KubernetesでFluentdの信頼性を担保するための3つの観点
概要
GKEなどを使えば自動的に標準出力のログが集計&集約され、Cloud Loggingなどを通して可視化されますが、
オンプレミス環境でKubernetesクラスタを構築する場合そうはいきません。
また単純なアプリケーションログの集計以外にも、
Kubernetesを使ってログ、データ集計をしている人はFluentdを運用しなくてはならない人は多いと思います。
本記事では、ログの集計、集約のデファクトスタンダードであるFluentdをKubernetes上に展開する上で、
信頼性を担保するための観点を整理します。
想定アーキテクチャ
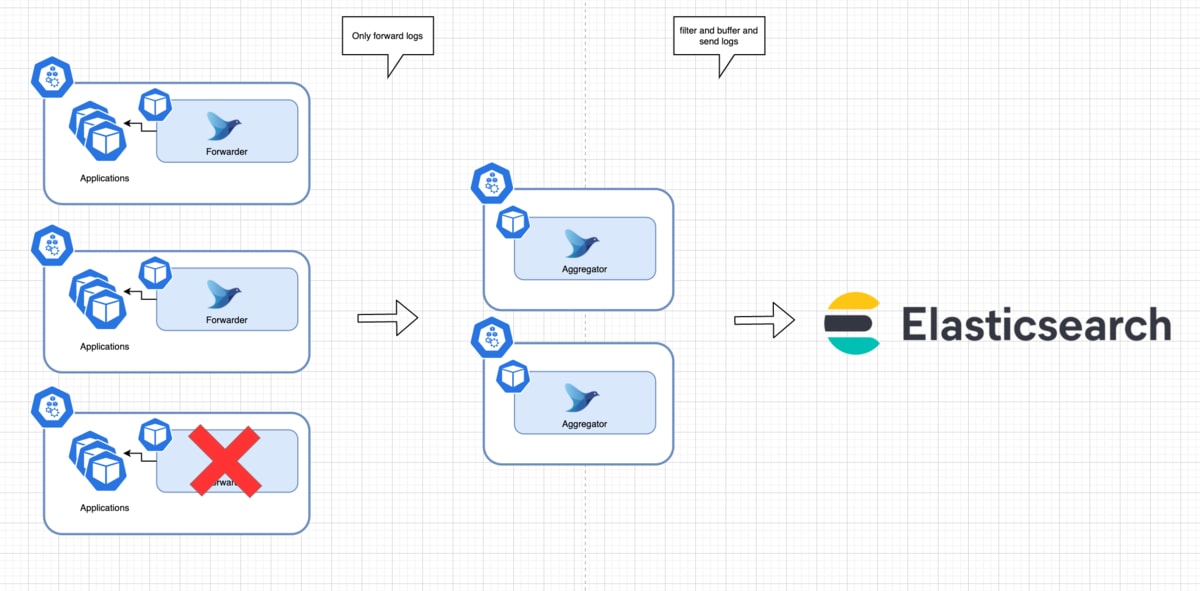
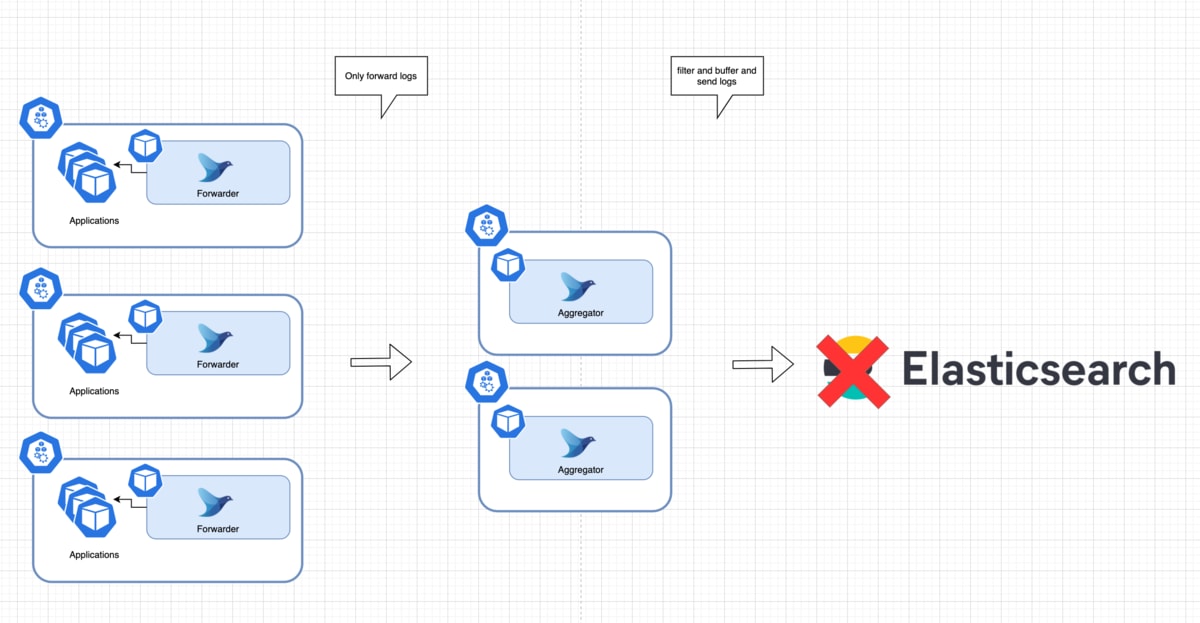
想定アーキテクチャとしては現場でよく構築されている、図のような構成を用います。

アーキテクチャの特徴
クラスタに、FluentdがForwarderとAggregatorという2つのロールでそれぞれ存在しています。
-
Forwarder
- DaemonSetでデプロイされる
- 各コンテナの出力ログをあつめ、Aggregatorに送信することだけが唯一の責務
-
Aggregator
- Deployment(もしくはStatefulSet)でデプロイされる
- ForwarderからTCPでログを受け取る
- filterを用いた加工処理や、最終的なデータストアへのログ送信を担う
-
ForwarderはAggregatorへServiceリソース経由でアクセスする
担保すべき信頼性
今回は「どこかに障害が発生したとしてもできる限りログを損失しないこと」を目標とし、
Forwarder, Aggregatorそれぞれで下記3つの観点をチェックしていきます。
- Podのクラッシュへの対応
- Podの退避への対応
