🆗
【Python・PySparkで学ぶ!】explode(array())で繰り返し属性を解消し、正規化しよう
↓配信マスタ(event_mail_mst)のサンプル

上記のような配信データを集約したCSVテーブルが存在すると仮定します。
◾️要望
とある日の朝会MTGにて、クライアントから次のような要望を頂きました。
『"配信マスタ"のKPIが繰り返し属性になっているため、これを解消したい』
本稿では、クライアントからの要望に答えながら、 繰り返し属性の解消 について学びます。
よろしくお願いいたします。
◾️AsIs(現状把握)
エンジニアとクライアント間の認識に相違があるとアウトプットのイメージに相違が発生します。
はじめに、 データアセスメントの観点から論点を提示し、クライアントと集計ロジックの認識を擦り合わせるタッチポイント を設けましょう。
◾️タッチポイント議事録
-
配信マスタ
- campaign_id:配信ID
- campaign_name:配信IDごとの名称
- subject:施策ごとの名称
- sender_email:送信元メールアドレス
- created_at:配信ごとの作成日時
- kpi1:配信KPI1
- kpi2:配信KPI2
- kpi3:配信KPI3
-
キャンペーンIDとKPI
- 第2正規形(2NF):campaign_id, kpi の複合キーによって kpi の値が決まっている。
- 第3正規形(3NF):kpi の値が campaign_id 以外の情報に依存しておらず、推移的従属(transitive dependency)がない。
- 合意『キャンペーンIDとKPIのCSVを作成する』
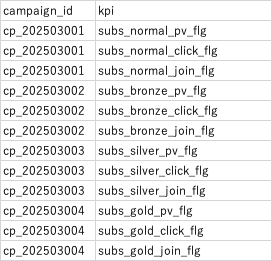
◾️アウトプットイメージ
タッチポイントより、クライアントとアウトプットイメージを次の通り合意いたしました。
例)
◾️ToBe(スクリプト作成)
はじめに、spark.read.csv()メソッドでCSVファイルを読み込みます。
CSVファイルを読み込み
from pyspark.sql import SparkSession
from pyspark.sql import functions as fn
from pyspark.sql.window import Window
import pandas as pd
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# スキーマ定義
email_mst_schema = StructType([
StructField("campaign_id", StringType(), False),
StructField("campaign_name", StringType(), False),
StructField("subject", StringType(), False),
StructField("sender_email", StringType(), False),
StructField("created_at", StringType(), False),
StructField("kpi1", StringType(), True), # KPI1
StructField("kpi2", StringType(), True), # KPI2
StructField("kpi3", StringType(), True) # KPI3
])
# CSV格納先
csv_path = "s3://aws_email_mst/sample_event_mail_mst.csv"
# CSV 読み込み
df = spark.read.csv(csv_path, schema=email_mst_schema, header=True)
次に、kpi 列を縦持ちにします。縦持ちにする手順は以下の通りです。
-
fn.explode(fn.array(kpi1, kpi2, kpi3)) を使って kpi 列を縦持ちにする。
a. fn.arrayでkpi1, kpi2, kpi3 の3つの列の値を1つの配列(Array型)に入れます。
b. fn.explode(配列)で、配列の各要素を個別の行に展開します。 - fn.filter(fn.col("kpi").isNotNull()) で NULL の KPI を削除する。
- campaign_id はそのまま保持する。
kpi 列を縦持ち
# KPIを縦持ちに変換
df_transformed = df.select(
fn.col("campaign_id"),
fn.explode(
fn.array(
fn.col("kpi1"),
fn.col("kpi2"),
fn.col("kpi3")
)
).alias("kpi")
).filter(fn.col("kpi").isNotNull()) # NULL値を除去
# 確認
df_transformed.show(truncate=False)
| campaign_id | kpi |
|---|---|
| cp_202503001 | subs_normal_pv_flg |
| cp_202503001 | subs_normal_click_flg |
| cp_202503001 | subs_normal_join_flg |
| cp_202503002 | subs_bronze_pv_flg |
| cp_202503002 | subs_bronze_click_flg |
| cp_202503002 | subs_bronze_join_flg |
| cp_202503003 | subs_silver_pv_flg |
| cp_202503003 | subs_silver_click_flg |
| cp_202503003 | subs_silver_join_flg |
| cp_202503004 | subs_gold_pv_flg |
| cp_202503004 | subs_gold_click_flg |
| cp_202503004 | subs_gold_join_flg |
上記の結果より、データ処理が意図した通りに実行されることがわかりました。
最終的なコードスニペットを紹介します。
コードスニペット
from pyspark.sql import SparkSession
from pyspark.sql import functions as fn
from pyspark.sql.window import Window
import pandas as pd
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# スキーマ定義
email_mst_schema = StructType([
StructField("campaign_id", StringType(), False),
StructField("campaign_name", StringType(), False),
StructField("subject", StringType(), False),
StructField("sender_email", StringType(), False),
StructField("created_at", StringType(), False),
StructField("kpi1", StringType(), True), # KPI1
StructField("kpi2", StringType(), True), # KPI2
StructField("kpi3", StringType(), True) # KPI3
])
# CSV格納先
csv_path = "s3://aws_email_mst/sample_event_mail_mst.csv"
# CSV 読み込み
df = spark.read.csv(csv_path, schema=email_mst_schema, header=True)
# KPIを縦持ちに変換
df_transformed = df.select(
fn.col("campaign_id"),
fn.explode(
fn.array(
fn.col("kpi1"),
fn.col("kpi2"),
fn.col("kpi3")
)
).alias("kpi")
).filter(fn.col("kpi").isNotNull()) # NULL値を除去
『結論』
◾️繰り返し属性の解消を学ぶメリット(ビジネスサイド)
-
データの一貫性
- すべてのキャンペーンに対して、KPI(Key Performance Indicator)が一貫して表現されるため、キャンペーンごとの成果を比較・評価しやすくなります。
-
可視化の簡素化
- 各KPIが独立した行として表現されるため、データを可視化する際に、特定のKPI(例:クリック率や加入率)の動向を簡単に比較でき、レポート作成が効率的になります。
◾️繰り返し属性の解消を学ぶメリット(エンジニアリングサイド)
- データ処理の柔軟性
- KPIごとに行が分割されているため、例えばPySparkやSQLでデータ処理を行う際に、特定のKPIだけを効率的にフィルタリングしたり集計したりすることができます。
- 機械学習や分析の準備
- KPIが独立したカラムで管理されることにより、機械学習モデルや統計解析において、各KPIを特徴量として扱うのが容易になります。モデルの学習がシンプルになり、予測精度を向上させる可能性があります。
Discussion