Real World HTTP(個人メモ)
HTTP/1.0 の世界
HTTPをデータの箱としてみると、4つの基本要素にフォーカスできる
- メソッドとパス
- ヘッダー
- ボディ
- ステータス
HTTPの歴史
HTTP は Web ブラウザとWeb サーバーが通信する時の手順とフォーマットをルール化したもの
- 1990年: HTTP/0.9
- 1996年: HTTP/1.0
- 1997年: HTTP/1.1
- 2015年: HTTP/2
最初のバージョン HTTP/0.9 は、HTML のドキュメントを要求して取得するだけのプロトコル
RFC は IETF という組織が中心となって維持管理している、通信の相互接続性を維持するために共通化された仕様書集。
Request For Commentは、「品質アップのためのご意見を広く世界から集める」という名目で仕様を公開することにした名残。
通信プロトコル(アルゴリズム)ではなく、ファイルタイプの種類(データ)などの共通情報は IANA が管理している。
通信のための規約ではなくブラウザに特化した機能の仕様策定は IETF から W3C (World Wide Webコンソーシアム)に移管された。
最近では策定のための議論の過程は W3C から分離した WHATWG という組織のもとで行われ ることも増えてきた。
HTTP0.9ではできなかったこと
- 1つのドキュメントを送る機能しかなかった
- 通信されるすべての内容はHTML文書であるという想定だったため、ダウンロードするコンテンツのフォーマットをサーバーから伝える手段がなかった
- クライアント側から検索のリクエストを送る以外のリクエストを送信できなかった
- 新しい文章を送信したり、更新したり、削除することはできなかった
HTTP1.0の変更点
- リクエスト時にメソッドが追加された(GET)
- リクエスト時にHTTPバージョンが追加された(HTTP/1.0)
- ヘッダーが追加された(Host、User-Agent、Accept)
- レスポンスの先頭にHTTPバージョンと3桁のステータスが含まれるようになった
- リクエストと同じ形式のヘッダーが含まれるようになった
ヘッダーをピックアップ
リクエスト
- User-Agent
- クライアントが自分のアプリケーション名を入れるところ。
- ネット利用者が使用しているOS・ブラウザ
- Referer
- サーバー側で参考にするための追加情報。クライアントがリクエストを送る時に見ていたペー ジの URL を送る。ページの参照元をサーバーが参照するのに用いる。
- Authorization
- 特別なクライアントにだけ通信を許可する際、認証情報をサーバーに伝える。RFC でいくつか の標準的な形式(Basic/Digest/Bearer)を定めているが、アマゾンウェブサービスや GitHub API など、ウェブサービス独自の表記を求められることもある
レスポンス
- Content-Type
- ファイルの種類を指定。
- ここには MIME タイプと呼ばれる識別子を記述する。
- Content-Length
- ボディのサイズ。
- Content-Encoding
- 何らかの圧縮が行われた場合に圧縮形式を説明する
- Date
- ドキュメントの日時
MIME タイプ
MIME タイプは、ファイルの種類を区別するための文字列で、電子メールのために作られた。
大項目 / 詳細という表記。
ニュースグループ
ニュースグループあるいは USENET と呼ばれる、記事を読んだり投稿するプラットフォーム。
HTTP はニュースグループから、メソッドとステータスという 2 つの機能を導入した。
ステータス
ステータスも、ニュースグループから持ち込まれた機能の 1 つ。
- 100番台
- 処理中の情報の伝達。1xx 系は特殊な用途で使う。
- 200 番台
- 成功時のレスポンス。一番使用されるステータスは200 OKで、正常終了
- 300 番台
- サーバーからクライアントへの命令。エラーではなく、正常処理の範疇。リダイレクトや、 キャッシュの利用を指示
- 400 番台
- クライアントから送られたリクエストにおかしなことがある場合に渡される
- 500 番台
- サーバー内部でエラーが発生した場合にクライアントに送付される
RFC の規約では、先頭 3 文字の数値を見てクライア ントが動作を変更できることを求めている。これは言い換えれば「先頭三文字の数値は機械的に解釈 できるものであるべきで、残りのテキスト部分はそれを見るユーザーのためのもの」という意味。
リダイレクト
300 番台のステータスの一部は、サーバーがブラウザに対して、リダイレクトを行うように指示する ステータス。
リダイレクトはブラウザとの協調動作で実現されており、サーバーはステータスと Location ヘッ ダーを返す。ブラウザはそれを見て、もう一度、そのヘッダーで指定された URL にリクエストし直す。
この再送信のところはユーザーから見れば一瞬で行われるため、ブラウザ の URL 表示だけがぱっと書き換わったように見える。
恒久的か一時的かは、移動する前のページが今後も存在するかどうかで分類している。
新しいドメインを取得してサーバーのコンテンツを移動した場合や、HTTP で運用されていたページを HTTPS に移行した場合、これまでのページを見ることはない。これは恒久的なリダイレクト。
メン テナンス期間の間だけすべてのリクエストをメンテナンス画面にリダイレクトするケースでは、将来的 には復旧して有効になるはずなので、一時的リダイレクト。
