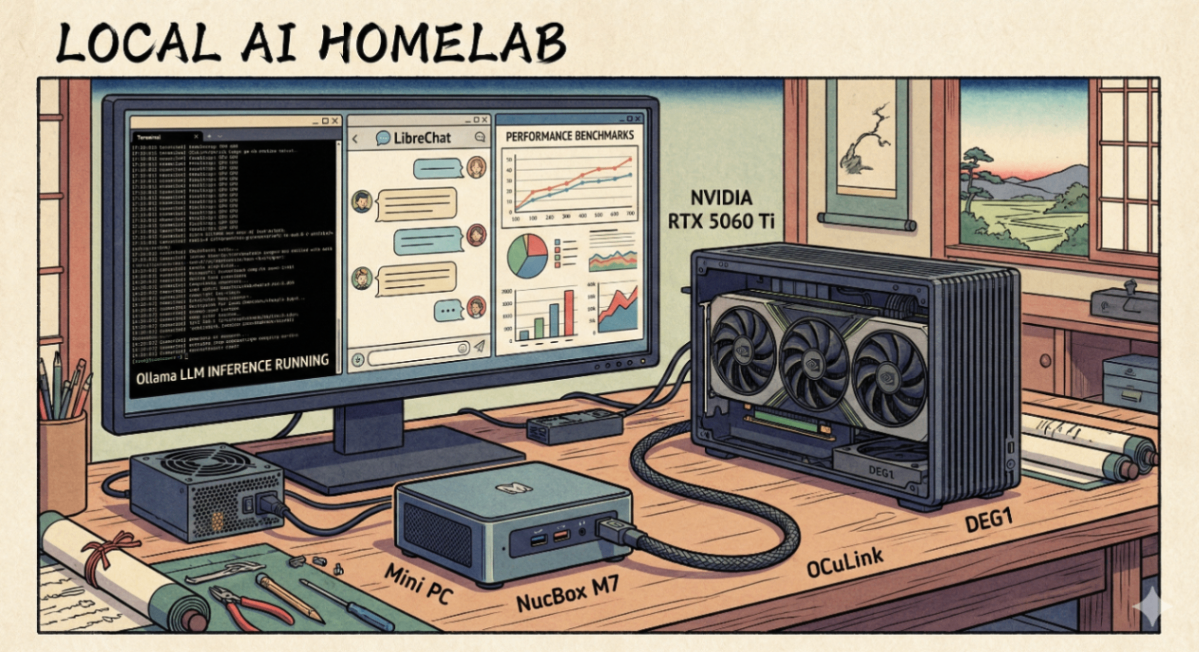
まず、構築した環境の概観としては以下のような感じとなっています。

LLM Server と 外付けGPU

構成内容
- GMKtec Mini PC NucBox M7
- Mini PC
- RAM: 16GB
- SSD: 512GB
- DEG 1 (外付けGPUドッキングステーション)
- GPU と電源ユニットを接続するステーション(詳細は後述)
- OCuLink で上記Mini PC と接続
- NVIDIA GeForce RTX 5060 Ti
- VRAM: 16GB
- DEG 1 にドッキング
- KRPW-GA750W
- 電源ユニット、GPU と DEG 1 に電源供給
- 750W ATXu
- OS / ミドルウェアなど
- Ubuntu 24.04 / Windows 11 ( デュアルブート)
- Tailscale (SSHで、サーバーに接続して管理できるようにするため)
- Ollama (LLMを動かすため)
- Librechat (Ollamaと繋いでチャットのウェブUIを利用するため)
名前の通り、LLMを動かすサーバーです。
Mini PC と、Oculink を使えば、気軽に?GPUが導入できそうだったので、Mini PC と NVIDIA の RTX 5060 Ti を使って、ハードウェアを構成しました。詳細は後述します。
Bastion Server (踏み台)

- 中古ノートPC
- Ubuntu 22.04
- Cloudflare Tunnel (cloudflared)
今回の本筋とは関係無いですが、外のネットワークから、Librechat などのLLMのWebアプリケーションを利用できるようにするため、Cloudflare Tunnel を設定し、スマホなどからアクセスできるようにしました。認証によるアクセス制御もできるので、Cloudflare Tunnel と関連の Cloudflare のサービス便利です!
↓Cloudflare Tunnel が有効で、外のネットワークから、LLMサーバーのWebアプリケーションにアクセスするイメージ

↓ cloudflare tunnel の設定などは、以下の記事もあるので良ければ 🙏
その他
- 普通に自宅に wifi ルーターがあり、各種PCやスマホがそこに接続
上記の通りサーバーを構築した結果、以下のように ollama が動かせます。
GPU なしでのベンチマーク
各種セットアップ・構築方法の説明の前に、まずGPUを接続しない状態のベンチマークを示します。
GPUなしとは、GMKtec Mini PC NucBox M7の単体のベンチマークです。内蔵GPUがあります。比較的安価なMiniPCの内蔵GPUなので、当然性能はそれなりです。
3DMark Steel Nomad
あまり良くわかっていないですが、最近グラフィック性能を評価するベンチマークでよく使われているっぽい 3DMark Steel Nomad で確認しました。

