🆗
【Python・PySparkで学ぶ!】欠損データ(取引がない日)を適切に処理する
欠損データ(取引がない日)がありますが、どう処理しますか?
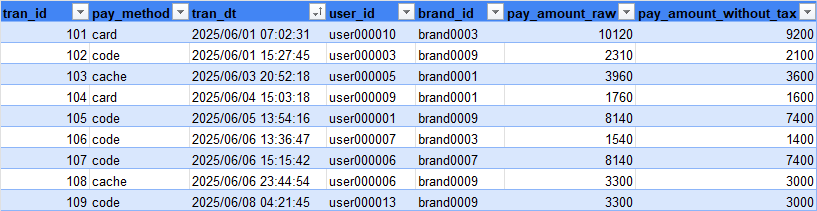
↓決済データ(transaction_data)
欠損データを適切に処理するメリット
欠損データを適切に処理することには、以下のようなメリットがあります。
-
データ分析の正確性を確保
欠損データがあると、平均値やトレンド分析の結果が歪む可能性があります。
-
データの可視化や集計の適切な実行
取引のない日を補完することで、時系列分析のグラフやヒートマップがより正確に描画できます。
-
実務でのデータ整備に役立つ
企業のデータ基盤では、データの欠損を適切に処理することで、正確なレポートを作成できます。
-
データ処理スキルの向上
PySpark を活用することで、大規模データの前処理スキルを磨くことができます。
では、具体的にどのように欠損データを処理するのか見ていきましょう。
では、どうするのか。取引がない日のデータを補完する方法
欠損データの処理の流れは以下の通りです。
- 日付データフレームを作成
- 取引がない日を含む日付リストを作成します。
- 取引データと日付データを結合
- 左外部結合(LEFT JOIN)を用いて、すべての日付をカバーするデータフレームを作成します。
- NULL 値を適切に処理
取引がない日には適切なデフォルト値を設定します。
日付データフレームを作成する。
日付データフレームを作成
start_date = datetime.strptime("2025-06-01", "%Y-%m-%d")
end_date = datetime.strptime("2025-06-15", "%Y-%m-%d")
date_list = [(start_date + timedelta(days=i)).strftime("%Y-%m-%d") for i in range((end_date - start_date).days + 1)]
date_df = (
spark.createDataFrame(date_list, "string").toDF("date")
.withColumn("weekday",
fn.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="1","日")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="2","月")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="3","火")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="4","水")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="5","木")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="6","金")
.when(fn.dayofweek(fn.to_date(fn.col("date"), "yyyy-MM-dd"))=="7","土")
.otherwise("不明")
)
)
date_df.show(len(date_list))
| date | weekday |
|---|---|
| 2025-06-01 | 日 |
| 2025-06-02 | 月 |
| 2025-06-03 | 火 |
| 2025-06-04 | 水 |
| 2025-06-05 | 木 |
| 2025-06-06 | 金 |
| 2025-06-07 | 土 |
| 2025-06-08 | 日 |
| 2025-06-09 | 月 |
| 2025-06-10 | 火 |
| 2025-06-11 | 水 |
| 2025-06-12 | 木 |
| 2025-06-13 | 金 |
| 2025-06-14 | 土 |
| 2025-06-15 | 日 |
日付データフレームと決済データを結合させる。
データフレームを結合
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
# 取引データのスキーマ
transaction_schema = StructType([
StructField("tran_id", IntegerType(), False), # 取引ID
StructField("pay_method", StringType(), False), # 支払方法 (card, code, cache)
StructField("tran_dt", StringType(), False), # 取引日時
StructField("user_id", StringType(), False), # ユーザーID
StructField("brand_id", StringType(), False), # ブランドID
StructField("pay_amount_raw", IntegerType(), False), # 税込み支払額
StructField("pay_amount_without_tax", IntegerType(), False) # 税抜支払額
])
transaction_sdf = spark.read.csv("s3a://data/transaction/", header=True, schema=transaction_schema).withColumn("tran_dt", fn.to_date("tran_dt", "yyyy/MM/dd HH:mm:ss"))
join_sdf.join(transaction_sdf, date_df.date == transaction_sdf.tran_dt, "left").show(len(date_list))
★欠損値(NULL)の処理
取引がない日のデータを補完するために、 NULL 値を適切な値に置き換えます。
欠損値(NULL)の処理
filled_sdf = joined_sdf.fillna({
"tran_id": 0,
"pay_method": "N/A",
"user_id": "N/A",
"brand_id": "N/A",
"pay_amount_raw": 0,
"pay_amount_without_tax": 0
})
filled_sdf.show(len(date_list))
この処理により、
- tran_id が 0
- pay_method が N/A
- pay_amount_raw が 0
といった形で欠損データを埋めることができます。

Discussion