- ログの宛先のダウンへの対応
※またログの損失を予防する代わりに、重複するログは多少許容することとします。(at-least-once)
1.Podのクラッシュへの対応
Forwarderの場合
Forwarderの役割は実際のログファイルから少しずつログを読み取りAggregatorへ送信することです。
また、Fluentdはパフォーマンス向上や、ログの送信先がダウンしていても問題ないようにバッファリング機構を持っています。
この前提から、FowarderのPodがクラッシュするときに想定したい注意点として以下の2つがあげられます。
(1) クラッシュからの復帰後、以前読んだところから読み取りを再開できるようにする
「ログの読み取り済みの位置を記録する」ことで対応します。
ログをファイルから読み取るとき、通常tail pluginを用いますが、
tail pluginにはpos fileという機能があります。
これを使うことで、読み取ってからバッファ済みになったログファイルの位置を記録しておくことができます。
(2) バッファされた未送信のログの損失を防ぐ
こちらは「未送信のバッファを永続化しておく」ことが必要です。
バッファリングにはメモリバッファとファイルバッファがありますが、
ファイルバッファを使っておくとクラッシュ時に損失を防ぐことができます。
Aggregatorの場合
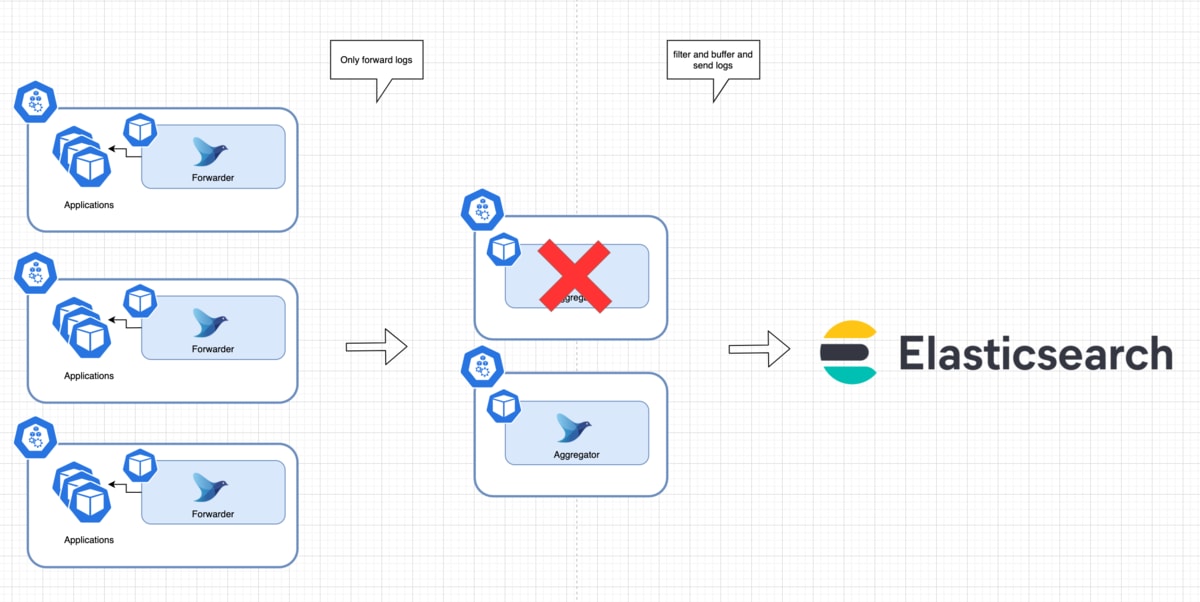
Aggregatorの役割は、ForwarderからTCPで受け取ったログを加工、フィルタ処理を行い、最終的なデータストアへ送信することです。
受け取った時点で、加工処理が走り、バッファに書き込みがされてからForwarderへACKが返ります。
なので、Aggregatorとしては受け取ったログのbufferをPodがクラッシュしたとしても保持し続けることが大事です。
これは、Forwarderで用いたfile bufferを指定しておけばOKです。
