Pythonで儲かるAIをつくる読書メモ
5-2. 天候による売り上げ予測(回帰)
この本の中では初めての分類(2値分類)ではなく、数値を推測する章になっていて、回帰アルゴリズムを使用した紹介になっている。
目的変数
目的変数になりえるカラムが3つあったが、その中の1つを選択して使用していた。
3種類のモデルを作ることも可能です。しかし、実装が煩雑になるので、目的変数を一つに絞り込むことにします。...他の2つの目的変数を対象としたモデルも、...関心のある読者は自分で試してみて
とのこと
入力変数
日付の情報が格納されている列があったが、dropして落としていた。「年」「月」を表す列があることと、日付をそのまま取り扱う処理パターンもあり「時系列分析」を扱う章で説明する、とのことだった。
アルゴリズム
回帰のアルゴリズム選択にはXGBoostのXGBRegressorを使用。
学習・予測
# アルゴリズム選定
# XGBRegressorを選定する
from xgboost import XGBRegressor
algorithm = XGBRegressor(objective ='reg:squarederror',
random_state=random_seed)
# 登録ユーザー利用数予測モデルの学習と予測
# 学習
algorithm.fit(x_train, y_train)
# 予測
y_pred = algorithm.predict(x_test)
# 予測結果確認
print(y_pred[:5])
[4927.806 4889.2686 3571.434 3637.8308 4719.999 ]
評価
# 評価(登録ユーザー利用数)
# score関数の呼び出し
score = algorithm.score(x_test, y_test)
# R2値の計算
from sklearn.metrics import r2_score
r2_score = r2_score(y_test, y_pred)
# 結果確認
print(f'score: {score:.4f} r2_ score: {r2_score:.4f}')
score: 0.4206 r2_ score: 0.4206
実は会期でも分類と同様、score関数という評価用の関数がある
