🥖
データベース速攻入門備忘録
はじめに
データベース速攻入門のインデックスとトランザクションとデッドロックの章の備忘録
インデックス
そもそもなぜインデックスが必要か?
インデックスが無い場合はテーブルの全レコードを最初から最後まで探すため、非常に時間がかかる
レコード数が数百万行ある場合を想像するとそのコスト感は容易に想像できる
インデックス
インデックスの中身は、検索項目とその検索項目が存在するレコードのポインタ
例えば、以下のようなpersonテーブルがあり
| アドレス | age | name |
|---|---|---|
| 30番地 | 10 | Alice |
| 45番地 | 12 | Bob |
| 78番地 | 32 | Bobby |
| 134番地 | 25 | Com |
nameカラムにインデックスが貼ってあったとする
| nameカラム | レコードのポインタ |
|---|---|
| Alice | 30番地 |
| Bob | 45番地 |
| Bobby | 78番地 |
| Com | 134番地 |
そして
select * from person where name = 'Bob'
というクエリが発行された場合、オプティマイザは以下のような処理をする
- personテーブルのnameカラムにはインデックスが貼ってある
- nameカラムのインデックスのデータの中身を参照し、Bから始まるデータの中でBobを見つける
- インデックスデータの中にはレコードのポインタが一緒に格納されているので、そのポインタ参照先の実データを返す
- Bobは45番地だからそこにある他のカラムのデータも一緒にまとめて参照できる
- MySQLの場合(ポインタ=PKとなる)
- インデックス内のデータはソートされているため、Bob以降のデータは無駄な検索になるので検索しない
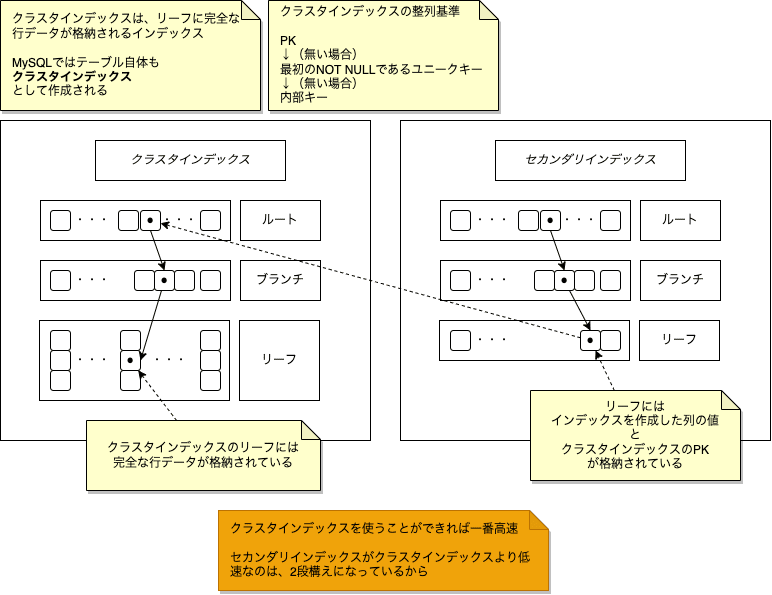
Bツリーインデックス
インデックスにも種類があり、MySQLで利用可能なインデックスはBツリーインデックスと呼ばれる構造でできている(一部例外を除く)
なので、Bツリーの仕組みを理解しておくことが重要
- ルートノード:インデックスの検索を開始する起点
- ブランチノード:ルートとリーフの間にあるリーフ群を担当するもの
- リーフノード:実際にインデックスされた列データとポインタのセットが格納されている場所
クラスタインデックスとセカンダリインデックス
- プライマリインデックス
- PKをキーにして検索する際に利用される
- セカンダリインデックス
- ユニークインデックスは、セカンダリインデックスにユニーク成約を付与したもの
PKのTIPS
- よほどのことがない限り、PKは必須
- RailsやDjangoなどのWebフレームワークはサロゲートキー(代理キー)を使っている
- PKを定義するサイズは可能な限り小さくする
- PKはクラスタインデックスだけでなく、セカンダリインデックスのリーフにも格納されるから
- 整列しているリーフ間に新たにPKを差し込まない
