100 Go Mistakes and How to Avoid Them読書メモ
1 Chapter 1. Go: Simple to learn but hard to master
2 Code and project organization
コードをイディオムに整理する
抽象化を効率的に扱う:インターフェースとジェネリクス
プロジェクトの構成方法に関するベストプラクティス
2.1 #1: Unintended variable shadowing
シャドーイングのせいで格納されるべき変数に値が入っていない紹介
ミスコード
okコード
2.2 #2: Unnecessary nested code
readabilityを向上するために以下を紹介
- ネストしたブロックの数を減らす努力
- ハッピーパスを左に揃えること
- できるだけ早く戻ること
2.3 #3: Misusing init functions
init欠点
- エラーハンドリングに制限がある。init関数でのエラーマネージメントがpanicくらいしかない
- テストの実装方法が複雑になる
- ステートを設定する必要がある場合、それはグローバル変数になる
このセクションで見たような静的コンフィギュレーションの定義など、状況によっては役に立つこともある。そうでない場合は、ほとんどの場合、アドホック関数で初期化を処理すべきです。
その役に立つとされる例のリンク https://cs.opensource.google/go/x/website/+/e0d934b4:blog/blog.go;l=32
2.4 #4: Overusing getters and setters
ゲッターやセッターの必要性を見出したり、前述したように、前方互換性を保証しながら将来の必要性を予見したりするのであれば、それらを使用することに何の問題もありません。
2.5 #5: Interface pollution
インターフェイスが大きくなればなるほど、抽象度は弱くなる。
とはいえ
インターフェイスに最適な粒度を見つけるのは、必ずしも一筋縄ではいかない。
いつインターフェースを使うかのヒントに以下を挙げていた
- Common behavior
- Decoupling
- Restricting behavior
Common behavior
Common behaviorの例にsortのインターフェースを紹介していた。
sort.Interfaceは適切な抽象化レベルであるため、非常に価値がある。
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less returns whether the element with index i should sort
// before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
Decoupling
具象クラスに依存しないでインターフェースに依存したらテストしやすくなるよ、という紹介
もうひとつの重要なユースケースは、コードを実装から切り離すことだ。具体的な実装の代わりに抽象化に頼れば、コードを変更することなく、実装自体を別のものに置き換えることができる。これはリスコフの置換原理(ロバート・C・マーティンのSOLID設計原則のL)である。
Restricting behavior
特定の動作に制限するためにインターフェースを使用することで、公開範囲を管理。
2.5.3 Interface pollution
Don’t design with interfaces, discover them.
インターフェースを設計をするな。見つけたときインターフェースにまとめなさい。たいていオーバーエンジニアリングだから、とのこと。
2.6 #6: Interface on the producer side
⭐
他の言語から来た人はstore側にinterfaceがある設計をよしとする。
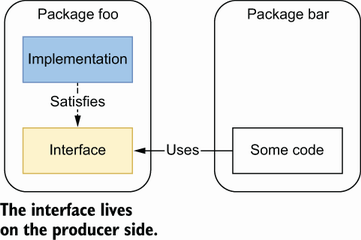
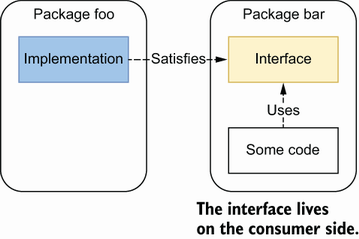
Goでは下のケースを採用するといいのでは、とのこと
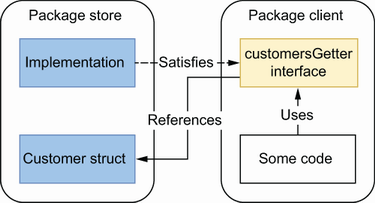
出所: 書籍から
interface から referencesしているのは以下のstore.Customerのこと
package client
type customersGetter interface {
GetAllCustomers() ([]store.Customer, error)
}
実際はstore.Customerはビジネスドメインのbusiness.model.Customerモデルを指すのだろう。
2.7 #7: Returning interfaces
⭐
ここでの言いたいこと
Returning structs instead of interfaces
Accepting interfaces if possible
2.8 #8: any says nothing
marshalやフォーマットに関する有用な場所以外は極力使用するのを避けよう
一般的に、私たちが書くコードを過度に一般化することは何としても避けるべきだ。コードの表現力など他の面を向上させるのであれば、少しくらい重複したコードの方がいい場合もあるかもしれない。
2.9 #9: Being confused about when to use generics
~int vs. int
type customConstraint interface {
~int
String() string
}
intを使うとその型に限定されるのに対し、~intはintを基礎型とするすべての型を限定する。
in generic
型パラメーターの最後の注意点は、型パラメーターはメソッド引数では使えないということです。例えば、以下のメソッドはコンパイルできない
type Foo struct {}
func (Foo) bar[T any](t T) {}
./main.go:29:15: methods cannot have type parameters
メソッドでジェネリックを使いたい場合、型パラメーターにする必要があるのはレシーバーだ。
2.10 #10: Not being aware of the possible problems with type embedding
embeddingすると公開されてほしくないものも公開されるデメリットを紹介していた
逆に、embeddingすることによっていちいちforward(プロキシー)する手間がなくなる例を紹介していた
Embedding vs. OOP subclassing
エンベッディングでは、埋め込まれた型はメソッドのレシーバーのままです。逆に、サブクラス化では、サブクラスがメソッドのレシーバーになります。
型埋め込みは主に利便性のために使われます。ほとんどの場合、ビヘイビアを促進するために使われます。