2つの値を比較...完全に一致。つまり、回帰モデルのscore関数はR²値(決定係数)を使っている
一般的にR²値は0.5より大きければモデルとして意味がある
0.426なのでモデルとしては意味がない結果になってしまった。
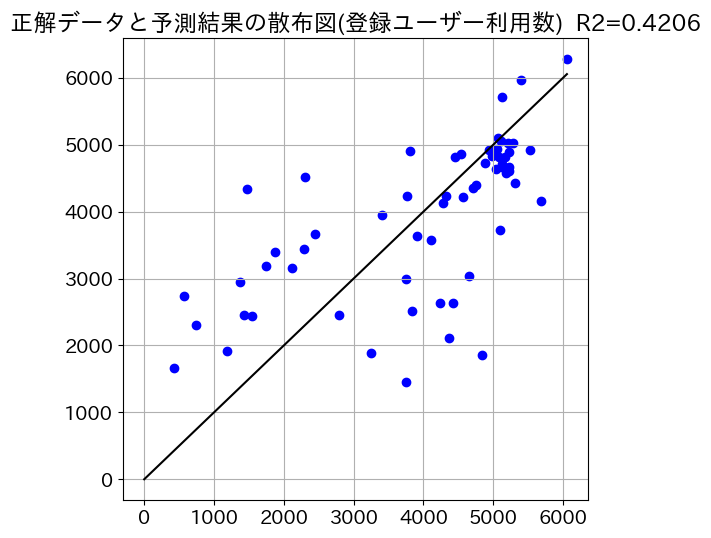
散布図表示
回帰のモデルでは、x軸を正解データ、y軸を予測結果にして散布図を表示すると、理想的には、すべての点がy=xのグラフに乗ります。散布図はモデルの制度を視覚的に理解する手かがりになります。
#正解データと予測結果を散布図で比較 (登録ユーザー利用数)
plt.figure(figsize=(6,6))
y_max = y_test.max()
plt.plot((0,y_max), (0, y_max), c='k')
plt.scatter(y_test, y_pred, c='b')
plt.title(f'正解データと予測結果の散布図(登録ユーザー利用数)\
R2={score:.4f}')
plt.grid()
plt.show()
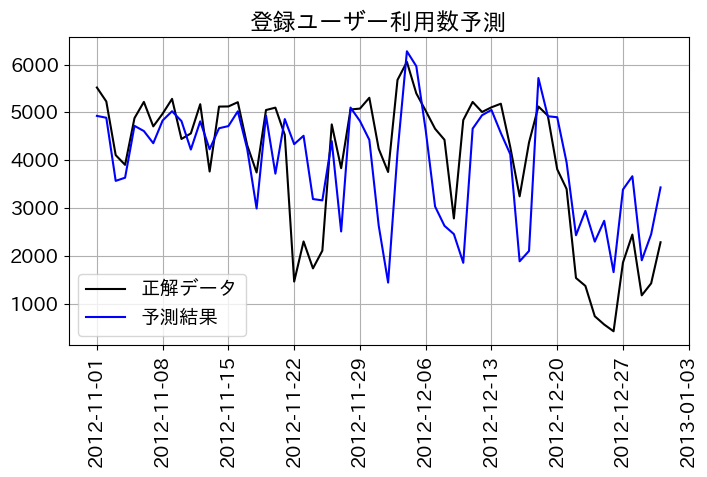
正解データと予測データを重ね書きした形で時系列グラフで表示する方法も紹介していた
チューニング
月と季節のカラム数値になっていて、
例えば「月」に関して言うと本来なら12月と1月は非常に近いのに、入力データの値としては一番離れてしまっています。このことがモデルの精度を悪くしている可能性が考えられます。「季節」に関しても同じことがいえます。
そこでこの2つの項目に...One-Hotエンコーディングをかけてみることにします。
ラベルの数値化で本来順序に意味がないものや、サイクル化(今回でいう12月から1月や、日曜から月曜のような)しているものは単純に数値化しないように、と他の教材で勉強したことがあったので、それだろう。
One-Hotエンコーディング後のR²(決定係数)は0.5099になったので制度がよくなった結果になった。
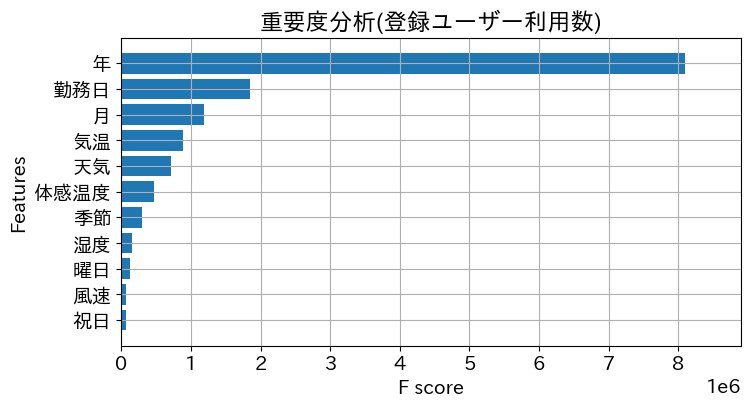
重要度分析
どの列の情報が重要だったかをxgboostのplot_importanceで描画できるとのこと
# 登録ユーザー利用数に対する重要度分析
import xgboost as xgb