URL(Uniform Resource Locators)
URI と URL はよく混同されるが、 URIにはURN(Uniform Resource Name)という、名前の付け方のルールも含まれている。
URLは 場所からドキュメントなどのリソースを特定する手段を提供する。
URL の構造
スキーム :// ホスト名 / パス
ポート省略時はそれ ぞれのスキームごとのデフォルトのポートを使う。HTTP であれば 80 番。HTTPS であれば 443 番。
URL はアドレスを指定するのに使いますが、同時に「ユーザーが読む文章」でもある。
意味のあるURLにすることは、ブラウザを使ってウェブにアクセスするユーザーだけではなく、 HTTP を使ったウェブの API を利用するプログラマーから見ても、プログラムが分かりやすくなるメ リットがある。
ボディ
通常、GET メソッド時に属性を送信する場合は、URL に付与したクエリー文字列を使って渡す。
サーバーはメッセージボディを読み込める必 要はあるが、リクエストされたメソッドがボディのセマンティクスを定めていない場合は、リクエスト の処理時にメッセージボディは無視されるべき(SHOULD be ignored)
HTTP/1.0 のセマンティクス
シンプルなフォームの送信
Content-Type: application/ x-www-form-urlencodedを設定する。
この場合、ボディは次のような形式になります。キーと値が イコールで接続され、各項目が &で繋がれた文字列になる。
しかし、区切り文字の & と = があっても、そのまま繋いでしまうため、読み込み側で正しく元のデータセットを復元できない。
ラウザは、RFC1866が定める変換フォーマットに従って文字列を変換する。このフォーマッ トでは、アルファベット、数値、アスタリスク、ハイフン、ピリオド、アンダースコアの 6 種類の文字 以外はエスケープが必要。
実際に区切り として使われる文字は変換されないため、読み込む側では正しく分解できる。
この方式をURL エンコードという。
HTML のフォームでは、オプションでマルチパートフォーム形式というエンコードタイプを選択できる。
通常の HTTP のレスポンスは一度に 1 ファイルずつ返すため、空行を見つけて、そこから Content- Length で指定されたバイト数分を読むだけでデータをまるごと取得できた。
しかし、マルチパートを使う場合は 1 度のリクエストで複数のファイルを送信できるため、受 け取り側でファイルを区切らなければ行けない。
multipart/form-data の場 合は、項目ごとに、追加のメタ情報をタグとして持てる。
x-www-form-urlencoded ではファイル送信に必要な情報すべてを送ること ができず、ファイル名だけが送信されてしまう。
300 番台のステータスを使ったリダイレクトにはいくつかの制限がある。
- URLには2000文字に収めるべき、という目安があるので、 GET のクエリーで送信できるデータ量に限界がある
- データがURLに含まれるため、送信したい内容がアクセスログなどに残ってしまう懸念がある
それを回避する方法としてたまに利用されるのが、HTML のフォームを利用したリダイレクト
この方法では、リダイレクト先に送りたいデータが<input type="hidden">タグで書き込まれて いる HTML がサーバーから返ってくる。
通信方法を最適化するために、ひとつのクエストの中でサーバーとク ライアントがお互いのベストな設定を共有する仕組みがコンテントネゴシエーション。
圧縮による通信速度の向上
現在一般的に使われている圧縮アルゴリズムを使うと、テキストファイルであ れば 1/10 程度のサイズに圧縮できる。
圧縮と展開は、通信にかかる時間よりも少ない時間で行えるため、圧縮を利用することでウェブ ページ表示までにかかるトータルの処理時間を減らすことができる。
コンテンツ圧縮を行うネゴシエーションはすべて HTTP のヘッダーの中だけで完了する。なお、コンテンツのデータ量を表す Content-Length ヘッダーは、圧縮後のファイルサイズになる。
クッキー
クッキーは、ウェブサイトの情報をブラウザ側に保存する仕組み。
クッキーも HTTP のヘッダーをインフラとして実装されている。
クッキーの分類
クッキーの発行元、使用期間、および目的の 3 種類 のカテゴリーで分類できる
- 発行元
- ユーザーが訪れたサイト(ファーストパーティ)か、それ以外のサイト(サードパーティ)か
- 使用期間
- ブラウザを閉じたら消えてしまうセッションクッキーと、期限が設定されていてブラウザを閉じても残る永続クッキー
- 目的
- 厳密に必要なクッキー。EC サイトで買い物など。
- 環境設定クッキー。過去に選択したユーザーの好みの言語、ユーザー名とパスワードなど
- 統計クッキー。アクセスしたページやクリックしたリンクなど、ウェブサイトの分析情報を収集 するためのクッキー
- マーケティングクッキー。ユーザーの行動をトラッキングして、広告の精度を上げたり、広告
の表示回数をコントロール
クッキーの間違った使い方
- 永続性の問題
- 無くなっても問題のない情報、もしくはサーバー側の情報から復元できるデータ以 外を格納する用途には向かない
- データサイズの問題
- リクエスト時にはヘッダーとして通信に常に付与される ため、通信量が増える
- 目安として最大容量は約 4 キロバイト、ドメインごとに 50 クッキー、全 部で 3000 クッキーほどはブラウザは保存できるように実装すべきと RFC6265 には書かれている