フィールドへのアクセスを単純化するためだけならembeddingはやめよう。
外部から隠したいフィールドやメソッドがあるならembeddingはやめよう。
型埋め込みを使用すると、エクスポートされた構造体のメンテナンスに余計な手間がかかるという意見もあるかもしれません。... このような余分な手間を省くために、チームはパブリック構造体への型の埋め込みを禁止することもできます。
2.11 #11: Not using the functional options pattern
Config struct
Builder pattern
Functional options pattern
2.12 #12: Project misorganization
まず、早すぎるパッケージングはプロジェクトを複雑にしすぎる可能性があるので避けるべきだ。完璧な構造を前もって無理に作るよりも、シンプルな構成にして、プロジェクトの中身を理解してから進化させた方がいい場合もある。
パッケージの名前は、何が含まれているかではなく、何を提供するかで決めるべきだ。
とりあえず一貫性が大事です、とのこと。
2.13 #13: Creating utility packages
意味のない名前で共有パッケージを作るのは良いアイデアではない。これには、utils、common、base などのユーティリティ・パッケージも含まれます。また、パッケージの名前を、それが何を含むかではなく、何を提供するかで決めることは、そのパッケージの表現力を高める効率的な方法であることを覚えておいてください。
ここでは小さいstringsetパッケージを作り、凝集度が高い、表現力豊かさを表現した紹介をしていた。
2.14 #14: Ignoring package name collisions
import redis
redis := redis.NewClient()
パッケージ名と変数名でコリジョン起こしているから気をつけてね、という話。
変数名の名前変えたり、importにエイリアスつけては、と紹介していた。
関数名もたまに変数名とコリジョン起こすの気をつけて、という話。copyを紹介してた。
2.15 #15: Missing code documentation
関数のコメントを書くときは、その関数がどのように行うかではなく、何を意図しているかを強調すべき、とのこと。
変数やconst変数は、目的を書くといいとのこと。
export=公開している要素は文書しなさい、とのこと。
2.16 #16: Not using linters
Summary
⭐
3 3 Data types
3.1 #17: Creating confusion with octal literals
file, err := os.OpenFile("foo", os.O_RDONLY, 0o644)
接頭辞に0ではなく、0oと表現しても8進数を表現できる紹介。可読性を高めるため。
2進数(Binary): 0b or 0B prefix
16進数(Hexadecimal): 0x or 0X prefix
虚数(Imaginary): i suffix (for example, 3i)
underscoreで区切りもつけられる。1_000_000_000
3.2 #18: Neglecting integer overflows
可能な限り小さな負の値は1111111111111111111111111111(1が32個)ではない(32bitアーキテクチャの場合)。10000000000000000000000000000000(符号ビット1と0が31個)とのこと。
var counter int32 = math.MaxInt32 + 1 はpanicになるけど
var counter int32 = math.MaxInt32
counter++
はpanicにならない。
バリデーション方法を紹介: https://github.com/teivah/100-go-mistakes/blob/master/src/03-data-types/18-integer-overflows/main.go
3.3 #19: Not understanding floating points
その差が小さな誤差値より小さいかどうかを比較する必要がある。例えば、testifyテストライブラリ(https://github.com/stretchr/testify)にはInDelta関数があり、2つの値が与えられたデルタの範囲内にあることを保証します。
デルタを使用して2つの値を比較することは、異なるマシン間で有効なテストを実施するための解決策となる。
浮動小数点演算の順序は、結果の精度に影響を与える可能性があることに留意してください。
サンプルコード: https://github.com/teivah/100-go-mistakes/blob/master/src/03-data-types/19-floating-points/main.go
近似値計算のTIPS
- 2つの浮動小数点数を比較する場合、その差が許容範囲内であることを確認する。
- 加算や減算を行うときは、より正確を期すために、同じような次数の演算をグループ化する。
- 精度を高めるために、加算、減算、乗算、除算を必要とする一連の演算を行う場合は、乗算と除算を最初に行う。
3.4 #20: Not understanding slice length and capacity
s1 := make([]int, 3, 6) ❶
s2 := s1[1:3]
のようにスライシングしたときはポインタは共有しているから、変更が共有されることを気をつけて。
3.5 #21: Inefficient slice initialization
capacityに値を設定しておくとパフォーマンスいいよ、という話。
3.6 #22: Being confused about nil vs. empty slices
"空"のスライスの初期化ではemptyまたはnilで返すならnilで返しなさい、とのこと。
var s []string これを使ったら、とのこと
3.7 #23: Not properly checking if a slice is empty
スライスの空チェックはlenで確認したらいいよ、とのこと
if len(some_list) != 0 {
}
インターフェイスをデザインするとき、nilと空のスライスを区別するのは避けるべき。呼び出し側はその2つを分けて考えないから、とのこと
3.8 #24: Not making slice copies correctly
copyでスライスをコピーするとき、lengthもきちんと考慮しなさい、という紹介
copy関数以外のコピーの方法もある、以下playgroundに記載
3.9 #25: Unexpected side effects using slice append
以下のコードは意図しない動きになるコードだ
s1 := []int{1, 2, 3}
s2 := s1[1:2]
