🆗
【Python・PySparkで学ぶ!】regexp_extract()でHTMLテキストデータを正規化しよう
↓イベントマスタ(2025_event_mst_1.csv)のサンプル

上記のようなイベント情報を集約したCSVファイルが存在すると仮定します。
◾️要望
とある日の朝会MTGにて、クライアントから次のような要望を頂きました。
『イベントマスタのメール文章を第一正規形にしたい』
本稿では、クライアントからの要望に答えながら、 データの正規化 について学びます。
よろしくお願いいたします。
◾️AsIs(現状把握)
エンジニアとクライアント間の認識に相違があるとアウトプットのイメージに相違が発生します。
はじめに、 データアセスメントの観点から論点を提示し、クライアントと集計ロジックの認識を擦り合わせるタッチポイント を設けましょう。
◾️タッチポイント議事録(第一正規化)
-
"メール本文"項目に関する情報
- HTML形式メールの<body></body>部分を抽出した文字列
-
正規化に関する合意
-
"タイトル"項目
- 合意『見出しタグ(Hタグ)で囲まれた文字列を"タイトル"項目としてデータに追加』
-
"本文"項目
- 合意『本文タグ(Bodyタグ)で囲まれた文字列のうち、見出しタグ(Hタグ)で囲まれた文字列とHTMLタグを除いた文字列を"本文"項目としてデータに追加』
-
"タイトル"項目
◾️タッチポイント議事録(データソース)
-
CSVファイルの情報
-
合意『データソースの特性を以下の通りとする』
- エントリーリストCSVファイル(2025_event_mst_1.csv): 静的データ
-
合意『データソースの格納先を以下の通りとする』
-
エントリーリストCSVファイル(2025_event_mst_1.csv)
- 格納先:s3://data/content/2025_event_mst_1.csv
-
エントリーリストCSVファイル(2025_event_mst_1.csv)
-
合意『データソースのオプション情報を以下の通りとする』
-
エントリーリストCSVファイル(2025_event_mst_1.csv)
- ヘッダー名称とデータ型
- キャンペーンID STRING型
- キャンペーン名称 STRING型
- キャンペーン開始日 STRING型
- キャンペーン終了日 STRING型
- メール本文 STRING型
- データソースのヘッダー行の有無
- ヘッダー行:無し
- 空文字の対応
- 空文字はnullに置換。その後、0埋めする。
- 複数行が1セル内に存在する場合の対応
- 複数行が1セル内に存在する場合がそもそもない。
- 文字コード
- データソースの文字コードがUTF-8なので、変換する必要なし
- Indexの必要性
- 必要なし
- ヘッダー名称とデータ型
-
エントリーリストCSVファイル(2025_event_mst_1.csv)
-
合意『データソースの特性を以下の通りとする』
◾️アウトプットイメージ
タッチポイントより、クライアントとアウトプットイメージを次の通り合意いたしました。
例)
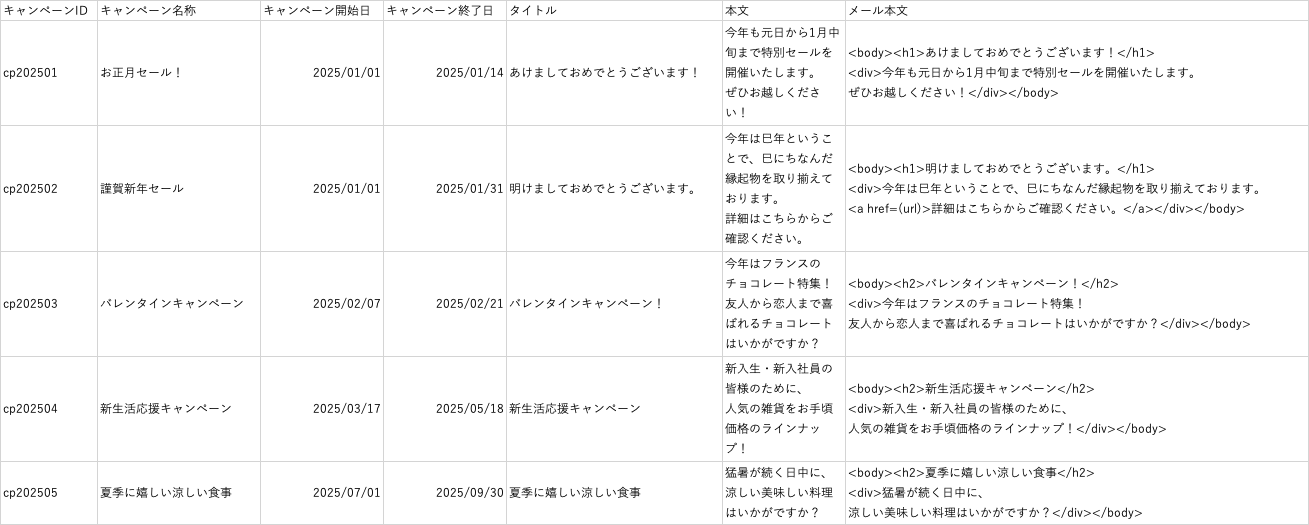
◾️ToBe(スクリプト作成)
タッチポイント議事録をもとに、スクリプトを作成します。
はじめに、CSVファイルを読み込みます。
CSVファイルを読み込み
from pyspark.sql.types import StructType, StructField, StringType
# スキーマ定義
event_mst_schema = StructType([
StructField("キャンペーンID", StringType(), False),
StructField("キャンペーン名称", StringType(), False),
StructField("キャンペーン開始日", StringType(), False),
