ChatGPTと対話してGPSデータシミュレーションを探索した話
概要
本稿の概要を以下に書きます。
- ChatGPTにより、ノーコードで歩行GPSシミュレーションデータを作成
- スキーマとサンプリング周期等の要件をプロンプトに指定することにより、テーブルデータを生成
- 出力データを地図上にプロット
- Pythonを使う歩行GPSシミュレーションデータの作成方法をChatGPTと探索
- ノーコードでは限界がありそうだと分かった
- PythonによるシミュレーションデータをChatGPTと対話しながら作成
- 出力データを地図上にプロット
はじめに
本稿はOptimind Advent Calendar 2023の11日目の記事です。
ちょうど一年ほど前に公開され、ChatGPTはもはや開発と不可分と言えるほど深く根付いたように思われます。自分においても、コーディングだけではなく、要件定義の観点、設計、規約、ドキュメンテーション等、ChatGPTを利用しない日はほとんど無いです。 データ作成においても、簡易にアプリケーションの確認を行うような単純なダミーデータの作成[1]にはChatGPTが使用できる場合が多いと思われ、実際に全件データの作成やストーリーのあるデータの作成など、多くの方々が実施されている様子です(参考1、参考2)。気になったのが、ある程度シミュレーション等複雑な要素を持つダミーデータの作成にどの程度対応可能あるいはリアルなデータを出力可能であるかということで、今回実験的に歩行GPSシミュレーションデータをChatGPTを使って作成してみることにしました。
なお、ChatGPTは、有償のGPT-4を使用しています。
1. ChatGPTにより、ノーコードで歩行GPSシミュレーションデータを作成
サクッと歩行GPSシミュレーションデータを作ってみます。数回プロンプトを微調整して初期データを得ました。
なんか途中でエラーを出してますが、復帰して結果を出力してくれています(偉い)。この時に得たCSVファイルはこれです。
地図上にタイムスタンプ、速度を含めプロットするように依頼して得たHTMLファイルがこれです(キャプチャを以下に添付)。
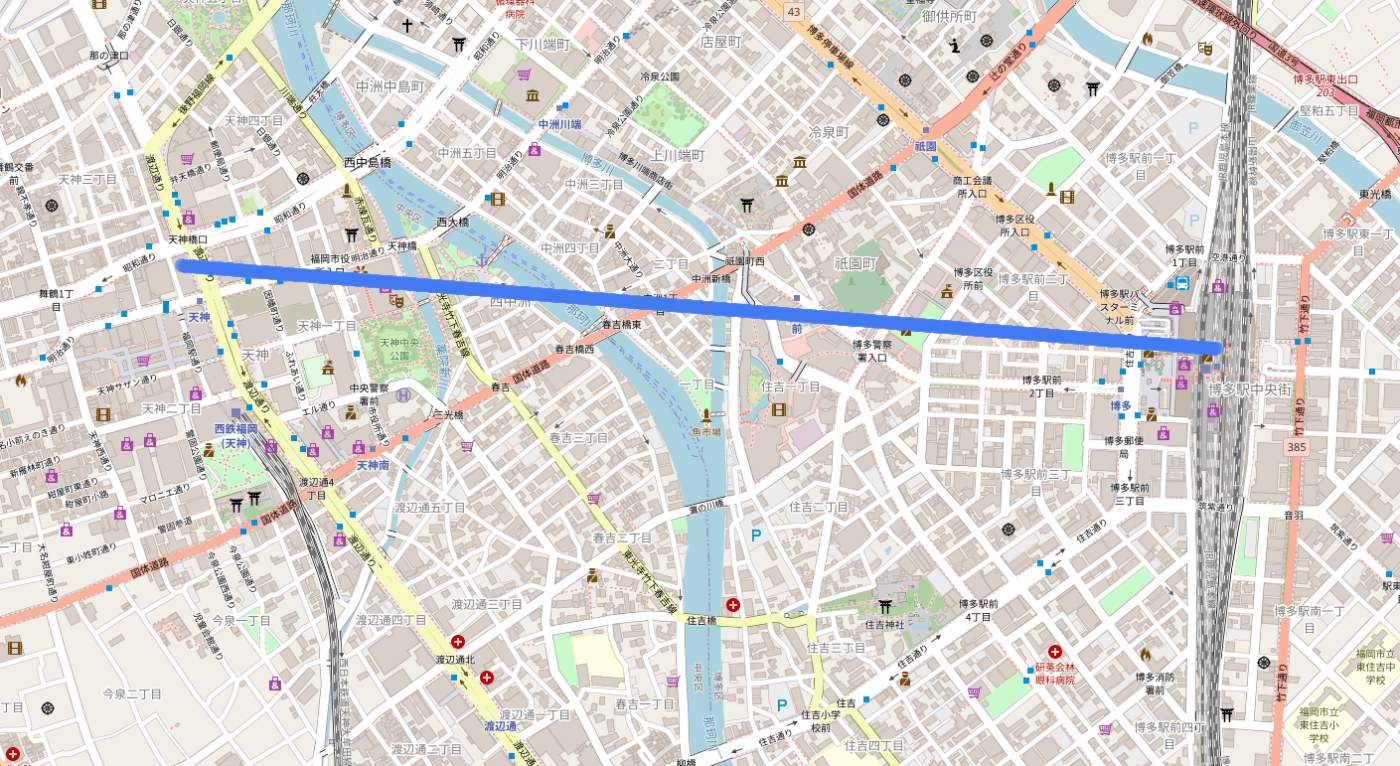
建物や川を完全に無視して直進していますね(男塾名物?)。ただ、これでも一定単純なテストに使えるようなデータが作成できたのではないでしょうか?