- セキュリティの問題
- secureを付与すれば HTTPS で暗号化された時にしか送受信され ませんが、HTTP の場合クッキーは平文で送受信される
クッキーに制約をあたえる
クライアントは、サーバーから受け取ったクッキーをローカルのストレージに保存し、同じ URL に アクセスするときにはそのクッキーを読み出してサーバーへ送信するリクエストヘッダーに加える。
HTTP クライアントには、これらの属性を解釈 し、クッキーの送信をコントロールする責務がある。
- Expires、Max-Age 属性
- クッキーの寿命を設定する。Max-Ageは秒で指定。現在時刻から指定された秒数を足した時間 に無効になる。
- Domain 属性
- クライアントからクッキーを送信する対象のサーバー
- 省略時はクッキーを発行したサーバー になる
- Path 属性
- クライアントからクッキーを送信する対象のサーバーのパス
- Secure 属性
- HTTPS での安全な接続時以外は、クライアントからサーバーへのクッキー送信をしない。
- Secure 属性をつけることで、HTTP 接続が使われる時 にはブラウザが警告を出し、ページヘのアクセスを止めるため、流出を防げるようになる
- HttpOnly 属性
- この 属性を付けると JavaScript エンジンから、クッキーを隠すことができる
- SameSite 属性
- 同じオリジンのドメインに対して送信するようになる
オリジン
ブラウザは「スキーム、ドメイン(ホスト名)、ポート」の 3 つの組が同じであれば同一のサイトと判断する。
クッキーに関しては、デフォルトでオリジン単位で取り扱われますが、パスの階層でフィルタ したり、サブドメインも有効にするなど少しは変更できる。
SameSite 属性
クッキーはオリジンがマッチするときに送信されますが、攻撃者によって乗っ取られたウェブサイ トからのアクセスであっても、ブラウザはそれを判別することなくクッキーを送信してしまいまう。
認証とセッション
認証、つまりユーザー名とパス ワードを入れてログインすることで、サービス側から、誰がアクセスしてきているのかを特定できる。
BASIC 認証と Digest 認証
- BASIC認証
- ユーザー名とパスワードを、base64 エンコーディングしたもの
- base64 エンコーディングは可逆変換であるため、サーバーで復元して元のユーザー名とパ スワードを取り出すことができる
- これをサーバー側のデータベースと比較して、正しいユーザーか どうかを検証
- ただし、SSL/TLS 通信を使っていない状態で通信を傍受されると、通信内容 から簡単にユーザー名とパスワードが漏洩してしまう
- Digest 認証
- ハッシュ関数(A → B は簡単に行えるが、B → A は単純には計算 できない)を利用
- ラウザが保護 された領域にアクセスしようとすると、401 Unauthorizedというステータスでレスポンスが帰る
- ユーザー名とパスワードそのものをリクエストに含めなくても、サーバー側でユーザーを正しく 認証できるようになる
BASIC 認証も Digest 認証も今ではあまり使われていない。
- 特定のフォルダ以下を「見せない」という使い方しかできず、トップページにユーザー固有の情報 を出すようなことができない。
- リクエストごとにユーザー名とパスワードを送信し、計算をして認証する必要がある。
- ログイン画面をカスタマイズできない。
- 明示的なログオフができない
- ログインした端末の識別ができない。
最近もっとも使われているのが、フォームを使ったログインとクッキーを使ったセッション管理の組 み合わせ
- クライアントは、フォームでIDとパスワードを送信
- Digest認証とは異なりユーザー IDとパ スワードを直接送信することになるため、SSL/TLSの利用が必須
- サーバー側ではユーザー ID とパスワードで認証し、問題がなければセッショントークンを発行
- サーバーは、セッショントー クンをリレーショナル・データベースやキーバリュー型のデータベースに保存
- トークン はクッキーとしてクライアントに戻される
- 2 度目以降のアクセスでは、クッキーを再送することで、 ログイン済みのクライアントであることがサーバーに分かる
プロキシ
プロキシは、HTTP などの通信を中継する仕組み。
外部からの攻撃から保護す るファイアウォールとしての役割もある。
また、低速な通信回線用にデータを圧縮して高速化する(画像の見た目等は劣化する)フィルタや、コンテンツのフィルタリング等にも利用される。
プロキシを実現する仕組みは単純で、GET 等のメソッドの次に来るパス名の形式だけが変わる。
中継されるプロキ シは途中のホストの IP アドレスを特定のヘッダーに記録していく。
キャッシュ
すでにダウンロード済 みで、内容に変化がなければダウンロードを抑制し、それによってパフォーマンスをあげるメカニズム。
キャッシュにはブラ ウザ上のキャッシュと、ウェブサービスとブラウザの間にたって動作するプロキシサーバーあるいは CDN(Content Delivery Network)と大きく2種類。
HTTP/1.1 を定義した RFC2068 では、永遠に更新しないこと が期待されるコンテンツでも、最大で 1 年の寿命にしましょう、というガイドラインが追加されている。
リファラー
リファラー(ヘッダー名 :Referer)は、ユーザーがどの経路からウェブサイトに到達したかをサーバーが把握するために、クライアントがサーバーに送るヘッダー。