fig, ax = plt.subplots(figsize=(8, 4))
xgb.plot_importance(algorithm, ax=ax, height=0.8,
importance_type='gain', show_values=False,
title='重要度分析(登録ユーザー利用数)')
plt.show()
5-3. 季節などの周期性で売上予測(時系列分析)
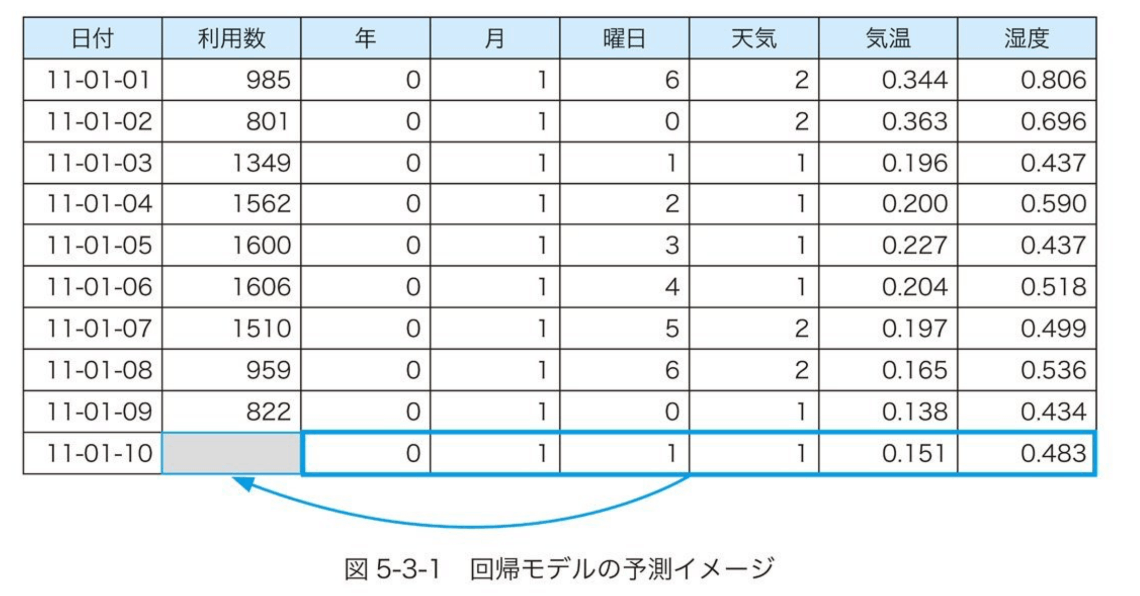
回帰モデルの予測イメージ、書籍から拝借
時系列分析の予測イメージ、書籍から拝借
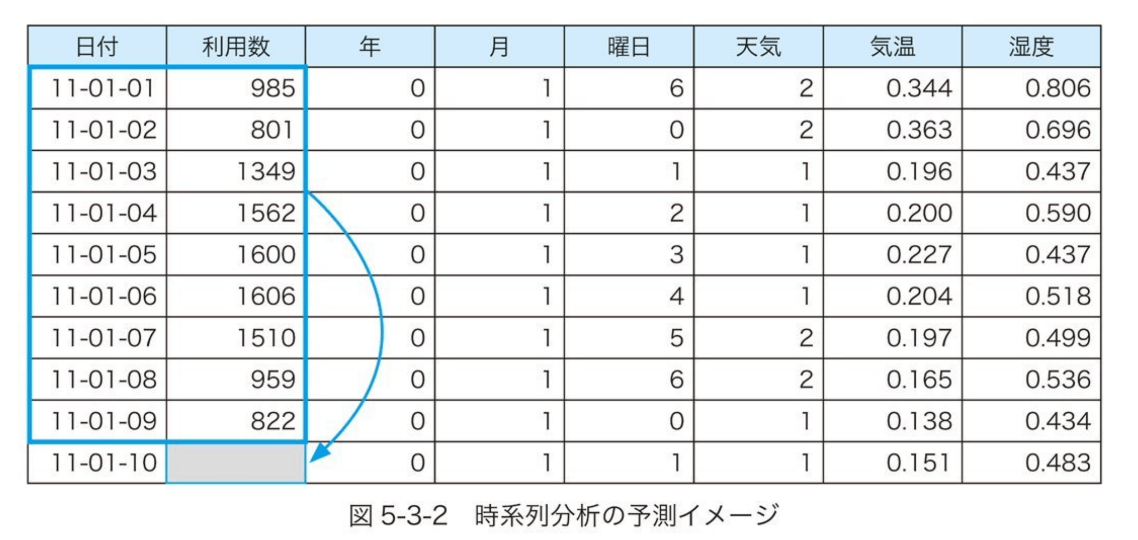
回帰モデルでは利用数の右側になる入力変数を利用して、利用数の予測をした。
時系列分析ではそれら入力変数を使用せずに、利用数を予測するとのこと。
日付のデータが重要な意味を持つとのこと。
「日付」をデータとして解析すると、...「年」「月」「曜日」の情報を抽出できます。しかも「月」「曜日」は周期性を持っています。...時系列分析の根本にある考えは、このような周期性を前提とした予測ということになります。...「周期関数」と「トレンド」を見つけることで将来の予測をするということになります。
アルゴリズム選択
# ライブラリのimport
from prophet import Prophet
# モデル選定
# 3つのseasonalityパラメータの設定が重要
# 今回のデータの場合、日単位のデータなのでdaily_seasonalityは不要
# weekly_seasonality とdaily_seasonalityは
# True / Falseの他に数値で指定することも可能 (三角関数の個数)
# seasonality_mode: additive(デフォルト) multiplicative
m1 = Prophet(yearly_seasonality=True, weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')
周期のパターンを見つけることが重要とのこと。
年周期、週周期、日周期(AM8からAM10までが利用高いとか)、それぞれyearly_seasonality, weekly_seasonality, daily_seasonalityにboolの値を設定する。