2. Podの退避への対応
Podの退避、移動や削除は以下のような様々なタイミングで訪れます。
- NodeのShutdown(Scale Inなど)、Replace、メンテナンス
- DaemonSet, DeploymentのUpdate
つまり、Podの削除とノード間移動を前提に考えなくてはいけません。
Forwarderの場合
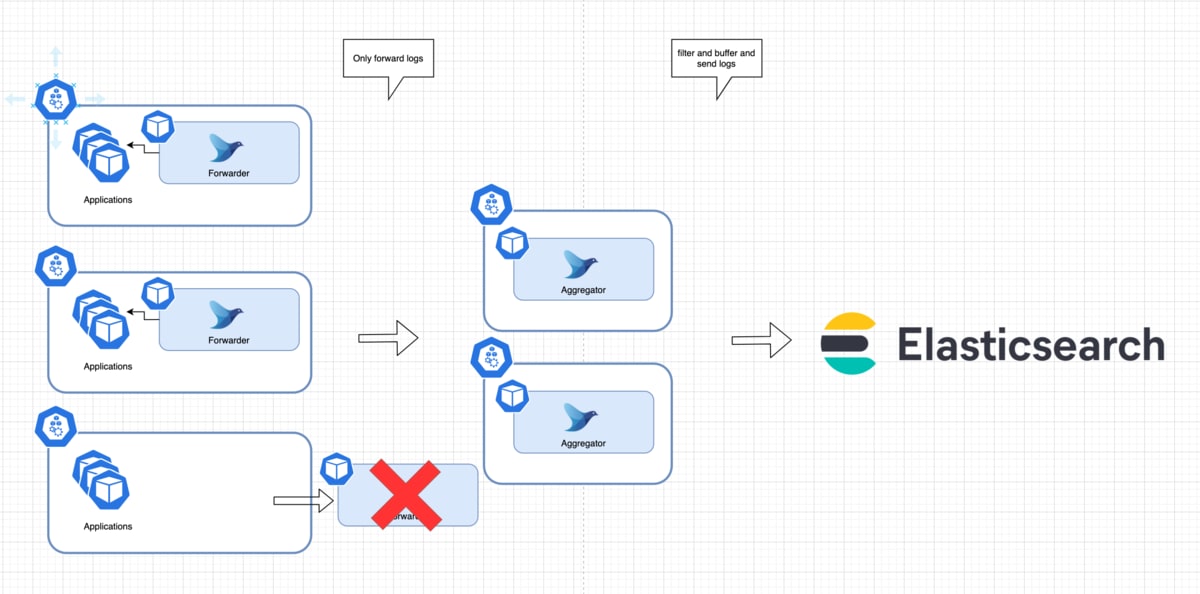
ForwarderはDaemonSetなので、
DaemonSetのUpdate発生時、Nodeが特にShutdownしないようなケースであれば、
hostPathに前述のpos fileとfile bufferをおいていればPodがいかに入れ替わろうと復旧可能です。
※ただしemptyDirはPodが退避されると一緒に削除されるのでNG
しかし、NodeもShutdownするケースは、Nodeのディスクにデータを残しておけば済む話ではないため注意が必要です。
よって、以下の2点を考慮する必要があります。
(1) Nodeがshutdownしてしまうので、プロセス終了時にバッファをflushする
flush_at_shutdownというパラメータがbufferingの設定の中にあるので、これを有効にしておけばOKです。
また、ちゃんとflushするのに必要な時間を確保するため、terminationGracePeriodSecondsは十分に取っておきます。
(2) プロセス終了時のflushのタイミングでAggregatorがダウンしているケースを考える
このケースは完全にログの送信を担保することはできません。
プロセスshutdown時にflushが失敗した場合、
secondaryを設定していればsecondaryにバックアップしてくれるような実装になっていれば回避できますが、
現状コードを読む限りそうはなっていません。