Ollama の verbose output
また、今回はゲームよりもLLMの推論を利用したいので、ollama のスループットも測って、ベンチマークしました。
ollama の対話シェルを起動
ollama run mistral --verbose
推論実行のために投げたプロンプト
Summarize the differences between CPUs and GPUs in AI inference
使用したモデル: mistral
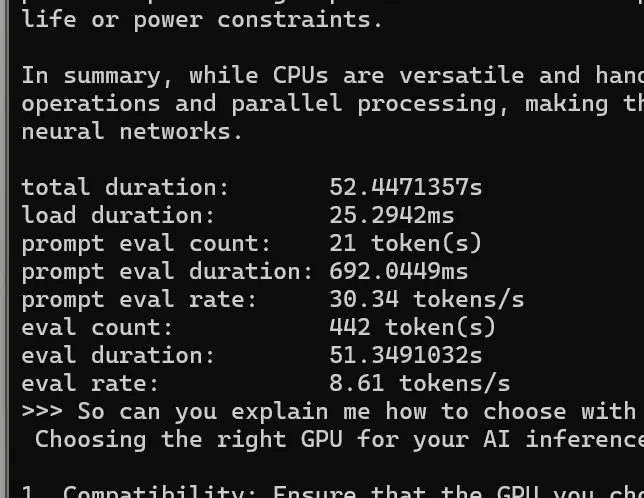
グラフィックの性能も、LLM推論のスループットも、どちらも想定通り実用はできないレベルの悪い結果が出ました。
GPU ありのベンチマーク
サーバーの構築方法など、後述しますが、ベンチマークの結果だけ先に出します。
3DMark Steel Nomad
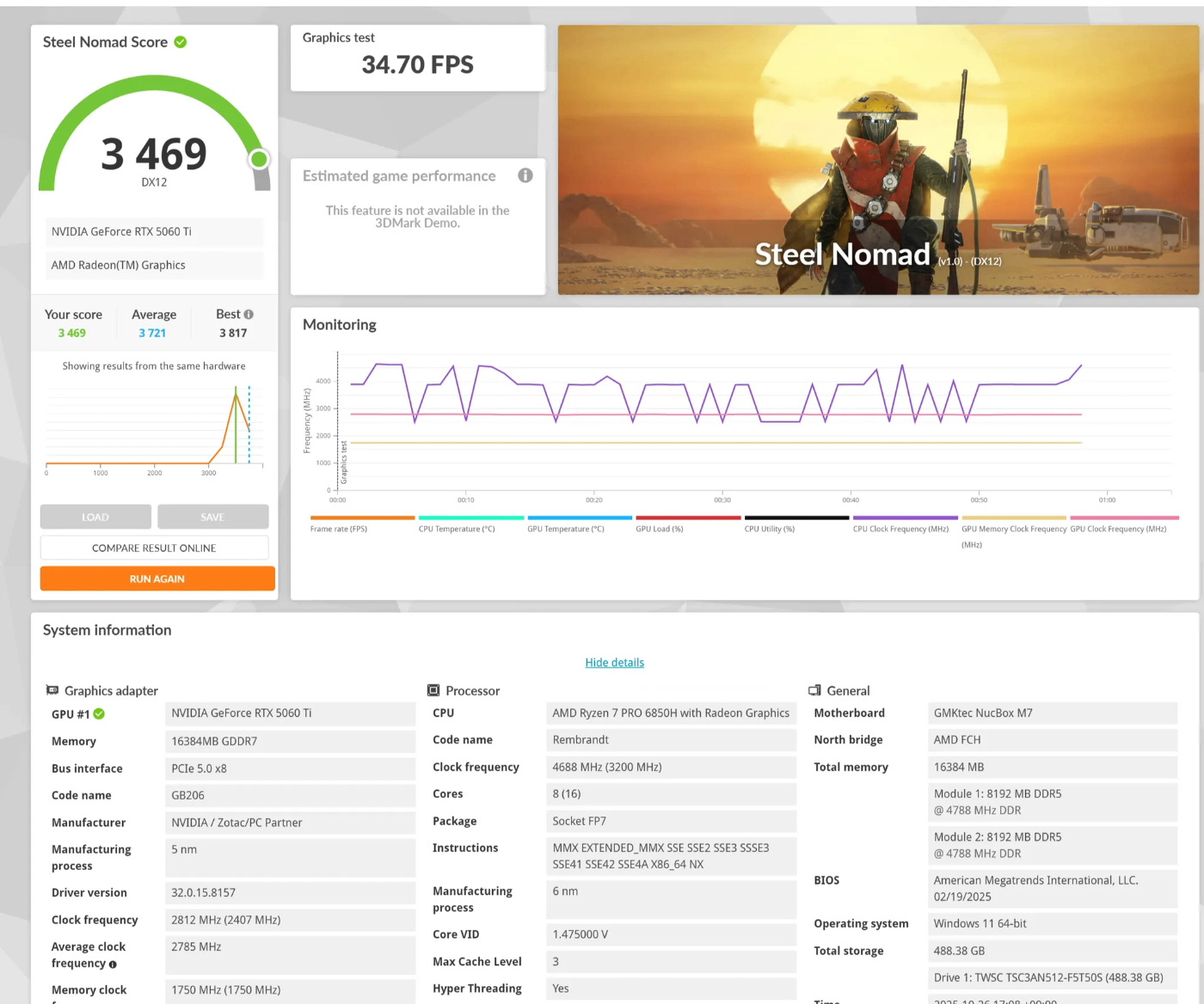
グラフィック性能は上がったものの、34FPSで、最新世代のGPUを使った割には思ったほどのパフォーマンスではなかったです。後ほど詳細に書きますが、OCuLink でGPUを接続したので、最新世代のGPUを使ってもこの程度の結果となったものと思われます。
Ollama の verbose output
ollama の対話シェルを起動
ollama run mistral --verbose
推論実行のために投げたプロンプト(GPUなしの場合と同じ)
Summarize the differences between CPUs and GPUs in AI inference
使用したモデル: mistral
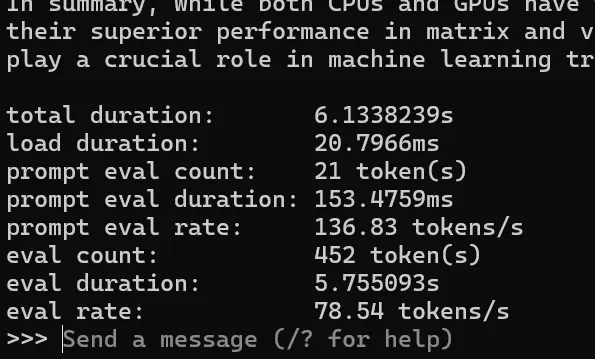
推論の方は、かなり性能が上がりました!
これでも、OCuLink の性能キャップがあるので、GPUのポテンシャルを最大限だせてはいないものの、実用的な?レベルにはなっているかなと思います。
以下で両者を比較します。
ベンチマーク比較: GPU あり/ なし
| 指標 | CPU使用時 (Image 2) |
GPU使用時 (Image 1) |
差異(倍率) | 改善率 |
|---|---|---|---|---|
| 総実行時間 | 52.45秒 | 6.13秒 | 8.56倍高速 | 88.3% 短縮 |
| プロンプト評価速度 | 30.34 tokens/s | 136.83 tokens/s | 4.51倍高速 | 350.9% 向上 |
| トークン生成速度 | 8.61 tokens/s | 78.54 tokens/s | 9.12倍高速 | 812.2% 向上 |
| 実験ID | OS | プロセッサ | 総実行時間 | プロンプト評価速度 | トークン生成速度 | 生成トークン数 |
|---|---|---|---|---|---|---|
| 実験1 | Windows | CPU | 51.33秒 | 30.34 tokens/s | 8.61 tokens/s | 442 tokens |
