PyMuPDFライブラリを用いてPDFファイルにヘッダーを表記する
概要
筆者の本業は弁護士です。
裁判所に証拠を提出する際、「甲1、2、3、…」「乙1、2、3、…」といった形で証拠番号を表記しなければならないのですが、事務局が紙媒体にスタンプ+手書きをしたり、Acrobatでヘッダーを追加したりといった方法で対応してきました。
例)

今般、申立時から証拠の数が200に届きそうな案件があり、手動でやるのがめんどくさいので、pythonとPyMuPDFライブラリを用いて、複数ファイルに対し自動で番号を表記してくれるetc.のツールセットを作りました。
機能と使い方
概略
- PDFファイルを、”【ヘッダー表記したい文字列】【デリミタ】【その他の文字列】.pdf"という名前で特定のフォルダに保存しておきます。デリミタはデフォルトがスペースですが、他の文字も指定できます。
- 元となるPDFファイルが格納された入力元・出力先フォルダを指定すると、入力元フォルダのPDFファイルにヘッダーを表記して、出力先フォルダに出力します。保存先フォルダにある元ファイルには変更を加えません。
- PDFのフッターにページ番号を描画することも可能です。
オプション
個々の関数により、以下の機能を実装しています。
| 関数名 | 機能の概略 |
|---|---|
| header_to_pdf() | PDFファイルにヘッダーのみを付与します。①ヘッダー分、元のPDFファイルを縮小して描画すること、②縮小せずに描画することの双方が可能です。元のPDFファイルの描画範囲を特定するために、元ページを矩形で囲むこと、ヘッダーとの境界線を描画することも可能です。 |
| header_to_pdf_in_folder() | 入力元フォルダの全てのPDFファイルに対しheader_to_pdf()を実行し、出力先フォルダに保存します。 |
