CQRSの観点から考えるGraphQLのスキーマ設計
最初に
GraphQLは参照系のQueryと更新系のMutationの2種類が区別して定義されています。
このように参照系と更新系のinterfaceを分けているため、GraphQLはCommand and Query Responsibility Segregation(CQRS)だと説明されることがあります。
確かにその通りなのですが、なぜCQRSのアーキテクチャなのか、具体的にQueryとMutationを定義する際にどういったことを意識するべきなのかということはあまり説明されていないように思います。
この記事ではCQRSがどういったことを意図しているのか、それを元にどのようにGraphQLでスキーマを設計するべきなのか説明します。
REST APIの問題点とCQRS
RESTはURLで表現されるデータに対してCRUD(Post, Get, Put, Delete)のアクションを定義することでAPIを設計します。
例えば、ある商品(product)を新規登録する場合は次のようなAPIを定義します。
CRUDで表現するとCreateProductとなります。
Post: /api/v1/products
このAPIのユースケースの一例としては、ユーザーがそのwebサービスに商品を登録する場合が考えられます。
特に問題ないように思えますが、APIを使用するクライアントは商品というデータ構造(サーバーサイド的にはDTO)をある程度意識する必要があります。
ここでRESTのCRUDに囚われずにこのAPIのユースケースを言語化してみます。
このAPIを使用するユーザーはProductをデータベースに保存したいのではなく、webサービスにProductを登録したいので、CreateProductよりはRegisterProductが適切にAPIのユースケースを命名できています。
このようにCRUDに縛られることなく、ドメインのユースケースに応じた適切な名前をつけることがCQRSの意義の一つです。
少し脱線しますが、以前話題になっていたこの素晴らしい記事が示唆しているようにエンジニアはまずデータ構造から考えがちです。もしかするとリソースベースで設計するREST APIの影響もあるのかもしれません。
なぜエンジニアが作る画面はダサいのか…?「理由」と「対策」を徹底解説【エンジニア向け画面デザイン講座】
もちろんデータ構造は重要です。ただAPIを設計する上でまず考えるべきは、そのAPIをクライアントがどのように使うのか、如何に使いやすくシンプルなinterfaceとするかです。
APIはそれを使用するクライアントのために作るものです。先ほどの例だと商品を登録したいユーザーのためにAPIを作るので、そのための操作はCreateではなく、Registerであるべきです。
CQRSはクライアントの操作やアクションに紐づくCommandと情報を取得するためのQueryを分割します。
その理由の1つとして、CommandとQueryでは求められる特性が異なるからです。
- Command: 整合性がとれたデータの作成、更新するためにトランザクション処理が必要。そのためにも正規化される必要がある。
- Query: 必要な情報を効率良く取得したいので、非正規化したデータが必要。
求められる特性が異なるのに、同じDTOを使っているとどちらかの要求を満たすための実装が増えて、プログラムはどんどん複雑化していきます。
なので、CommandとQueryでは異なるデータモデルを使用するというのがCQRSの考えです。
また先ほど述べたように、ドメインロジックに関わる命名をREST APIのCRUDだけでは表現しきれないという点もあります。
GraphQLのスキーマ設計
ユースケースに応じたQueryを定義する
REST APIのようにResourceベースではなく、ユースケースごとにQueryを作成するのが望ましいです。
以下にあまり良くない一例として、blogPostsというQueryを定義し、idとname, isPublishedを引数としています。
このように汎用的なAPIとするとサーバーサイドが実装するQueryは少なくなりますが、クライアントがそのAPIをどのように使用すればいいのか把握しづらくなります。
RESTではクエリパラメータによってこのような実装になりがちかと思います。
汎用的なQueryを一つ作るよりも、blogsPostsByIdやblogPostsByName, undisclosedBlogPostsのようにユースケースが明確なQueryを複数定義する方が使いやすく、理解が容易なAPIとなります。
一つのことを上手くやるという教訓がありますが、GraphQLでも同様です。
type Query {
blogPosts(id: ID, name: String, isPublished: Boolean): [BlogPost!]! # bad
blogPostsById(id: ID!): [BlogPost!]! # good
blogPostsByName(name: String!): [BlogPost!]! # good
undisclosedBlogPosts: [BlogPost!]! # good
}
計算が必要な情報はGraphQLサーバで補う
以下の例では、Orderの総額をtotalPriceで返しています。
type Query {
orderById(id: ID!): Order
}
type Order {
id: ID!
items: [Item!]!
totalPrice: Int!