つまりどうしても損失させられないようなログ(監査ログなど)は、
はじめからsecondaryではなくcopyプラグインを活用して、複数箇所に同時に保存しておく、
といった対応が必要になります。
Aggregatorの場合
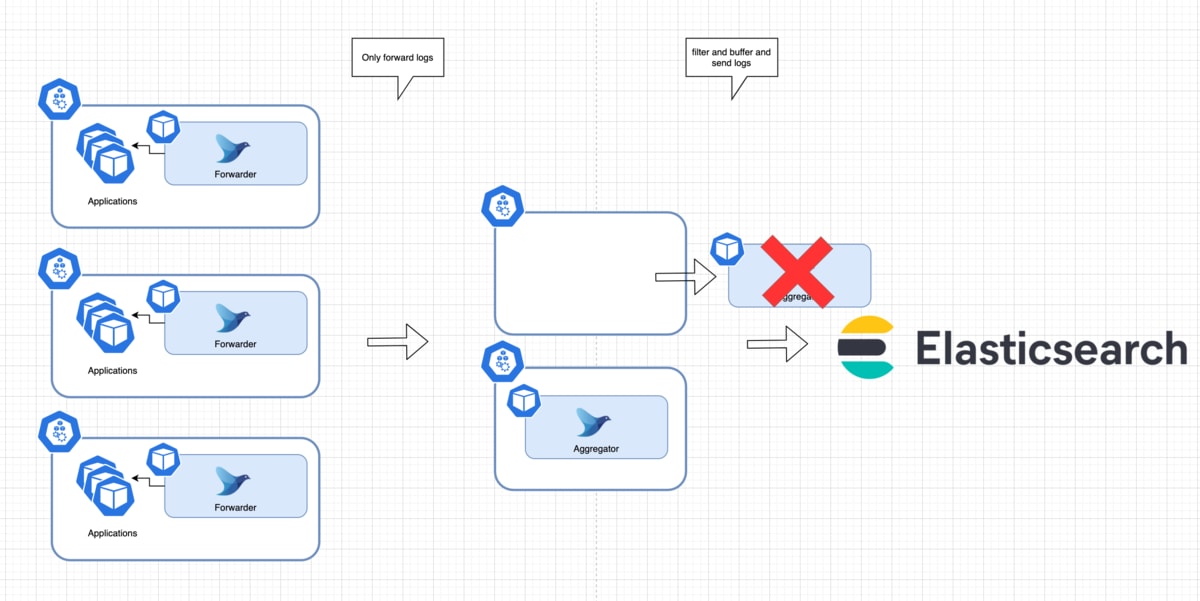
DaemonSetと違うのは、すべてのNodeに1台だけ存在する構成にはなっていないので、
Node配置のAffinity設定や、一気にPodがダウンしないように気を使ってあげる必要があります。
またDaemonSetと違い、TCPでリクエストを受ける構成なので、
プロセスshutdown時にSIGTERMとbuffer flushのタイミングを考えなくてはいけません。
それを踏まえ、下記の2点を検討します。
(1) Pod削除時にbufferをflushする
Forwarderのときと同じく、flush_at_shutdownを行います。
AggregatorはForwarderと違って、TCPで通信を受け付けるので、
新規のリクエストを止めてからflushするようにする必要があります。
具体的にはPodのpreStopでsleepさせて、し
っかりServiceへのリクエストを止めてからSIGTERM => flush処理に移るようにするのが安全です。
また、flush時に宛先がdownしているとForwarderと同じようにデータが損失してしまうため、 Volumeをアタッチしておき、バッファの保存先をそこに指定おけば復旧可能になります。
(2) 一気に複数のPodが同時にUnavailableにならないようにする
特定NodeにPodが集中しないよう、Affinity設定を入れます。
また、PodDisruptionBudgetを活用し、UnavailableなPodの数を制限するようにします。
3. ログの宛先のダウンへの対応
Forwarderの場合
