【Amazon Aurora Serverless v2・Amazon Bedrock】手動でベクトルDBを作成してRAGを作成してみよう
はじめに
Amazon Bedrockのナレッジベースを使用すれば、OpenSearch ServerlessやAmazon Aurora Serverless v2をプロビジョニングでき、簡単にRAGシステムを作ることができます。
自動プロビジョニングは非常に便利な機能ですが、この機能は裏でCloudFormationを使用してデフォルトVPCにデータベースの作成やテーブルの作成などを行っています。
そのため、既存のVPCやサブネット、データベースのプライベートサブネットへの配置など、事前に作成済みのリソースを使用してデータベースを構築したい場合は、自動プロビジョニング機能を利用することができません。
そこで今回は、すべて手動でAmazon Aurora Serverless v2を作成し、ベクトルDBの設定をして、Amazon Bedrock ナレッジベースを活用したRAGシステムの実装方法について解説します。
Amazon Aurora Serverless v2を選択する理由
ベクトルDBの選択肢として、OpenSearch ServerlessやPineconeなど様々な選択肢がありますが、今回Aurora Serverless v2を選択する理由は以下の通りです。
コスト効率: 使用した分だけの従量課金で、アイドル時は最小容量まで自動スケールダウン
最小容量0にしてしまうとリクエスト時にコールドスタートしてしまうので注意。
PostgreSQLの豊富な機能: pgvectorエクステンションによる高性能なベクトル検索に加え、RDBMSとしての堅牢なデータ管理機能
既存システムとの親和性: 多くの企業で採用されているPostgreSQLベースのため、既存のデータベース運用ノウハウを活用可能
AWSマネージドサービス: バックアップ、パッチ適用、監視などの運用負荷を軽減
セキュリティ: VPC内でのプライベート配置、IAMによる細かなアクセス制御が可能
作成するリソース一覧
ネットワーク関連
- VPC
- サブネット
- NATゲートウェイ
- インターネットゲートウェイ
- ルートテーブル
セキュリティ関連
- シークレットマネージャー
- マスターユーザー用(Aurora作成時自動生成)
- アプリケーションで使用するユーザー用
- セキュリティグループ(Aurora用)
- IAMロール(Bedrockナレッジベース用)
データベース関連
- Aurora PostgreSQL Serverless v2
- ベクトルDB設計(pgvector)
- サブネットグループ
AI/ML関連
- S3
- RAG用データソース
- Amazon Bedrock ナレッジベース
- 埋め込みモデル:Titan Text Embeddings v2
実装
VPC,サブネット,NATゲートウェイ,インターネットゲートウェイ,ルートテーブル
データベースはプライベートサブネットに配置するので、
パブリックサブネット2個とプライベートサブネット2個を作成していきます。

セキュリティグループ(Aurora用)
Aurora PostgreSQL Serverless v2用のセキュリティグループを作成します。
インバウンドルール
-
タイプ:
PostgreSQL -
プロトコル:
TCP -
ポート範囲:
5432 -
ソース:
カスタム -
対象:
自分のセキュリティグループ ID
※同じセキュリティグループ内からのみアクセス許可
アウトバウンドルール
-
タイプ:
すべてのトラフィック -
プロトコル:
すべて -
ポート範囲:
すべて -
ソース:
カスタム -
対象:
0.0.0.0/0
シークレットマネージャー
マスターユーザー用はAurora作成時に自動生成されるので、アプリケーションで使用するユーザー用のシークレットを作成していきます。
もちろんマスターユーザー用を独自に作成することも可能です。
- マスターユーザー:DBA作業用
- アプリケーションユーザー:Bedrock ナレッジベース専用
後々にクエリエディタでログインする際に使用しますので、キーをusernameとpasswordにするように作成してください。

Aurora PostgreSQL Serverless v2
まずは、サブネットグループを作成しましょう。
プライベートサブネットをグループに含めます。

では、いよいよデータベースの作成に入ります。
-
エンジンのタイプ:
Aurora (PostgreSQL Compatible) -
バージョン:
Aurora PostgreSQL (Compatible with PostgreSQL 16.6)