s3 := append(s2, 10)
結果は以下
スライスや、スライスのスライスを関数の引数に渡すときも注意が必要
あとそもそもスライスは関数の引数に渡して、その先で中身を変更すると、呼び出し元のスライスも変更されることに注意
3.10 #26: Slices and memory leaks
3.10.1 Leaking capacity
msgのcapacityはスライシングした場合、capacityの容量は含んだままなのでメモリの確保が予期せぬメモリリークにつながる紹介。
NG
return msg[:5]
OK
msgType := make([]byte, 5)
copy(msgType, msg)
return msgType
NG
return msg[:5:5]
ガベージコレクタが開放しないとのこと。
3.10.2 Slice and pointers
メモリリークにつながる可能性のあるコード
3.11 #27: Inefficient map initialization
サイズが分かっていれば容量指定しよう、の紹介
m := make(map[string]int, 1_000_000)
3.12 #28: Maps and memory leaks
mapは要素を削除してもメモリが残ってしまう挙動がある。(runtime.hmapの設計における要因で?例えばBというフィールド)
解決策としてはGoにマップの再作成を強制したり、ポインタを使用する、を紹介していた。
3.13 #29: Comparing values incorrectly
sliceとmap(structに含む場合も)は != nilはできるが ==、!=の比較はできない
⭐
reflect.DeepEqual
google/go-cmp
stretchr/testify
Summary
⭐
4 Control structures
4.1 #30: Ignoring the fact that elements are copied in range loops
rangeの割当はcopy。
4.2 #31: Ignoring how arguments are evaluated in range loops
classic for loopは無限ループになる。評価がその都度になるから。rangeは最初だけ評価。
4.3 #32: Ignoring the impact of using pointer elements in range loops
セマンティクスの面では、ポインタ・セマンティクスを使ってデータを保存することは、要素を共有することを意味する。例えば、以下のメソッドは、要素をキャッシュに挿入するロジックを保持している:
type Store struct {
m map[string]*Foo
}
func (s Store) Put(id string, foo *Foo) {
s.m[id] = foo
// ...
}
sliceのrangeで代入されたvalueは同じポインターアドレスを使いまわしている。
NG
OK
4.4 #33: Making wrong assumptions during map iterations
- イテレーションの順番は再現性あるものではない
- イテレーションの間にentryを追加すべきではない
イテレーション中にマップエントリーが作成された場合、そのエントリーはイテレーション中に作成されることもあれば、スキップされることもある。この選択は、作成される各エントリーと、イテレーションごとに異なる可能性がある。
NG
OK
4.5 #34: Ignoring how the break statement works
swtich, selectがループの中にあったrbreak気をつけて、ラベル使って抜けよう、という紹介。
4.6 #35: Using defer inside a loop
ループ内でdeferを呼び出すと、すべての呼び出しがスタックされる:各反復中に実行されないので、ループが終了しないとメモリー・リークを引き起こす可能性がある、
NG
OK1
OK2
Summary
⭐
5 Strings
5.1 #36: Not understanding the concept of a rune
⭐
charsetとは、その名の通り、文字の集合のことです。例えば、Unicode charsetは2^21文字を含んでいます。
encodingは文字のリストをバイナリに変換したものです。例えば、UTF-8は全てのユニコード文字を可変バイト数(1バイトから4バイト)でエンコードできるエンコード規格です。
文字集合の定義を簡単にするために文字について触れました。しかしユニコードでは、一つの値で表される項目を指すためにコードポイントという概念を使います。例えば、汉字はU+6C49コードポイントで識別されます。
ルーンはユニコードのコードポイントです。
s := string([]byte{0xE6, 0xB1, 0x89})
fmt.Printf("%s\n", s) // 汉
Goでは、文字列は任意のバイトの不変スライスを参照する。
5.2 #37: Inaccurate string iteration
lenはルーン数ではなく、文字列のバイト数を返す。
ルーン数はUTF-8ならutf8.RuneCountInStringでカウントできる
fmt.Println(utf8.RuneCountInString(s))
5.3 #38: Misusing trim functions
TrimRightとTrimSuffixの挙動の違いを紹介
5.4 #39: Under-optimized string concatenation
performance issue。メモリの再割当て頻発。
OK
_, _ = sb.WriteString(value)について
このメソッドがnil以外のエラーを返すことはない。では、このメソッドがシグネチャの一部としてエラーを返す目的は何だろうか?strings.Builderはio.StringWriterインターフェイスを実装しており、このインターフェイスには1つのメソッドが含まれている:WriteString(s string) (n int, err error)である。したがって、このインターフェイスに準拠するためには、WriteStringはエラーを返さなければならない。
とのこと
5.5 #40: Useless string conversions
stringから[]byte、または[]byteからstringの変換を無駄にしないように、という紹介
stringパッケージにある便利関数はbytesパッケージにもある可能性があるので心に留めといてね、とのこと
5.6 #41: Substrings and memory leaks
まず以下は気をつけて
s1 := "Hello, World!"
s2 := s1[:5] // Hello
意図した振る舞いはきっとこっち
s1 := "Hêllo, World!"