ウェブサービスの設計者は、プライバシーに関わる情報が GET パラメータとして表示されるような仕 様を作成しては行けない。
GET パラメータは、リファラーを通じて外部のサービスに送信されるので、 プライバシー情報の流出につながる。
リファラーを送信しないようにウェブブラウザを設定するこ とも可能。
検索エンジン向けのコンテンツのアクセス制御
クローラー向けのアクセス制御の方法として、主に 2 つの手法が広く使われている。
- robots.txt
- サーバーのコンテンツ提供者が、クローラーに対してアクセスの許可・不許可を伝える ためのプロトコル
- サイトマップ
- ウェブサイトに含まれるページ一覧とそのメタデータを提供する XML ファイル
ユーザーエージェント
ウェブの世界においてはブラウザなどの通信を代行するプログラムのことをユーザーエージェントと呼ぶ。
Go 言語による HTTP/1.0 クライアントの実装
GET メソッドの送信と、ボディ、ステータス、 ヘッダーの受信
io.Reader
Go 言語では、データのシーケンシャルなデータの入出力を io.Reader、io.Writerインタフェース として抽象化しており、ファイル、ソケットなどさまざまなところで使用される。
func ioutil.ReadAll(reader io.Reader) ([]byte, error)
io.Readerの内容をまとめてバイト配列に読み込む
func Copy(dst io.Writer, src io.Reader) (written int64, err error)
io.Reader から io.Writer にまるごとコピー
fmt.Fprintf(writer io.Writer, format string, ... variant{})
フォーマット付き文字列を io.Writerに書き出し
GET メソッド + クエリーの送信
クエリー文字列は、url.Values型を使って宣言
values. Encode()を呼んで文字列に
HEAD メソッドでヘッダーを取得
HTTP/1.1 のシンタックス: 高速化と安全性を求めた拡張
HTTP/1.1 の、プロトコルシンタックスとしての変更点は次の通り
- 通信の高速化
- Keep-Aliveがデフォルトで有効に
- TLSによる暗号化通信のサポート
- 新メソッドの追加
- PUTとDELETEが必須のメソッドとなった
- OPTION、TRACE、CONNECTメソッドが追加
- プロトコルのアップグレード
- 名前を使ったバーチャルホストのサポート
- サイズが事前にわからないコンテンツのチャンク転送エンコーディングのサポート
- DATA URIスキーム
Keep-Alive による通信の高速化
Keep-Alive は、HTTP の下のレイヤーである TCP/IP の通信を効率化する仕組み
Keep-Alive を使わない場合は、ひとつのリクエストごとに通信を閉じます。Keep-Alive を使うと連続したリクエ ストの時に接続を再利用します。
Keep-Alive の持続時間は、クライアントとサーバーの両方が持っています。片方が TCP/IP の切断 を行った瞬間に通信が完了するため、どちらか短い方が採用されます。
パイプライニング
パイプライニングは最初のリクエストが完了する前に次のリクエストを送信し、「レスポンスを待っ て次のリクエストを出す」までの待ち時間を排除することでネットワークの稼働率を上げ、パフォーマ ンスを向上させる機能
パイプラインは無駄な仕様だったというわけではなく、さまざまな問題を解決し、後の HTTP/2 においてストリームという新しい仕組みとして生まれ変わりました。
TLS(トランスポート・レイヤー・セキュリティ)
HTTPのウェルノウンポートは80番ですが、HTTPS(HTTP Secure)は443番を使い、別のサー ビスとして扱われています。
HTTP の通信を途中で中継するゲートウェイから見ると「暗号化されていて通信の内容を覗いたり変 更ができない双方向通信」です。
ハッシュ関数
- 同じアルゴリズムと同じ入力データであれば、結果として作られるハッシュ値は同じになる。h(A) = Xが常に成り立つ
- 同一ハッシュ値を持つ任意のデータの組を見つけるのが難しい。h(A) = h(B)となる任意のデータ の 組 A と B を 見 つ け る の は 困 難( 強 衝 突 耐 性 )
共通鍵暗号と公開鍵暗号とデジタル署名
暗号のアルゴリズムで大事だとされていることは、アルゴリズムそのものを秘密にするのではなく、 アルゴリズムが公開されていても安全に通信できること
TLS で使われ ているものには、共通鍵方式と、公開鍵方式の 2 種類があります。
共通鍵方式は、鍵をかけるのと鍵をあけるのに同じ鍵を使う方式
鍵交換
DH(ディフィー・ヘルマン)鍵交換ア ルゴリズムのポイントとしては、鍵そのものを交換せず、クライアントとサーバーでそれぞれ 鍵の材料を作り、お互いに交換しあって、それぞれの場所で計算して同じ鍵を得ます。
共通鍵方式と公開鍵方式を使い分ける理由
TLS では通信ごとに一度だけ使われる共通鍵を作り出し、公 開鍵方式を使って通信相手へ厳重に鍵を受け渡し、その後は共通鍵で高速に暗号化を行うという 2 段 階の方式を利用しています。
公開鍵方式の方が安全性は高いのですが、鍵を持っていたとしても暗号 化と復号化に必要な計算量が共通鍵方式に比べて大きすぎるため
TLS の通信手順
