約4ヶ月前、文学作品の冒頭を読んで作者を当てる Web サービス、「文豪推理」をリリースしました。
https://zenn.dev/kangetsu_121/articles/d99e8306c0d895
そして昨日、個人開発サービス第二弾として、ストリートファイターシリーズのプロ選手の YouTube 配信・動画を一覧できるサービス、SF Streaming Portal (SF-SP) をリリースしました!
今回も友人の @kokokocococo555 さんとの開発です。
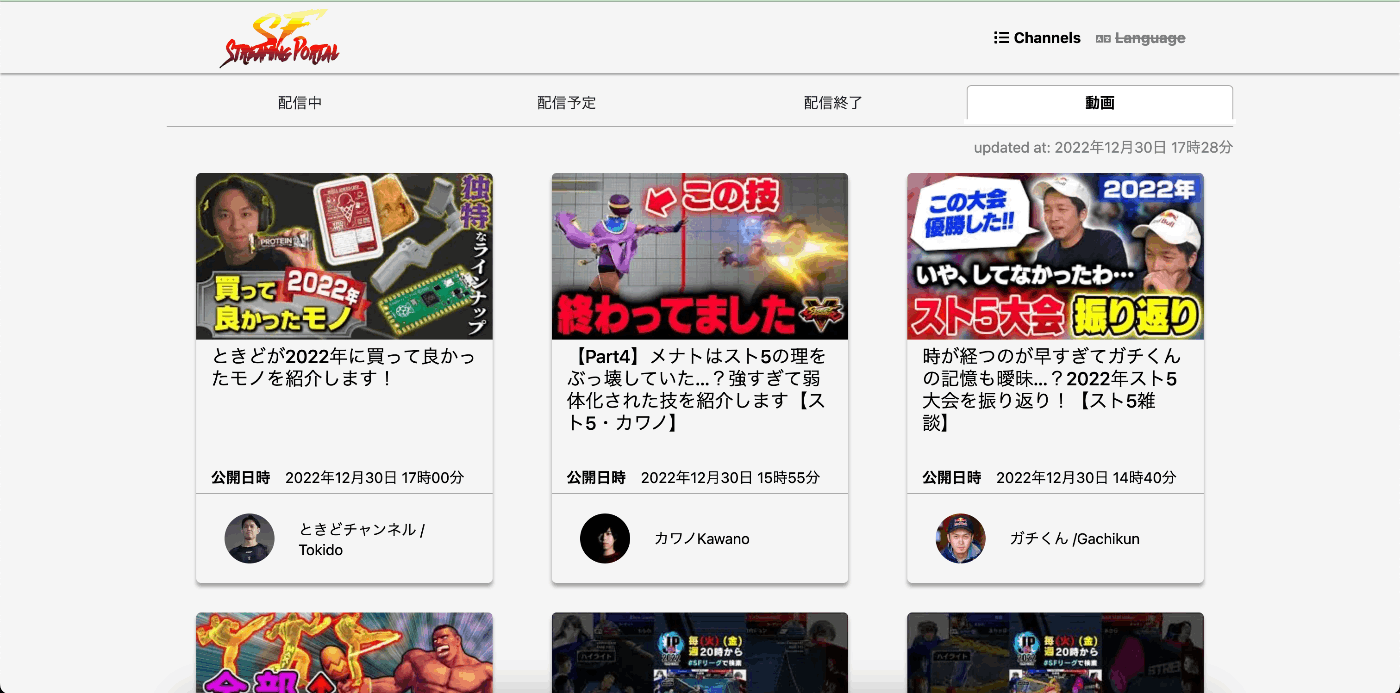
SF-SPトップページ
どんな配信・動画があるかをぱっと見られますので、ぜひストリートファイターシリーズに興味なかった、という方も https://sf-streaming-portal.tailoor.dev/ から少しだけ覗いていただけると嬉しいです。
例によって学びが多くあったので、サービス紹介と経験・知見の還元を目的として本記事にまとめます。
どんなサービスか
SF Streaming Portalは、日本の有名な対戦格闘ゲームであるストリートファイターシリーズのプロ選手のYouTube配信・動画を一覧できるポータルサイトです。各選手のチャンネルを個別に見に行かなくても、配信中の動画や配信予定の動画があるかなどを確認できます。
2022年12月30日現在では、2022年度ストリートファイターリーグ[1] の参加選手を基本的に対象としています。
配信中、配信予定、配信済み、動画の4種類にタブを分けており、それぞれの種類に応じた配信・動画情報がリンク付きのサムネイルで見られます。
配信・動画情報の取得はYouTube Data API と RSS を利用して取得しています。
利用技術と構成
利用技術一覧
SF Streaming Portalは、以下の技術を主に利用しています。
- TypeScript
- React
- CSS Modules
- Python
- Next.js
- Docker
- Cloud Build
- Cloud Run
- Cloud Storage
- Cloud Scheduler
- Cloud Pub/Sub
- Cloud Functions
- GitHub Actions
- Vercel
役割分担
2人の役割分担です。
私の担当が多かったので、執筆の都合上私のアカウントで記事投稿をしています。
- @kangetsu_121
- サービス原案
- フロントエンド実装 (TypeScript, React, Next.js, CSS Modules)
- インフラ構築 (Cloud Build, Cloud Run, Cloud Functions, Vercel)
- @kokokocococo555
- YouTube Data API 利用検討
- バックエンド実装 (YouTube Data API を利用する Python, Cloud Storage 利用)
- Big Query 利用検討 (最終的に不採用判断)
- 共同
- サービス具体案
- サービスデザイン検討
- サービステスト
- デバッグ
- etc.
構成詳細
フロントエンド: TypeScript, React, CSS Modules
基本的に文豪推理と同じ構成ですので、詳しくは 文豪推理の記事 をご覧ください。
今回特筆すべき内容としては、外部データ取得で意味のあるコンテンツのレンダリングに時間がかかると予想されたことから、ユーザー体験改善のためにプレースホルダーを実装したこと、頻繁に更新されるデータに依存することからuseSWR を使って実装とデータ取得を効率的にしたことなどが挙げられます。
プレースホルダーをどうやって実装するか想像がついていなかったのですが、「そういう見た目のコンポーネントを書くだけ」という意外と素朴な方法で実現できました。また、データが取得できない場合にプレースホルダーを描画する実装も useSWR のおかげで容易だったと感じます。

データ取得が完了していない場合に表示される
バックエンド: Python (文責: kokokocococo555)
YouTube Data API v3 と RSS を使用してチャンネル情報や動画情報を取得しています。
取得した情報を JSON ファイル形式に整形。保存先は Google Cloud Storage です。