| 実験2 | Windows | GPU | 5.75秒 | 136.83 tokens/s | 78.54 tokens/s | 452 tokens |
GPUありの場合
- 総実行時間
- 8.9倍高速!
- プロンプト評価速度
- 4.5倍高速!
- トークン生成速度
- 9.1倍高速!
当たり前ですが、LLM推論におけるGPUのありがたみが分かりました。
ハードウェアのセットアップ
ここあらは具体的にどのように環境を作ったか書いていきます。まずはハードウェアから。
ハードウェア選定
マザーボード vs 外付け GPU (eGPU, external GPU)
ハードウェアとか自作PCはあまり詳しくないので、GPU動かすにはそもそも何が必要なんだというところからスタートでした。
今回改めて調べてみると、大きく分けると以下の2通りのやり方が大別されそうです。
- マザーボードにGPUを挿して、デスクトップPCを構成する。CPU, RAM, SSD/HDD なども合わせてセットアップして、デスクトップPCを組むやり方。
- ノートPCや、ミニPCをOculink や Thunderbolt/USB4 のインターフェース/規格を通じて、外付けGPUと接続するやり方。
今回私は、後者の方式を採用しました。
後者の場合のメリット
- ノートPCやミニPCにプラグアンドプレイ(※) の感覚で簡単にハードウェアをセットアップできる
- 最近安くて性能が安定してきた中国製のミニPCが活用できる。更にノートPCなど使えば、余っているPCで、GPUを運用でき、ハードウェアの支出を抑えられる。
- デスクトップを組み立てるよりも狭い・小さいスペースでできる。机の余っているスペースで設置できました。
後者の場合のデメリット
- 自分でデスクトップPCを組み立てるほうが、安くて高性能という最適なPCが実現できそう。(けど知識や経験も必要)
- OCuLink や Thunderbolt/USB4 でGPUをつなぐ場合、直接マザーボードに組み込んでPCIeの接続をするよりも、転送速度が落ち、GPUのフルの性能が活かせない。
(※) プラグアンドプレイの感覚ですが、OCuLink を使う場合、ケーブルを抜いたり刺したりするだけで配線ができるという意味であって、実際にそうする場合は、システムの電源を落とす必要があり、ホットスワップには対応していません。
OCuLink でGPUを外付けするハードウェア
また、外付けGPUの方式を採用する場合も更に選択肢はいろいろあります。
ググると、すぐに出てくる情報としては、このリンクにあるような外付けGPUBOX を使い、それにグラフィックボード(GPU) を挿して、thunderbolt や OCuLink のケーブルでPCと接続するというパターンが多いです。
EGPU Boxを実際に使っている例
しかし、この GPU BOX がとても高価に感じます。グラフィックボードや、PCがない状態の、単体では何も機能しない鉄の塊が5万~10万ほどの価格帯で販売されています。
ほかにも色々探してみると、上記のようなEGPU BOX よりも安い製品があり、それが以下の DEG 1です。