-
DB クラスター識別子:
oishi-bedrock-knowledge-base-cluster -
マスターユーザー名:
BedrockAdmin -
認証情報管理:
AWS Secrets Manager で管理 -
暗号化キーを選択:
aws/secretsmanager (デフォルト) -
クラスターストレージ設定>設定オプション:
Aurora スタンダード -
インスタンスの設定>DB インスタンスクラス:
Serverless v2 -
容量の範囲>最小キャパシティ (ACU):
0.5 -
容量の範囲>最大キャパシティ (ACU):
16

-
マルチ AZ 配置:
EC2 コンピューティングリソースに接続しない -
コンピューティングリソース:
Aurora レプリカを作成しない -
ネットワークタイプ:
IPv4 -
VPC:
事前に設定したVPC -
DB サブネットグループ:
事前に設定したサブネットグループ -
パブリックアクセス 情報:
なし -
VPC セキュリティグループ:
事前に設定したセキュリティグループ -
アベイラビリティーゾーン:
ap-northeast-1a -
認証機関:
rds-ca-rsa2048-g1 (デフォルト) -
RDS Data API:
有効化★重要! -
データベースポート:
5432 -
リードレプリカの書き込み転送:
オフ

以下画像の通り
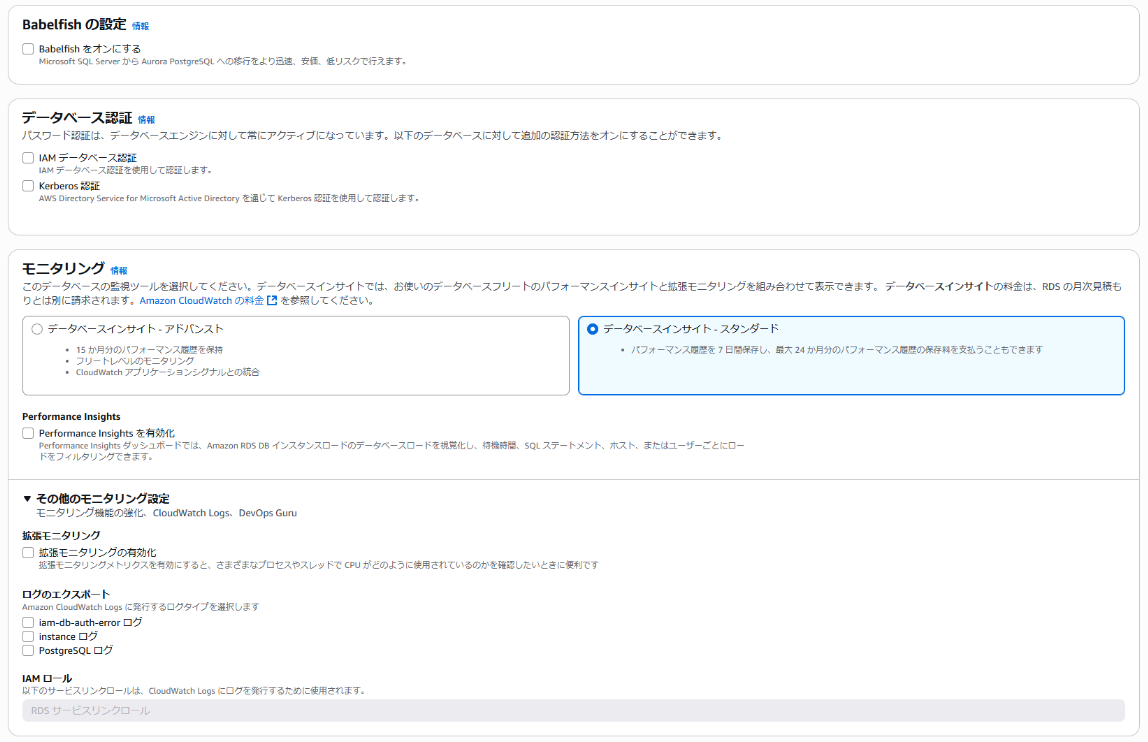
-
最初のデータベース名:
Bedrock_Knowledge_Base_Cluster -
DB クラスターのパラメータグループ:
default.aurora-postgresql16 -
DB パラメータグループ:
default.aurora-postgresql16 -
オプショングループ:
default.aurora-postgresql16 -
暗号を有効化:
オン:(default) aws/rds -
削除保護の有効化:
オフ
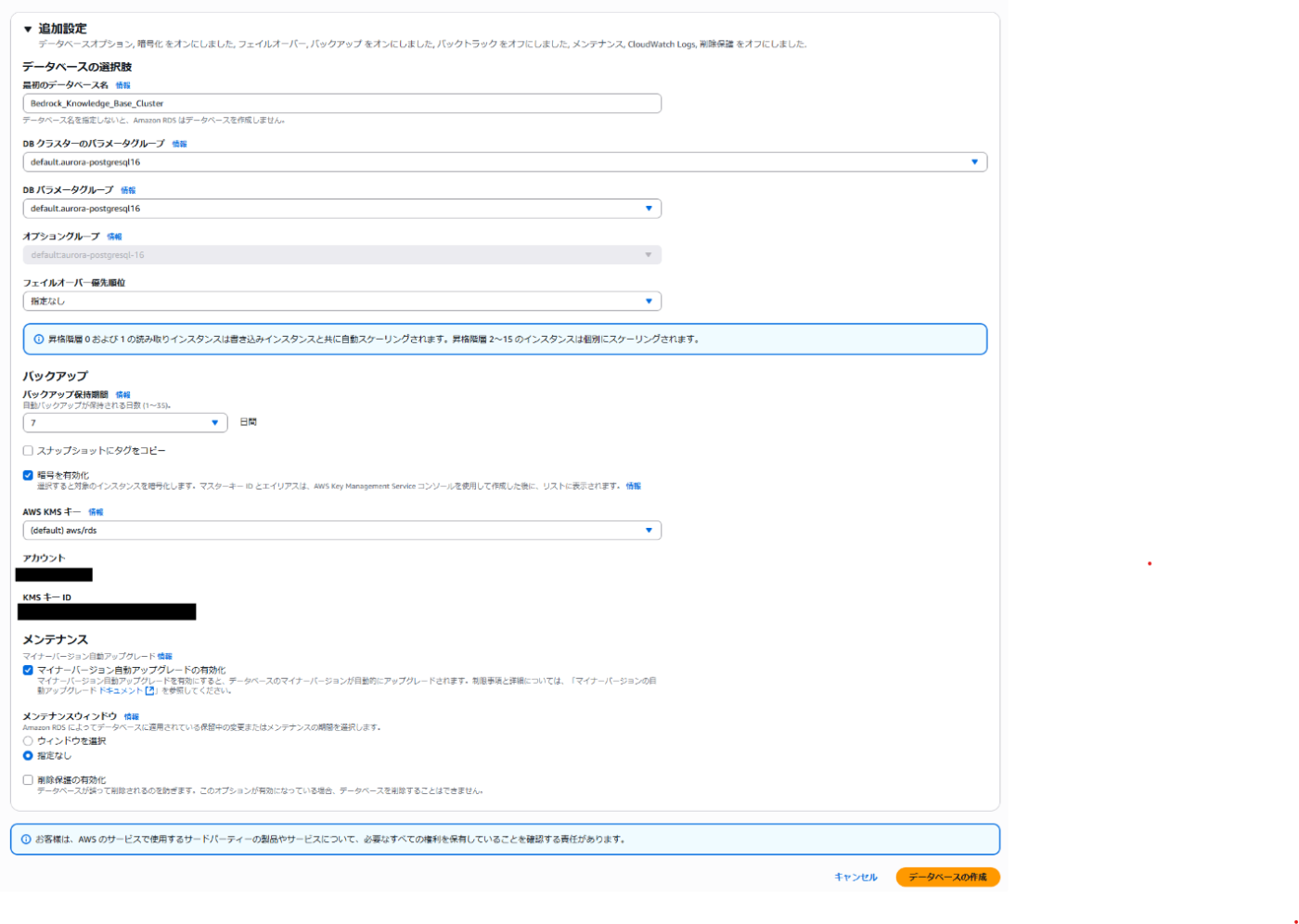
これでデータベースを作成しましょう!
アプリケーション用ユーザー作成
ここからデータベース内に入り、設定をしていきます。
わざわざ踏み台サーバー等を用意しなくても、Data APIを有効化していれば、クエリエディタが使用できます。これでマネジメントコンソールからSQL文を実行できます。
詳しくはこちらを参照ください。
まず、アプリケーション用ユーザーを作成するためにマスターユーザーでログインします。
ここでのシークレットマネージャーのARNはAurora作成時に自動で作成されたものですので、ご注意ください。

