【Amazon Bedrock】ナレッジベース活用AIアプリの構造化データのチャギング戦略
はじめに
Knowledge Bases for Amazon Bedrockを使用して、社内文書検索AIアプリを作成している際に、社員情報がまとまっているエクセルのデータの検索の精度が低く、改善することが求められました。
この時使用した方法をご紹介します。
構造化データと非構造化データ
構造化データと非構造化データの違いについておさらいしておきましょう。
構造化データは、厳密なフォーマットで管理されているデータのことを言います。
構造化データはExcel、CSV、RDSのテーブル等が該当します。
非構造化データは構造化データのようなルールはなく、画像、音声、動画ファイル、テキストドキュメントなど様々あります。
参考:構造化データと非構造化データの違いは何ですか?
環境
- ベクトルDB
- Amazon Aurora PostgreSQL
- 埋め込みモデル
- Titan Text Embeddingsv2
- 基盤モデル
- Claude 3.5 Sonnet v2
構成
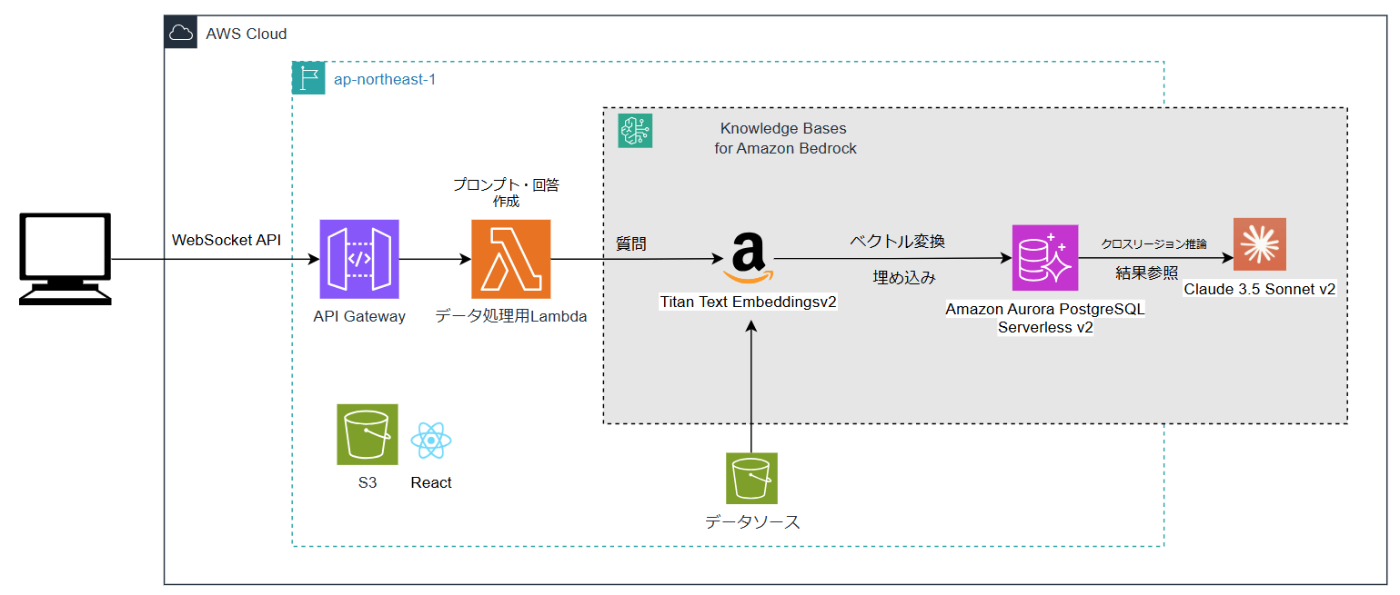
結論
精度改善ができた要因は、主に以下の2つが挙げられます。
- ナレッジベースの設定のチャギング戦略で階層型チャンキングを使用する
- データ処理用Lambdaでのハイブリッド検索の実装
ナレッジベースの設定のチャギング戦略で階層型チャンキングを使用する
今回の精度の低さの原因は、以下の事象が関係していると考えられました。
- 関連した情報がチャンク間にまたがって分割されてしまい、思うような検索結果が得られない。
- チャンクサイズを大きくするとノイズが多くなり、正確さが失われる。
そこで階層型チャンキングを使用することで、データ全体を網羅しながら、詳細なレベルの情報まで扱える柔軟性を確保することができた為と思われます。こうした階層構造を用いることで、チャンク間の文脈を保持しつつ、必要に応じて情報にアクセスすることができました。
また、オーバーラップも適切な値にすることで、生成される応答やコンテンツの一貫性が向上しました。
以下が今回の階層型チャンキングの設定です。
階層型チャンキング の設定
親トークンの最大サイズ 3000
子トークンの最大サイズ 1000
オーバーラップ 60
文書全体
├── 親チャンク1(3000トークン)
│ ├── 子チャンク1-1(1000トークン)
│ ├── 子チャンク1-2(1000トークン)
│ └── 子チャンク1-3(1000トークン)
├── 親チャンク2(3000トークン)
│ ├── 子チャンク2-1(1000トークン)
│ ├── 子チャンク2-2(1000トークン)
│ └── 子チャンク2-3(1000トークン)
└── ...