s2 := string([]rune(s1)[:5]) // Hêllo
メモリアロケーション的なTIPSで
NG
OK
Summary
⭐
6 Functions and methods
When to use value or pointer receivers
When to use named result parameters and their potential side effects
Avoiding a common mistake while returning a nil receiver
Why using functions that accept a filename isn’t a best practice
Handling defer arguments
6.1 #42: Not knowing which type of receiver to use
- レシーバーがポインターでなければならない
メソッドがレシーバーを変更する必要がある場合。このルールは、レシーバーがスライスで、メソッドが要素を追加する必要がある場合にも有効です
type slice []int
func (s *slice) add(element int) {
*s = append(*s, element)
}
-
レシーバーがポインターであるべき
レシーバーが大きなオブジェクトのとき。 -
レシーバーが値でなければならない
イミュータブルにするとき
map, function, or channelのとき値にしないとコンパイルエラーになる。(ならなくない?-> https://go.dev/play/p/4e_OO9bhwWT) -
レシーバーが値であるべき
変更させる必要がないスライスのとき
小さいarrayやtime.TImeのようなミュータブルなフィールドがないstructのとき
int, float64, or stringのような基本型のとき
レシーバーにポインターと値が混ざるのはOKか
基本的には混ざらないようにしよう、ただtime.TimeのUnmarshalBinaryのように混在していしまうケースは仕方がない。
6.2 #43: Never using named result parameters
効果がある例
表現力が少し乏しい
type locator interface {
getCoordinates(address string) (float32, float32, error)
}
より豊か
type locator interface {
getCoordinates(address string) (lat, lng float32, err error)
}
6.3 #44: Unintended side effects with named result parameters
NG
errが0値(nil)で初期化されるので、明示的代入をしなくてもコンパイルエラーにならない
OK
6.4 #45: Returning a nil receiver
⭐
インターフェースはディスパッチ・ラッパーである。ここでは、wrappeeはnil(MultiErrorポインタ)であり、wrapperはそうではない(エラーインターフェース)。
nilレシーバーを持つことは許され、nilポインターから変換されたインターフェイスはnilインターフェイスではない。
インターフェイスを返す必要がある場合、nilポインタではなくnil値を直接返すべきである。一般的に、nilポインターを持つことは望ましい状態ではなく、バグの可能性が高いことを意味する。
NG
OK
6.5 #46: Using a filename as a function input
ファイル名を引数とするのはどうだろうか。 io.Readerを引数にとってみよう
ファイルでも、HTTPリエスとでも、ソケット入力でも対応できる。
テストが読みやすくなるし、メンテナンスしやすくなる
6.6 #47: Ignoring how defer arguments and receivers are evaluated
deferの引数はコールしたとき評価される。その後にその引数に値が入ってもその値が入る訳では無い。
解決策の1つとしてはdeferの引数にポインターを使う。
2つ目の方法としては、クロージャーを使う
func main() {
i := 0
j := 0
defer func(i int) {
fmt.Println(i, j)
}(i)
i++
j++
}
deferにメソッドを指定したらどうなるか
レシーバーが値のとき -> deferをコールしたときの評価。deferの後にレシーバーのフィールドを更新してもそれは反映されていない状態のもの
レシーバーがポインターのとき -> ポインタによって参照される構造体に加えられた変更が見える。
Summary
⭐
7 Error management
Understanding when to panic
Knowing when to wrap an error
Comparing error types and error values efficiently since Go 1.13
Handling errors idiomatically
Understanding how to ignore an error
Handling errors in defer calls
7.1 #48: Panicking
いつ使うか
1つはプログラマーのエラーを知らせるケース、もう1つはアプリケーションが必須の依存関係を作成できないケースである。
7.2 #49: Ignoring when to wrap an error
ラッピングとは、エラーにコンテキストを追加したり、エラーを特定のタイプとしてマークしたりすることである。エラーをマークする必要がある場合は、カスタム・エラー・タイプを作成する必要があります。しかし、コンテキストを追加するだけであれば、新しいエラー・タイプを作成する必要がないため、%wディレクティブでfmt.Errorfを使用すべきである。しかし、エラー・ラッピングは、呼び出し元がエラーを利用できるようにするため、潜在的なカップリングを引き起こす。これを防ぎたいのであれば、エラーラッピングではなく、エラー変換、例えば、%vディレクティブでfmt.Errorfを使うべきです。
7.3 #50: Checking an error type inaccurately
error wrappingとそのcheck(errors.As)の紹介
switch err := err.(type)
errors.As
7.4 #51: Checking an error value inaccurately
sentinel errors = error values
A sentinel error is an error defined as a global variable:
import "errors"
var ErrFoo = errors.New("foo")
慣例では接頭辞にErrがつく。例えば、ErrFoo、sql.ErrNoRows
期待されるエラーは、エラー値(センチネルエラー)として設計されるべきである: var ErrFoo = errors.New("foo").
予期しないエラーは、エラー・タイプとして設計する必要があります。type BarError struct { ... }、そしてエラー・インターフェースを実装している。
センチネル・エラーをラップすることもできます。fmt.Errorfと%wディレクティブを使用してsql.ErrNoRowsをラップすると、err == sql.ErrNoRowsは常に偽になります。
ここでもGo 1.13が答えを提供しています。errors.Asを使用して型に対するエラーをチェックする方法について見てきました。エラー値では、errors.Isを使用できます。
7.5 #52: Handling an error twice
経験則として、エラーは一度だけ処理すべきである。エラーを記録することはエラーを処理することであり、エラーを返すこともエラーを処理することである。したがって、ログを取るかエラーを返すかのどちらかであるべきで、両方を取るべきでは決してない。
NG
OK
wrappingしてコンテキストを追加していることもワンポイント
7.6 #53: Not handling an error
func notify() error {
// ...