- INSERTやUPDATEで、整列しているリーフの間に追加された場合、再配列が発生することがあるから
- リーフに行データを格納しているので、再配列はコストが高い動作になる
- INSERTやUPDATEで、整列しているリーフの間に追加された場合、再配列が発生することがあるから
- プライマリキーがない場合はレプリケーションの同期速度が著しく落ちる
インデックスオプション
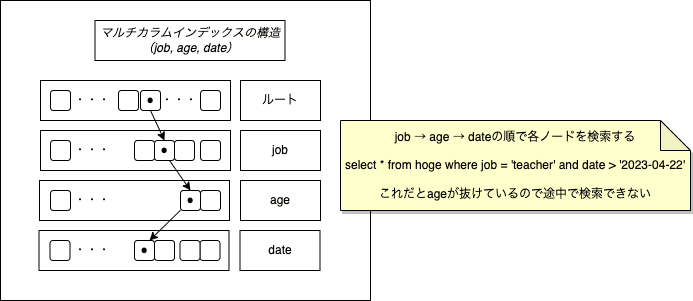
- マルチカラムインデックス
- よく利用する1つのインデックスに複数の列を含めるもの
- 複数の検索条件で利用
- 指定した列の順序でブランチ、リーフがソートされるので、検索条件によってインデックスが効かない場合があるので注意
- ファンクションインデックス
- あらかじめ関数構文をインデックスに指定することで、列の比較条件に関数を使用した場合にインデックスを利用できないという制限を回避するための機能
- プレフィックスインデックス
- インデックスサイズを小さくするために、列の何バイト目までを含めるかを指定
- 降順インデックス
- order by descのように降順ソートにもインデックスを利用するための機能
- 複数値インデックス
- JSON内の配列値にインデックスを利用するための機能
Explainコマンド
インデックスの利用の有無に着目するために「table」「possible_keys」「key」の3つに着目する
possible_keysにあるインデックスがkeyになかったり、possbile_keysにあるはずのインデックスがなかったりした場合はインデックスが効いてない
| カラム | 備考 |
|---|---|
| id | SELECT認識子 |
| select_type | SELECT型 |
| table | 出力行のテーブル |
| partitions | 一致するパーティション |
| type | 結合型 |
| possible_keys | 選択可能なインデックス |
| key | 実際に選択されたインデックス |
| key_len | 選択されたキーの長さ |
| ref | インデックスと比較されるカラム |
| rows | 調査される行の見積もり |
| filtered | テーブル条件によってフィルタ処理される行の割合 |
| Extra | 追加情報 |
インデックスが利用可能なケース
- 定数値との比較(=,>,<,BETWEEN)
- IS (NOT) NULL
- 結合処理(JOIN .. ON)
- 前方一致(LIKE '文字列%')
- MAX(), MIN()
- ORDER BY, GROUP BY
- マルチカラムインデックスの先頭列からAND条件で使っている場合
インデックスが利用できないケース
- マルチカラムインデックスの先頭列を指定してない
- マルチカラムインデックスの各列をOR条件で使用
- LIKE検索で後方一致や部分一致
- ORDER BYでASCとDESCを同時に指定している