TLS の通信は大きく 3 つに分けることができます。
- ハンドシェイクプロトコルと呼ばれる通信を確立 するステップ。
- 次がレコードプロトコルと呼ばれる通信時のステップ。
- 最後が SessionTicket という仕 組みを使った、再接続時の高速なハンドシェイクです。
プロトコルのアップグレード
- HTTPからTLSを使った安全な通信へのアップグレード(TLS/1.0、TLS/1.1、TLS/1.2)
- HTTPからWebSocketを使った双方向通信へのアップグレード(websocket)
- HTTPからHTTP/2へのアップグレード(h2c)
チャンク
HTTP/1.1 からサポートされた新しいデータ表現に、全体を一括で送信するのではなく小分けにして 送信するチャンク方式があります。
データ URI スキーム
データ URI スキームを利用すると、URI がデータの位置 を表す識別子ではなく、データそのものになります。
このデータ URI スキーム形式の用途として一般的なのが、スタイルシートに画像をテキストとして埋 め込む方法です。
HTTP/1.1 のセマンティクス: 広がる HTTP の用途
ファイルをダウンロードした後でローカルに保存
ブラウザがファイルをどのように処理するのか決めているのは、拡張子ではなくサーバーから送られ てくる MIME タイプでした。
Content-Disposition ヘッダーの内容によって、ブラウザはこの動作を変更します。
XMLHttpRequest
XMLHttpRequest とブラウザの HTTP リクエストの違い
- 送受信時にHTMLの画面がフラッシュ(リロード)されない
- メソッドとして、GETとPOST以外も送信できる
- フォームの場合、キーと値が1:1になっている形式のデータしか送信できず、レスポンスはブラウ
ザ で 表 示 さ れ て し ま う がさまざまなフォーマットが送受信できる - いくつか、セキュリティのための制約がある(後述)
XMLHttpRequest のセキュリティ
XMLHttpRequest の機能は強力すぎるため、ウェブページに悪意のあるスク リプトが埋め込まれると、認証されているウェブサイトへの通信が行われて、ブラウザ利用者の意図し ないデータ改変が行われたり、データが奪われる危険があります。
XMLHttpRequest のセキュリティ制御は、アクセスできる情報の制限、送信制限という 2 つの制限 から成り立っています。
WebDAV
WebDAVはHTTPを拡張することで分散ファイルシステムとして使えるようにしたものです。
ウェブサイト間で共通の認証・認可プラットフォーム
シングルサインオン
シングルサインオンは各システム間のアカウント管理をばらばらに行わず、一度サインインしたら、全システ ムがすべて有効になるような仕組みです。
Kerberos 認証
Kerberosで認証を行うと、チケット保証サーバー(TG)へのアクセストークンである、TGTTicket-Granting-Ticket)と、セッションキーが得られます。サービスやシステムを使う時には、TGTとセッションキーをチケット保証サーバー(TGS)に送り、クライアントからサーバーにアクセスするためのチケットと、セッションキーをもらいます。
SAML(Security Assertion Markup Language)
SAML はウェブ 系の技術(HTTP / SOAP)を前提としたシングルサインオンの仕組みです。
SAML は XML ベースの規格を数多く手がけている OASIS(Organization for the Advancement of Structured Information Standards)で策定されてい る規格です
クッキーを使ってセッションを管理するウェブの仕組みに準じており、ドメインをまた いだサービス間でシングルサインオンできるようになっています。
- ユーザー
- ブラウザを操作している人
- 認証プロバイダー(IdP)
- ID を管理するサービス
- サービスプロバイダー(SP)
- ログインを必要とするサービス
まず事前準備として、認証プロバイダーにサービスの情報を登録します。
- サービスのID(認証プロバイダーがサービスを識別するためのもの)
- 認証プロバイダーがHTTP-POSTする先のエンドポイントURL
- バインディング(urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POSTなど)
- 場合によってはX.509形式の公開鍵
サービスプロバイダー側にも認証プロバイダー情報を登録します。これも認証プロバイダーから XML ファイルが提供されています
SAML が面白い点は、事前に証明書などを交換してしまえば、すべてブラウザ経由のリダイレクト だけで済み、IdP と SP の直接通信がない点です。
OpenID
OpenID は、中央集権の ID 管理を行うのではなく、すでに登録されているウェブサービスのユーザー 情報を使い、他のサービスにログインすることができる仕組みです。
- OpenID プロバイダー
- ユーザー情報を持つウェブサービス。ユーザーはすでにこのサービスの ID を所有する。2017 年現在、Yahoo! JAPANとHatenaが対応している
- リライングパーティー
- ユーザーが新たに利用したいウェブサービス
- ユーザー入力識別子
- OpenID プロバイダーが提供する、ユーザーごとの URL 形式の文字列。OpenID プロバイダー のユーザープロフィール画面などに表示される。ユーザーを特定する ID ではなく、サービス 名レベルの識別子が使われることもある