}
notify()
エラーをなかったコトにするより
// At-most once delivery.
// Hence, it's accepted to miss some of them in case of errors.
_ = notify()
こちらのほうがいいよ、という紹介。未来のメンテナーが理解してコードの意味を理解してくれる、という内容。
7.7 #54: Not handling defer errors
NG
OK
このOKのコードは7.5 #52: Handling an error twiceに当てはまらないのか?
Summary
⭐
8 Concurrency: Foundations
Understanding concurrency and parallelism
Why concurrency isn’t always faster
The impacts of CPU-bound and I/O-bound workloads
Using channels vs. mutexes
Understanding the differences between data races and race conditions
Working with Go contexts
8.1 #55: Mixing up concurrency and parallelism
8.2 #56: Thinking concurrency is always faster
Concurrent: 前節のウェイター・スレッドとコーヒーマシンのスレッドのように、2つ以上のスレッドが重複した時間帯に開始、実行、完了することができる。
Parallel: 複数のウェイター・スレッドのように、同じタスクを一度に複数回実行できる。
concurrencyは常に逐次実行より早い訳では無いから、ファーストチョイスではないよ、の紹介
8.3 #57: Being puzzled about when to use channels or mutexes
一般的に、parallel goroutinesは同期する必要があります。
parallel goroutines間の同期はミューテックスによって実現されるべきです。
concurrent goroutinesのゴルーチンは協調し、オーケストレーションする必要がある。
その教頭はチャネルで表現されるべき。
状態を共有したいときや共有リソースにアクセスしたいとき、ミューテックスはそのリソースへの排他的アクセスを保証する。逆に、チャネルは、データの有無にかかわらず(チャネル構造体{}の有無にかかわらず)シグナルを送るための仕組みである。協調や所有権の移動は、チャネルを介して実現されるべきである。
8.4 #58: Not understanding race problems
8.4.1 Data races vs. race conditions
Data race
解決方法1
解決方法2
解決方法3
これまで見てきたことをまとめよう。データ・レースは、複数のゴルーチンが同じメモリ・ロケーション(例えば同じ変数)に同時にアクセスし、そのうちの少なくとも1つが書き込みを行っている場合に発生する。また、3つの同期化アプローチでこの問題を防ぐ方法も見てきた
アトミック操作の使用
クリティカルセクションをミューテックスで保護する。
通信とチャネルを使用して、1つの変数が1つのゴルーチンによってのみ更新されるようにする
reace condition
これは結局iは1か2にどちらになるか分からない。
アプリケーションはデータ・レースがなくても、制御不能なイベント(ゴルーチンの実行、チャネルへのメッセージの発行速度、データベースへの呼び出しの持続時間など)に依存する動作をすることがあります。これがreace conditionです。
8.4.2 The Go memory model
NG
OK1
OK2
8.5 #59: Not understanding the concurrency impacts of a workload type
CPU-boundとI/O-boundに起因するものがある、とのこと
8.6 #60: Misunderstanding Go contexts
Summary
⭐
9 Concurrency: Practice
Preventing common mistakes with goroutines and channels
Understanding the impacts of using standard data structures alongside concurrent code
Using the standard library and some extensions
Avoiding data races and deadlocks
9.1 #61: Propagating an inappropriate context
以下はpublishより早くクライアントにレスポンスが返されるとキャンセルされる、とのこと
けどそれを、context.background()すると早くに返されようがきちんとpublishは実行されるとのこと。
けどまだ問題がある。新しいコンテキストの発行をしてしまうと、r.Context()の中に重要な値を格納していたらそれが使えなくなるからだ。
それを解決するために、新しいコンテキスト(の役割)を作ってみることだ。
これで、キャンセルもタイムアウトされない、とのこと。
9.2 #62: Starting a goroutine without knowing when to stop it
ゴルーチンが開始されるときはいつでも、いつ停止するかについて明確な計画を立てるべきです。最後になるが、あるゴルーチンがリソースを作成し、その有効期限がアプリケーションの有効期限に束縛されている場合、アプリケーションを終了する前にこのゴルーチンが完了するのを待った方が安全だろう。こうすることで、リソースを確実に解放することができます。
NG
OK
defer w.close()で開放
9.3 #63: Not being careful with goroutines and loop variables
9.4 #64: Expecting deterministic behavior using select and channels
NG
OK
複数のチャンネルでselectを使用する場合、複数のオプションが可能な場合、ソース順で最初のケースが自動的に勝つわけではないことを覚えておく必要があります。その代わり、Goはランダムに選択するので、どの選択肢が選ばれるかは保証されない。この振る舞いを克服するために、単一のプロデューサー・ゴルーチンの場合、バッファされないチャネルか単一のチャネルを使用することができます。複数のプロデューサ・グルーチンの場合、優先順位付けを処理するために内部セレクトとデフォルトを使うことができます。
9.5 #65: Not using notification channels
空の構造体は、意味がないことを伝えるための事実上の標準です。たとえば、ハッシュセット構造(一意な要素の集合)が必要な場合は、空の構造体を値として使用します。
map[K]struct{}.
