GoのMemory fragmentationの発生理由と対処法
本記事について
Goで開発している中で、なぜかobjectは確実に解放されているはずなのに、
プロセスのメモリ使用率が下がらず、逆にどんどん増加し続けてしまう問題に遭遇しました。
結論から言うとこれはmemory fragmentationが問題で発生しており、
本記事ではなぜその問題が発生したのか、そしてそれをどのように解決したのかを整理していこうと思います。
前提
私はPrometheus互換の時系列データベースを開発するチームに所属しており、その中にIn-Memoryなストレージコンポーネントが存在しています。
時系列データとは、timestampとvalueを持ったdata pointsの集合で、
私達のストレージでは4時間ごとのdata pointsを"chunk"と呼ばれるデータ構造にまとめて保持しています。
例えばCPU使用率のmetricsを想像すると、どの時間にどのくらいの使用率だったかといったデータが保存されています。
そして1つのchunkは1つのmetricに対応していて、1つのmetricあたり最大8つのchunkを同時に保持します。
8つ以上にならないよう、4時間ごとにそれぞれのmetricに対して一番古いchunkを削除しています。
またIn-Memoryであるため、データをプロセスの再起動で失わないように、snapshot機能を持っています。
これによって、再起動したときにこのsnapshotとwalのようなログから起動前の状態を完全に復元することができます。
問題
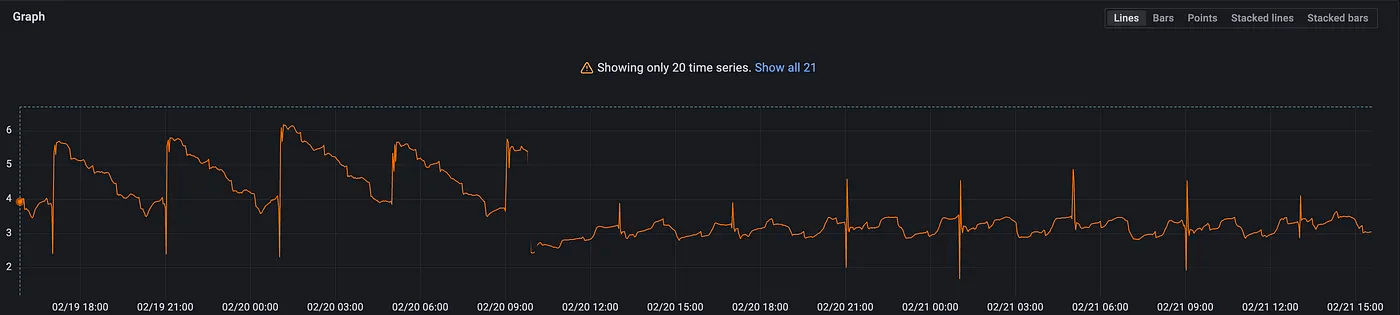
このIn-Memoryストレージを再起動してからおよそ32時間 ~ 36時間程度の間、プロセスのMemoryの使用量が継続的に伸び続けてしまう現象が発生しました。

Go pprofによる調査
まずメモリリークを疑い、go pprofを使ってheap profileをとってみることにしました。
大体1時間ごとにprofileを取り、差分をみていくことで、解放されずに残っているobjectはないか、
何がmemoryを専有しているのかを詳細に調査しました。
しかしchunkは意図通りに4時間ごとにexpireしており、不審な占有objectも見つけられませんでした。
さらに、totalのheap使用量も、問題のないノードと同じくらいしかないこともわかりました。
つまりheap自体は使用していないのに、プロセスとしてはより多くのメモリを必要としてしまっているということです。
Go memstatsによる調査
GoのPrometheusの計装ライブラリを使うことで、Goのmemstatsの情報がmetricsとして観測することができます。
go_memstats_heap_inuse_bytes{…} - go_memstats_heap_alloc_bytes{…}