OAuth
OAuth は認証ではなく認可のための仕組みとして開発されました。
- 認可サーバー
- OpenID でいうところの OpenID プロバイダー。ユーザーは、この認可サーバーのアカウント を持っている
- リソースサーバー
- ユーザーが許可した権限で自由にアクセスできる対象。Twitter や Facebook の場合は認可 サーバーと同一
- クライアント
- OpenID でいうところのリライングパーティー。ユーザーがこれから使用するサービスやアプリケーション。OpenID とは異なり、認可サーバーにアプリケーション情報を登録し、専用の ID(client_id と client_secret)を取得しておく必要がある。この ID はクレデンシャルと呼ばれ ることがある
OpenID Connect
OpenID Connectは、OAuth 2.0をベースにして、認可だけではなく、認証として使っても問題ない ように拡張したものです。
クライアントから見たOAuth 2.0との違いは、ユーザープロフィールへのアクセス方法が規格化さ れたことです。
JWT(JSON Web Token)
JWT は 3 つの base64 エンコードされた文字列を、ピリオドで接合した文字列です。それぞれ、ヘッ ダー、ペイロード、署名となっています。
JWT の場合、「ログインした」実績情報と、ログインしたユーザーの詳細情報の両方が含まれます。 検証ができてしまえば、ペイロードに入っている情報であれば認証サービスに問い合わせずに、ユー ザーの情報が取得できます。これが JWT トークンが一番便利なところです。
Go 言語によるHTTP1.1 クライアントの実装
Keep-Alive
ソケットという1 本のパイプを時間分割で共有する仕組みなので、最後まで読み きって終了したことを明示しなければ、次のジョブをいつ使い始めればいいのか判断できずに再利用 できません。
TLS
URL を https:// にするだけで標準ライブラリを使った TLS 通信が可 能です。
証明書の作成
デフォルトではシステムが持っている証明書を使って証明書を確認します。
- OpenSSLコマンドを使って秘密鍵ファイルを作る
- 証明書要求ファイルを作る
- 証明書要求ファイルに署名して証明書ができる
チャンク
http.Postで 2048 バイト以上のファイルを送信する場合で、Request.ContentLengthを設定せずに 送信する場合に自動でチャンク形式でのアップロードになります。
リモートプロシージャコール(RPC)
HTTP/2、HTTP/3 の シンタックス:プロトコルの再定義
HTTP/2、HTTP/3 で変わらないこと
単純な機能の漸進的な修正ではなく、すべての要素が一度分解されて、大量のアセット が必要な時代の要件に合致するようにゼロから組み上げられました。
通信のオーバーヘッドを小さくするためにバイナリプロトコルとなり、HTTP の特性に合わせたヘッ ダー圧縮などが組み込まれました。また、その下の TCP のレイヤーで行っていることをエミュレーショ ンしたり、高度な制御機構を取り込みました。
なお、HTTP/2 が出てきたからといって、HTTP/1.1 が不要になるわけではなく、HTTP/3 が出てき
たからといって、HTTP/2 が不要になるわけではありません。TCP しか使えない環境で最速を求める 場合には HTTP/2 になるでしょう。
大規模なウェブシステムを作るとして、ロードバランサーなどのエッジまでは TLS の暗号化を使った 通信になりますが、その中のロードバランサーの内側は TLS を使わない通信を使います。そうなると HTTP/1.1 となります。
HTTP/2
HTTP/2 は久々の大き なアップデートで、パフォーマンス向上にフォーカスしています。プロトコルをどのようなバイト列と して表現して通信するかが大きく変わりました。
SPDY
SPDY は Google が開発した HTTP 代替のプロトコルで、これがほぼそのまま HTTP/2 となりました。
Google が SPDY を開発したのは、これまでの HTTP が改善してきた転送速度を一段と向上させるた めです。
「ウェブサイトの JavaScript や CSS、画像などはなるべく少ないファイル数にまとめることで高速化 させる」というのが HTTP/1.1 時代に高速なウェブサイトを作るためのテクニックとして一般的でした。
SPDY と HTTP/2 以降、ファイルをまとめる効果は小さくなることが見込まれています。
HTTP/2 の改善点
- ストリームを使ってバイナリデータを多重に送受信する仕組みに 変更
- ストリーム内での優先順位設定や、サーバーサイドからデータ通信を行うサーバーサイドプッシュ を実装
- ヘッダーが圧縮されるようになった
HTTP/2 では、これまで手が付けられてこなかったヘッダー部の圧縮や、規格化されたもののいまひとつ活用さ れていなかったパイプライニングの代替実装が追加されました。
ストリームによる通信の高速化
HTTP/2 の一番大きな変化は、テキストベースのプロトコルからバイナリベースへのプロトコルに変 化したという点です。各データはフレームと呼ばれる単位で送受信が行われます。
HTTP/2 では 1 本の TCP 接続の内部に、ストリームという仮想の TCP ソケットを作って通信を行い ます
HTTP/2 のアプリケーション層
