列ストア形式のDBはなぜ分析ワークロードに適しているのか



Bigquery,Snowflakeのような列ストア形式のDBの方がPostgreSQL, mySQLのような行ストア形式のDBよりも分析に適しているとはよく聞きますがその理由について凄く単純化して説明します。
コンピュータは通常、データの長期保存用にハードドライブのブロックに格納します。データは複数のブロックに保存できます。
後でそのデータが必要になったとき、ハードディスク・ドライブはどのブロックに必要なデータがあるかを調べ、それらのブロックを読み込みます。
多くのブロックに保存されたデータは、単一のブロックに保存された同じデータよりも検索に時間がかかります。分析ワークロードの場合、必要なデータを少数のブロックに保存することで、クエリー速度を向上させることができます。
下記のデータがどのようにDBに保存されるかを見ていきます。
| 年 | 年齢グループ | コロナ入院率 |
|---|---|---|
| 2019 | 0~17歳 | 13.9% |
| 2019 | 17~49歳 | 22.5% |
| 2019 | 50歳以上 | 63.7% |
| 2020 | 0~17歳 | 3.9% |
| 2020 | 17~49歳 | 18.5% |
| 2020 | 50歳以上 | 80.1% |
| 2021 | 0~17歳 | 15.5% |
| 2021 | 17~49歳 | 23.3% |
| 2021 | 50歳以上 | 61.7% |
行ストアの場合
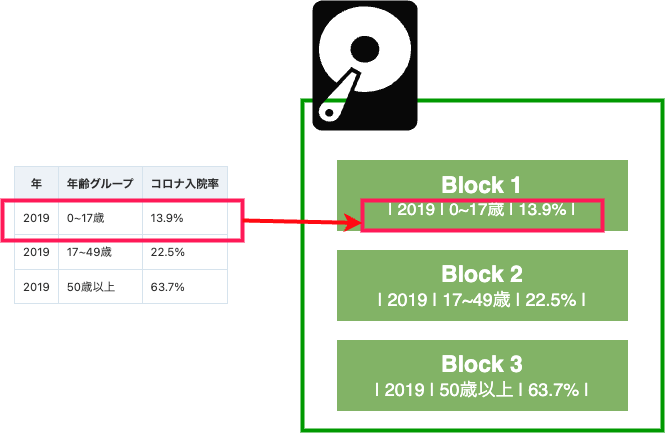
テーブルが行ストア形式で書かれている場合、各行のデータは一緒に保存されます。この図では、2019年シーズンの0~17歳のグループのデータをブロック1に配置しています。この形式は、コンピュータ・システムが新しいデータを新しいブロックに書き込むことでテーブルに追加できるため、トランザクション作業には最適です。しかし、「2019年シーズン、全年齢層の平均入院率はどのくらいか」という質問に関心がある場合、システムは2019年のデータを含む各ブロックを読み込む必要があります。この単純化した例では、3ブロックのデータを読み込む必要があります。この保存方法は、多くのデータ行の要約を必要とすることが多い分析ワークロードでは、比較的時間がかかる可能性があります。
列ストアの場合
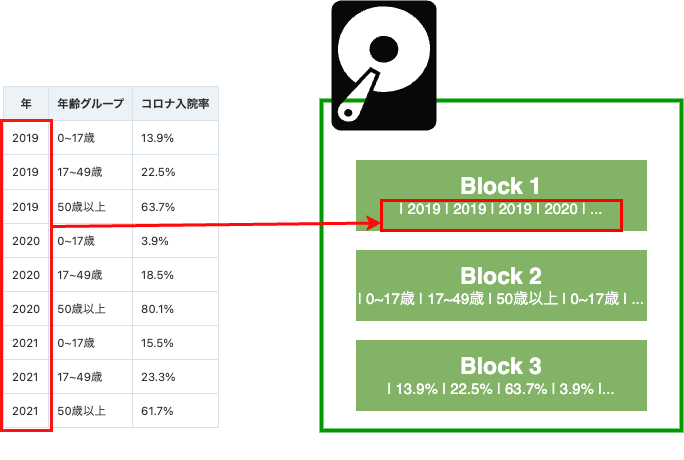
カラム・ストア形式では、カラムのデータをまとめて保存します。例えば、年の列のデータは図のブロック1に示されています。「2019年シーズン、全年齢層の平均入院率は何%か」という質問に対して、コンピュータ・システムはシーズンと割合のデータを含むブロックを読み込むだけでよいため、同じ質問に答えるために使用するデータ・ブロックが1つ少なくなります。このストレージ形式が分析ワークロードに最適で、行ストア形式よりも高速にレスポンスを返すのはこのためです。トレードオフとして、各列のブロックを読み込んで編集する必要があるため、新しい行を追加するのに比較的時間がかかります。最後に、カラム・ストアには、ブロック内のデータがすべて同じ型であるため、データ圧縮が向上するという利点もあります。したがって、同じデータをより少ないスペースで保存することができます。
Discussion