またもう一つ重要なパラメータがseasonlity_mode。additiveとmultiplicativeの2つの値が取れる。seasonality_modeは説明読んでもよく分からなかった。
宿題: seasonality_mode
seasonality_mode: オプションは [ ‘additive’、’multiplicative’] です。デフォルト‘additive’です。多くのビジネス時系列には乗法的季節性があります。これは、時系列を調べて、季節変動の大きさが時系列の大きさに応じて大きくなるかどうかを確認することで最もよく識別されます。
学習
# 学習
m1.fit(x_train)
予測
# 予測用データの作成
# (日付 ds だけの入ったデータフレーム)
# 61は予測したい日数 (2012-11-1 から2012-12-31)
future1 = m1.make_future_dataframe(periods=61, freq='D')
# 予測
# 結果はデータフレームで戻ってくる
fcst1 = m1.predict(future1)
評価
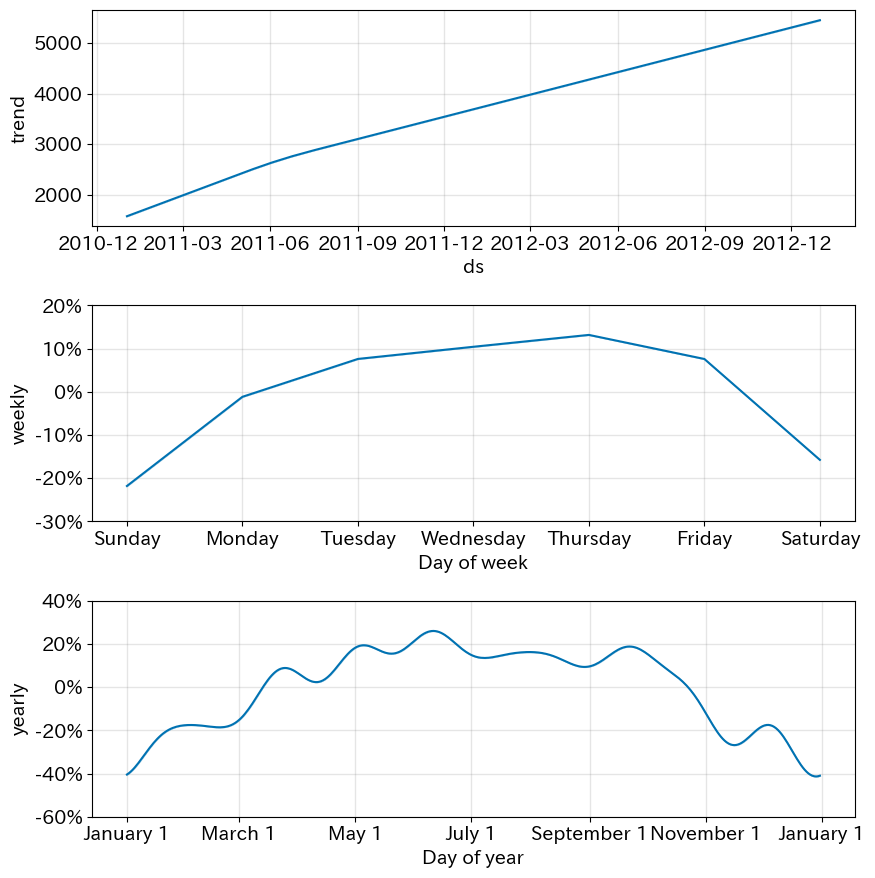
Prophet独自の評価方法であるplot_components
# 要素ごとのグラフ描画
# この段階ではトレンド、週周期、年周期
fig = m1.plot_components(fcst1)
plt.show()
長期トレンド、週周期、年周期(Trueを設定した箇所)の特徴が見れる。
訓練データ・検証データ全体のグラフ化
m1.plot(fsct1, ax=ax)
R²値(決定係数)の計算
# ypred1: fcst1から予測部分のみ抽出する
# 予測結果の中央値はyhatという項目に含まれる
ypred1 = fcst1[-61:][['yhat']].values
# ytest1: 予測期間中の正解データ
ytest1 = x_test['y'].values
# R2値の計算
from sklearn.metrics import r2_score
score = r2_score(ytest1, ypred1)
# 結果確認
print(f'R2 score:{score:.4f}')
R2 score:0.3730