このメトリクスを見ると、4時間ごとに急激な増加が発生しているのがわかります。
この結果は、heapがinuseとして扱われているのにも関わらず、
allocateされて実際に使われてるspaceが少ないことを表しています。
つまりFragmentationが多く起こっている可能性があることを示しています。
通常は4時間ごとにいくつかのchunkが削除され、そのタイミングで一旦allocated spaceが減るので増加自体は想定どおりです。
しかし通常は、新しく来るdata pointsが空いているスペースに埋められて、このfragmentationは減少していく傾向にあります。
それが再起動してからの36時間はまったく減る気配がないため、削除によって空いたスペースが有効に使えていないのではないか、そしてそれはmemory fragmentationによって発生しているのではないかという仮説を立てました。
Snapshotからの復旧処理の修正
私たちのストレージのsnapshotは、すべてのchunkのbyte列をファイルに書き出す単純なものです。
しかし、並行処理と効率化の関係上、chunkのbyte列は読み取った順にどんどん書き込まれます。
そしてこのsnapshotファイルは復旧時には頭から順に読み込まれるので、この並びが復旧時にallocateされていく順番になります。
これが時系列順に並んでいないので、4時間ごとのchunkの削除タイミングでいわばあなぬけ状態になり、画像のように隙間ができているのではないかと考えました。

そこで、snapshotをファイル書き込み前に時系列順にソートするように修正し、復旧時のallocationも時系列順に発生するようにしました。
こうすれば削除のタイミングでもきれいに時系列順に前からリリースされ、空いたスペースを新しいdata pointsで有効活用できると考えました。
しかし改善されるどころか、ソートのコストでsnapshotの作成が遅くなってしまいました。
Goのheap管理とsize class
Goのheapはmspanという単位で管理され、
各mspanは8KBの連続したいくつかのページで構成されるようです。
Golang's memory allocation
🚀 Visualizing memory management in Golang
さらに各mspanには対応するsize classというものがあり、
なにかGoのobjectをallocateするときには、最も小さく、かつ収容できるsize classのmspanが選ばれるようです。

この図はスレッドごとのキャッシュなど、細かい詳細が省かれているので正確ではありませんが、イメージとしてはこのようになっています。
これを踏まえて、size classに着目して調査を進めました。
chunkは内部に、実際のデータ、data pointsとなるbyte sliceを持っています。
そしてそれは下記のコードで初期化されています。
make([]byte, 0, 128)
capに128を指定しているので、このchunkのcapは128を起点にある計算式に従って増えていきます。
これはGoのsliceに仕様によるもので、sliceは自身のcapを超えたときに、内側で現在のcapを元に計算した新しいより大きなcapのarrayをallocateし直し、ポインタをそのarrayに向けるという処理をしています。
つまり、sizeクラスと照らし合わせて考えると、allocationのイメージは次の図のようになります。

ここで重要なのは、slicaが128B -> 256B -> 512B -> 896B -> 1408B -> 2048Bと決まったサイズに成長していくため、ある程度決まったsize classが毎回選ばれるということです。
これに対して、snapshotからchunkを復旧するときは下記のようになっていました。
make([]byte, 0, actual chunk size)
chunkの実際のサイズはmetricsによって様々です。
つまり、復旧されたchunkはもとのchunkとは全く別のsize classに配置されていることになります。
イメージとしては次の図のようになります。

このように広範囲にわたってsize classレベルで分散されていたのです。
これでsnapshotのbyte列を時系列順にソートしても意味をなさなかった理由がわかりました。
そこで、復旧処理についても128bytesのcapで初期化することにしました。
結果、ある程度うまく働きましたが、多少fragmentationが発生してしまい、完全にはメモリの増加が消えなかったので、snapshotを時系列順に並べる案も同時に取り入れたところ、きれいにfragmentationが解消されました。
まとめ
Goのheapはmspanという単位でメモリのスペース管理をしていて、これは8KBの連続したページによって構成されます。
そして、各mspanには対応するsize classが決まっており、これによってそのmspanに配置できるobjectのsizeが決まります。
よって、memory fragmentationを防ぐにはsize classとobjectのlifetimeを考えた時間的局所性の2軸について配慮する必要があります。
Discussion