🆗
【Python・PySparkで学ぶ!】複雑なデータ結合(inner)をしよう
↓トランザクションテーブル(transaction_table)のサンプル
| tran_id | pay_method | tran_dt | user_id | brand_id | shop_id | pay_amount_raw | pay_amount_without_tax | y | m | d |
|---|---|---|---|---|---|---|---|---|---|---|
| 101 | code | 2025/01/03 06:48 | user000007 | brand0002 | shop0004 | 1540 | 1400 | 2025 | 01 | 03 |
| 102 | cache | 2025/01/04 22:27 | user000001 | brand0001 | shop0006 | 6050 | 5500 | 2025 | 01 | 04 |
| 103 | code | 2025/01/08 03:22 | user000001 | brand0005 | shop0003 | 8140 | 7400 | 2025 | 01 | 08 |
| 104 | card | 2025/01/09 09:10 | user000011 | brand0002 | shop0001 | 770 | 700 | 2025 | 01 | 09 |
↓飲食店応援キャンペーン店舗マスタ(food_event_2025)の店舗データ(food_event_2025.csv)のサンプル
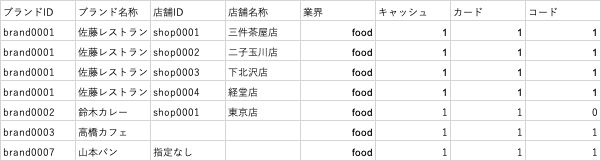
上記のような決済データを集約したSQLテーブルと、キャンペーン店舗マスタのCSVファイルが存在すると仮定します。
◾️要望
とある日の朝会MTGにて、クライアントから次のような要望を頂きました。
『飲食店応援キャンペーン店舗マスタ(food_event_2025)の店舗に限定した決済データを作成したい』
- 飲食店応援キャンペーン(food_event_2025)の店舗データの情報
本稿では、クライアントからの要望に答えながら、 複雑な内部結合 について学びます。
よろしくお願いいたします。
◾️AsIs(現状把握)
エンジニアとクライアント間の認識に相違があるとアウトプットのイメージに相違が発生します。
はじめに、 データアセスメントの観点から論点を提示し、クライアントと集計ロジックの認識を擦り合わせるタッチポイント を設けましょう。
◾️タッチポイント議事録
-
トランザクションテーブル
- 2025年1月の決済情報
-
項目情報
- ブランドID:店舗共通のID
- 店舗共通のID
- 店舗ID :店舗別のID。他ブランドの店舗IDと被る可能性あり。
- ブランドID:店舗共通のID
-
飲食店応援キャンペーン店舗マスタ(food_event_2025)
- ブランドID:キャンペーン対象ブランドのID
- 店舗ID :店舗別のID。全ての店舗がキャンペーン対象の場合、NUll値か"指定なし"が入る
-
結合に関する合意
- 合意『結合キーは"ブランドID"である。ただし、店舗IDがある場合は、ブランドIDと"店舗ID"を結合キーとする』
- 合意『トランザクションテーブルと飲食店応援キャンペーン店舗マスタを完全対等に内部結合する』
◾️アウトプットイメージ
タッチポイントより、クライアントとアウトプットイメージを次の通り合意いたしました。
例)
| tran_id | pay_method | tran_dt | user_id | brand_id | shop_id | pay_amount_raw | pay_amount_without_tax | y | m | d |
|---|---|---|---|---|---|---|---|---|---|---|
| 102 | cache | 2025/01/05 13:40 | user000001 | brand0001 | shop0001 | 4400 | 4000 | 2025 | 01 | 05 |
| 101 | code | 2025/01/07 06:48 | user000007 | brand0002 | shop0004 | 1540 | 1400 | 2025 | 01 | 07 |
| 104 | card | 2025/01/10 09:10 | user000011 | brand0002 | shop0001 | 770 | 700 | 2025 | 01 | 10 |
| 104 | card | 2025/01/15 15:23 | user000011 | brand0001 | shop0004 | 770 | 700 | 2025 | 01 | 15 |
◾️ToBe(スクリプト作成)
タッチポイント議事録をもとに、スクリプトを作成します。
◾️作成手順
はじめに、データソースの読み読みを行います。
具体的には、SQLテーブルを読み込むために、spark.sql()メソッドでDDLを書き、CSVファイルを読み込むためにスキーマを設定します。
データソースの読み読み
from pyspark.sql.types import StructType, StructField, StringType, IntegerType,
# テーブルの削除
spark.sql("DROP TABLE IF EXISTS transaction_table")
# テーブルの作成
spark.sql("""
CREATE TABLE IF NOT EXISTS transaction_table (
tran_id STRING, --トランザクションID
pay_method STRING, --決済手段
tran_dt TIMESTAMP, --トランザクション日時
user_id STRING, --ユーザーID
brand_id STRING, --ブランドID
shop_id STRING, --店舗ID
pay_amount_raw INT, --決済金額(税込)
pay_amount_without_tax INT, --決済金額(税抜)
y STRING, --年
m STRING, --月
d STRING --日
)
STORED AS PARQUET
PARTITIONED BY (y string,m string,d string) -- パーティションの定義
TBLPROPERTIES (
'parquet.compression' = 'SNAPPY' -- Parquetファイルの圧縮方式
)
LOCATION 's3a://data/warehouse/transaction_table/'; -- データの格納場所
""")
# MSCK REPAIRでパーティションの修復
spark.sql("""MSCK REPAIR TABLE transaction_table;""")
# スキーマ定義
shop_mst_schema = StructType([
StructField("ブランドID", StringType(), False),
StructField("ブランド名称", StringType(), False),
StructField("店舗ID", StringType(), False),
StructField("店舗名称", StringType(), False),
StructField("業界", StringType(), False),
StructField("キャッシュ", IntegerType(), False),
StructField("カード", IntegerType(), False),
StructField("コード", IntegerType(), False)
])