以下のSQL文を実行していきます。一列ごとでも、全文でもどちらでもOKです。実行をクリックしましょう。
StatusがSuccessになったら成功です。

-- pgvectorを有効化
CREATE EXTENSION IF NOT EXISTS vector;
-- アプリケーションユーザーを作成
CREATE ROLE bedrock_user WITH LOGIN PASSWORD 'アプリケーション用ユーザーパスワード';
-- スキーマ作成権限を付与
GRANT CREATE ON DATABASE "データベース名" TO bedrock_user;
-- ※(必要に応じて)パスワード変えるとき
ALTER ROLE bedrock_user WITH PASSWORD 'xxx';
次に、スキーマとテーブルを作成していきます。
まず、データベースを変更するをクリックして、アプリケーションユーザーのシークレットマネージャーに変更してログインしましょう。
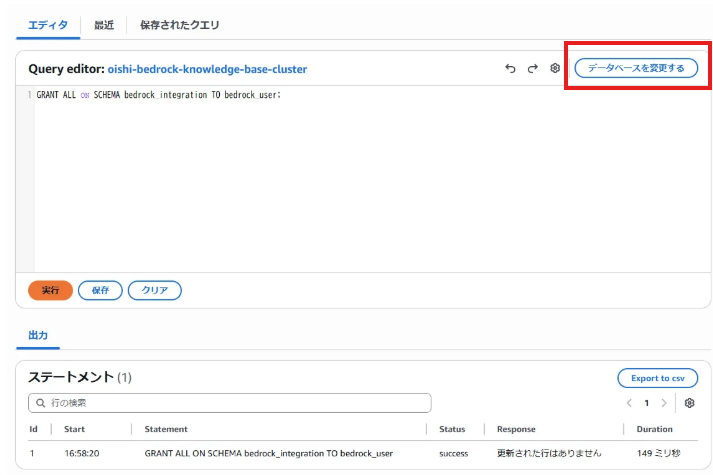
ログインできたら以下のSQLを実行していきます。
-- スキーマ作成
CREATE SCHEMA bedrock_integration;
-- テーブル作成
CREATE TABLE bedrock_integration.bedrock_knowledge_base (
id uuid PRIMARY KEY,
embedding vector(1024),
chunks text,
metadata jsonb,
custommetadata jsonb
);
-- ベクター検索用インデックス
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING hnsw (embedding vector_cosine_ops);
-- テキスト検索用インデックス
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (to_tsvector('simple'::regconfig, chunks));
-- カスタムメタデータ検索用インデックス
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (custommetadata);
お疲れ様でした!
これでデータベースの設定は完了です!
RAG用 S3バケット
データソースを保管しておく為のS3バケットを作成します。
特に設定はないので、デフォルトで大丈夫です。
IAMロール(Bedrockナレッジベース用)
Bedrockナレッジベースがデータベースやシークレットマネージャーなどにアクセスできるようにロールを作成します。
amazon.titan-embed-text-v2:0はお使いの埋め込みモデルで設定してください。
ポリシーを2つ作ります。
ポリシー作成
- BedrockExecution-Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.titan-embed-text-v2:0"
],
"Effect": "Allow",
"Sid": "BedrockInvokeModelStatement"
},
{
"Action": [
"rds:DescribeDBClusters"
],
"Resource": [
"arn:aws:rds:ap-northeast-1:アカウントID:cluster:oishi-bedrock-knowledge-base-cluster"
],
"Effect": "Allow",
"Sid": "RdsDescribeStatementID"
},
{
"Action": [
"rds-data:ExecuteStatement",
"rds-data:BatchExecuteStatement"
],
"Resource": [
"arn:aws:rds:ap-northeast-1:アカウントID:cluster:oishi-bedrock-knowledge-base-cluster"
],
"Effect": "Allow",
"Sid": "DataAPIStatementID"
},
{
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
" アプリケーションユーザーのシークレットマネージャーのARN"
],
"Effect": "Allow",
"Sid": "SecretsManagerGetStatement"
}
]
}
- Bedrock-S3-Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"アカウントID"
]
}
},
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::RAG用S3のバケット名"
],
"Effect": "Allow",
"Sid": "S3ListBucketStatement"
},
{
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"アカウントID"
]
}
},
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::RAG用S3のバケット名/*"
],
"Effect": "Allow",
"Sid": "S3GetObjectStatement"
}
]
}
上記2つをアタッチしたポリシーを作成します。
ここでは、BedrockExecutionRoleとしておきます。
Amazon Bedrock ナレッジベース
いよいよナレッジベースの作成です。
下記の画面から新規作成していきましょう。