| header_and_pagenum_to_pdf() | PDFファイルにヘッダー及びフッターを付与します。フッターにはページ番号を描画することが可能です。その他の機能はheader_to_pdf()と概ね同様です。 |
| header_and_pagenum_to_pdf_in_folder() | 入力元フォルダの全てのPDFファイルに対しheader_and_pagenum_to_pdf()を実行し、出力先フォルダに保存します。 |
| header_and_frame_to_pdf() | PDFファイルにヘッダーを付与し、元のPDFを縮小して描画し、元のPDFファイルのページを矩形(フレーム)で囲みます。 |
| header_and_frame_to_pdf_in_folder() | 入力元フォルダの全てのPDFファイルに対しheader_and_frame_to_pdf()を実行し、出力先フォルダに保存します。 |
| concat_pdf() | 入力元フォルダにある全てのPDFファイルを結合し、出力先として指定されたPDFファイルに保存します。header_and_frame_to_pdf_in_folder()などの関数と組み合わせれば、複数のPDFファイルを結合して出力先のフォルダに個別ファイルとして保存した後、出力先のフォルダにある全ての加工後PDFのファイルを結合し、一括して印刷ができるようになります。※再帰検索せず、入力元フォルダ直下にあるPDFファイルのみを結合します。 |
以上の他にも関数がありますが、おって記事を改めて解説します。
インストール
Pythonのインストール、PyMuPDFのインストールは、それぞれのドキュメントや各書籍を参考にしてください。
concat_pdf()の処理において、ファイル名で適切に並び替えるために、natsortライブラリも用いています。こちらのインストールも必要です。