StructField("キャンペーン終了日", StringType(), False),
StructField("メール本文", StringType(), False)
])
# データの読み込み
event_mst_sdf = spark.read.csv(
path="s3a://data/content/2025_event_mst_1.csv",
header=True,
schema=event_schema,
multiLine=True
)
次に、タッチポイントの合意に従い、"タイトル"項目と "本文"項目を作成します。
作成手順は以下の通りです。
- 正規表現を用意
- fn.regexp_extractで"メール本文"からHタグの中身を抽出
- fn.regexp_replaceで"メール本文"からHタグの中身とHTMLタグと改行コード(¥n)を削除
"タイトル"項目と"本文"項目を作成
# 正規表現を用意
title_pattern = r"<h[1-6]>(.*?)</h[1-6]>"
content_pattern = r"<h[1-6]>.*?</h[1-6]>|<.*?>|\n"
# 正規表現を使ってタイトル・本文を抽出
output_sdf = (
event_mst_sdf
.withColumn("タイトル", fn.regexp_extract("メール本文", title_pattern, 1))
.withColumn("本文", fn.regexp_replace("メール本文", content_pattern, ""))
.select(
"キャンペーンID",
"キャンペーン名称",
"キャンペーン開始日",
"キャンペーン終了日",
"タイトル",
"本文",
"メール本文"
)
)
| キャンペーンID | キャンペーン名称 | キャンペーン開始日 | キャンペーン終了日 | タイトル | 本文 | メール本文 |
|---|---|---|---|---|---|---|
| cp202501 | お正月セール! | 2025/01/01 | 2025/01/14 | あけましておめでとうございます! | 今年も元日から1月中旬まで特別セールを開催いたします。ぜひお越しください! | <body><h1>あけましておめでとうございます!</h1>\n<div>今年も元日から1月中旬まで特別セールを開催いたします。\nぜひお越しください!</div></body> |
| cp202502 | 謹賀新年セール | 2025/01/01 | 2025/01/31 | 明けましておめでとうございます。 | 今年は巳年ということで、巳にちなんだ縁起物を取り揃えております。詳細はこちらからご確認ください。 | <body><h1>明けましておめでとうございます。</h1>\n<div>今年は巳年ということで、巳にちなんだ縁起物を取り揃えております。\n<a href=(url)>詳細はこちらからご確認ください。</a></div></body> |
| cp202503 | バレンタインキャンペーン | 2025/02/07 | 2025/02/21 | バレンタインキャンペーン! | 今年はフランスのチョコレート特集!友人から恋人まで喜ばれるチョコレートはいかがですか? | <body><h2>バレンタインキャンペーン!</h2>\n<div>今年はフランスのチョコレート特集!\n友人から恋人まで喜ばれるチョコレートはいかがですか?</div></body> |
| cp202504 | 新生活応援キャンペーン | 2025/03/17 | 2025/05/18 | 新生活応援キャンペーン | 新入生・新入社員の皆様のために、人気の雑貨をお手頃価格のラインナップ! | <body><h2>新生活応援キャンペーン</h2>\n<div>新入生・新入社員の皆様のために、\n人気の雑貨をお手頃価格のラインナップ!</div></body> |