処理は Python で行っています。
インフラ: Cloud Build, Cloud Run, Cloud Storage, Cloud Scheduler, Cloud Pub/Sub, Cloud Functions
デプロイ先のインフラは文豪推理と同じく、GCP の Cloud Run を利用しました。
また、YouTube Data API から取得したデータは JSON に整形して、Cloud Storage に格納して参照するようにしています。
秘匿すべき情報が含まれていないことと、安価なストレージであることから、データ参照先として採用しました。
YouTube Data API からデータを定期的に取得するジョブは、Cloud Scheduler -> Cloud Pub/Sub -> Cloud Functions という構成で実行しています。
この構成は GCP で定期実行ジョブを組むときの基本形の一つのようです、詳細については Cloud Functionsを定期実行させてみる などをご覧ください。
CI: GitHub Actions
GitHub Actions は、主に Cloud Functions で定期実行する Python スクリプトを更新した際に、Cloud Functions にデプロイするために使っています。
Actions として Google 公式の Authenticate to Google Cloud と deploy-cloud-functions を利用しています。
開発環境: Vercel
こちらも 前回 と同じくです。
Vercel のプレビュー環境は非常に便利でありがたいです。
各技術の選定理由
前回 と同じものは割愛し、今回新たに増えた Cloud Functions について書きます。
Cloud Functions
YouTube Data API を Python スクリプトで叩いていると書きましたが、YouTube の配信・動画情報は絶えず更新されるので、短いスパンでの定期実行によるデータ更新が必要です。
この定期実行は、初めは GitHub Actions を利用して実行していました。
しかし、GitHub Actions は 最低実行間隔が 5分である こと[2]、指定した時間に実行されることが保証されない こと[3] (いずれも https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#schedule 参照)、そして無料枠では 2,000分/月 の実行時間のみの利用 であることなどから、採用を見送りました。
代わりに Compute Engine の無料枠を使って VM で cron 実行することも考えましたが、折角なので新しい技術を触ろう、と Cloud Functions の採用に至りました。
Cloud Functions は設定やデプロイに少し手こずりましたが、無料枠もあり[4]、また 256MB・1vCPU で運用していますが起動から処理完了までも十分早く、問題なく稼働してくれています。
データの保存
YouTube Data API 実行結果のデータは、Cloud Storage に JSON 形式で保存し、更新しています。今回も前回と同じくそこまで大きくないデータであったこと、API 以外での書き込みが発生しない、同期ずれが深刻なものでない、検索なども行わないため、データロックや検索最適化が不要と考えたためです
開発での学び
前回 と被る部分は割愛し、今回新たに得たものを中心に紹介します。
良いと感じたもの
Next.js スタンドアロンモード
今回は (今回も) Cloud Run に Next.js のアプリケーションをデプロイしているのですが、Next.js のスタンドアロンモード を利用すると、コンテナのイメージサイズを大きく削減することができます。
つまり、ひいては CI/CD の時間 (ビルド時間、デプロイ時間など) を削減することができます。
私たちの環境でも、イメージサイズは大体半分くらいになりました。
実装にあたっては、waddy_u さんの Next.jsのスタンドアロンモードでビルドしたイメージを Cloud Run へデプロイする を主に参考にさせていただきました。