ソースコード
コーディングの例
実行用の適当な.pyファイル(例:run_toolkit.py)を作成し、同じフォルダにpdf_toolkit.pyを保存しておきます。
元ファイル
※元ファイルは、Wordのテンプレートから適当に作成したものです。
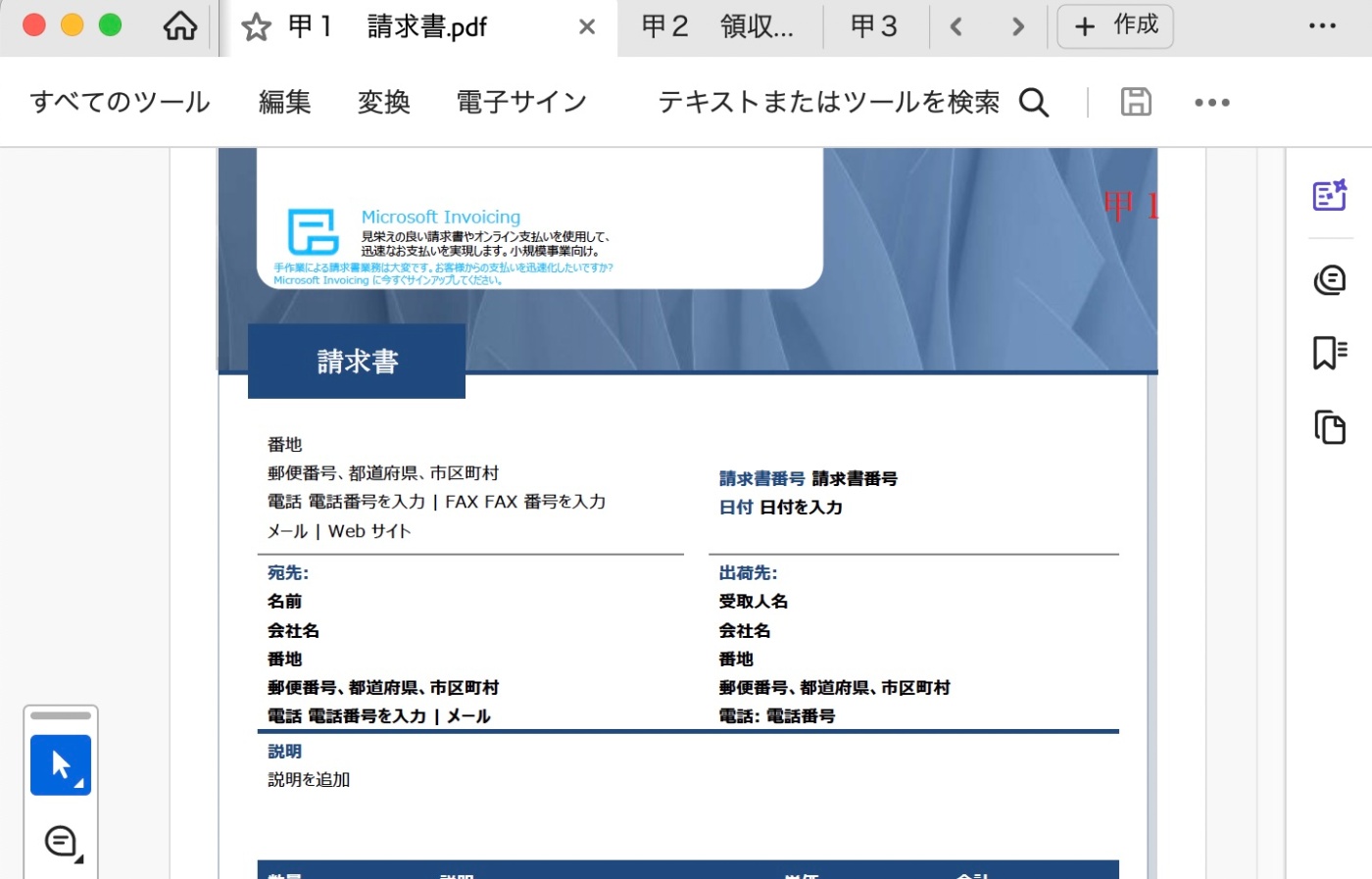
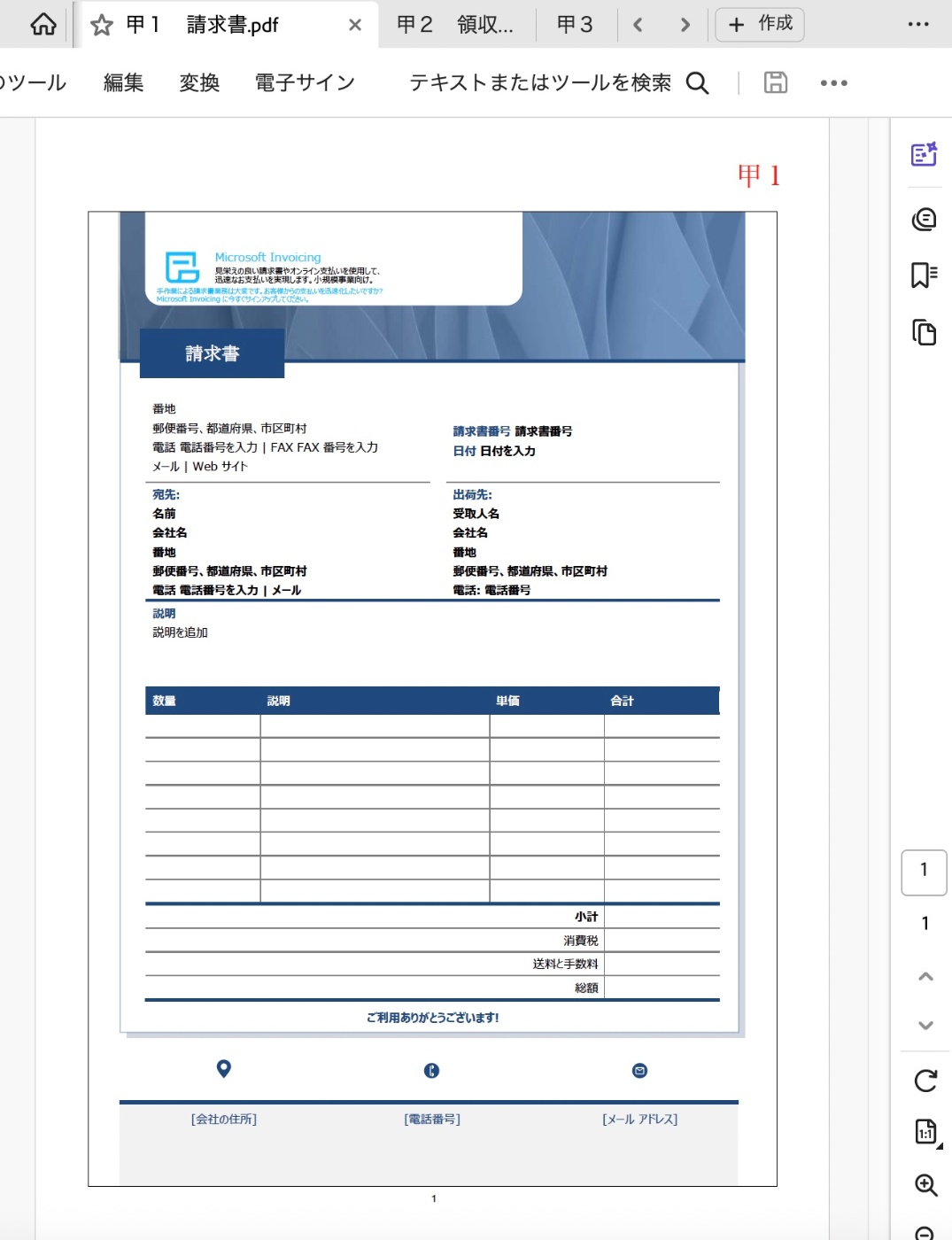
甲1

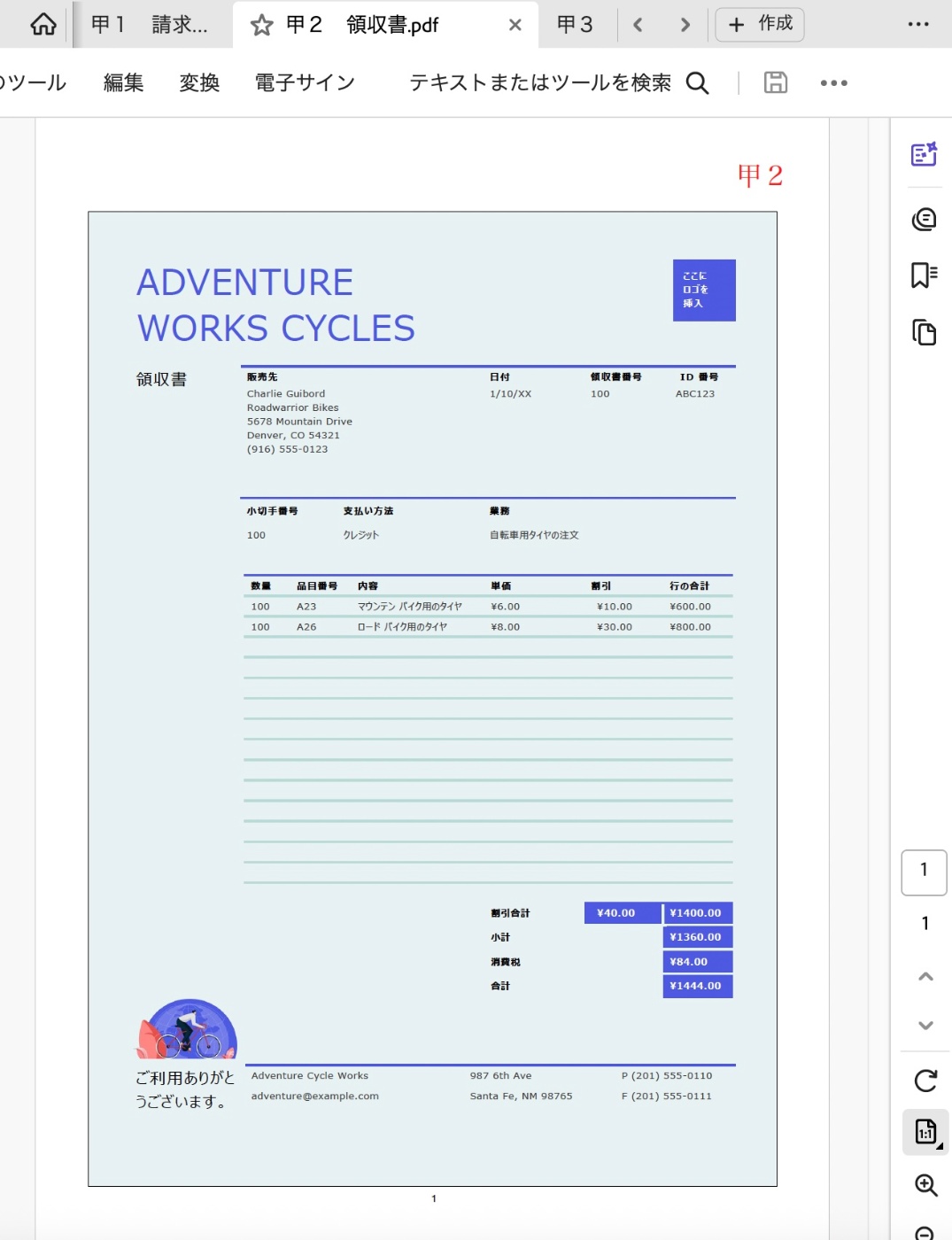
甲2

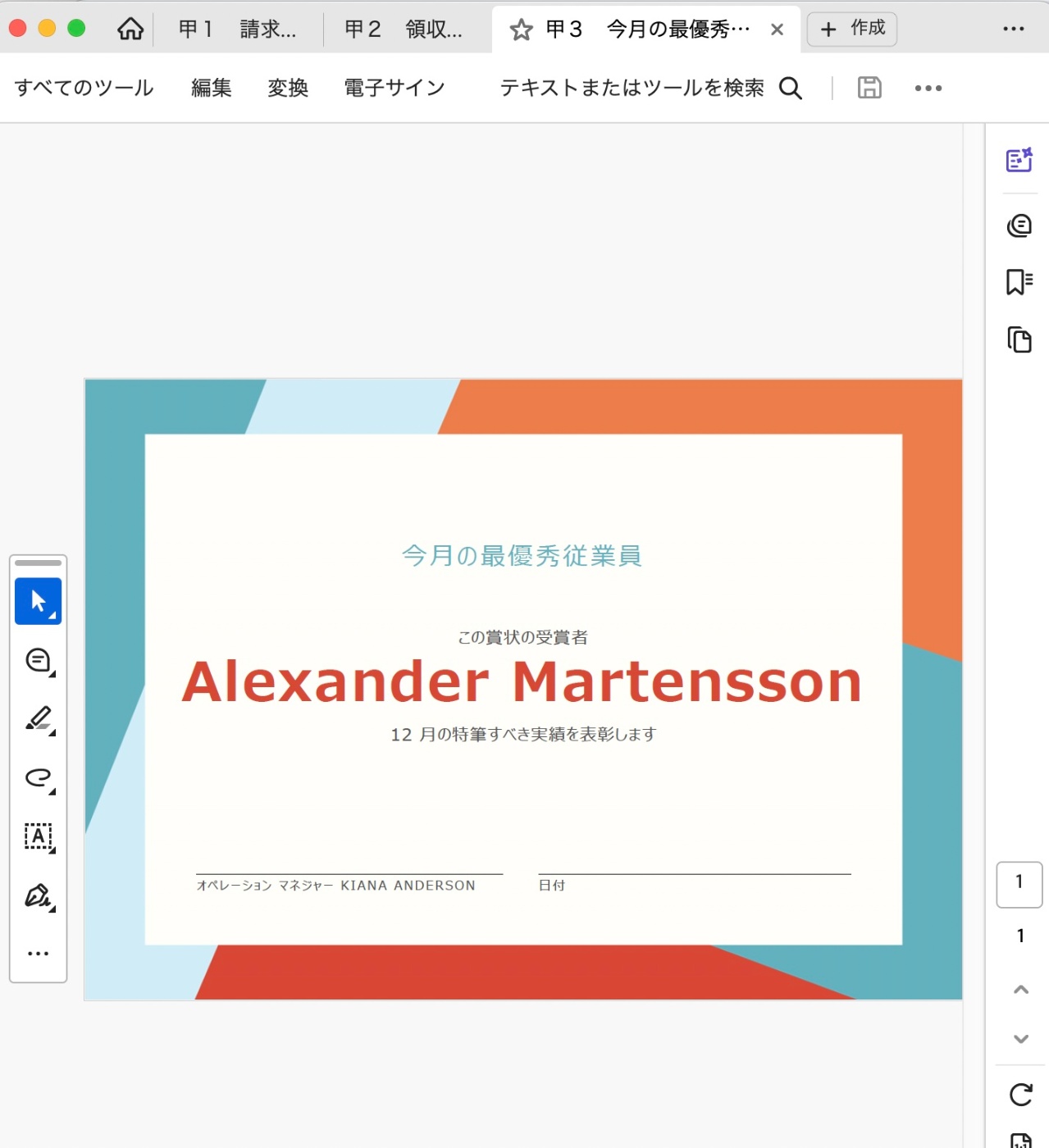
甲3
元のPDFファイルを縮小せずに、ヘッダーのみ表記する例
import sys
import pdf_toolkit
pdf_toolkit.header_to_pdf_in_folder(
input_folder_path=sys.argv[1],
output_folder_path=sys.argv[2],
resize_original=False
)
python run_toolkit.py ./元ファイルフォルダ ./出力先フォルダ
実行結果
甲1の例
元のPDFファイルを縮小し、ヘッダー及びページ番号並びに元ページを囲む矩形を表記する例
import sys
import pdf_toolkit
pdf_toolkit.header_and_pagenum_to_pdf_in_folder(
input_folder_path=sys.argv[1],
output_folder_path=sys.argv[2],
resize_original=True,
draw_content_border=True
)