予測期間中(検証期間中)のグラフ表示
ax.plot(dates_test, ytest1, label='正解データ', c='k')
ax.plot(dates_test, ypred1, label='予測結果', c='b')
チューニング
チューニングの最初のステップとして、「祝日」をモデルに組み込むことにします。
# holidaysパラメータを追加してモデルm2を生成
m2 = Prophet(yearly_seasonality=True,
weekly_seasonality=True, daily_seasonality=False,
holidays = df_add, seasonality_mode='multiplicative')
holidaysというパラメータにdf_addを指定。df_addの内容は本参照
チューニング2
日付以外の項目を入力データに追加する機能を持っています。
# アルゴリズム選定
m3 = Prophet(yearly_seasonality=True,
weekly_seasonality=True, daily_seasonality=False,
seasonality_mode='multiplicative', holidays = df_add)
# add_regressor関数で、「天気」「気温」「風速」「湿度」をモデルに組み込む
m3.add_regressor('天気')
m3.add_regressor('気温')
m3.add_regressor('風速')
m3.add_regressor('湿度')
# 学習
m3.fit(x2_train)
x2_trainの内容は本参照
# 予測用の入力データを作る
future3 = df3[['ds', '天気', '気温', '風速', '湿度']]
# 予測
fcst3 = m3.predict(future3)
評価方法は先述と同じ。本参照。
5-4 おすすめ商品の提案(アソシエーション分析)
著者さんのこの項の解説記事があった
モデル
アプリオリ分析、指示度、確信度、リフト値というのを使用した分析、モデリングがアソシエーション分析というのだと思う。
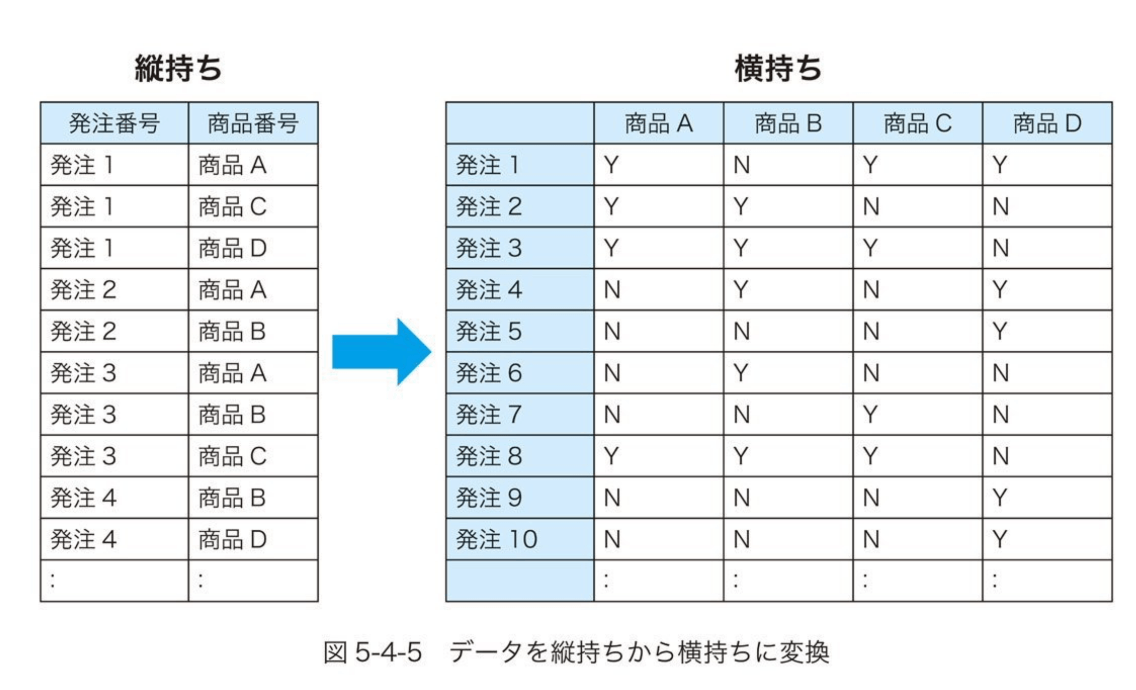
アプリオリ分析。イメージ書籍参照