折角このHTMLを生成するためにPythonにコードを書いてもらい、地図上のEDAに一部使えそうなので、添付します(ただし自分では実行していない。動作未確認)。
import folium
from folium.plugins import MarkerCluster
import base64
import io
# 地図を初期化(博多駅を中心に設定)
map_center = [start_latitude, start_longitude]
map = folium.Map(location=map_center, zoom_start=14)
# マーカークラスターを作成
marker_cluster = MarkerCluster().add_to(map)
# 各GPSデータポイントにマーカーを設置
for index, row in gps_data.iterrows():
# マーカーに表示する情報を作成
popup_info = folium.Popup(
f"Timestamp: {row['Timestamp']}<br>Speed: {row['Speed(km/h)']} km/h",
parse_html=True
)
folium.Marker(
location=[row['Latitude'], row['Longitude']],
popup=popup_info,
).add_to(marker_cluster)
# 地図を一時ファイルとして保存
map_file_path = '/mnt/data/gps_data_map.html'
map.save(map_file_path)
map_file_path
2. Pythonを使う歩行GPSシミュレーションデータの作成方法をChatGPTと探索
よりリアルっぽいデータは作れないのか気になったので、対話を続けます。

ChatGPTが実行するPython環境からpip installできない等制約でもあるのかなと思いましたが、一旦自分が全くコードを書かずにデータを作るということはここまでで打ち止めの様子です。
ただ、Python実行環境を肩代わりすればなんかいけそうな雰囲気ではあったので、コードの書き方を聞いてみました。
ただ、この時のコードは期待通りに動きませんでした(一応ここに置いておきます)。
ここからしばらく、自分でコードを改変したり、エラー内容をChatGPTに問いかけたりすったもんだして、以下のコードを得ました。
import osmnx as ox
import networkx as nx
import pandas as pd
from datetime import datetime, timedelta
import numpy as np
from math import radians, cos, sin, asin, sqrt
def haversine(lon1, lat1, lon2, lat2):
# ラジアンに変換
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
# ハーバーサイン公式
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
c = 2 * asin(sqrt(a))
r = 6371 # 地球の半径(キロメートル)
return c * r
def interpolate_points(p1, p2, num_points):
""" p1とp2の間にnum_pointsの数だけポイントを補間する """
return zip(np.linspace(p1[0], p2[0], num_points),
np.linspace(p1[1], p2[1], num_points))
def generate_gps_data(start_point, end_point, start_time, speed_km_per_h, sampling_rate):
# OSMnxで道路ネットワークを取得
G = ox.graph_from_point(start_point, dist=3000, network_type='walk')
# 最も近いノードを見つける
orig_node = ox.distance.nearest_nodes(G, start_point[1], start_point[0])
dest_node = ox.distance.nearest_nodes(G, end_point[1], end_point[0])
# 最短ルートを見つける
route = nx.shortest_path(G, orig_node, dest_node, weight='length')
