ログ検索を爆速にするGrafana Loki 3.0の新機能: Bloom Filter + Ngram検索



はじめに
Grafana Lokiは今やログのモニタリングでスタンダードとなりつつある、コスト効率性の高いプロダクトです。
そんなLokiですが最近3.0がリリースされました。
このバージョンには非常に面白いアイデアが採用されていて、Bloom FilterとNgramの仕組みにより、オブジェクトストレージやキャッシュからのデータダウンロード量を大幅に削減しています。
Grafana Cloudの環境下ではおよそ70 ~ 90%のダウンロードデータを削減できたようです。
本記事では、この仕組みについて詳しく解説しようと思います。
従来のGrafana Lokiの検索の仕組み
Grafana Lokiにおいて重要な概念が3つあります。
「Series」、「Chunk」、「Index」です。
Series
例えばこのようなログを仮定します。
{service="travel-api", environment="production", pod="travel-api-0"} [INFO] Service started
このログのラベルのKey-Valueペアである、
{service="travel-api", environment="production", pod="travel-api-0"}
このユニークな組み合わせをSeriesと呼びます。
それぞれのSeriesはユニークなIDを持っています。
Chunk
Chunkは一つのSeriesに紐づいていて、サイズや時間でまとまったログの塊です。
この塊はLokiのconfigに依存しますが、あるSeriesのログが一定時間、もしくは一定サイズたまったタイミングで一つのChunkとして書き出されます。
当然一つのSeriesには複数のChunkが紐づいていて、時間経過によって紐づくChunk数は増えていきます。
それぞれのChunkもまた、ユニークなIDを持っています。
Index
Indexは、ラベルの組み合わせから該当するSeriesを特定するための転置Indexです。
たとえば、
{service="travel-api"}
というラベルの組み合わせがQueryで与えられたとき、
{service="travel-api", environment="production", pod="travel-api-0"}
上記のような該当するSeriesを索引するためのデータ構造です。
重要なのは、Indexしているのはラベルのペアだけであり、ログの中身については一切関知していないということです。これによってIndexデータサイズを大幅に削減しています。
検索の仕組み
従来のLokiでは、まず与えられたラベルの組み合わせをもとにIndexデータベースから該当するSeriesを取得します。そして、与えられた検索の範囲時間から該当するChunkのIDを取得します。
その後取得したChunk IDに該当するChunkをオブジェクトストレージ、もしくはChunkキャッシュ(MemcacheやRedisなど)から取得します。
取得したChunkをパースした後、
{service="travel-api"} |= "reqID=xxxxxxx"
のようなフィルタリング条件がある場合は、パースしたデータを一つずつ確認してQueryの条件を満たすものだけ抽出し、結果に集約されていきます。
そしてすべてのChunkが走査されたら結果が返却される、という仕組みになっています。
詳しくは私の過去のCNDTの登壇でも詳しく解説しています。
従来の検索方法の大きな問題点
ここで大きな問題点があります。
Indexはログの中身自体は見ていないため、{service="travel-api"}に該当するChunkを一旦すべてダウンロードしてからフィルタリングする必要があります。
しかし、reqID=xxxのような条件は大抵の場合、数個のログだけにヒットするようなものです。
それにも関わらず、一度{service="travel-api"}にヒットするログのChunkをすべて収集しなくてはいけないのです。
Grafana Labsの公称によれば、50 ~ 60%ものChunkは一切使われることなく捨てられているようです。これは大きな無駄です。
Lokiを使っていて、たった数行のLogを抽出するのになんで何十GBも処理されているのだろうと感じ方も多いのではないでしょうか?
Bloom FilterとNgramによるアプローチ
では、どのように解決すればよいでしょうか?
事前に明らかに不要になるSeries、Chunkが特定できれば無駄なダウンロードをせずに済みます。
そこで導入されたのがBloom FilterとNgramの合せ技です。
Bloom Filterとは?
Bloom Filterとは検索対象のデータに対して、実際に検索する前に「与えられたKeyのデータが存在しないこと」を高速にチェックするためのデータ構造及びアルゴリズムです。
例えばある配列bloomを仮定し、配列のindexにhash値、配列の値にフラグを持つとします。
あるKey、"keyA"のデータを保存するとき、"keyA"のhash値を計算しbloom[hash(keyA)]のフラグを立てます。
するとその後、"keyA"のデータを検索しようとした場合は、同様にhashを計算してbloomをチェックします。
すでにkeyAの配列indexにはフラグが立っているので「データが入っているかもしれない」ことがわかります。
ここで「かもしれない」としたのはハッシュが衝突する可能性を考慮したためです。
また、Keyが"keyB"のデータを検索する場合、"keyB"のhash値のデータはまだbloomに存在しないため、確実に存在していないことが断定できます。
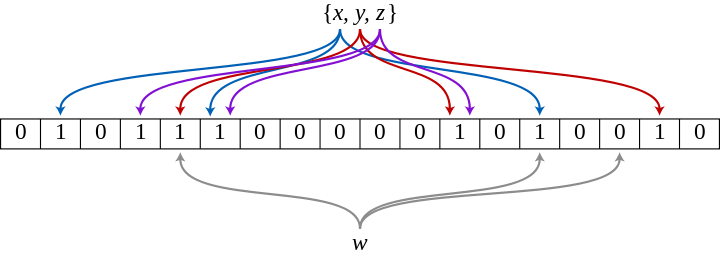
引用:https://en.wikipedia.org/wiki/Bloom_filter
Bloom Filter + Ngramによる新しい検索手法
ではこれを使ってどうやってQueryを改善するのでしょうか?