アソシエーション分析全体像が多少イメージつきやすい。イメージ書籍参照
データ前処理
データをOne-Hot形式化
指示度、確信度、リフト値を計算するのに、データをOne-Hot形式化が必要なのだろう。
One-Hot形式化 -> 以下のようなイメージの形式に変換
書籍から拝借
# 発注番号と商品番号をキーに商品個数を集計する
w1 = df3.groupby(['発注番号', '商品番号'])['商品個数'].sum()
# 結果確認
print(w1.head())
発注番号 商品番号
536370 10002 48
21035 18
21724 12
21731 24
...
536852 21786 24
21791 12
22539 24
...
536974 20679 6
20725 10
20726 10
Name: 商品個数, dtype: int64
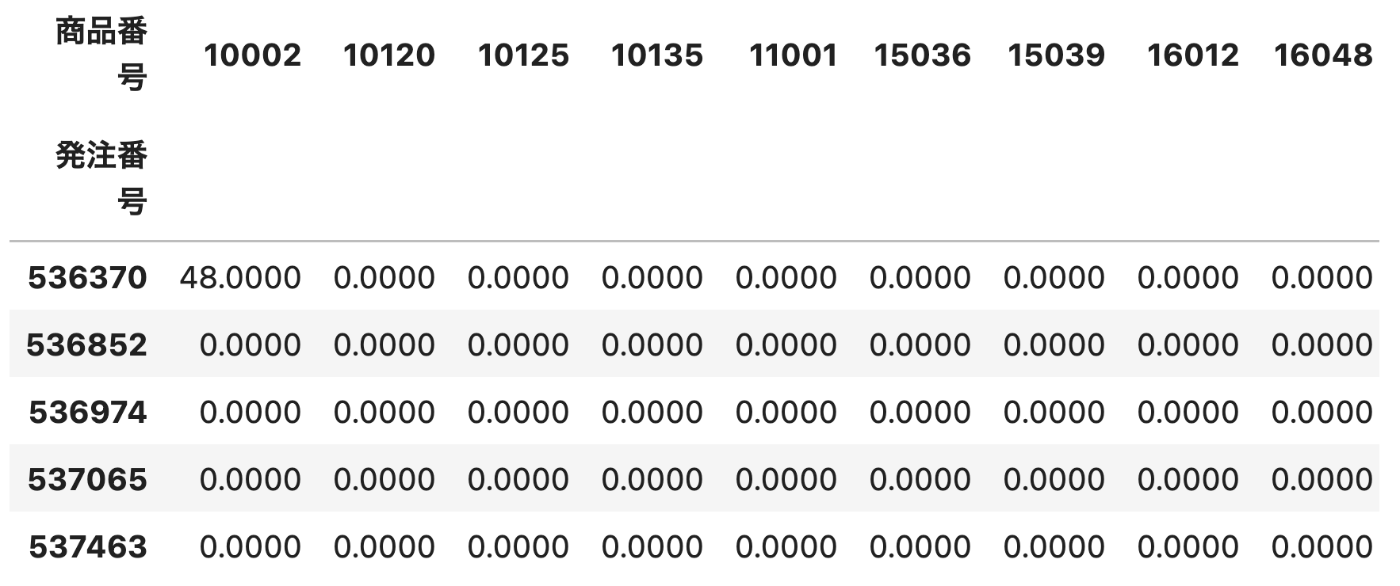
# 商品番号を列に移動 (unstack関数の利用)
w2 = w1.unstack().reset_index().fillna(0).set_index('発注番号')
# サイズ確認
print(w2.shape)
(392, 1542)
# 結果確認
display(w2.head())
# 集計結果が正か0かでTrue/Falseを設定
basket_df = w2.apply(lambda x: x>0)
# 結果確認
display(basket_df.head())
アルゴリズムの選択と分析
アソシエーション分析用のライブラリ
# ライブラリの読み込み
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
以降のコードは書籍または冒頭著者記事参考。
aprioriの方では、指示度を算出、しきい値0.06より大きかったら抽出ということをやっているらしい。
association_rulesの方では、確信度とリフト値の2種類があり、association_rules関数のパラメータで指定。この例では「リフト値が1以上」という条件を指定。
その結果、ある商品の強い関係が見ることができたが、これをどのようにビジネス上の戦略として考えられるかが重要な点とのこと。セット販売して割引とかが考えられると一つ示唆していた。
チューニング