}
type Item {
name: String!
price: Int!
}
itemsに注文商品一覧があるので、総額はitemのpriceをクライアント側で合計すれば算出することもできます。
一方でクライアント側で算出するとサーバーサイドとクライアントで不整合が生じる可能性もあります。こうしたビジネスロジックに関わる部分はサーバーサイドで計算し、クライアントはただ値を表示するだけとするのがベストです。
また、totalPriceをリクエストに含めない限りはGraphQLサーバーでも計算されないため、必要なときだけ計算可能です。
GraphQLではビジネスロジックに関わるデータやユースケースの都合をサーバーサイドで積極的に吸収することを心がけましょう。
CQRSはドメイン駆動設計を実践するためのプラクティスでもあります。
GraphQLで設計するモデルは単なる属性のfieldだけでなく、ユースケースに応じて計算されたfieldも含めるべきです。GraphQLのモデル設計でもドメイン駆動設計で言われるドメイン貧血症を避けるようにしましょう。
Mutation
type Mutation {
registerProduct(input: ProductInput!): RegisterProductPayload # good
createProduct(input: Product!): Product # bad
}
type Product {
name: String!
description: String
price: Int
options: [Option!]!
}
type RegisterProductPayload {
userErrors: [UserError!]!
product: Product
}
type UserError {
message: String!
field: [String!]
}
input RegisterProductInput {
name: String!
description: String
price: Int
}
上記の例では、商品を登録するMutationを定義しています。
CQRSではCRUDにとらわれず適切な命名でユーザーのアクションや操作を定義することが重要です。ここではユースケースに合わせてcreateProductではなくregisterProductとしています。
また、createProductの例ではProduct typeを引数に持っていますがこれもNGです。
CQRSの考えに基づき、QueryとMutationのデータ構造は区別する必要があります。
例えば、商品を登録する際にそのオプションは指定しないという要件だとすると、Productのoptionsというフィールドは不要です。
CQRSの特徴を意識して、同じモデルに対する操作でもQueryとMutationでは使用する型を変えます。
Mutationの引数はユーザーのアクションの際に必要な情報を過不足なく表現しましょう。
基本的にはMutation一つごとにユニークなinputを定義すると良いです。機械的にmutation名 + inputで命名します。
今回の場合はregisterProduct + input = RegisterProductInputです。
また、戻り値も同様にMutationごとにmutation名 + payloadで独自の型を定義しています。
更新処理には不正な値が入力されたりして失敗がつきものです。戻り値で作成したデータの情報を返す以外に、失敗した場合はuserErrorsでその原因を返しています。
GraphQLはdataとは別にerrorsでエラーの値を返すことが一般的ですが、アプリケーション都合のエラーは別で定義して返すと扱い易いです。
IDを付ける
GraphQLを使用したアプリケーションは次のように一方向のデータフローで処理が行われます。
- Queryで必要なデータを取得し、画面に表示する。更新処理が必要な場合は、その中から情報をpickupしてMutationを実行する
- Mutationでイベントを処理する。
- Queryを再実行してMutationで更新されたデータを取得して画面に反映する。1に戻る。
CQRSでは3つの領域があるとして説明されており、上の1,2,3と対応します。
- Client: DTOを消費してコマンドを生成する。
- Domain: コマンドを消費して、イベントを生成する
- Read Model: イベントを消費してDTOを生成する。
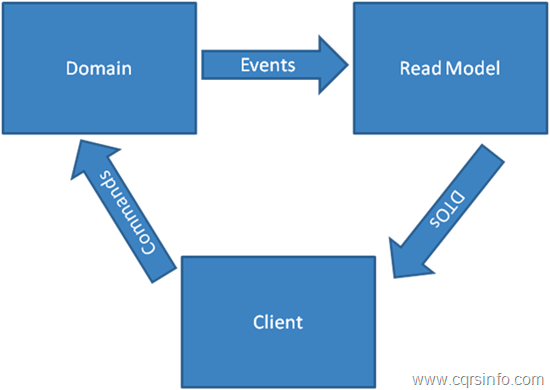
GraphQLクライアントのApollo Clientやurql, relayはクライアントキャッシュの生成とそのpurgeによってこのデータフローを実現しています。
ApolloだとMutationの後にrefetchQueriesを実行することで実現しますし、urqlはMutation後に__typenameから関連するキャッシュを見つけて全てpurgeします。
このキャッシュ戦略を効率的に行うために、GraphQLの各typeにはIDを設けることが重要です。
relayの規約では、Nodeというidのみを持つinterfaceを定義して、それぞれのtypeはこのNodeをimplementすることが推奨されています。
interface Node {
id: ID!