python run_toolkit.py ./元ファイルフォルダ ./出力先フォルダ
実行結果
甲1の例
甲2の例
甲3の例
ペーイレイアウトが縦でも横でも適切に縮小されて表示されます。

元のPDFファイルを縮小し、ヘッダー及びフレームを表記するとともに、結合されたPDFファイルを出力する例
import sys
import pdf_toolkit
pdf_toolkit.header_and_frame_to_pdf_in_folder(
input_folder_path=sys.argv[1],
output_folder_path=sys.argv[2]
)
pdf_toolkit.concat_pdf(
input_folder_path=sys.argv[2],
output_pdf_path=sys.argv[3]
)
python run_toolkit.py ./元ファイルフォルダ ./出力先フォルダ 甲1~3.pdf
結合後のファイルの例

ロジックのコア
PyMuPDFライブラリのPage.show_pdf_page()メソッドは、既存のPDFファイルの「n-up」バージョンを作成し、複数の入力ページを1つの出力ページに結合します。このメソッドを用いて、元PDFファイルのページと同じサイズのページを作成した後、ヘッダーand/orフッター領域を除外した領域に、元ページの内容を描画することで、元PDFファイルのページ縮小を行っています。ページ縮小をしない場合は、元ページと同一サイズのページに描画します。
source_doc = pymupdf.open(input_pdf_path)
output_doc = pymupdf.open()
for page_idx in range(source_doc.page_count):
original_page = source_doc.load_page(page_idx)