# データフレームを作成
tran_sdf = spark.read.table("transaction_table")
cp_store_mst = spark.read.parquet("s3a://data/warehouse/food_event_2025.csv/",header=True,schema=shop_mst_schema)
次に、データフレームを結合します。結合の手順は以下の通りです。
- 基本的にはブランドIDが結合キー
- 店舗IDがNullまたは"指定なし"であればブランドIDと店舗IDが結合キー
結合
union_sdf = tran_sdf.join(
cp_store_mst
# 名称のバッティングをバッティングを無くすため、名称変更を行う。
.withColumnRenamed("brand_id", "brand_id_store")
.withColumnRenamed("shop_id", "shop_id_store"),
on=(
(fn.col("brand_id") == fn.col("brand_id_store")) &
(
(fn.col("shop_id") == fn.col("shop_id_store")) |
(fn.col("shop_id") == "指定なし") |
(fn.col("shop_id_store") == "") |
(fn.col("shop_id_store").isNull())
)
),
how="inner"
)
| tran_id | pay_method | tran_dt | user_id | brand_id | shop_id | pay_amount_raw | pay_amount_without_tax | y | m | d |
|---|---|---|---|---|---|---|---|---|---|---|
| 102 | cache | 2025/01/05 13:40 | user000001 | brand0001 | shop0001 | 4400 | 4000 | 2025 | 01 | 05 |
| 101 | code | 2025/01/07 06:48 | user000007 | brand0002 | shop0004 | 1540 | 1400 | 2025 | 01 | 07 |
| 104 | card | 2025/01/10 09:10 | user000011 | brand0002 | shop0001 | 770 | 700 | 2025 | 01 | 10 |
| 104 | card | 2025/01/15 15:23 | user000011 | brand0001 | shop0004 | 770 | 700 | 2025 | 01 | 15 |
上記の結果から、操作が意図した通りであることが確認できました。
最後に、スクリプト全量をご紹介します。
スクリプト全量
from pyspark.sql import SparkSession
from pyspark.sql import functions as fn
from pyspark.sql.types import StructType, StructField, StringType, IntegerType,
import pandas as pd
# セッション作成
spark = SparkSession.builder.getOrCreate()
# テーブルの削除
spark.sql("DROP TABLE IF EXISTS transaction_table")
# テーブルの作成
spark.sql("""
CREATE TABLE IF NOT EXISTS transaction_table (
tran_id STRING, --トランザクションID
pay_method STRING, --決済手段
tran_dt TIMESTAMP, --トランザクション日時
user_id STRING, --ユーザーID
brand_id STRING, --ブランドID
shop_id STRING, --店舗ID
pay_amount_raw INT, --決済金額(税込)
pay_amount_without_tax INT, --決済金額(税抜)
y STRING, --年
m STRING, --月
d STRING --日
)
STORED AS PARQUET
PARTITIONED BY (y string,m string,d string) -- パーティションの定義
TBLPROPERTIES (
'parquet.compression' = 'SNAPPY' -- Parquetファイルの圧縮方式
)
LOCATION 's3a://data/warehouse/transaction_table/'; -- データの格納場所
""")
# MSCK REPAIRでパーティションの修復
spark.sql("""MSCK REPAIR TABLE transaction_table;""")
# スキーマ定義
shop_mst_schema = StructType([
StructField("ブランドID", StringType(), False),
StructField("ブランド名称", StringType(), False),
StructField("店舗ID", StringType(), False),
StructField("店舗名称", StringType(), False),
StructField("業界", StringType(), False),
StructField("キャッシュ", IntegerType(), False),
StructField("カード", IntegerType(), False),
StructField("コード", IntegerType(), False)
])
# データフレームを作成
tran_sdf = spark.read.table("transaction_table")
cp_store_mst = spark.read.parquet("s3a://data/warehouse/food_event_2025.csv/",header=True,schema=shop_mst_schema)
union_sdf = tran_sdf.join(
cp_store_mst
# 名称のバッティングをバッティングを無くすため、名称変更を行う。
.withColumnRenamed("brand_id", "brand_id_store")
.withColumnRenamed("shop_id", "shop_id_store"),
on=(
(fn.col("brand_id") == fn.col("brand_id_store")) &
(
(fn.col("shop_id") == fn.col("shop_id_store")) |
(fn.col("shop_id") == "指定なし") |
(fn.col("shop_id_store") == "") |
(fn.col("shop_id_store").isNull())
)
),
how="inner"
)
『結論』
◾️複雑なJoin結合を習得するメリット(ビジネスサイド)
-
データ品質の向上
- 特定条件(指定なしやNULL)を許容することで、正確なデータ統合が可能になります。
-
柔軟な分析
- 店舗データの有無を考慮しても正確な売上レポート作成が可能です。
◾️複雑なJoin結合を習得するメリット(エンジニアサイド)
-
エラー回避
- NULL や空文字対応ができるため、結合エラーを未然に防止します。
-
データモデル設計の理解促進
- 結合条件からデータモデルの関係性や制約を学べるため、データエンジニアリングスキルが向上します。
Discussion