-
ナレッジベース名:
任意 -
サービスロール:
先ほど作成したロール(BedrockExecutionRole) -
データソース:
S3

-
データソース名:
任意 -
S3 の URI:
先ほど作成したS3バケット -
チャギング戦略:
任意

-
埋め込みモデル:
Titan Text Embeddings v2(任意:ポリシー設定忘れずに) -
ベクトルストアの作成方法:
既存のベクトルストアを選択
★ここで新規作成を選んでしまうと今までの苦労が水の泡です。。 -
ベクトルストア:
Aurora -
Amazon Aurora DB クラスター ARN:
作成したDB参照
★ここのARNはデータベースのARNです。インスタンスのARNを指定しないように注意してください。 -
データベース名:
Bedrock_Knowledge_Base_Cluster -
テーブル名:
bedrock_integration.bedrock_knowledge_base -
シークレットARN:
アプリケーションユーザーのシークレットARN -
シークレットARN:
アプリケーションユーザーのシークレットARN -

-
ベクトルフィールド名:
embedding -
テキストフィールド名:
chunks -
メタデータフィールド名:
metadata -
プライマリキー:
id

これでナレッジベースの作成は完了です!!
データソース同期
作成が完了したら、ベクトルDB(Aurora)に埋め込みモデルを使用して、データソースをベクトル変換していきます。
ここは1クリックで完了します。
作成したナレッジベースのデータソースにチェックを入れた状態で同期をクリックします。

もし警告が出る場合は、データソースが対応していない可能性があります。
以下を参照してください。
成功したら全体の完成です!!
テスト
では、作成したものをテストしていきましょう。
以下のナレッジベースをテストをクリックします。

使用したい基盤モデルを選択します。
プロンプトでデータソース内に関するものを入力してみましょう。
回答が得られればRAGの完成です!

-
モデルが選択できない場合は、以下から使いたいモデルのアクセスを有効化しましょう。

-
モデルの料金について
https://aws.amazon.com/jp/bedrock/pricing/ -
Claudeモデルは1分間のリクエストに制限があることがあるので、確認しましょう。
Service Quotasでrequests per minute for Anthropic Claude 3.5 Sonnetなどと検索すれば確認できます。クォータ値を上げたい場合は、サポートに連絡して上げてもらいましょう。

おわりに
本記事では、Amazon Aurora Serverless v2とAmazon Bedrockを使用して、手動でベクトルDBを構築しRAGシステムを実装する方法について解説しました。
自動プロビジョニング機能とは異なり、既存のVPCやセキュリティ要件に合わせてカスタマイズしたデータベース環境を構築することができました。
機能的にはOpenSearch Serverlessを使用したいところですが、料金のことを考えるとAurora Serverless v2も選択の一つに入ってくると思います。
手動での構築は工数がかかりますが、セキュリティ要件やネットワーク構成をより細かく制御できるメリットがあります。
今回の実装手順が、参考になれば幸いです。
Discussion