if(original_page.rotation != 0):
original_page.remove_rotation()
# 出力ドキュメントに新しいページを作成 (元のページと同じサイズ)
new_page = output_doc.new_page(width=original_page.
rect.width,
height=original_page.rect.height
)
# ヘッダー領域を定義
header_actual_rect = pymupdf.Rect(0, 0,
new_page.rect.width, header_height
)
# 元のコンテンツが表示される領域を定義 (ヘッダー領域の下)
if(resize_original): #オリジナルを縮小
content_rect = pymupdf.Rect(0, header_height,
new_page.rect.width, new_page.rect.height)
else: #オリジナルを縮小しない
content_rect = pymupdf.Rect(0, 0, new_page.
rect.width, new_page.rect.height)
# 元のページコンテンツを新しいページのcontent_rectに表示 (スケーリング)
new_page.show_pdf_page(content_rect, source_doc,
page_idx, keep_proportion=True, overlay=True)
指定可能な引数
以下がheader_and_pagenum_to_pdf_in_folder()関数の引数です。
他の関数でも比較的柔軟に設定できるようになっています。ソースコードをご参照の上で、適宜ご利用ください。
def header_and_pagenum_to_pdf_in_folder(
input_folder_path,
output_folder_path,
overwrite=True,
resize_original=True,
# ヘッダー描画用引数
header_font_name="japan",
header_font_size=20,
header_text_color=(1, 0, 0),
header_height=70,
header_padding=10,
delimiter=Delimiters.Space,
stamp_only_firstpage=False,
draw_header_line=False,
header_line_color=(0, 0, 0),
header_line_width=0.5,
# フッター描画用引数
footer_font_name="helv",
footer_font_size=8,
footer_text_color=(0, 0, 0),
footer_height=40,
footer_padding=3,
write_pagenum=True,
show_total_pages=False,
draw_footer_line=False,
footer_line_color=(0, 0, 0),
footer_line_width=0.5,
# 矩形描画用引数
draw_content_border=True,
content_border_width=0.5,
content_border_color=(0,0,0)
):
Disclaimer
自己利用のためのツールですので、自己責任で利用されてください。
不具合等は適宜お知らせいただけると助かります。
ソースコード及び本記事はちょこちょこアップデートすると思います。
本業が忙しいのでのんびり対応します(´・ω・`)
Discussion