dbt の description を COMETA に反映させるチャレンジ
COMETA に dbt の yml ファイルで定義した desciption の値を持ってくる。
COMETA の CSV インポート機能で以下のテンプレートが取得できる。データストアは Snowflake を使う。
- テーブル基本メタデータ (snowflake-database-metadata-import)
- スキーマ基本メタデータ (snowflake-schema-metadata-import)
- テーブル基本メタデータ (snowflake-table-metadata-import)
- カラム基本メタデータ (snowflake-column-metadata-import)
- カラム参照 (snowflake-relationship-import)
catalog.json や manifest.json をゴニョゴニョするのはつらそうだったので
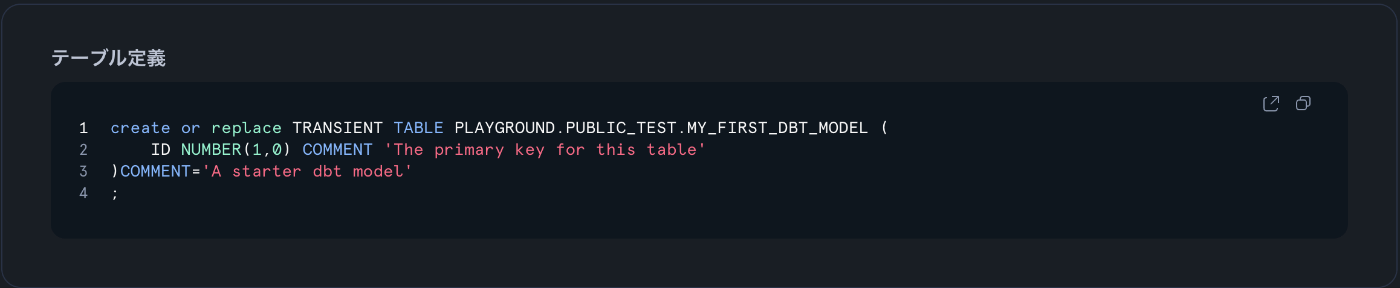
dbt の persist_docs を true にして Snowflake の COMMENT に反映させてそれを取得してみる。
models:
<resource-path>:
+persist_docs:
relation: true
columns: true
テーブルレベル
select
table_catalog as database,
table_schema as schema,
table_name as name,
comment as description
from playground.information_schema.tables
where table_schema = 'PUBLIC_TEST';
| DATABASE | SCHEMA | NAME | DESCRIPTION |
|---|---|---|---|
| PLAYGROUND | PUBLIC_TEST | MY_SECOND_DBT_MODEL | A starter dbt model |
| PLAYGROUND | PUBLIC_TEST | MY_FIRST_DBT_MODEL | A starter dbt model |
テーブル基本メタデータ (snowflake-table-metadata-import)
- database_name
- schema_name
- table_name
- logical_name
- description
カラム名まで揃えた SQL
select
table_catalog as "database_name",
table_schema as "schema_name",
table_name as "table_name",
comment as "logical_name",
comment as "description"
from playground.information_schema.tables
where table_schema = 'PUBLIC_TEST';
いったん logical_name と description は同じものを。
| database_name | schema_name | table_name | logical_name | description |
|---|---|---|---|---|
| PLAYGROUND | PUBLIC_TEST | MY_SECOND_DBT_MODEL | A starter dbt model | A starter dbt model |
| PLAYGROUND | PUBLIC_TEST | MY_FIRST_DBT_MODEL | A starter dbt model | A starter dbt model |
Snowsight から CSV でダウンロードして、COMETA > 管理・連携 > メタデータ管理 > メタデータインポートでデータストアを適切なものに、インポート対象は「テーブル基本メタデータ」に指定して「CSVをアップロード」でダウンロードした CSV をアップロードする。
無事完了。

今回はテストのため不思議な where 句を添えているけれど、本来は COMETA と連携している Snowflake のロール(COMETA_ROLE みたいなの)で実行すれば、where がいらない。
後できれいな SQL を作る。
Python のほうが書きやすい。
dbt sources の description を persist_docs で書き込めないので結局は json -> csv をやらないと完璧ではないかな。
dbt で管理しているのはテーブルレベルの description と カラムレベルの description なので、
その他は頑張れという認識。
- テーブル基本メタデータ (snowflake-database-metadata-import)
- スキーマ基本メタデータ (snowflake-schema-metadata-import)
- カラム参照 (snowflake-relationship-import)
カラム参照は頑張ればできるのかな?