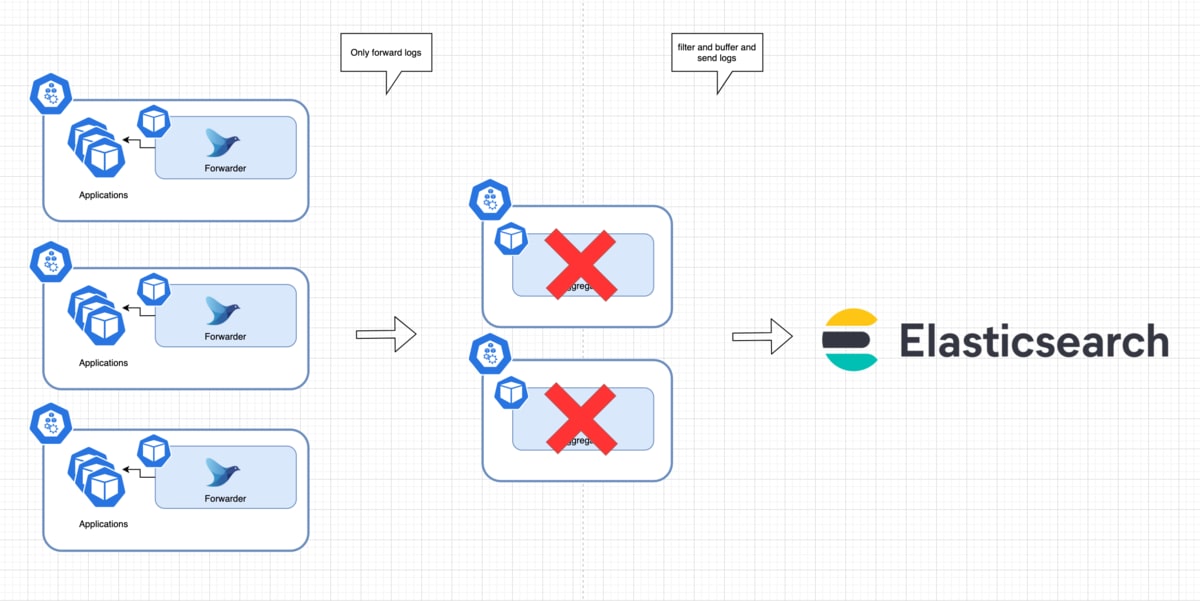
宛先がダウンしている場合でもログが失われないようにするために、前述したfile bufferを用います。
この際、2つ注意点があります。
(1) Aggregatorがバッファに書き込み完了したことを保証する
AggregatorがTCPでログを受け取っても、バッファにちゃんと書き込まれているとは限りません。
よって、Aggregatorがデータを受け取った直後、バッファに書き込まれる前にプロセスが終了してしまった場合データが失われます。
これに対応するため、
forwardのpluginには、Aggregatorがbufferに書き込み完了しACKを返すまで、送信が完了したとみなさないようにするパラメータがあります。
このパラメータを有効にすることで、Aggregator到達時点まではat-least-onceを保証することができます。
(2) Aggregatorへの送信失敗に備える
Aggregatorへの送信が失敗に備えるには、バッファの永続化、リトライ、secondaryを意識する必要があります。
そして、送信失敗したとしても復旧可能にしておく方法として2つ手段があります。
-
リトライを無限にし、バッファをHostのディスク領域に永続化しておく
-
リトライ回数に制限を設けておき、制限に達したらsecondaryの送信先に送信する
バッファサイズは、ディスク容量、オープンできる最大ファイルディスクリプタ数、時間辺りのログ流量 * 障害許容時間などを加味して決定します。
またsecondaryは、リトライが制限に達するか、回復不可能なエラーが発生した場合に送信先として使われることになります。
Aggregatorの場合
Aggregatorの場合は、Forwarderと違い、require_ack_responseなどのパラメータは使えません。
到達保証は宛先データストアと宛先へのoutput pluginの実装次第になります。