チャネルはデータ付きでもデータなしでもかまいません。Goの標準に準拠した慣用的なAPIを設計する場合、データのないチャネルはchan struct{}型で表現する必要があることを覚えておきましょう。こうすることで、受信者はメッセージの内容から意味を期待せず、メッセージを受け取ったという事実だけを期待すればよいことが明確になります。Goでは、このようなチャネルを通知チャネルと呼びます。
9.6 #66: Not using nil channels
まとめると、nilチャネルへの待機や送信はブロッキング動作であり、この動作は無駄ではないということがわかった。2つのチャネルをマージする例を通して見てきたように、nilチャネルを使用して、select文から1つのケースを削除するエレガントなステートマシンを実装することができます。nilチャンネルは条件によっては有用であり、並行コードを扱うGo開発者のツールセットの一部であるべきだ。
9.7 #67: Being puzzled about channel size
同期が保証されるのはunbuffered channelであって、buffered channelではない。さらに、もしbuffered channelが必要なら、チャンネル・サイズのデフォルト値として1つを使うことを忘れてはならない。他の値を使うかどうかは、正確なプロセスを用いて慎重に決めるべきで、その根拠はおそらくコメントされるべきだろう。最後になったが、buffered channelを選択すると、unbuffered channelであれば発見しやすい、デッドロックが発生する可能性があることを覚えておこう。
9.8 #68: Forgetting about possible side effects with string formatting
9.8.1 etcd data race
ctxKey := fmt.Sprintf("%v", ctx)
// ...
wgs := w.streams[ctxKey]
修正(https://github.com/etcd-io/etcd/pull/7816)は、マップのキーをフォーマットするためにfmt.Sprintfに頼らず、コンテキスト内のラップされた値の連鎖をトラバースして読み取らないようにすることだった。その代わりに、カスタムstreamKeyFromCtx関数を実装して、変更不可能な特定のコンテキスト値からキーを抽出することで解決した。
意味分からなかった
9.8.2 Deadlock
(そもそもstring()の中でロックなんてとるの?)
9.9 #69: Creating data races with append
一般的に、スライスが一杯になったかどうかによって異なる実装をすべきではない。並行アプリケーションで共有スライスにappendを使用すると、データレースにつながる可能性があることを考慮する必要があります。したがって、これは避けるべきである。
9.10 #70: Using mutexes inaccurately with slices and maps
NG
balances := c.balances は同じポインタ(backed by the same array)を見ているから、data receになっている
OK
9.11 #71: Misusing sync.WaitGroup
NG
wg.Addの実行場所がgo routingの中で実行されている。このせいでwg.Addが実行される前にwg.Wait()がカウント0になって通るケースが起こる。
9.12 #72: Forgetting about sync.Cond
9.13 #73: Not using errgroup
9.14 #74: Copying a sync type
経験則として、複数のゴルーチンが共通のsync要素にアクセスする必要がある場合は、すべて同じインスタンスに依存するようにしなければなりません。このルールはsyncパッケージで定義されているすべての型に適用されます。この問題を解決する方法として、ポインターを使う方法があります。sync要素へのポインタか、sync要素を含む構造体へのポインタのどちらかを持つことができる。
以下のような場合、意図せずsyncフィールドをコピーしてしまうという問題に直面する可能性がある:
値のレシーバを持つメソッドを呼び出す(これまで見てきたように)。
同期引数を持つ関数の呼び出し
同期フィールドを含む引数を持つ関数の呼び出し
sync要素
sync.Cond
sync.Map
sync.Mutex
sync.RWMutex
sync.Once
sync.Pool
sync.WaitGroup
Summary
⭐
10 The standard library
Providing a correct time duration
Understanding potential memory leaks while using time.After