# ルート上の各ノードの座標と距離を取得
nodes = [(G.nodes[node]['x'], G.nodes[node]['y']) for node in route]
distances = [haversine(lon1, lat1, lon2, lat2) for (lat1, lon1), (lat2, lon2) in zip(nodes[:-1], nodes[1:])]
# 総距離と移動時間の計算
total_distance = sum(distances)
total_time = total_distance / (speed_km_per_h / 60) # 分単位で計算
# サンプル数と各セグメントに必要なサンプル数の計算
total_samples = int(total_time * 60 / sampling_rate)
segment_samples = [max(1, round(d / total_distance * total_samples)) for d in distances]
# 各セグメント間でポイントを補間
sampled_points = []
for (p1, p2), num in zip(zip(nodes[:-1], nodes[1:]), segment_samples):
# 各セグメントのポイントを補間
segment_points = list(interpolate_points(p1, p2, num))
sampled_points.extend(segment_points[:-1]) # 各セグメントの最後のポイントを除外
# 最後のポイントを追加
sampled_points.append(nodes[-1])
# サンプリングされたポイントからデータフレームを作成
sampled_gps_data = pd.DataFrame(sampled_points, columns=['longitude', 'latitude'])
# 総サンプル数に合わせるために、不足分のポイントを調整
total_samples = min(len(sampled_gps_data), total_samples)
sampled_gps_data = sampled_gps_data.iloc[:total_samples]
# タイムスタンプと速度をデータフレームに追加
timestamps = [start_time + timedelta(seconds=sampling_rate * i) for i in range(total_samples)]
sampled_gps_data['timestamp'] = timestamps
sampled_gps_data['speed_km/h'] = speed_km_per_h
return sampled_gps_data
# パラメータ設定
start_point = (33.5904, 130.4206) # 博多駅の座標
end_point = (33.5919, 130.3982) # 天神駅の座標
start_time = datetime.now()
speed_km_per_h = 4.5 # 歩行速度
sampling_rate = 5 # サンプリングレート(秒)
gps_data = generate_gps_data(start_point, end_point, start_time, speed_km_per_h, sampling_rate)
gps_data.to_csv('./outputs/gps_data.csv', index=False)
これが出力するCSVファイルをプロットしたものがこれです(キャプチャを下に貼ります)。
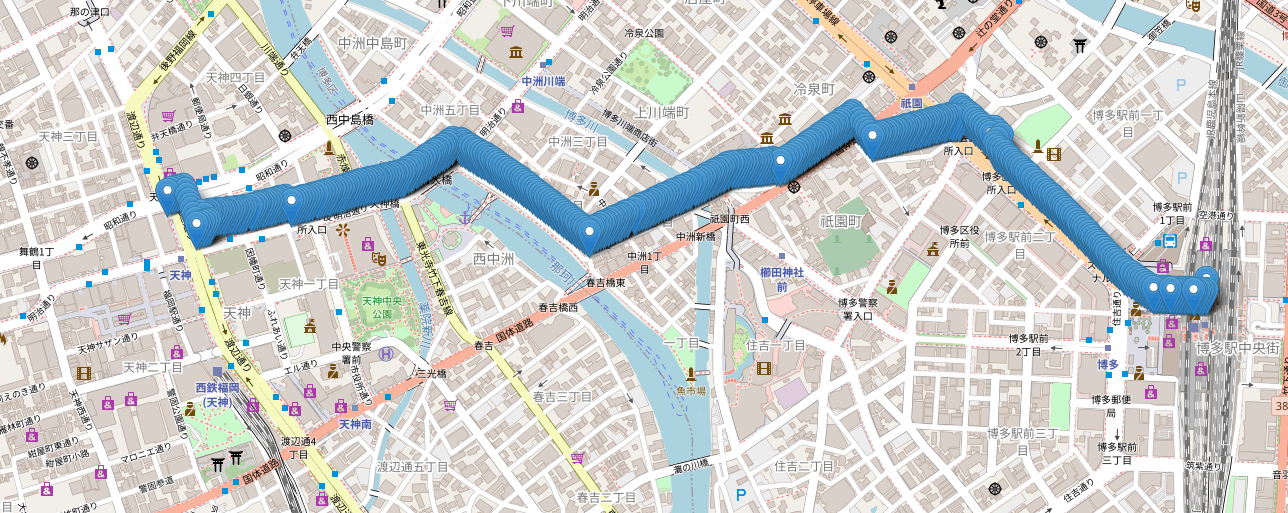
細かい部分を見るとビルに侵入していたりします。ただ、パッと見博多から天神まで行くのに通りそうな道であり、用途によっては十分に活用できるダミーデータが作れたのではないでしょうか?信号待ち等を考慮して歩行速度を微調整するなど行うことで、より良いシミュレーションデータも作れそうです。ここまでのデータを作るのに30分も掛からなかったと思います。
以上の出力ファイルやコードはここにおいています。
感想
以上の実験を通して得た感想としては、ある程度複雑なシミュレーションデータを作成する能力をChatGPTは既に持っているのだろうなということです。ただし一定の制約があって実行はできないものがあるので、人間はその制約部分を肩代わりしてやったりする必要があるのだと思いました。
【追記】
チャ○チャリアプリで目的地設定&簡易ルート表示みたいなのやってくれないかな。真面目に考えたら問題あるのかもしれないが。
-
スキーマを与えて、乱数で各フィールドを埋められるテーブルデータのダミーを作成するなど。 ↩︎
Discussion