| cp202505 | 夏季に嬉しい涼しい食事 | 2025/07/01 | 2025/09/30 | 夏季に嬉しい涼しい食事 | 猛暑が続く日中に、涼しい美味しい料理はいかがですか? | <body><h2>夏季に嬉しい涼しい食事</h2>\n<div>猛暑が続く日中に、\n涼しい美味しい料理はいかがですか?</div></body> |
(見づらくて申し訳ありません)
上記の結果から、操作が意図した通りであることが確認できました。
最後に、スクリプト全量をご紹介します。
スクリプト全量
from pyspark.sql import SparkSession
from pyspark.sql import functions as fn
from pyspark.sql.types import StructType, StructField, StringType
import pandas as pd
# セッション作成
spark = SparkSession.builder.getOrCreate()
# スキーマ定義
event_schema = StructType([
StructField("キャンペーンID", StringType(), False),
StructField("キャンペーン名称", StringType(), False),
StructField("キャンペーン開始日", StringType(), False),
StructField("キャンペーン終了日", StringType(), False),
StructField("メール本文", StringType(), False)
])
# データの読み込み
event_mst_sdf = spark.read.csv(
path="s3a://data/content/2025_event_mst_1.csv",
header=True,
schema=event_schema,
multiLine=True
)
# 正規表現を用意
title_pattern = r"<h[1-6]>(.*?)</h[1-6]>"
content_pattern = r"<h[1-6]>.*?</h[1-6]>|<.*?>|\n"
# 正規表現を使ってタイトル・本文を抽出
output_sdf = (
event_mst_sdf
.withColumn("タイトル", fn.regexp_extract("メール本文", title_pattern, 1))
.withColumn("本文", fn.regexp_replace("メール本文", content_pattern, ""))
.select(
"キャンペーンID",
"キャンペーン名称",
"キャンペーン開始日",
"キャンペーン終了日",
"タイトル",
"本文",
"メール本文"
)
)
『結論』
◾️HTML文の正規化を習得するメリット(ビジネスサイド)
HTML文の正規化を習得するメリットは以下の通りです。
-
顧客の嗜好や行動の正確な把握
- Webデータの正規化によって、より一貫したユーザー行動や傾向を把握でき、マーケティングや戦略の精度が向上する。
-
分析精度の向上
- 正規化を行うことで、異なる形式のHTMLデータが統一され、分析に必要な信頼性の高いデータを得られる。
◾️HTML文の正規化を習得するメリット(エンジニアリングサイド)
HTML文の正規化を習得するメリットは以下の通りです。
-
自動化の促進
- 正規化のプロセスを自動化することで、手作業を減らし、より迅速にデータを活用できるようになる。
-
メンテナンスの簡素化
- 統一されたデータ形式により、今後の保守やアップデートが容易になり、エラーを減少させる。
Discussion
このコードで、正規表現を最初に用意する理由は何ですか?