DEG1 特徴
- 安い。EGPU BOX は5万 からなのに対して、1万ちょっとで買える。
- EGPU BOX ではないので、電源ユニットは別途用意する必要あり。
- OCulink のみに対応。
- Thunderbolt / USB 4 非対応。
- 小型、机の空いたスペースでもおけるサイズ感。小さめの米袋ぐらいのサイズ??
↓ネット上にDEG 1 を使ってGPUを動かす実例も多いです。
そもそも OCuLink ってなんだって感じですが、PCIeのインターフェースを外部のデバイスと接続するための規格っぽくて、かなり低レイヤーな感じのようです。そのため、速度が早い。とはいえ、PCIe のデータ転送をその規格用に変換とかするので当然オーバーヘッドがあり、直接グラフィックボードを PCIe と接続するよりは、遅くなり、フルの性能が出せなくなります。
そのため、どれぐらいの性能ロスがあるのか以下にAIにまとめさせた表を載せます。ネット上で眺めた情報と大きな矛盾はないので、参考レベルでは間違いなさそうです。
GPUの接続種類ごとの性能比較表
| 規格 | 最大帯域 | PCIe帯域 | 状況 | 備考 |
|---|---|---|---|---|
| PCIe 3.0 x16(直接接続) | 252 Gbps | 252 Gbps | デスクトップ標準 | 内蔵GPU用 |
| PCIe 4.0 x16(直接接続) | 504 Gbps | 504 Gbps | 現在主流 | ハイエンドGPU標準 |
| PCIe 5.0 x16(直接接続) | 1,008 Gbps | 1,008 Gbps | 最新世代 | RTX 50シリーズ対応 |
| ─────── | ─────── | ─────── | ─────── | ─────── |
| PCIe 4.0 x4(直接接続) | 64 Gbps | 64 Gbps | M.2 SSD標準 | 参考:内蔵x4 |
| OCuLink (PCIe 4.0 x4) ⭐ | 64 Gbps | 64 Gbps | 現在主流 | DEG1はこれ |
| OCuLink (PCIe 5.0 x4) | 128 Gbps | 128 Gbps | 対応製品増加中 | 次世代外部接続 |
| USB4 v1.0 | 20-40 Gbps | 0-32 Gbps | 現在主流 | トンネリング |
| USB4 v2.0 | 80 Gbps | 64 Gbps | 製品化開始 | トンネリング |
| Thunderbolt 4 | 40 Gbps | 32 Gbps | 現在主流 | トンネリング |
| Thunderbolt 5 | 80 Gbps(120 Gbps非対称) | 64 Gbps | 2024年後半〜 | トンネリング |
星印が、DEG 1 と 私が使っている Mini PC の組み合わせのものです。改めて見るとかなり性能ロスが・・・安くないGPUの買い物をして、性能が出せないのはもったいないですが、設置スペースの制約とか、かけられる時間の制約とか、ハードウェアを構築する難易度とかもろもろ考えて、DEG1使う決断をしました。
GPU/グラフィックボード
性能要求を決める
お金が無限にあれば、一番高いグラフィックボードを買うだけですけど、毎月貯金残高が日経平均株価並を推移しているので、コスパを重視します。
では、自宅で動かすLLMで求められる必須パフォーマンスはなにかというと、
- 最低限、ChatGPTのようなチャットインターフェースに特化したLLMを動かせる
本当は以下のような内容もロマンがありますが、高いGPU性能が必要になりそうな気がしたので、オプショナルに。
- 品質の高い画像生成を繰り返し多数できる
- 動画生成ができる
- モデルのファインチューニングができる
上記のようにどのような性能が必要なのかを決めることができたので、選定基準を具体的に検討します。
LLMは VRAMのサイズが命?
細かい話は割愛し、最大公約数的にGPUに求められる性能は何かというと、VRAMのサイズです。
なぜなら、GPUがモデルのパラメータを処理する前に、モデル自体をVRAMに読み込むためです。
AIに聞いた内容の転載で恐縮ですが、もしVRAMが足りないと、 Out of Memory のエラーが発生したり、システムRAMにオフロード・スワッピングする動作がおきて、処理速度が大幅に低下するようです。
必要なVRAMサイズの計算
以下のサイトを参考にしました。
LLMのユーザー目線で、ざっくり、必要なVRAMを求めるには以下のように計算できそうです。
必要なVRAM = パラメータ数 * 量子化 bit のバイトサイズ * (いろいろなバッファとして、1.2)
パラメータ数はシンプルで、Ollamaのサイトでモデルの詳細を見たときに表示される、20b, 8b, 3b などで表示されるもので、b は billion (10億) を表します。
そして、完全オリジナルのオレオレ表現で恐縮ですが、量子化 bit のバイトサイズは、MXFP4や、Q4_K_M, FP4 などいろいろな種類があるようで、それぞれ、 bit 数は細かく違いますが、4 という数字が入っていたら、大体 4 bit ぐらいと考えて差し支えなさそうです。16, 32, 5 などで表現される量子化もあります。
具体例で見てみると、以下の llama3.1:8b の場合、8 billion のパラメータ、quantization(量子化) が Q4_K_M になっています。
計算すると、以下のようになります。
4 GB ≒ 80億 * 0.5 バイト(4bit)