Avoiding common mistakes in JSON handling and SQL
Closing transient resources
Remembering the return statement in HTTP handlers
Why production-grade applications shouldn’t use default HTTP clients and servers
10.1 #75: Providing a wrong time duration
は1秒ではない
1000 = time.Microsecond = 1000 * time.Nanosecond
10.2 #76: time.After and memory leaks
一般的に、time.Afterの使用には注意が必要である。作成されたリソースが解放されるのは、タイマーの期限が切れたときだけであることを忘れないでください。time.Afterの呼び出しが繰り返される場合(たとえば、ループ、Kafkaコンシューマー関数、HTTPハンドラーなど)、メモリ消費がピークに達する可能性があります。このような場合は、time.NewTimerを使用することをお勧めします。
10.3 #77: Common JSON-handling mistakes
10.3.1 Unexpected behavior due to type embedding
embbed field使うとメソッドが昇格して思わぬ動きをする例を紹介。この例ではMarshalJSONがtime.Timeに実装されていて、それが実行されて期待したjsonフォーマットで出力されない例を提示。
10.3.2 JSON and the monotonic clock
10.3.3 Map of any
anyでunmarshalすると
小数を含むかどうかにかかわらず、すべての数値は float64 型に変換される。
10.4 #78: Common SQL mistakes
10.4.1 Forgetting that sql.Open doesn’t necessarily establish connections to a database
直感に反するかもしれませんが、sql.Openは必ずしも接続を確立するわけではなく、最初の接続は簡単に開くことができることを覚えておいてください。構成をテストし、データベースに到達可能であることを確認したい場合、sql.Openの後にPingまたはPingContextメソッドを呼び出すべきです。
10.4.2 Forgetting about connections pooling
A connection in the pool can have two states:
- Already used (for example, by another goroutine that triggers a query)
- Idle (already created but not in use for the time being)
SetMaxOpenConns
SetMaxIdleConns
SetConnMaxIdleTime
SetConnMaxLifetime
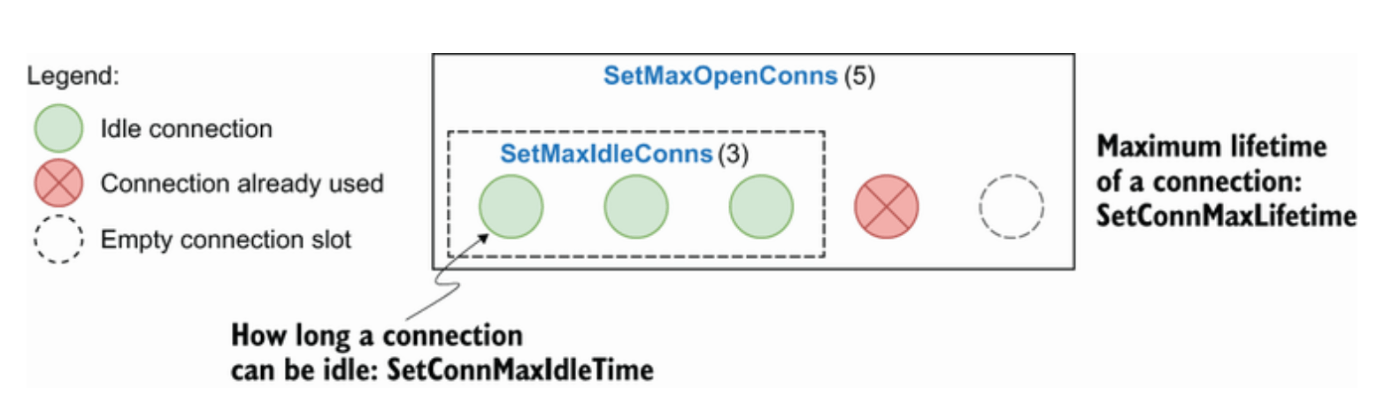
10.4.3 Not using prepared statements
10.4.4 Mishandling null values
10.4.5 Not handling row iteration errors
rows.Errも忘れないでね
10.5 #79: Not closing transient resources
10.5.1 HTTP body
リークを避けるためにリソースをクローズするのは、HTTPボディの管理だけに関係するわけではない。一般的に、io.Closerインタフェースを実装するすべての構造体は、ある時点でクローズされるべきです。このインターフェースにはCloseメソッドが1つあります
10.5.2 sql.Rows
rows.Close()はしましょうという紹介
10.5.3 os.File
がクローズされなければならないかは、前もって明確になっているとは限らない。この情報は、APIのドキュメントを注意深く読んだり、経験を積んだりすることでしか得られない。しかし、構造体がio.Closerインターフェースを実装している場合、最終的にはCloseメソッドを呼び出さなければならないことは覚えておく必要がある
10.6 #80: Forgetting the return statement after replying to an HTTP request
http.handlerでエラー起きたらreturnしようね、という紹介
10.7 #81: Using the default HTTP client and server