- ORDER BY、GROUP BYで指定する列が複数のテーブルにまたがっている
- 比較する列のデータ型が一致しない(DATEとVARCHARやINTとCHARなど)
- 検索行数がテーブルの全行数の大半になるような場合
トランザクション
MySQLでトランザクションが利用できるのはInnoDBストレージエンジンのみ
ACID特性
- Atomicity(原子性)
- トランザクション内の処理は「すべて実行される」か「すべて実行されない」のどちらかでないと行けない
- ロールバックという処理が必要になる
- Consistency(一貫性)
- トランザクション実行前後でのデータの整合性が保証されていないといけない
- Isolation(独立性)
- トランザクション実行中は他の処理から隠蔽されている性質
- アプリケーションの仕様によっては必要でないケースがある。その場合はSQL規格で定義されている4つのトランザクションの分離レベルで調整できる。
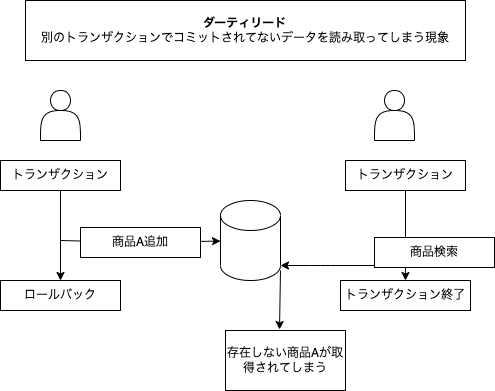
- READ UNCOMMITED: 他のトランザクションがコミットしていないデータも読めてしまう
- READ COMMITED: 他のトランザクションがコミットされたデータを読めてしまう(OracleyaSQLサーバーのデフォルト)
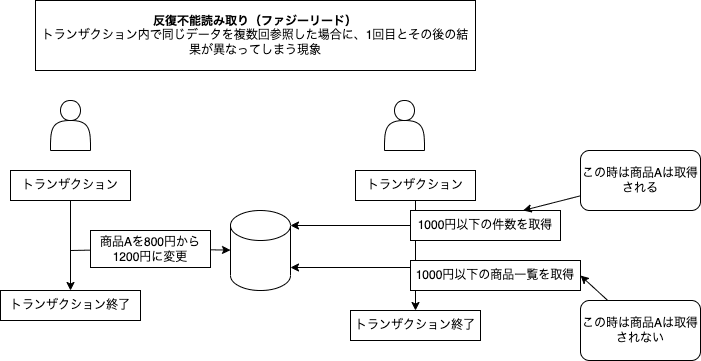
- REPEATABLE READ: 読み取り対象のデータが基本的には他のトランザクションにより変更されることはない(MySQLのデフォルト)
- SERIALIZABLE: トランザクションが重ならないように、制御し、安全にデータを操作できる。しかし、ロックの影響により同時実行性が低下してしまうため、あまり使われることはない。
- これらの分離レベルとダーティリード、反復不能読み取り(ファジーリード)、ファントムリードの関係性
分離レベル ダーティリード 反復不能読み取り ファントムリード READ UNCOMMITED 発生する 発生する 発生する READ COMMITED 発生しない 発生する 発生する REPEATABLE READ 発生しない 発生しうる(Locking Readの場合) 発生しうる(Locking Readの場合) SERIALIZABLE 発生しない 発生しない 発生しない - Locking Read:SELECT ... FOR SHAREで共有ロックを取得した参照を行う場合 or SELECT ... FOR UPDATEで排他ロックを取得して参照する場合
- ダーティリード
- 反復不能読み取り(ファジーリード)
- ファントムリード
- 反復不能読み取り(ファジーリード)の新規登録バージョン。1回目は存在しなかったのに、その後の参照では参照できてしまう状態
- アプリケーションの仕様によっては必要でないケースがある。その場合はSQL規格で定義されている4つのトランザクションの分離レベルで調整できる。
- トランザクション実行中は他の処理から隠蔽されている性質