その他、メタ情報などのオーバーヘッドも加えると、最終的には、以下の ollama コマンドが示す通り 4.9 GB になります。ざっくり概算を求めるなら、このような要領で計算するといいかなと思われます。
$ ollama ls | grep 'llama3.1:8b'
llama3.1:8b 46e0c10c039e 4.9 GB 42 hours ago
更に上記で引用したサイトに掲載されいている、LLMにモデル別おすすめのGPUなどが記載されていて、参考になります。Mistral Samml 3 や、GPT-OSS-20B を動かすなら、5060 Ti 16GB のGPUが推奨されるとのこと。

色々総合すると、予算は多くはかけられないけど、最低限の性能は欲しいという場合h、VRAM が、 16GBは必要そうです。....それでも安くはない 💸💸💸
コスパ良さそうな RTX 5060 Ti 16GB に決定
必要なVRAMもなんとなくわかり、コスパが一番良さそうなものとして、5060 Ti を選びました。グラフィックスの性能だけで見ると Radeon RX 9060 XT 8GB のほうがコスパがいいですが、上記の検討の通り、やっぱりVRAMが大事だと思うので、5060 Ti 16GB にしました。このGPUで、gpt-ossも、deepseek も動かせたので、その点満足しています。

OS インストール / ドライバの設定
Windows と Ubuntu をデュアルブートでインストールしました。
以下のサイトの説明がとてもわかりやすかったです。スクショとかも Ubuntu 24.04 のものでした。
大まかな流れは、以下のとおりで、上記サイトの手順をそのままなぞることができました。
- Mini PC に最初から入っている windows のパーティションを小さくして、空きスペースを用意する
- Ubuntu の bootable USB を作成
- BIos で secure boot を無効化
- bootable USB を挿して、Ubuntuをインストール(Install Ubuntu alongside Windows Boot Manager)
Windows 11でのドライバ設定
Nvidia ドライバのインストール