しきい値0.06から0.065に増やして、同条件で分析した結果、分析で上位だったものがでなくなった。
分析の結果(書籍参照)指示度の値がしきい値より低かったので、除外されてしまった様子。
しきい値の値を低くしないと抽出できないものもある反面、小さくしすぎると計算量が膨大になるというトレードオフがある模様。試行錯誤によりこの値は見つけていく形になるとのこと。
関係グラフの視覚化
解説は以下
networkx.DiGraphヨクワカラナイ
より発展した分析
協調フィルタリングという分析手法がある。ただライブラリ読んで、結果を得るということは現段階ではできないので、がんばってください、というエール
教師なし学習による分析で意味を持つのは、得られた知見を基に戦略を打ち出せた時です。
5-5 顧客層に応じた販売戦略(クラスタリング、次元圧縮)
データ読み込みから確認まで
販売チャネルと地域をdrop対象にしているけどなんでだろ。
区分を数値で表したデータだから数値としての意味はないからか?文脈として不必要?
クラスタリングの実施
K平均方 K-Meansを利用
# データ前処理とデータ分割は不要
# アルゴリズムの選択
from sklearn.cluster import KMeans
# グループ数を定義
clusters=4
# アルゴリズムの定義
algorithm = KMeans(n_clusters=clusters,
random_state=random_seed)
# 学習、予測の実施
y_pred = algorithm.fit_predict(df2)
# 結果の一部確認
print(y_pred[:20])
[1 2 1 1 0 1 1 1 1 2 2 1 0 2 0 1 2 1 1 1]
教師あり学習の場合、...「学習」「予測」とステップを勧めました。しかし前節のアソシエーション分析と同様に、...教師なし学習の場合は、学習と予測は同時に行います。
クラスタリング結果の分析
# グループごとの平均値計算
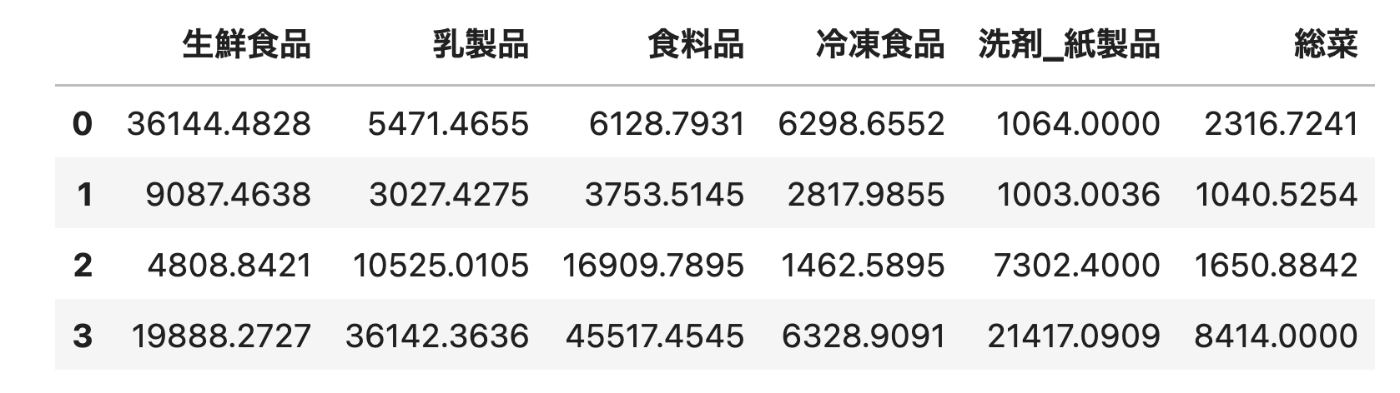
df_cluster = df2.groupby(y_pred).mean()
display(df_cluster)
以下このスクラップ書いている人の疑問
y_predの値でgroupbyの結果がイメージつかないな。
