論文要約:Multi-word Term Embeddings Improve Lexical Product Retrieval
この論文を読もうとしたきっかけ
- セマンティック検索でファッションドメインの語を扱う方法を理解
- Elasticsearch9系でrank_vectors mappingによりlate-interactionが可能になったので理解
Abstract
ECにおける製品検索に特化した新しい埋め込みモデル「H1」について述べている。
H1モデルの主な特徴と利点
- 複数の単語からなる製品名を一つのトークンとして(つまりフレーズのように)処理できる点が大きな特徴
- 例えば「new balance shoes」や「gloria jeans kids wear」といった検索クエリに対して、「new balance」や「gloria jeans」などのブランド名を一語として正しく認識・処理可能
- このような処理によって、検索精度を高めつつ、再現率(Recall)を損なわずに結果を返すことが可能
ハイブリッド検索での性能比較
- H1モデルを、ハイブリッド検索(キーワード検索+ベクトル検索)の中で他の最先端モデルと性能を比較した
- 評価の結果、H1モデルはWANDS公開データセットにおいてmAP@12 = 56.1% 、 R@1k = 86.6%を記録し、他のSoTAモデルを上回るパフォーマンスを示した
Introduction
製品検索における語彙検索モデル(BM25等)の課題
- 語彙ミスマッチ問題:クエリと商品の語が一致しないと、検索再現率(Recall)が低下する
- 意味理解の欠如:クエリと商品の文脈的なつながりを把握できず、検索精度(Precision)も低下する
これらの問題の根本は、語彙検索モデルが離散的で疎な単語表現に依存しており、柔軟な意味の類似性を捉えにくい点にある。
セマンティック検索モデルの登場と意義
- セマンティック検索では、単語やフレーズを連続ベクトル(埋め込み)で表現することで、意味的な関係性を反映できる
- これにより、語彙ミスマッチの問題をある程度緩和可能
- 現在の研究潮流は、語彙検索とセマンティック検索のハイブリッド化へ向かっている
製品検索は「一般的な文書検索」とは異なる
製品検索は以下の点でユニークな性質を持つ:
- ランキングの仕組みが異なる:文書内の単語頻度(TF)に依存するBM25のような手法は、製品検索では有効でないことが多い
- マルチモーダル性:製品ページはタイトル・説明・画像など複数の情報を含むため、検索システムはそれらを統合的に扱う必要がある
- 検索目的が異なる:製品検索は購買意図に基づくため、一般の情報検索とはユーザー行動が異なる
- 評価指標が異なる:テキストや画像などのモダリティ単位で評価されることもあり、再現率や精度の計測方法にも独自性がある
本研究の目的
製品検索におけるハイブリッド検索システムを対象に、セマンティックモデルとトークン化の工夫が検索性能にどのように寄与するかを評価する。
特に、ブランド名などの複数語を1つのトークンとして処理するSentencePiece拡張と、Late Interaction(クエリの単語ベクトルと商品の単語ベクトルを検索実行時に比較してスコアを出す方法)による類似度計算の組み合わせが、検索精度に与える影響を明らかにする。
Methodology
MethodologyではH1モデルの概要が示されている。
構成とアーキテクチャ
H1はColBERTに着想を得た簡素なDual Encoderモデル。クエリと商品をそれぞれBERTベースのエンコーダーに通し、共通のベクトル空間に変換して類似度を計算。
※ColBERTと大きく異なるポイントは以下で示す
特徴:カスタム語彙のトークン化
H1の特徴は、ブランド名などを1トークンとして処理できる点。
- 「new balance shoes」のようなクエリで「new balance」を単語の並びではなく、ブランドとして理解
- SentencePieceトークナイザーにカスタム語彙を追加
- H1はトークナイザーにSentencePieceを使っている
- split_by_whitespace=False でマルチワード対応
類似度計算:sColBERT関数
- クエリ中の各トークンと商品内のすべてのトークンの最大類似度を合計してスコアを算出
- 平均ではなく最大を使うことで、重要な語の影響を強く反映できる
- クエリトークンが複数ある場合は合計してスコアとする

学習
ポジティブ(関連あり)とネガティブ(無関係)のクエリ・商品ペアで学習。損失関数により、ポジティブな類似度は高く、ネガティブは低くなるよう最適化される。
オフライン処理:商品とキーワードのインデックス作成
H1モデルはあらかじめ商品とクエリ単語の関連性を計算しトークンID→商品IDのインデックスを作成する。
クエリ側
- ユーザーが使いそうなキーワードやフレーズを収集
- 「new balance」のようなブランド名を1つのトークンとして扱う(語彙に「new balance」というブランド名を組み込んでおく)
- 各トークンをベクトルに変換
商品側
- 商品説明文をトークンに分割し、同様に埋め込みを生成(ここで上記同様ブランド名を1つのトークンとして扱う)
- 各トークンをベクトルに変換
インデックスの作成
- クエリトークン毎に商品トークン群の類似度をそれぞれ計算。商品トークンの類似度の最大値をクエリトークンと商品の類似度とする(sColBERT関数)
- クエリトークン毎に、閾値以上の類似度商品を関連づけてインデックスとする(ColBERTよりインデックス量が少ない)(閾値の決め方については論文中に記載はなかった)
例:「new balance」トークン→ New Balance製品群が登録される
(閾値が厳しいと、new balanceというトークンが含まれる商品のみに限定されそう。閾値を緩くするとこれが一致しない商品を含まれてくるイメージ)