- Durability(永続性)
- サーバーを冗長構成にしたり、バックアップをきちんと取っておいたりする必要
MySQLのTIPS
- AUTOCOMMITがデフォルトで有効化されている
- UPDATEを実行する度にトランザクションがコミットされる
- トランザクションの関数を宣言することで無効化できる
- UPDATEを実行する度にトランザクションがコミットされる
- 暗黙的なコミット
- COMMITを明示的に実行しなくてもコミットされる場合がある
- トランザクション内でインデックスを追加する場合
- COMMITを明示的に実行しなくてもコミットされる場合がある
- セーブポイント
- トランザクション内で指定した状態まで部分的に戻すことができる
- SAVEPOINT xxx; でセーブルポイントを指定
- ROLLBACK TO SAVEPOINT xxx; で指定のセーブポイントに戻る
デッドロック
複数のトランザクションが存在する条件下でお互いがお互いのロック解除待ちになってしまい処理が進まなくなってしまったこと
MySQLは
- テーブルロック: テーブル全体をロック
- 行ロック: 特定の行をロック。その他の行はロックされてない状態
- InnoDBの行ロックは複数種類ある
- レコードロック
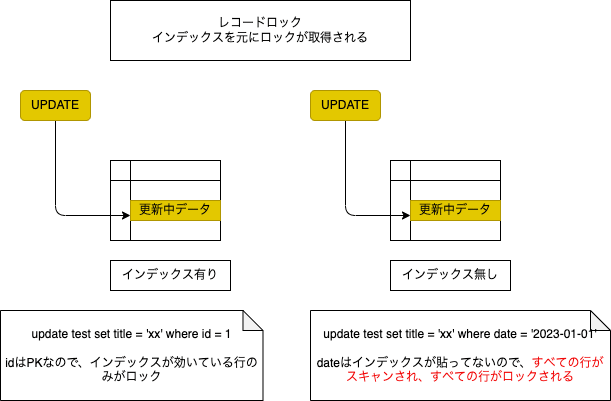
- ギャップロック

- ネクストキーロック
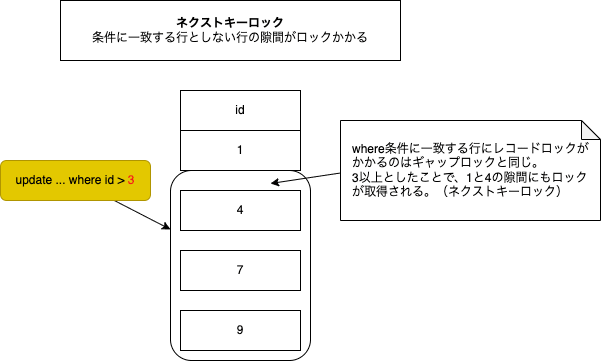
の2種類がある。
また、ロックには
- レコードロック
- InnoDBの行ロックは複数種類ある
- 共有ロック
- 他のトランザクションからは更新できない
- 読み取りのみ可能
- 他のトランザクションからも同じ対象に共有ロックが取得できる
- 排他ロック
- 他のトランザクションからは更新できない
- 読み取りのみ可能
- 他のトランザクションから共有ロックや排他ロックを取得することができない
の2つがある。
デッドロックTIPS
- トランザクションが別々のテーブルでもデッドロックが発生する可能性はある(外部キーにおけるデッドロック)
- 外部キーとなっているものを更新しようとして、別のトランザクションから外部キーの元テーブルの対象行を更新しようとする
- MySQLでは、innodb_deadlock_detectがデフォルト有効になっているので、デッドロックは自動で検出&ロールバックされる
- SHOW ENGINE INNODB STATUSで直近に発生したデッドロック情報を閲覧できる
- 直近のものしか表示されないので、すべての詳細なデッドロック情報を出力したい場合は、innodb_print_all_deadlocksを有効にするとエラーログに出力される
- ACTIVEの項目でロックの取得時間を確認して短くなるように調整する
- ロックの範囲を小さくする(トランザクションサイズを小さく)
- 適切なインデックスを貼る(インデックスが当たらないとフルスキャンになり全レコードがロック対象になるため)
Discussion