スタンドアロンモードが experimental の頃の記事ですが、とてもわかりやすいので興味があればぜひご覧ください。
Cloud Functions
選定理由はすでに書きましたが、運用する中で思った以上に処理速度が早いこと、サーバーレスなのでサーバー管理が不要なことはメリットが大きいと感じました。
Compute Engine を採用していたら、外部に公開していないとはいえセキュリティアップデートなど、なんだかんだサーバーの管理は必要です。
そうしたことを気にしなくて良いのは、サーバーレスのありがたさだと感じました。
また Cloud Storage に実行結果の JSON を送信していますが、同一リージョンの GCP サービス間連系なので、データ送信部分が無料なのも嬉しいです。
SWR (useSWR)
SWR (useSWR) で、データ格納先である Cloud Storage をウォッチして、更新を反映するようにしています。
useSWR を使うことで実装もコンパクトになり、かつ迅速にウォッチ先のデータ更新を反映することができるので、非常に便利でした。
解説は他に詳しい記事がたくさんありますので、そちらをご覧ください。
e.g., https://zenn.dev/mast1ff/articles/5b48a87242f9f0, https://zenn.dev/uttk/articles/b3bcbedbc1fd00, https://zenn.dev/yukikoma/articles/17adad7fedd5af,
つまづいた点とその解決
次に、開発中につまづいた・はまった点などを紹介します。
こちらは主に技術面のお話になります。
バックエンド: Python での YouTube Data API の Quota と YouTube のチャンネルID 取得 (文責: kokokocococo555)
実装中につまずいた
- YouTube Data API の Quota について
- YouTube のチャンネルID 取得について
共有します。
1.まずは、今回のサービス要件との兼ね合いで頭を悩ませた YouTube Data API の Quota (API の利用上限) への対応について。
「複数チャンネルの配信中動画を一箇所で確認したい」という本サービスの特徴上、API を高頻度で叩かなければなりませんが、そこで問題になったのが Quota (API の利用上限) です。
- Quota は 1日 10000が上限
-
search().list()(チャンネルID を指定して、チャンネルの複数動画情報を取得) を用いると 1回 100程度消費 -
videos().list()(動画ID を指定して動画情報を取得) を用いると 1回 1程度消費 - 指定する parts数ごとに 2程度追加で消費
※Quota について参考
- https://developers.google.com/youtube/v3/getting-started#quota
- https://masaki-blog.net/youtube-data-api-quotas
素朴に設計すると「チャンネルごとの動画情報を Search で取得し、配信中、配信予定、配信終了、一般動画に分ける」ことが考えられます。
しかし 20以上のチャンネルを対象に Search を行うとすぐに Quota が枯渇し、本サービスの肝である「今配信中の動画はあるのか」という機能を十分に提供できません (1日に 4回程度しか情報を更新できず、意味がありません)。
最低でも数分に 1回程度は情報更新しなければ「配信中に動画無かったのに実は配信が始まってた! 見逃したひどい!!」となりかねません。
この Quota の問題にどう対応するのか、「特定のチャンネルの配信予定日時を YouTube Data API から取得する」を参考にさせていただきました。
具体的には RSS と videos().list() を組み合わせて使用しています。
動画ID の取得は RSS で代用しました。
RSS を用いると YouTube のチャンネルごとの動画情報を 15件まで取得できます (YouTube の RSS の公式ドキュメントは見つけられませんでしたので、いつか使用できなくなるのかもしれません)。
https://www.youtube.com/feeds/videos.xml?channel_id={チャンネルID}