Datastoreへの送信失敗に備える
こちらもForwaderからAggregatorへの送信失敗ケースと同様の観点で考えます。
-
リトライを無限にし、PersistentVolumeをAttachしてそこでバッファのファイルを永続化する
-
リトライ回数に制限を設けておき、制限に達したらsecondaryの送信先に送信する
Aggregatorの場合は、DaemonSetではないので必ず同じノードで起動してくれる保証はありません。 そこでDeploymentではなくStatefulSetでデプロイしておき、VolumeをAttachすることでバッファを永続化しておくことができます。
まとめ
まとめるとこれまで、述べた3つの観点に対し、下記のように対応すればOKです。
-
Forwarder
- input
- tail ではpos fileを設定する
- output
- file bufferを使う
- require_ack_responseを設定する
- hostPathにfile bufferを永続化しておく
- flush_at_shutdownを設定する
- pos fileやbufferingにはemptyDirを使わない
- どうしても失いたくないログはcopy pluginで二重に保存しておくと安心
- input
-
Aggregator
- affinityで分散しておく
- PDBで一気にunavailableにならないよう気をつける
- リクエストを止めてからflushするようSIGTERMのタイミングを調整する
- outputでは、
- file bufferを使う
- VolumeをAttachしてそこにfile bufferを永続化しておく
- flush_at_shutdownを設定する
- bufferingにはemptyDirを使わない
- どうしても失いたくないログはcopy pluginで二重に保存しておくと安心
Discussion