pd.Series(y_pred).value_counts()
1 276
2 95
0 58
3 11
dtype: int64
groupbyのbyパラメータの訳
選択された軸と同じ長さのリストまたはndarrayが渡された場合、値がそのまま使用されてグループが決定されます
下のデータフレームに0, 1, 2, 3で表現されるndarrayのgoupbyってなんだ
あ、分かった。各レコードに0, 1, 2, 3というラベルをつけて、その値でグループ分けしているのか。
「顧客を特徴ごとにグループ化する」-> 今回はk平均方を使って予測値0, 1, 2 3でグループ化した。
分析をグラフ化
# グループ別の棒グラフ表示
df_cluster.plot(kind='bar',stacked=True,
figsize=(10, 6),colormap='jet')
plt.show()
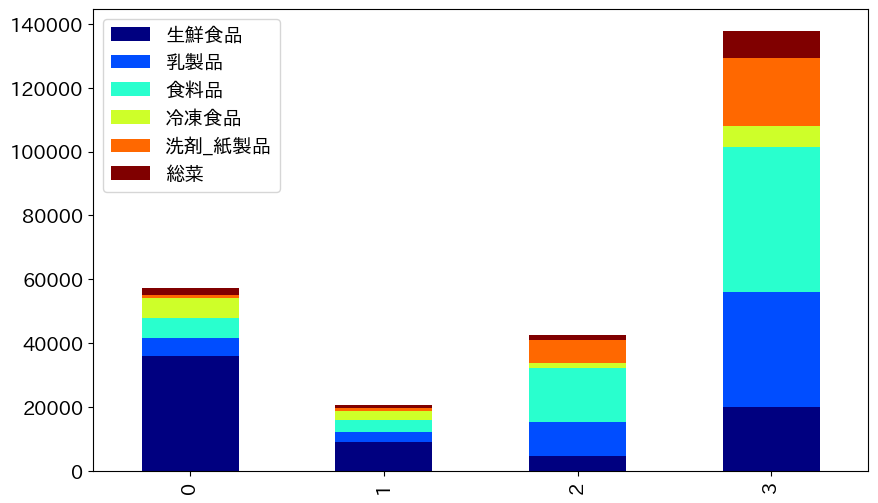
特徴
0グループは生鮮食品グループ、1グループは金額少ない、2, 3は食料品多め
販売チャネルと地域を含めた分析は書籍参照
次元圧縮の実施
アルゴリズム、Principal Component Analysis主成分分析
# アルゴリズムの選択
from sklearn.decomposition import PCA
# モデル生成
# 散布図表示が目的のため2次元に圧縮
pca = PCA(n_components=2)
# 学習・変換の実施
d2 = pca.fit_transform(df2)
# 結果の一部表示
print(d2[:5,:])
[[ 650.0221 1585.5191]
[-4426.805 4042.4515]
[-4841.9987 2578.7622]
[ 990.3464 -6279.806 ]
[10657.9987 -2159.7258]]
次元圧縮の活用方法
書籍参照
6 AIプロジェクトを成功させる上流工程のツボ
6.1 機械学習の適用領域の選択
- 処理パターンのあてはめが肝要
- 教師あり学習は正解データ入手が命
- AIに100%は期待するな
6.2 業務データの入手・確認
データの所在確認
部門をまたがるデータ連携の課題
データの品質
One-Hot エンコーディングの問題 (特徴量多すぎてしまう場合)