videos().list() であれば 1回 1程度しか Quota を消費しない、1回の実行で最大 50までの video情報を取得できる (search は複数のチャンネルID 指定ができない) ため、動画数が多くなければ数分ごとに 1回でも実行できます。
(※複数の動画ID を指定した場合に追加で quota を消費するのか確認できてはいません。ただ、実績に鑑みると単に 動画ID数 を掛けた数よりはかなり少ない消費のように思います。)
2.次に、YouTube のチャンネルID 取得について。
最近の YouTube は URL にチャンネルID が記載されていないケースが多いです。
YouTube の画面のどこを見てもチャンネルID が見つかりませんので、最終的には以下の流れでチャンネルID を取得しました。
- 対象チャンネルの動画を 1つ選び、動画ID を URL から取得
- YouTube Data APIの
videos().list()で動画情報を取得。その中にチャンネルID が含まれる
Cloud Storage のキャッシュ (文責: kokokocococo555)
Storage に上書き保存したはずの JSON ファイルを見てみると中身が更新されていない、という事象が発生して頭を抱えました。
「Cloud Storage のキャッシュはデフォルトで max-age 3,600秒 らしい」と kangetsu_121 さんが調べてくれて、本サービスではキャッシュされても困ると考え、無効化することにしました。
なお、今回は Storage のオブジェクトの固定メタデータを Python を用いて変更、無効化しています (google-cloud パッケージ を使用)。
その際に少しつまずいた部分がありましたので共有しておきます。
- Python から変更する際、
blob.metadata = {key: val}で変更すると、変更したい固定キーメタデータのCache-Controlではなくカスタムキーに{key: val}が登録されてしまうので注意が必要です - そのため、
blob.cache_control = "no-store"で固定キーメタデータを編集する必要があります - なお、コンソール上から設定する際には
Cache-Control欄にno-storeと記載します - 参考
- https://cloud.google.com/storage/docs/metadata?hl=ja
- https://cloud.google.com/storage/docs/viewing-editing-metadata?hl=ja#storage-set-object-metadata-python
- https://gcloud.readthedocs.io/en/latest/storage-blobs.html#google.cloud.storage.blob.Blob.cache_control
- https://cloud.google.com/storage/docs/json_api/v1/objects#cacheControl
Cloud Functions への GitHub Actions からのデプロイ
「Cloud Functions は設定やデプロイに少し手こずった」と書きましたが、具体的には GCP の権限設定周りや Actions の設定で悩みました。
今回は専用のサービスアカウントを作成してそのアカウントで実行などをするようにしたのですが、GitHub Actons から Cloud Functions にデプロイ〜実行までする場合は、Cloud Build の権限や、Cloud Functions 実行サービスアカウントとしての明示的な指定などが必要です。
また、Cloud Functions へのデプロイに利用した deploy-cloud-functions ですが、Readme に必要な情報は書いてあるのですが Inputs 部分をしっかり読んだ方が良いです。
ドキュメント冒頭に太字である通り、
This GitHub Action is declarative, meaning it will overwrite any values on an existing Cloud Function deployment.