インストールが終わると、Device Manager にこのように NVIDIA のGPUが認識されるようになります。

Task Manager でも NVIDIA GeForce RTX 5060 Ti が認識されるようになります。

Ubuntu 24.04 Desktop でのドライバ設定
Nvidia ドライバのインストール
Ubuntu での Nvidia のドライバのインストールの方法は失念してしまいました・・・
結果的に今以下のようにインストールされていて、nvidia-smi が実行でき、GPUの存在が確認できる状態です。
$ apt search nvidia-driver-580-open
Sorting... Done
Full Text Search... Done
nvidia-driver-580-open/noble-updates,noble-security,now 580.95.05-0ubuntu0.24.04.2 amd64 [installed]
NVIDIA driver (open kernel) metapackage
$ nvidia-smi
Tue Dec 9 21:38:44 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5060 Ti Off | 00000000:01:00.0 Off | N/A |
| 0% 38C P8 5W / 180W | 15MiB / 16311MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1694 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+
以下の記事を参照していたので、これらの記事で紹介されている方法か、普通にNvidiaの公式サイトに行って、示される手順に従ってインストールしたと思われます。
Ollama をインストール
GPU の接続までできたので、次は、LLMを動かすためのミドルウェアをインストールしていきます。Ollama から。
windows のWSL でも、Ubuntu でも以下の Linux 向けのダウンロードページに記載されているコマンドを実行するだけでインストールできます。
# 転載したコマンド
curl -fsSL https://ollama.com/install.sh | sh
そしたら、以下のように動き始めます。
$ systemctl status ollama.service
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Drop-In: /etc/systemd/system/ollama.service.d
└─override.conf
Active: active (running) since Wed 2025-12-10 09:46:35 JST; 9h ago
Main PID: 18656 (ollama)
Tasks: 22 (limit: 15102)
Memory: 6.4G (peak: 8.9G)
CPU: 33.280s
CGroup: /system.slice/ollama.service
└─18656 /usr/local/bin/ollama serve
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=device.go:228 msg="compute graph" device=CUDA0 size="104.8 MiB"
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=device.go:233 msg="compute graph" device=CPU size="5.6 MiB"
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=device.go:238 msg="total memory" size="13.1 GiB"
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=sched.go:482 msg="loaded runners" count=1
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=server.go:1272 msg="waiting for llama runner to start responding"
Dec 10 18:48:45 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:45.447+09:00 level=INFO source=server.go:1306 msg="waiting for server to become available" status="llm server>
Dec 10 18:48:52 my-NucBox-M7 ollama[18656]: time=2025-12-10T18:48:52.718+09:00 level=INFO source=server.go:1310 msg="llama runner started in 8.05 seconds"
Dec 10 18:48:54 my-NucBox-M7 ollama[18656]: [GIN] 2025/12/10 - 18:48:54 | 200 | 10.121538998s | 172.18.0.7 | POST "/v1/chat/completions"
Dec 10 18:48:56 my-NucBox-M7 ollama[18656]: [GIN] 2025/12/10 - 18:48:56 | 200 | 2.293276189s | 172.18.0.7 | POST "/v1/chat/completions"
Dec 10 18:53:56 my-NucBox-M7 ollama[18656]: ggml_backend_cuda_device_get_memory utilizing NVML memory reporting free: 3487236096 total: 17103323136
ollama.service が動いていることが確認できたら、以下のように、ollama コマンドで対話的なシェルで推論実行ができます。
$ ollama run mistral
>>> Send a message
LibreChat インストール
こちらは、公式のインストール手順を参照し、docker compose としてインストールしました。
細かい設定とかせず、とりあえずLibreChatのAIとのチャット機能を動かすだけなら、上記を見てインストール手順を踏むだけである程度は行けました。
ただし、docker のコンテナから、ollama にアクセスさせるために、以下のように ollama が待ち受けるネットワーク・インターフェースの設定は必要でした。
# systemdサービスのオーバーライド設定を編集
sudo systemctl edit ollama.service
エディタが開くので、以下のように、OLLAMA_HOST を すべてのネットワーク・インターフェースにバインドする必要がありました。
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
さらに、やっぱり今どきは web search を有効にして、最新のインターネットの情報に基づくRAGを実行しないと、意味ないなと思い、以下のページを見て設定しました。
サードパーティの検索のAPIキーとかを取得する必要があるんですが、最初のいくらかのリクエストは無料で使えるので、動作確認するのはすぐにできました。いずれのAPIキーも数千回ぐらいは無料で使えるっぽいです。
以下、実際に使用したAPIです。
RAGが必要そうなプロンプトを実行すると以下のような感じです。(モデルは、gpt-oss:20b を使用)

そしたら、以下のように情報を集めてくれました!