Python で書くとこんな感じ(テーブルレベル)
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
import pandas as pd
from functools import reduce
def main(session: snowpark.Session):
data = []
databases = ["SOURCE", "STAGING", "INTERMEDIATE", "MARTS"] # 自分でデータベースを選ぶ
for database in databases:
table = f"{database}.INFORMATION_SCHEMA.TABLES"
table_df = session.table(table)[["TABLE_CATALOG", "TABLE_SCHEMA", "TABLE_NAME", "COMMENT"]].filter(col("TABLE_SCHEMA") != "INFORMATION_SCHEMA")
df = table_df.with_column('"description"', table_df["COMMENT"])
data.append(df)
return reduce(snowpark.DataFrame.union, data).rename({
col("TABLE_CATALOG"): '"database_name"',
col("TABLE_SCHEMA"): '"schema_name"',
col("TABLE_NAME"): '"table_name"',
col("COMMENT"): '"logical_name"',
})
Markdown も試す。
{% docs test %}
# Iamque praecordiaque paratur hac haec cladibus
## Finierat timentia Phobetora visent pavens non feroxque
_Lorem_ markdownum lecta: iuvencos emeritis ima. Supremis quam quas _veteres_
annos tenet erat, inde distinxit modo limine **flammis**.
- hello
- world
### heading3
1. Madefactam ausus arsit tanges
2. Vulnere Tellus relinquam postquam exiguo
3. Incumbit ire faciem pariter suumque
4. Tuorum iam totis in non sed sceleri
5. Et est ipsi relinquar fortuna ignem lactentem
6. Peregrinum interea ille fecunda nunc serpens faciam
{% enddocs %}
version: 2
models:
- name: my_first_dbt_model
description: '{{ doc("test") }}'
columns:
- name: id
description: "The primary key for this table"

COMETA の論理名はテキストエリア

説明(description) は Markdown 対応してくれている。
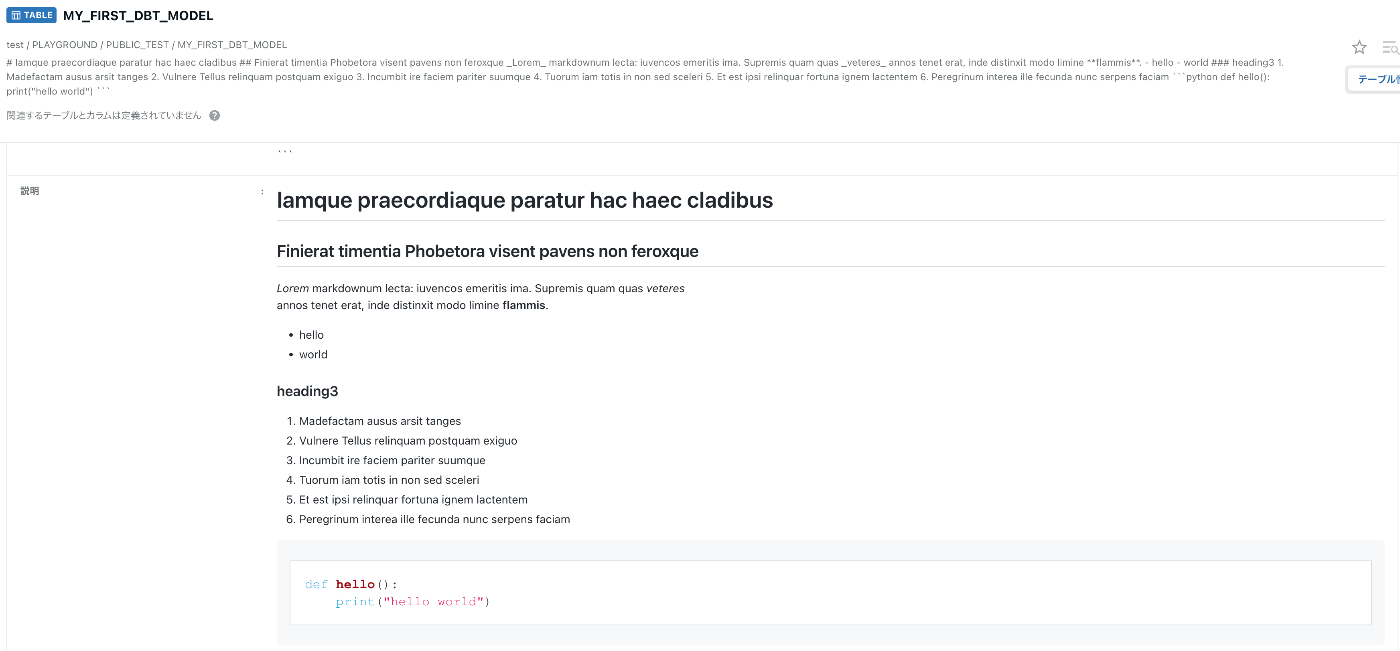
このように設定するのもありかもしれない。
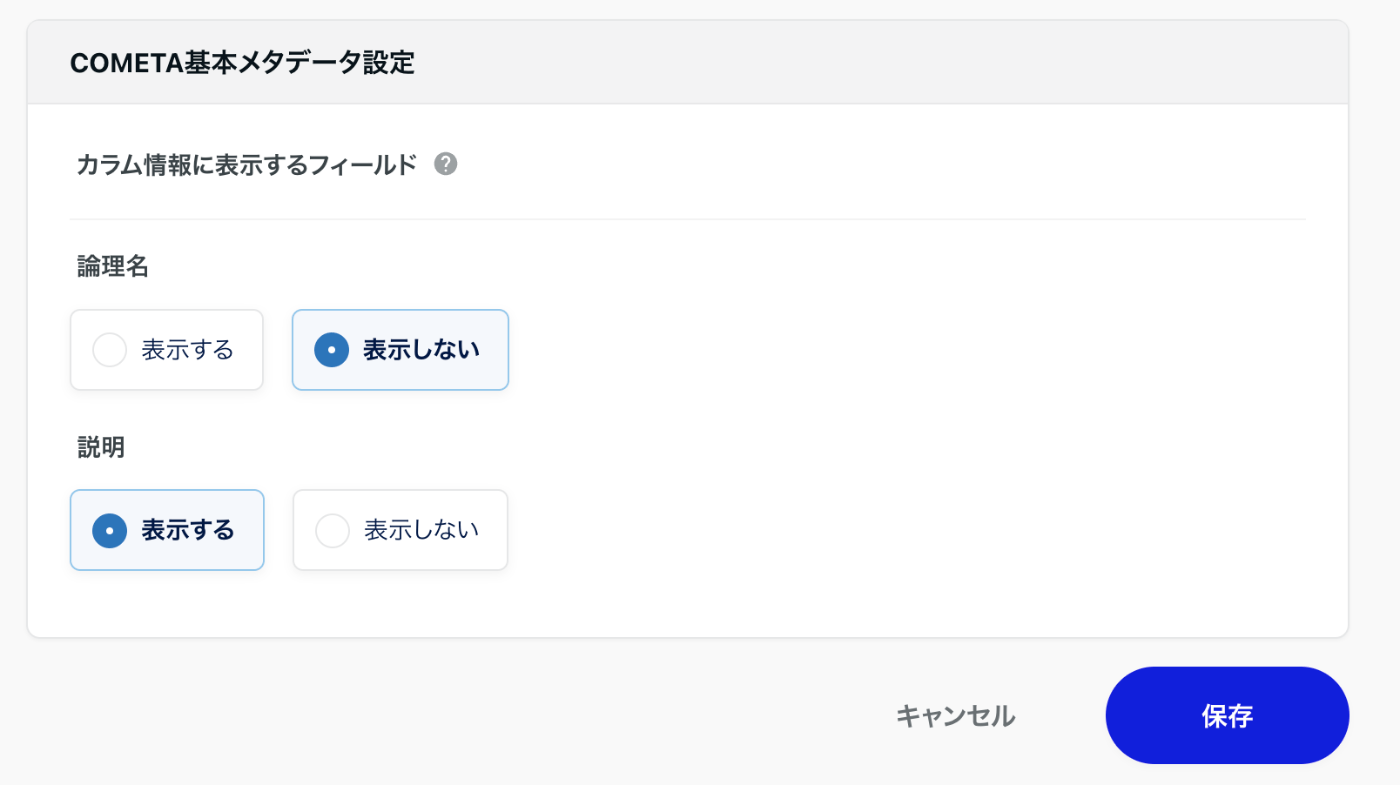
↑あくまでカラムレベルの設定で今までやってきたテーブルレベルでは設定できない。
あと null はあっても問題ない。