マルチモーダル分類メモ
Multimodal Classification: Current Landscape, Taxonomy and Future Directions
「早期」、「後期」、「中期」、「ハイブリッド」といった用語が用いられてきました
画像、テキストなどの各要素をどの段階で合成するか?によっておおよその手法が分類されているらしい
1. 早期融合
早期融合は、主要な学習モデルが実行される前に、すべてのマルチモーダル データがマージされるときに行われます。2 つ以上のモダリティからのデータが結合され、学習アルゴリズムに渡されます。この種の融合を実現する最も一般的な方法の 1 つは、従来の特徴ベクトルや事前学習済みニューラル ネットワークからの出力ノードなど、入力モダリティデータを単純に連結することです。
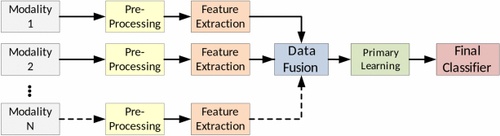
学習機の作成はClassificierの1回のみ。
2. 後期融合
後期融合は、図2に示すように、最終分類の前に各モダリティについて独立して特徴抽出を実行します。融合段階の出力には、ディープネットワークを用いた低レベルの学習済み特徴量、または完全な分類アルゴリズムによるクラス確率が含まれます。どちらの場合も、学習結果は最終的な分類のために統合されます。

- pros
- 各モダリティを特定のアルゴリズムでトレーニングできる
- 将来的に異なるモダリティを追加または交換することが容易
- 各モダリティを特定のアルゴリズムでトレーニングできる
- cons
- モダリティ間のデータ共有が不足している(データ間の関係性を学習できていない)
3. モダリティ間の融合
モダリティ間の融合は、主要な学習段階の前または最中に、モダリティ固有のデータを共有できるようにします。初期または後期の融合とは異なり、このアプローチは、各モダリティが互いのコンテキストを使用して、モデル全体の予測力を向上させる方法を提供します。
(方法をイメージ出来てないが、)事前学習時にデータ共有を行いつつ学習させることでより良い結果が得られたらしい。
単一のデータ共有操作を備えたクロスモダリティ アーキテクチャ

学習プロセス中にモダリティ間のデータが複数回共有されるサンプルのクロスモダリティ アーキテクチャ

データ融合
データ融合手法を連結とマージ融合の2つに分類

連結
このデータ融合手法は、モダリティデータを単純に連結して単一の特徴ベクトルを形成します。この手法を使用する場合、入力データは生の特徴量、クラス尤度ベクトル、またはニューラルネットワークノードのいずれかです。連結の例を図5(a)に示します。これは従来の機械学習の特徴量の例であり、図5(b)はニューラルネットワークノードの例です。
マージ
このアプローチは、モダリティデータと、単純な連結よりも複雑なビジネスロジックを結合します。マージ処理は、従来の機能では算術演算子(\sigma)は、図5 (c)に示すように、入力値を新しい特徴ベクトルに変換します。ニューラルネットワークのマージは、モダリティ固有のノードを、ネットワークの重みとバイアスを利用して特徴を結合する出力マージ層に接続します(図5(d))。
雰囲気はわかったので、実装的に良さそうなものを探してみる
a,b,c,d feature data concatnate
参考
各モーダル
Tabular (mlp)
class TabularFeatureExtractor(nn.Module):
def __init__(self, input_dim, output_dim):
super(TabularFeatureExtractor, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, output_dim)
)
def forward(self, x):
return self.net(x)
imageFeature
class ImageFeatureExtractor(nn.Module):
def __init__(self, output_dim):
super(ImageFeatureExtractor, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.head = nn.Sequential(
nn.Flatten(),
nn.Linear(self.flattened_size, output_dim)
)
def forward(self, x):
x = self.features(x)
x = self.head(x)
return x
AudioFeature
class AudioFeatureExtractor(nn.Module):
def __init__(self, output_dim):
super(AudioFeatureExtractor, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=AUDIO_FEATURES_SHAPE[0], out_channels=16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.head = nn.Sequential(
nn.Flatten(),
nn.Linear(self.flattened_size, output_dim)
)
def forward(self, x):
x = self.features(x)
x = self.head(x)
return x
a. concatenation(features)
- 提示されたコードと同様でいい
- 3モーダルのFeatureを
torch.catによって並列で結合してLinear層に入れてる
class MultimodalClassifier(nn.Module):
def __init__(self, num_tabular_features, image_feature_dim, audio_feature_dim, fusion_dim, num_classes):
super(MultimodalClassifier, self).__init__()
self.tabular_extractor = TabularFeatureExtractor(num_tabular_features, fusion_dim)
self.image_extractor = ImageFeatureExtractor(fusion_dim)
self.audio_extractor = AudioFeatureExtractor(fusion_dim)
# Fusion layer
self.fusion_mlp = nn.Sequential(
nn.Linear(fusion_dim * 3, 256), # Concatenate features from all 3 modalities
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)
def forward(self, tabular_data, image_data, audio_data):
tabular_features = self.tabular_extractor(tabular_data)
image_features = self.image_extractor(image_data)
audio_features = self.audio_extractor(audio_data)
# Concatenate features
combined_features = torch.cat((tabular_features, image_features, audio_features), dim=1)
output = self.fusion_mlp(combined_features)
return output
c. Merged がわかりやすいので手法Cから
c. merged (features)
- 単に合計する
- fusion_dim は同一の想定なので単に足すだけでいいはず?
- mlp層も fusion_dimに合わせる
...
# Fusion layer
self.fusion_mlp = nn.Sequential(
nn.Linear(fusion_dim, 256), # merged features from all 3 modalities
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)
def forward(self, tabular_data, image_data, audio_data):
tabular_features = self.tabular_extractor(tabular_data)
image_features = self.image_extractor(image_data)
audio_features = self.audio_extractor(audio_data)
# merge features (sum)
merged_features = tabular_features + image_features + audio_features
# 内積, 調和平均などいろいろ試せそう
output = self.fusion_mlp(merged_features)
return output
b,d network merge
- "networkとしてマージする" の意味がよくわからない
- 1つの nn.Sequential モデルとして使うみたいな意味?
- 各モーダルの全結合層を抜いて中間層として扱う
- 各モーダルの中間層をLinear層でマージ すればいいのかな