2段階検索プロセス
第1段階: 子チャンク(1000トークン)で精密検索
第2段階: ヒットした子チャンクの親チャンク(3000トークン)で文脈提供
階層型チャンキングとは
階層型チャンキングは、データを段階的に分割して階層構造を構築するチャンキング手法です。
まず大きな単位(親チャンク)でデータを分割し、その後各親チャンクをさらに細かい単位(子チャンク)に分けていきます。
この階層構造により、データ全体の文脈を保持しながら詳細な情報へのアクセスも可能になり、RAGシステムにおける検索精度と回答品質の両方を向上させることができます。
一般的にRAGにおけるチャンクサイズは、検索フェーズでは小さい方が精度が上がりやすい一方で、回答生成フェーズでは大きい方が精度が上がりやすいという性質を持ちます。
- 検索フェーズ: 小さなチャンクの方が関連性の高い情報を特定しやすく、検索精度が向上
- 生成フェーズ: 大きなチャンクの方が豊富な文脈情報を提供でき、回答品質が向上
階層型チャンキングでは、各ファイルをまず親チャンクに分割した後、さらに子チャンクとして分割し、親子をネスト構造として整理します。
- 親チャンク: 大きなサイズで文脈情報を豊富に含む
- 子チャンク: 小さなサイズで精密な検索を可能にする
- ネスト構造: 親子関係を明確に管理し、検索時は子チャンク、生成時は親チャンクを使用
その上で、サイズの小さな子チャンクを検索で使用し、サイズの大きな親チャンクを回答生成で使用することで、検索と回答生成の精度を同時に上げる良いとこ取りができるようになります。
この手法により、大規模なデータセットでも段階的な粒度で効率的に処理でき、上位レベルのチャンクが全体の文脈を提供し、下位レベルのチャンクが具体的な情報を補完するため、幅広い情報を一貫して処理することが可能です。
ナレッジベースのチャンキング戦略では、他にも以下が選択できます。
- デフォルトチャンキング
- デフォルトでは、テキストを約 300 トークンのサイズに自動的に分割します。文書が 300 トークン未満またはすでに 300 トークンの場合、それ以上は分割されません。
- 固定サイズのチャンキング
- テキストを設定したおおよそのトークンサイズに分割します
- セマンティックチャンキング
- テキストチャンクまたは文のグループを、意味的にどの程度似ているかを基準に整理します。
- チャンキングなし
- すでに前処理されたドキュメントや、それ以上のチャンクが不要な別のファイルに分割されたテキストに適しています。
オーバーラップとは
オーバーラップとは、隣接するチャンク間に共通の部分を持たせる手法です。各チャンクが一部データを共有することで、情報の断絶や文脈の喪失を防ぎます。
例えば100文字単位で分割する場合、次のチャンクが前のチャンクの最後20文字を含むように設定することで、データ間のつながりをより正確に理解できます。このように文脈を維持しながら分割を行うため、RAGが検索や生成の精度を高める効果があります。
文脈の連続性が確保されることで、生成される応答やコンテンツの一貫性が向上します。
一方で、オーバーラップではデータの冗長性が増し、全体のデータ量が膨らむというデメリットもあります。そのため、オーバーラップの範囲を適切に設定し、効率性と文脈の維持をバランスよく考慮することが重要です。
データ処理用Lambdaでのハイブリッド検索の実装
ベクトルDBへの検索時にハイブリッド検索を使用したことも精度向上の要因と思われます。
API呼び出し方法
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 10,
'overrideSearchType': 'HYBRID'
}
}
セマンティック検索とハイブリッド検索
セマンティック検索
セマンティック検索は、文章の意味や文脈を理解して検索を行う手法です。従来のキーワード検索とは異なり、単語の表面的な一致ではなく、言葉の意味的な関連性を基に情報を検索します。
例えば、「車」と検索した場合、セマンティック検索では「自動車」「乗用車」「クルマ」といった同義語や関連語を含む文書も検索結果として返します。これは、文章をベクトル化(埋め込み表現)して、意味的な類似度を計算することで実現されます。
ハイブリッド検索
ハイブリッド検索は、セマンティック検索とキーワード検索(レキシカル検索)を組み合わせた検索手法です。両方の検索結果を統合し、それぞれの長所を活かしながら短所を補完します。
キーワード検索は特定の用語や固有名詞の検索に優れており、セマンティック検索は文脈や意味の理解に長けています。ハイブリッド検索では、これらの結果をスコアリングして統合することで、より精度の高い検索を実現します。
おわりに
今回、社員情報Excelの検索精度が低いという課題に取り組む中で、階層型チャンキングとハイブリッド検索という新しい手法を学ぶことができました。
構造化データに対するRAGの改善アプローチを実際に試してみて、チャンキング戦略の重要性を改めて実感しました。同じような課題で困っている方の参考になれば嬉しいです。
Discussion