オンライン評価:実際の検索を模して性能を測定
事前に作ったインデックスを使って検索・評価を行う。
商品候補の取得
- クエリ(例:「new balance shoes」)をトークン分割 → 「new balance」「shoes」
- インデックスから、それぞれに関連する商品を取得
- 候補を結合して1つのリストにする
検索結果の並び替えと評価
- 候補商品とクエリ全体の類似度を再計算
- 類似度の高い順に商品を並び替え → 検索結果として表示
評価結果(H1モデルのスコア)
- mAP@12(上位12件の平均適合率):56.1%
- R@1k(上位1000件の再現率):86.6%
これらのスコアは他の先進モデルを上回っている。
Experiments
ExperimentsではH1モデルと既存の検索モデルの性能評価について詳しく記載されている。
比較対象モデル
- H1モデル
- TCT-ColBERT
- Single Encoder (SE)
- Dual Encoder (DE)
- ColBERT
トークン化手法
- Byte Pair Encoding (BPE)
- Unigram
- Word tokenization
また各トークン化手法には、2つのバリエーションが提案された:
- ブランド名を特殊トークンとして追加した「マルチトークン (mt) バージョン」
- 標準の「非マルチトークン (non-mt) バージョン」
評価方法論と指標
以下の指標を計算:
- mAP@12
- R@1k
データセット
WANDSデータセット(EC検索評価用データセット)
データセットの主な特徴は以下の通り:
- 42,994の製品候補
- 480のクエリ
- 233,448のクエリと製品のペアに対する関連性スコア
関連性スコアは「完全に関連 (Exact)」、「部分的に関連 (Partial)」、「無関係 (Irrelevant)」の3段階で注釈付けされていますが、モデルの学習には「Exact (1)」と「Irrelevant (-1)」のみが使用され、学習前にクラスバランスが調整されました。
アブレーションスタディ
H1、SE、DEの各モデルタイプについて、最良の結果をもたらす以下を探索:
トークン化手法
- Byte Pair Encoding (BPE)
- Unigram
- Word tokenization
モデルのハイパーパラメータ(埋め込み次元数)
結果、以下の場合に最良の結果を達成:
- H1モデル
- 768埋め込み次元
- BPE、マルチトークン (mt) の組み合わせ
R@1k = 86.6%およびmAP@12 = 56.1%という最良の結果を達成しました。
BPEとUnigramの両方において、mtがどのモデル、どの埋め込み次元数でも一貫して優れた結果を生み出すことが確認された。
最良モデルの比較
アブレーションスタディで得られた最適なハイパーパラメータを持つH1、SE、DEモデルと、ColBERTモデルの性能が比較されました。
ColBERTのWANDSデータセットでの評価結果(Table 1)が示されており、H1モデルは特にmAP@12(Precision at 12 items)においてColBERTよりも良い結果を示している。

H1モデルは、他のモデルと比較して、カットオフ閾値kの増加に伴うPrecisionの低下が緩やかであり、Recallの維持能力も高いことが以下の図で示されている。
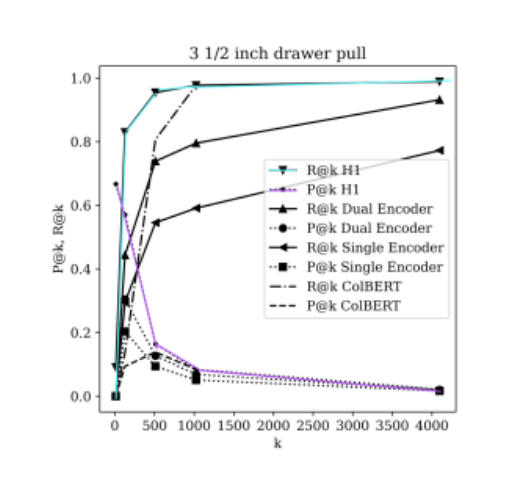
この評価により、H1モデルがWANDSデータセットでmAP@12 = 56.1%およびR@1k = 86.6%を達成し、既存のSoTAモデルを上回る新たなベンチマークを設定したと結論付けられている。
Conclusion
H1モデルは、Eコマース検索特化の埋め込みモデル:
- 「new balance」等の複数単語ブランド名を単一トークン処理することで、検索精度と効率を大幅に向上
- WANDSデータセットで最高性能(mAP@12=56.1%、R@1k=86.6%)を達成
補足
H1とColBERTの違いについてメモ
トークナイザーの違いについて
H1はSentencePieceを使っている
- ブランド名などの新語を容易に追加しやすい
- 語彙とマージルールが密結合になっている
- ユーザー定義語彙をサポートしている
ColBERTはWordPieceなどのBERT互換のトークナイザーを使っている
- WordPieceはブランド名などの新語を追加しようとしても、WordPieceマージルールに則っていないので難しい
- 語彙とマージルールが疎結合になっている
- ユーザー定義語彙をサポートしていない
(※詳細な理解が間に合わなかったので、本質的になぜ難しいかはわからなかった)
モデルの違いについて
| 項目 | H1 | ColBERT |
|---|---|---|
| モデルの使われ方 | 検索時に使われず、オフライン時のみ使われる | 検索時に使う |
| インデックス、ストレージとして保持する内容 | トークンごとに対応する候補商品(逆インデックス) | 全トークン毎のベクトル、商品の全トークンベクトル |
| Late Interaction 処理 | インデックスから候補絞り→再スコアリング | 全ドキュメントを再スコアリング |
なぜH1は比較的新しい語彙追加が簡単で、ColBERTは難しいのか?
使っているトークナイザー(WordPiece)の影響
インデックス構造の柔軟性
- H1はインデックス構造がトークン→商品群のため、新しい語彙(トークン)が追加されたらそれに対応する商品群を追加すれば良い
- ColBERTはドキュメントのトークン毎のベクトル値を持つため、全トークンベクトルを再構築する必要がある。モデルをクエリ時に使う。
Discussion