HTTP/1.1 はテキストプロトコルでした。ヘッダーの終端を探すには空行を見つけるまで 1 バイトず つ読みこんで発見する必要があります。エラー処理などもあるため、サーバーとしてはパースまで含め て逐次処理せざるを得ず、高度な並列化は難しいと思われます。
HTTP/2 はバイナリ化されており、レ スポンスの先頭にフレームサイズが入っています。TCP ソケットのレイヤーでは、データをフレーム単 位へと簡単に切り分けられるため、受信側の TCP ソケットのバッファをすばやく空にでき、通信相手に対しても次のデータを高速にリクエストできるようになります。
フローコントロール
HTTP/2 はインターネットの 4 階層モデルのうちのアプリケーション層に当たるものですが、トラン スポート層に近いものを内部に持っているのが特徴です。
フローコントロールは、ストリームを効率よく流すために用いられる通信量の制御処理です。
通信速 度差がありすぎる機器の組み合わせで通信するときに、速い方の機器が遅い方に大量のパケットを送 りつけて処理できなくなるような事態を防ぐのが目的です。
サーバープッシュ
サーバープッシュによって、クライアントから要求 される前に優先度の高いコンテンツを送信できるようになりました。
HTTP/2 とプリロードによるリソース取得の最適化
一番効果が大きいのはサーバープッシュです。これはリクエストが発生する前に送信を開始するた め、もっとも効果が高くなります。クライアント側からサーバーに対してリクエストを行う通信が 1 つ 省略されるからです。
これらを先行して行うように、<link>タグや Linkヘッダーを使って指示できます。
これらのタグと、あとで説明する prerender は、リソースヒントという仕様にまとまっています
<link rel="preconnect" href="//cdn.example.com" crossorigin>
プリロードが効果的に働くのは、CSS の中で定義されているウェブフォントなどでしょう。CSS を読 み込んで、CSS をパースして初めて必要なことがわかってサーバーにリクエストを送ってフォントファ イルをロードします。リードタイムが伸びるのでフォントをプリロードしておくことには価値がありま す。
HPACK によるヘッダーの圧縮
ヘッダーは HPACK という方式で圧縮されます。世の中の圧縮アルゴリズムの多くは、データ圧縮時 に、辞書と、辞書のキーの配列という 2 つのデータを作ります。同じ長い文が多ければ多いほど、辞書 の項目は少なくなり、同じキーが何度も使われるようになって圧縮率が上がります。HPACK は普段使 われるファイル圧縮のアルゴリズムと違い、事前に定義済みの辞書(静的テーブル)を持っています。
HTTP/3
QUIC
UDP は TCP から再送処理、輻輳制御などの高 機能な機能を取り払い、初回接続時のネゴシエーションを軽くしたプロトコルです。
HTTP/3 のレイヤー
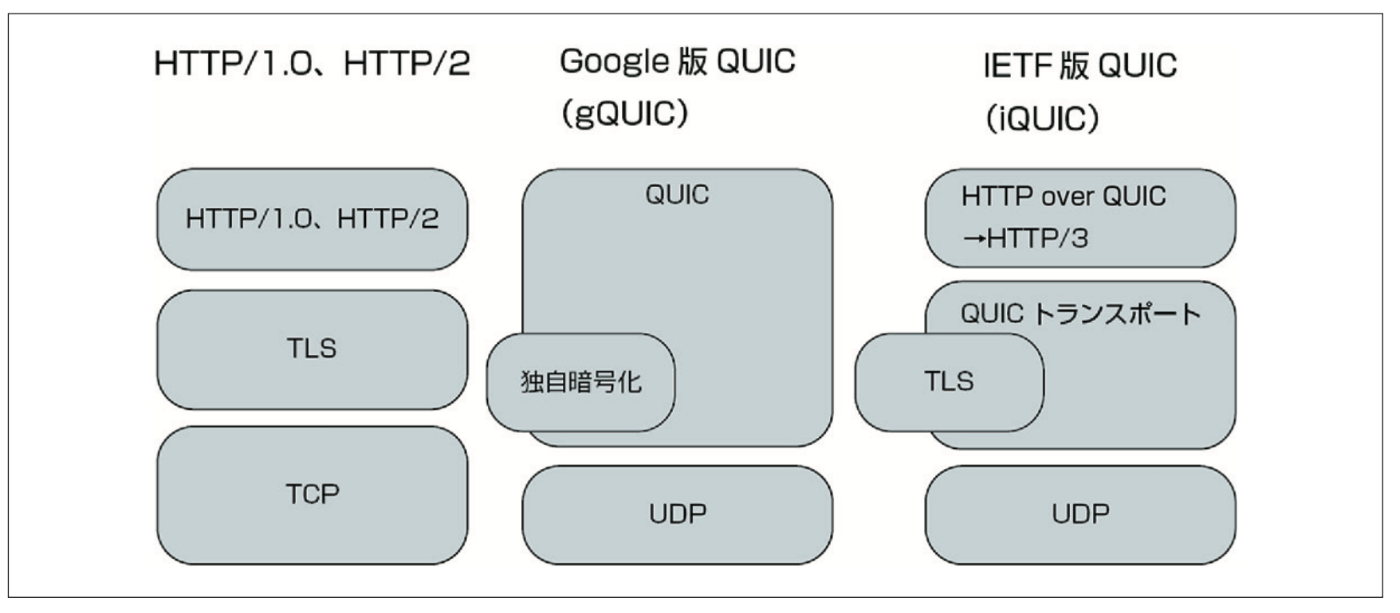
TCP の場合は、1 つのコネクション内のパケットがすべて整列されて転送されることを保証するプロ トコルでした。QUIC は、セッションは張るものの、その中に複数の通信の疑似セッション(ストリーム) を張り、ストリームの内部では順序保証はするものの、ストリーム間での保証はしません。それにより、 1 つのストリームが失敗したときの影響が、他のストリームに及ばなくなります。
QUIC トランスポートプロトコルは、UDP を元にして、再送処理、輻輳制御、暗号化などを実装し たものになります。大雑把にいってしまうと、TCP と TLS のレイヤーの置き換えです。
HTTP/3
HTTP/2 と比較すると、QUIC トランスポート側と、HTTP/3 とに分かれたため、HTTP/3 側はシン プルになっています。
全体的な違いとしては
- ストリームIDのビット数が31から62に増えてオーバーフローの危険性がかなり減った
- 各フレームはストリームIDとフラグを持たなくなった
- フラグによって増減するフィールドがなくなった
- ヘッダー圧縮のアルゴリズムが、HPACKから、QPACKという別の方式に変わった
新たな JavaScript 用の通信 API
Fetch API
- XMLHttpRequestよりも、オリジンサーバー外へのアクセスなど、CORSの取扱いが制御しやす くなっている
- JavaScriptのモダンな非同期処理の記述法であるPromiseに準拠している
- キャッシュを制御できる
- リダイレクトを制御できる
- リファラーのポリシーを設定できる
- Service Worker内から利用できる
Server-Sent Events
チャンク形式は、巨大なファイルコンテンツを小分けにして送信するた めの通信方式でした。このチャンク形式の「少しずつ送信」という特徴を応用して、サーバーから任意 のタイミングでクライアントにイベントを通知できる機能を実現しています。
WebSocket
WebSocket はサーバー/クライアント間で、オーバーヘッドの小さい双方向通信を実現します。
HTTP ウェブプッシュ
HTTP ウェブプッシュは、ウェブサイトにスマートフォンアプリケーションのような通知機能を提供 する仕組みです。
Service WorkerはフロントエンドのブラウザのHTML表示機能からすると、ウェブサーバーとフロ ントエンドの中間にある、プロキシサーバーのような存在です。ただし、Service Workerは常に起動 し続けているわけではなく、addEventListener()イベントハンドラを登録しておくと、必要なときだ け起動して処理を行います。