その結果の回答が・・・・全く回答になっていない 🤣
この辺は、ローカルLLMの性能の限界や、モデル自体のポテンシャル、特性、システムプロンプトの設定などの調整が必要になるんだろうなと思いました。
おまけの検証: Windows VS Ubuntu
LLMを動かそうといろいろ情報を集めていると、世の中には、WindowsでGPUを接続して、LLMを動かすという例が結構あります。ゲーム需要も考えると、もともとゲーム用途でインストールしたGPUを利用してLLMを動かすということが一般的なんだろうなと思います。(初めからLLMを目的にGPUを買う一般消費者はそうそういないだろうなと・・・)
一方で、UbuntuでLLMを動かすほうがパフォーマンスが上がるというような情報を見つけました。これを確認したかったので、今回WindowsとUbuntuのデュアルブートにしていました。
↓以下の動画の 4分あたりでwindows, 9分あたりでubuntuを動かしていて、ubuntu のほうがトークン生成量/秒が多いことが示されていました。
WindowsとUbuntu両者でのベンチマーク比較は以下です。
OS/プロセッサの組み合わせ別の結果
| 実験ID | OS | プロセッサ | 総実行時間 | プロンプト評価速度 | トークン生成速度 | 生成トークン数 |
|---|---|---|---|---|---|---|
| 実験1 | Windows | CPU | 51.33秒 | 30.34 tokens/s | 8.61 tokens/s | 442 tokens |
| 実験2 | Windows | GPU | 5.75秒 | 136.83 tokens/s | 78.54 tokens/s | 452 tokens |
| 実験3 | Ubuntu | CPU | 46.43秒 | 29.72 tokens/s | 10.66 tokens/s | 495 tokens |
| 実験4 | Ubuntu | GPU | 5.10秒 | 653.15 tokens/s | 83.09 tokens/s | 424 tokens |
OS/プロセッサの組み合わせごとの比較の結果
| 比較 | 環境1 | 環境2 | 性能向上 | 分析 |
|---|---|---|---|---|
| OS 比較 (CPU) | Windows CPU 8.61 t/s |
Ubuntu CPU 10.66 t/s |
1.24倍 | Ubuntuが若干高速 |
| OS 比較 (GPU) | Windows GPU 78.54 t/s |
Ubuntu GPU 83.09 t/s |
1.06倍 | Ubuntuが若干高速 |
| プロセッサ比較(Windows) | Windows CPU 8.61 t/s |
Windows GPU 78.54 t/s |
9.1倍 | 期待通りのGPUによる性能向上 |
| プロセッサ比較(Ubuntu) | Ubuntu CPU 10.66 t/s |
Ubuntu GPU 83.09 t/s |
7.8倍 | 期待通りのGPUによる性能向上 |
Ubuntuがより高速であるということがわかりました!
GPUの場合、CPUの場合、どちらもUbuntuが高速です。
理由はよくわからないですが、Windows環境の場合、WSLなどを介してOllamaを動かすので、その仮想化レイヤーのオーバーヘッドはパフォーマンス劣化の要因に含まれていそうです。
騒音・電気代
GPUといえば、大量の電力を食う、冷却のためのファンがうるさい、みたいなイメージが有りましたが、今回のセットアップでは、そのあたりあまり気になりません。
特に電気代が上がった感覚もないです。それもそのはず、常に使う用途は今のところなく、その間はずっとアイドル状態です。nvtop コマンドで確認できます。
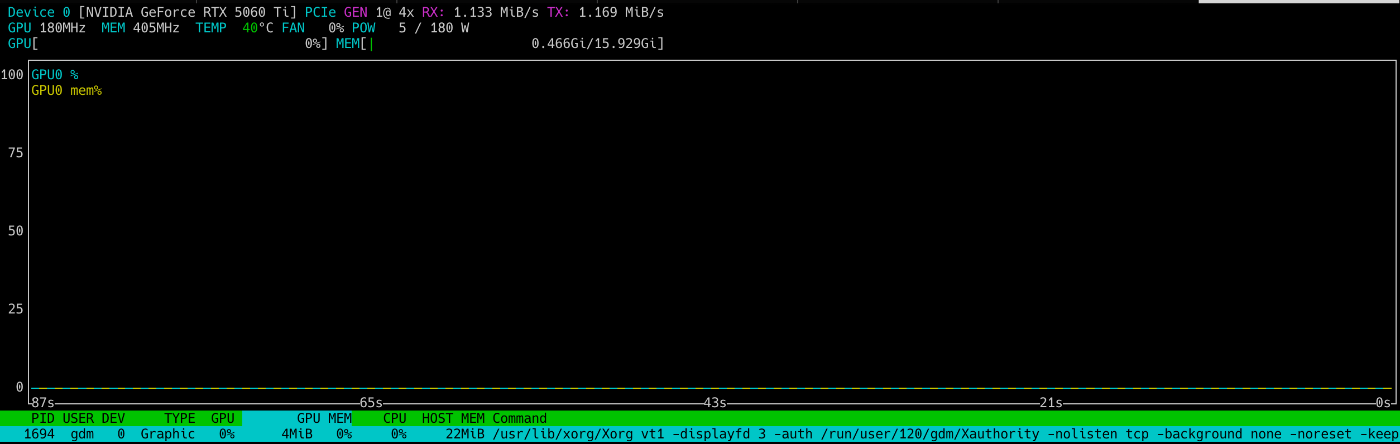
LibreChat でAIが回答している間は、以下のようにGPU と VRAM が使われますが、回答が終わればリソースは使われなくなります。