}
type Person implements Node {
id: ID!
name: String!
age: Int
}
ドメインに関連する具体的な命名とする
GraphQLに限った話ではないですが、定義するtypeはドメインに関連する具体的な命名にしてください。
例えば、Userという名前は管理者なのか、エンドユーザーなのかわかりません。
AdminUserとEndUserという二つのtypeを定義した方が明確です。
汎用的な名前をつけるのではなく、ドメインと関連する具体的な命名にしましょう。
type AdminUser implements Node {
id: ID!
name: String!
}
type EndUser implements Node {
id: ID!
name: String!
}
Schema First, Code Firstについて
ここまで述べてきたようにGraphQLはUIを作成するクライアントのためのもので、データ構造を意識したリソースベースではなく、クライアントのユースケースに応じた設計とする必要があります。
なのでGraphQLのサーバーを実装するエンジニアだけではなく、フロントエンドやモバイルエンジニアもスキーマ設計に参加するべきですし、簡単に把握、編集できることが重要です。
よくSchema First vs Code Firstの議論がありますが、どちらで開発するにしてもAPIの仕様を決める際にはgraphqlファイルで議論したり、graphqlファイルのPRを作成することで設計するべきだと自分は考えています。
なぜならgraphqlファイルを作成せずにサーバーサイドのコードのみで定義すると、どうしてもその言語に馴染みのないクライアントサイドのエンジニアがAPI設計に参加しづらくなり、サーバーサイドのエンジニア都合で仕様が決まりがちだからです。
GraphQLのサーバー実装方法は使用するライブラリによって異なりますが、クライアントサイドのエンジニアもAPIの設計に関わることができる開発フローにするべきです。
GraphQLが適していないユースケース
ここまでGraphQLについて説明してきましたが、もちろんGraphQLが有効でないケースもあります。
例えば、以下のような例があります。
- サーバー間通信
- UIで使用されることを想定していないAPI
GraphQLはUIの変更に迅速に対応するためにクライアントがfetchする情報を柔軟に変えられること、fragment colocationしてUIのコードと同じデータ構造でレスポンスを受け取れることが利点です。
サーバサイドで何かしらのAPIを使用する場合はAPIから取得したデータを用いて計算処理を行い、特定のロジックを実装するために使用しているはずです。
その場合にAPIの戻り値を木構造で取得したいというモチベーションはなく、リソースベースで2次元情報を返すREST APIの方が扱い易いです。
例えば、Stripe APIは決済という特定の処理をサーバーサイドで行うために使用するので、GraphQLで提供されても利点はないでしょう。
GraphQLは銀の弾丸ではなく運用する際はRESTとは異なる苦労があります。(モニタリング、クエリの制限、N+1, キャッシュなど)
適切なユースケースでGraphQLを使用しましょう。
最後に
GraphQLスキーマ設計についてCQRSと関連付けていくつか説明しました。
GraphQLで重要なことはクライアントが望むものを返すことなので、サーバーサイドの実装詳細に影響されずクライアントにとって使いやすいスキーマ設計にしましょう。
また、実際にGraphQLを選定する際はProduction Ready GraphqlやShopify/graphql-design-tutorial、GitHub GraphQL APIなどを参考にすることをおすすめします。
Discussion