10.7.1 HTTP client
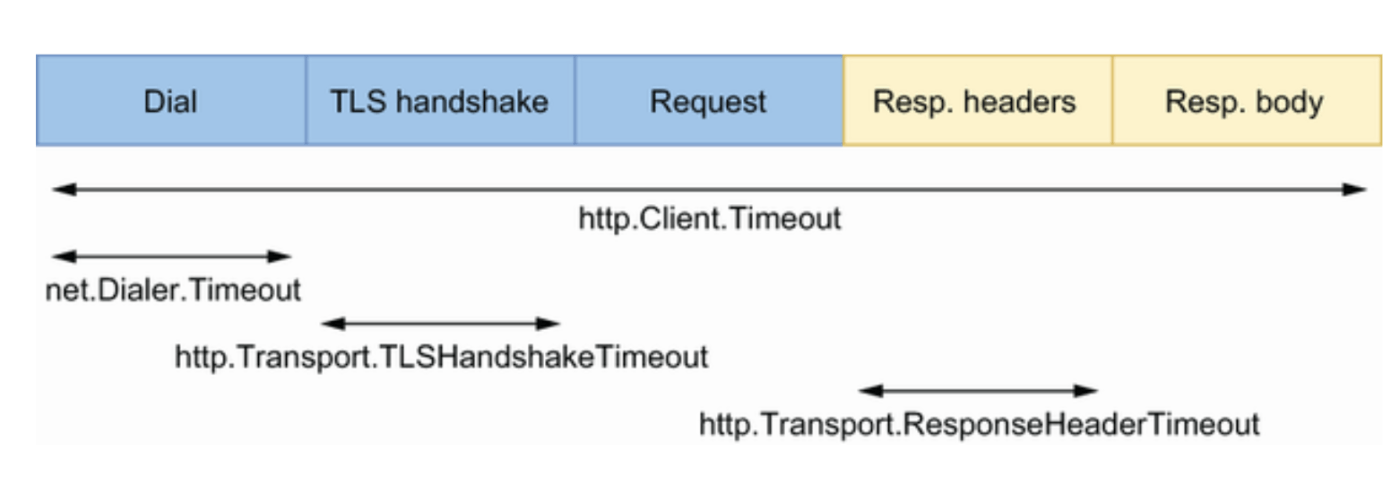
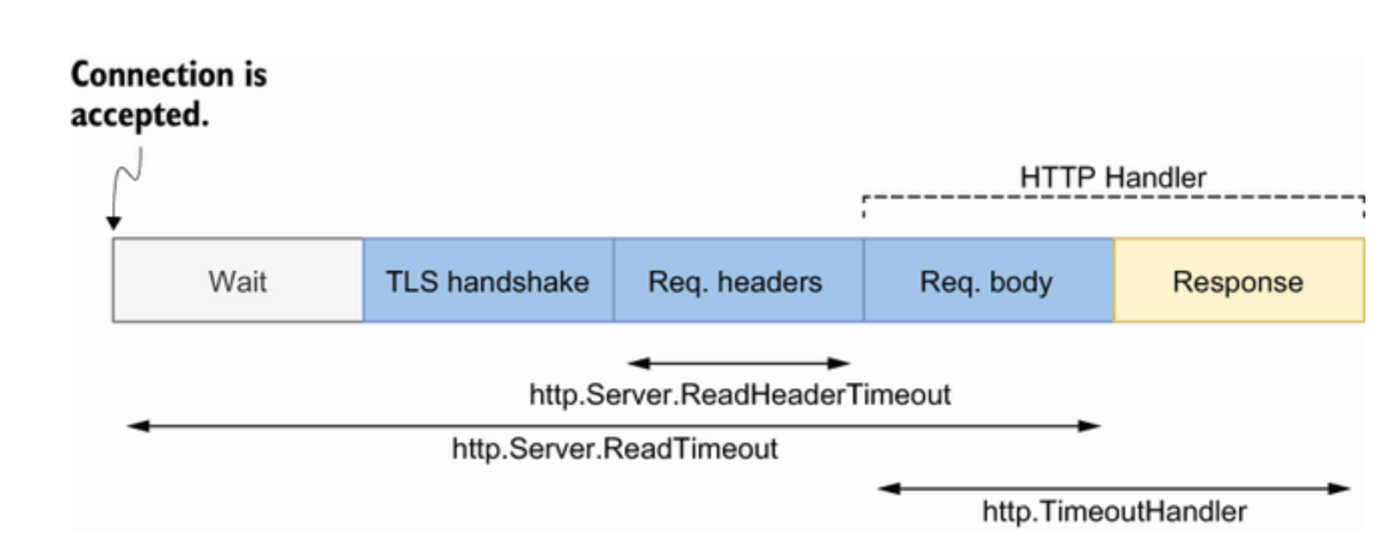
10.7.2 HTTP server
Summary
⭐
11 Testing
11.1 #82: Not categorizing tests
11.1.1 Build tags
//go:build integration
11.1.2 Environment variables
func TestInsert(t *testing.T) {
if os.Getenv("INTEGRATION") != "true" {
t.Skip("skipping integration test")
}
11.1.3 Short mode
func TestLongRunning(t *testing.T) {
if testing.Short() {
t.Skip("skipping long-running test")
}
11.2 #83: Not enabling the -race flag
テストやCIで-raceをつけてテストを実行することをおすすめするよ、という紹介
11.3 #84: Not using test execution modes
11.3.1 The parallel flag
t.Parallel()
11.3.2 The -shuffle flag
go test -shuffle=on -v .
seed
go test -shuffle=1636399552801504000 -v .
11.4 #85: Not using table-driven tests
11.5 #86: Sleeping in unit tests
falkyテストの対処方法で、リトライやチャネルを使った同期の方法を紹介している。 https://github.com/teivah/100-go-mistakes/blob/master/src/11-testing/86-sleeping/main_test.go
11.6 #87: Not dealing with the time API efficiently
time.now()を使っている箇所をどうテストで対応するかの紹介。
モックを構造体にinjectした方法や、モックを直接渡して動作できるようなインターフェースにするやり方を紹介
11.7 #88: Not using testing utility packages
11.7.1 The httptest package
11.7.2 The iotest package
11.8 #89: Writing inaccurate benchmarks
11.8.1 Not resetting or pausing the timer
11.8.2 Making wrong assumptions about micro-benchmarks
$ go test -bench=. -count=10 | tee stats.txt
$ benchstat stats.txt
11.8.3 Not being careful about compiler optimizations
コンパイラの最適化がベンチマーク結果を欺くのを避けるために、このパターンを覚えておこう。テスト対象の関数の結果をローカル変数に代入し、最新の結果をグローバル変数に代入する。このベストプラクティスは、間違った仮定をすることも防いでくれる。
compiler optimization example。最適化により(インライン化という表現があった)関数が呼ばれなくなり、正確なベンチマークが計測されないとのこと
コンパイラの最適化を欺く例。計測が可能になる
11.8.4 Being fooled by the observer effect
11.9 #90: Not exploring all the Go testing features
11.9.1 Code coverage
カバレッジ情報を生成
$ go test -coverprofile=coverage.out ./...
カバレッジを開く
$ go tool cover -html=coverage.out
coverpkg
go test -coverpkg=./... -coverprofile=coverage.out ./...
11.9.2 Testing from a different package
11.9.3 Utility functions
テストのために使う構造体の生成をするためにutility関数を作成することはあると思うが、エラーかどうかチェックする場合、t *testing.Tを渡してそのutility関数内でチェックしてしまおう。そうすればテストコードの見通しがよくなるよ。
11.9.4 Setup and teardown
Summary
⭐