騒音に関しても、GPU/電源ユニットどちらもファンレスで、アイドル状態のときはファンが止まっているので無音です。動いていても、冷蔵庫より静か。
さらに、アイドル状態の電気代さえも、仕事中は触らないので、systemd のタイマーで電源を切るように設定してあげて更に節約できました。
ハマったところ
ほんとうはめっちゃいっぱいあるんですが、Claude Desktop で質問しながらいろいろ解決しました。とりあえず思い出せるものだけ書いておきます。
電源ユニット選び・接続
めちゃくちゃ地味で初歩的ですが、以下の点を悩みまくりました。
- ワット数は最低限どれだけ必要なのかを検討して、対応した製品を購入する
- 電源ユニットの規格としてSFX・ATXがありどちらか選ぶ。DEG1はどちらも対応していたので良かった。
- 電源ケーブルの種類が多すぎて、意味わからなかった。けど、AIに聞きつつ総当りみたいにやって、なんとか成功。
- しかも電源ユニットも1~2万とかするので、失敗したらまあまあ金銭的にきついという・・・。
最終的には、以下の動画見つつ、アマゾンで対応していそうな製品を選びました。
PCがGPUを全く認識してくれない
これはめっちゃハマりました。DEG1にグラフィックボードと電源ユニットを接続して、光ったりしているので、電気が通っていることは間違い無いんですが、PCに接続して使おうとすると全然認識してくれず・・・グラフィックボードのファンが回ったりもしているので、電源は通っているはず・・・・。なぜ?と頭を抱えましたが、半日間PCの再起動を繰り返し、ネット上の不具合情報とかも大量に読み漁った結果、グラフィックボードがDEG1に物理的にちゃんと挿していなかっただけでした。
↓かすかに見える金色の部分・・・それが奥まで刺さっていなかっただけでした!10万弱するGPUに力をかけて押し込む勇気がなかった。勇気出したら解決しました。

Ollama がGPUを使ってくれない
頭かかえましたが、以下のスレッドと、コメントを見つけて、Ollamaを完全終了してまた開始したらGPUを使ってくれるようになった。(Windowsの場合だったので、タスクマネージャ使って完全終了させた)

コスト総額
環境を作るのにかかった費用: ¥144,862
| No. | 商品名 | 型番/詳細 | 購入日 | 価格 | 販売元 |
|---|---|---|---|---|---|
| 1 | GPU | ZOTAC GAMING GeForce RTX 5060 Ti 16GB Twin Edge (ZT-B50620E-10M VD9182) | 2025/10/22 | ¥72,873 | Amazon.co.jp |
| 2 | Mini PC | GMKtec Nucbox M7 (AMD Ryzen 7 PRO 6850H, 16GB RAM, 512GB SSD, Oculink搭載) | 2025/10/22 | ¥48,727 | GMKtec-直営店 |
| 3 | 外付けGPUドック | MINISFORUM DEG1 (Oculink対応) | 2025/10/22 | ¥11,382 | MINISFORUM JAPAN |
| 4 | 電源ユニット | 玄人志向 KRPW-GA750W/90+ (750W ATX 80 PLUS Gold フルプラグイン セミファンレス) | 2025/10/22 | ¥11,880 | - |
| 合計 | ¥144,862 |
更に、秋になってから、RAM とかストレージの値上がりのニュースばかり目についたので、煽られて、追加注文してしまいました。
| No. | 商品名 | 型番/詳細 | 購入日 | 価格 | 販売元 |
|---|---|---|---|---|---|
| 5 | SSD | Samsung 990 EVO Plus 1TB PCIe Gen 4.0 x4 NVMe M.2 (MZ-V9S1T0B-IT/EC) | 2025/11/13 | ¥15,990 | Amazon.co.jp |
| 6 | メモリ | プリンストン Micron純正 32GB (16GB×2枚組) DDR5 4800 SODIMM (HBN4800-16GX2) | 2025/11/13 | ¥21,800 | プリンストン公式オンラインストア |
| 合計 | ¥37,790 |
💸 💸 💸 💸 💸 💸
合計: ¥182,652
💸 💸 💸 💸 💸 💸
chatgpt plus の年間費用と比べると...
まぁコスパは全然良くないですね😇
でも実験環境としての価値は高いはず...!
(そう思わないと精神に異常をきたしそう)

まとめ
財布へのダメージは致命傷でした 💀
ですがこれで色々実験できる環境が手に入りました。
得られたもの:
✅ GPT-OSS-20B、DeepSeekなどが動く実環境
✅ トークン生成速度9倍の実測データ
✅ OCuLink接続の実践知識
✅ 失敗を含めた「作る」経験
この経験はきっと業務にも活かせる...はず!
(そう信じて痛い出費を正当化しています😇)
🌺 沖縄から「21世紀を代表する会社」を創る仲間を募集
シーエー・アドバンスは、「沖縄のインターネット産業の未来を創る」をビジョンに掲げ、サイバーエージェントグループの一員として、ABEMAやAmebaを支える社内システムを開発しています。 勤務地は沖縄・那覇市 おもろまち。 Next.js 、React、Ruby on Rails、AWS などモダンな技術で、東京・ベトナムのエンジニアと協業。若手が裁量権を持って挑戦できる環境です。
失敗を恐れず挑戦できる文化。一緒にアドバンス(進歩)しませんか?
Discussion