なので、当然と言えば当然ですがデフォルト値以外の設定は全て明示的に Workflow の yml に書く必要があります。
今回の私たちのケースだと、Secret、実行サービスアカウント、build_environment_variables などが見落としがちなポイントでした。
どのパラメータが必要かを確認する方法として、個人的にはまず GUI などで Cloud Functions が実行できるまで設定し、その後 Cloud Functions の [関数の詳細] > [同等の REST] をみるのがわかりやすいと思いました。
REST と Actions でプロパティのキー名が微妙に異なる点のみ要注意です。
OGP の生成
解決せず諦めたのですが、今回は Twitter でシェアしても Twitter でサムネイル画像は出ません。
Next.js で SSR (Server-side Rendering) や Sattic Generation (SG) を使えば実現はできるのですが、今回は実装やリソース処理効率を優先して諦めました。
ここを諦めて CSR にすることで useSWR による実装とデータ取得が容易になったと思っているので納得しているのですが、もし私が勘違いしており、良い方法があればコメントいただけると大変助かります。
参考: https://zenn.dev/a_da_chi/articles/105dac5573b2f5#csr%2Fssr%2Fssg%2Fisrの使い分け
参考にさせていただいたサイト
今回は配信・動画ポータルを作るということで、必ず類似サービスがあるはずだと考え、初めにいくつか似たコンセプトのサービス・サイトを探しました。
その中で自分達が良いなと思い、最も参考にさせていただいたのが ホロすけ さんでした。
チャンネル詳細ページなどは完成度が高く (かつ今回の自分達の用途とは違ってもいたため) 真似できませんでしたがとても素敵でした!
今後の展望
年内ギリギリですが、前回からそこまで期間を空けずに2つ目のサービスをリリースできたことは嬉しかったです。
YouTube 以外に配信サービスとして活用されている Twitch に対応したり、海外ファンが多い作品なので多言語対応したり、など Issue に積んでいるものもまだあるので、改善できる部分は継続して取り組みたいと考えています。
また、今回のサービスは再利用可能な構造になっているので、取得する YouTube チャンネルを変更すれば、特定のトピックに特化した配信・動画ポータルを作ることができます。
今回は私の趣味でストリートファイターに特化しましたが、需要があれば、もしかしたらそういうこともやるかもしれません。
少しでも興味を持ってもらえましたら、サービスを触ったり Twitter やフォームで感想・要望などを書いていただいけると大変励みになります!
3つ目のサービスはゆっくり考えようと思うので、また何かできたら見ていただけると嬉しいです。
-
ストリートファイターシリーズは数年前からストリートファイターリーグでプロ選手のチーム対抗リーグ戦を行っています。野球のペナントレースのように、放映中はご飯を食べながら応援して見てました ↩︎
-
↩︎The shortest interval you can run scheduled workflows is once every 5 minutes.
-
↩︎Note: The schedule event can be delayed during periods of high loads of GitHub Actions workflow runs. High load times include the start of every hour. To decrease the chance of delay, schedule your workflow to run at a different time of the hour.
-
https://cloud.google.com/functions/pricing Free Tier 参照。日本語解説だと https://blog.g-gen.co.jp/entry/cloud-functions-explained なども ↩︎

Discussion