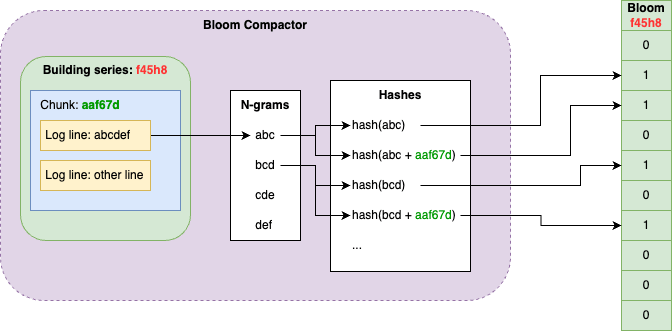
まずSeriesごとに一つのBloomをそれぞれ保持します。
そしてログが保存された後、そのログの内容の文字列についてNgramを取ります。
画像の例だと、"abcdef"という文字列がログの中身だとすると、このトリグラムを取るとabc, bcd, cde, defとなります。
これらのトークンに対してハッシュ値を計算し、該当するSeriesのBloomに対してフラグを立てていきます。
また同時に、その保存時間帯のChunkのIDを識別し、トークン + ChunkのIDのハッシュ値を計算して該当SeriesのBloomのフラグを立てます。
(なぜこのようにするかは後述します)
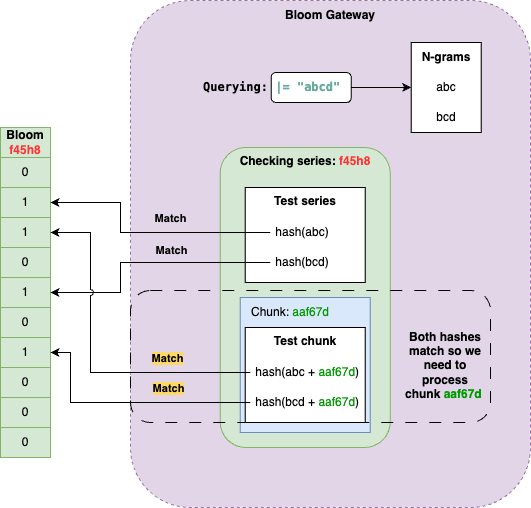
検索されるとき、Indexから該当のSeriesとChunkのIDを取ってきたら、対応するSeriesのBloomをチェックします。
例えば"abcd"という文字列が含まれるログを検索しようとしたら、"abcd"という文字列をNgramで分解し、"abc", "bcd"というトークンを得ます。(今回のではトリグラムと想定)
これらのトークンに対してハッシュ値を計算し、すべてのトークンのハッシュ値に対してbloomのフラグが立っているかをチェックします。もしどちらか一方、もしくは両方立っていない場合、このSeriesは検索対象から除外することができます。
また検索時にはターゲットとなるChunkのIDも識別されているので、そのすべてのChunkに対して、hash(abc + chunk id)とhash(bcd + chunk id)がbloomでフラグが立っているかをチェックすることで、不要なChunkも同様に除外することが可能です。
(これがChunkのidをhashに加えるパターンでもbloomに保存していた理由です)
これにより、Queryによっては相当数のChunk、Seriesをダウンロード対象から事前に除外することが可能になります。
恩恵を受けるQueryと受けないQuery
もちろんこのアプローチは万能ではありません。
reqID="xxx"のような数行のログをヒットさせたい場合には絶大な効果を発揮しますが、例えばreqID!="xxx"のようなネガティブ検索の場合、うまく機能しません。
この場合は引き続き従来の方法でターゲットChunkをすべてダウンロードしてからフィルタリングする必要があります。
Grafana Loki query acceleration: How we sped up queries without adding resources
こちらのブログにもどういうときにうまくいき、どのようなときはうまく動作しないかを述べているので参考にしてみてください。
まとめ
本記事では、Loki3.0で導入された、Bloom Filter + Ngramでどのようにログ検索を爆速にしているかを紹介しました。
実際には特定のログだけ抽出したいといったケースがほとんどだと思いますので、かなりのユースケースでこの機能の恩恵を受けられるのではないでしょうか?
気になる方はリリースノートをチェックして、ぜひ試してみてください。
Discussion