HTTP/2 のセマンティクス: 新しいユースケース
セマンティックウェブ
セマンティックウェブで「意味を扱う」というのは、ページに含まれる情報を分析し、情報を集約し たり探したりするのを人手を介さずに行えるようにすることです。
RDF(Resource Description Framework)
RDF は URI で識別されるエンティティ間の関係性を記述します。
RSS
RSSはウェ ブサイトの更新履歴のサマリーに関するボキャブラリーです。
ウェブサイトをブラウザで巡回しなくても、専用のリーダーが登録した RSS の更新チェックを行 い、未読のエントリーを集めて効率よく閲覧できるようにしてくれます。
オープングラフプロトコル
オープングラフプロトコルはソーシャルネットワークで使われるメタデータで、ソーシャルネットワー クでトップシェアを誇る Facebook が開発しました。
オープングラフプロトコルが設定されているウェ ブサイトの URL を SNS 等に貼り付けると、記事の一部が引用され、画像も表示されます。
単に URL だけが表示されるのと比較すると他のユーザーから興味をもってもらえるチャンスが増えます。
AMP(Accelerated Mobile Pages)
AMP はモバイルの高速化のための仕組みです。
現代のウェブサイトは、複雑な JavaScript を駆使して構築されています。それを平準化してモバイ ル専用の軽量なページを作る所が AMP の出発点です。
モバイルアプリケーションにより多様化するブラウズ環境
URL のような情報を元に、アプリケーションの特定の機能を呼び出せる 仕組みが OS に加わり、ウェブからアプリケーションへのリンクのような形で動作します。方式自体は Android と iOS で多少異なりますが、このような仕組みをまとめて DeepLink と呼びます。
MPEG-DASH による動画ストリーミング再生
DASHはDynamic Adaptive Streaming over HTTPの頭文字を取った名前で、HTTPを使い、動 的に適切なビットレートでストリーミングを行う方式を意味します。
Go言語によるHTTP/2、HTML 5 のプロトコルの実装
HTTP/2
Go言語は2016年2月にリリースされた1.6から、標準でHTTP/2サポートが組み込まれていま す。
クライアント視点で見るRESTful API
REST(REpresentational State Transfer)はRoy Fielding氏が2000年にネットワークベースのソフ トウェアアーキテクチャの論文の中で発表したものです
REST は HTTP のシンタックスをプロトコルの土台として使っていますが、通信のセマンティクスも HTTP にならうようにしましょうという考えです。
- APIがウェブサーバーを通じて提供されている
- GET /users/[ユーザーID]/repositoriesのように、パスに対してメソッドを送ることでサービスを得る
- APIの成功可否はステータスとしてクライアントに通知される
- URLはリソースの場所を表す表現であり,サービスの顔として大切である
- 必要に応じて、GETパラメータ、POSTのボディなどの追加情報を送信することもある
- サーバーからの返り値としては、JSONやXMLのような構造化テキスト、あるいは画像データなどが返ってくることが多い
- URLはリソースの階層を表したパスになっている。名詞のみで構成されている
- リソースに対して、HTTPメソッドを送ることでリソースの取得、更新、追加などの操作を行う
- ステータスを見ればリクエストが正しく処理されたかどうかが判定できる
- GETメソッドは何度呼んでも状態を変更することがない
- クライアント側では管理すべきステートが存在せず、1回ごとのリクエストは独立して発行できる
- トランザクションは存在しない
HATEOAS
HATEOAS(Hypermedia As The Engine Of Application Stat)はRESTの一部である「インタフェー スの一般化」を仕様化したもの
リソース間の関連情報やリソースの操作のリンクをレスポンスに 含めることで、リソースの自己記述力を向上させます
メソッド
HTTP の仕様ではメソッドの分類には、安全とべき等(とう)という 2 つの指標があります
安全は、 実行してもリソースを変化させないもの
べき等はサーバーのリソースは変更されますが、何度実行しても結果が変わらないというもの
安全なものはべき等性も兼ね備えています
JavaScript によるブラウザからの 動的な HTTP リクエスト
ブラウザの HTTP とライフサイクル
ブラウザがHTTPアクセスをする箇所は主に2箇所あります。ウェブサイトのロードと、その後 JavaScript を使ったアクセスです。
Fetch API
ウェブの進化は速度とセキュリティ向上という 2 つのベクトルによって発展してきましたが、Fetch API は後者にあたります。デフォルトでより厳格な設定が選択されており、必要に応じて明示的に解除 するという設計になっています。
Fetch APIにしかできないこと
キャッシュの制御
Service Worker対応
Server-Sent Events
Server-Sent EventsはXMLHttpRequestやFetch APIとは異なり、サーバー側から通信を行うた めのプロトコルおよび JavaScript の API です。