snowflake
外部ステージのファイルを確認する方法
SELECT $1, $2, $3, $4, $5, $6, $7
FROM 'hogehoge.csv';
外部ステージの定義確認
指定された外部ステージ(ここでは@DB_STAGE)の定義を確認してください。以下のコマンドを実行することで、外部ステージの詳細情報を表示することができます。
DESC STAGE DB_STAGE;
ファイルの存在確認
指定したファイルパス(export/cdc/CDC_TXN-20230821.csv.gz)が実際に存在するか確認してください。例えば、以下のコマンドでリストを取得できます。
LIST '@DB_STAGE/export/cdc/';
外部ステージに設定されたファイルフォーマットを確認する。INFORMATION_SCHEMAのViewの中にFILE_FORMATSがあるので活用
SELECT *
FROM DATALAKE.INFORMATION_SCHEMA.FILE_FORMATS;
ALTER STAGE DB_STAGE
SET FILE_FORMAT = (FORMAT_NAME = CSV);
外部ステージごとにファイルフォーマットが固定なのか確認が必要。同じ外部ステージでcsvとparquetを使い分けたい。操作中に異なるファイルフォーマットを動的に指定してデータをロードする必要あり。
snowflakeでVARCHAR型とSTRING型の違い
基本的に同じ。
VARCHAR: 可変長の文字列データ型。定義時に最大長を指定することができますが、指定しない場合はデフォルトの最大長(16777216 文字)となります。
STRING: VARCHARのエイリアス(同義語)として使われることが多いです。実際には、STRINGはVARCHARと同じ振る舞いをします。
Failed to cast variant value 1 to BOOLEAN の対応
snowflakeではVariant型のデータ値をBOOLEAN型にcastすることができない。
一回、VARCHAR型を経由してからBOOLEAN型にする。
((data:test_bool)::VARCHAR)::BOOLEAN
マルチクラスターウェアハウスとは
Snowflakeのマルチクラスターコンピューティングウェアハウスは、企業が大量のデータをリアルタイムで効率的に処理するニーズに応えるための強力な機能 です。大規模なデータセットに対するクエリや、多数のユーザーからの同時アクセスが予測される場面で、この機能は特に価値を発揮します。
- スケーラビリティ: トラフィックやクエリの負荷が増加すると、自動的に複数のコンピューティングクラスターを起動して、その負荷を分散する能力があります。
- パフォーマンス: 複数のユーザーまたはシステムが同時にデータウェアハウスにアクセスしても、クエリのパフォーマンスが低下することがありません。これは、必要に応じて追加のクラスターが動的にスピンアップされるためです。
- コスト効率: クラスターは、必要なときだけ起動されるため、リソースの浪費を減少させ、コスト効率を高めることができます。
- 自動的なスケールダウン: 負荷が減少すると、不要なクラスターは自動的にシャットダウンされ、リソースの消費を最小限に抑えます。
- 分離されたリソース: コンピューティングとストレージが分離されているため、それぞれを独立してスケールアップ・ダウンすることができます。
Snowflakeのデフォルトの仮想ウェアハウスはシングルコンピュートで、同時に複数のクエリを実行することはできません。複数のクエリが送られると、一つずつ順番に処理されます。しかし、ユーザーや連携システムが増えると、この方式ではクエリの処理に遅延が生じる恐れがあります。
この問題を解消するために、Snowflakeは「Multi-Cluster Warehouse (MCW)」を提供しています。これは複数のクラスタを持つ仮想ウェアハウスで、高い同時並行性を持っており、多くのリクエストに効率的に対応することができます。ただし、この機能はEnterprise Edition以上のプランでのみ利用可能です。
Query Acceleration Serviceとは
Snowflakeの「Query Acceleration Service」は、ウェアハウスのクエリワークロードを高速化するための機能です。このサービスを活用することで、特定の高リソース消費クエリ(外れ値クエリ)の影響を低減し、ウェアハウス全体のパフォーマンスを向上させることができます。この高速化は、クエリ処理の一部をSnowflakeの共有コンピューティングリソースにオフロードすることで実現されます。
この機能は、以下のようなワークロードに特にメリットをもたらします:
アドホック分析: 予期せぬクエリが投げられる場面での分析。
予測困難なデータ量: クエリごとに取得するデータの量が不確かな場合。
大量データスキャン: 大規模なデータスキャンや特定のフィルタリングを伴うクエリ。
「Query Acceleration Service」の導入により、並行処理の量を増やすとともに、データスキャンやフィルタリングにかかる時間を短縮し、ワークロードの効率的な処理が期待できます。
snowpipe関係コマンド
snowpipeが動作したかを確認
SELECT SYSTEM$PIPE_STATUS('[テーブル名]');
IAM_POLICYを確認
SELECT SYSTEM$GET_AWS_SNS_IAM_POLICY( 'arn:~~~' );
作成されたPipeを確認
SHOW PIPES;
copy履歴を確認
SELECT *
FROM TABLE(information_schema.copy_history(table_name=>'[テーブル名]', start_time=> dateadd(hours, -100, current
git repository連携した後のストアドプロシージャをpythonスクリプトから作る方法
CREATE OR REPLACE PROCEDURE hello_git ()
returns table ()
language python
runtime_version='3.8'
packages= ('snowflake-snowpark-python')
imports= ('@upatel_snowpark_workshop/branches/main/gittest.py')
handler= 'gittest.hello';
CALL hello_git();
-- You will see 1000 rows of customer as created earlier
deploy streamlit app from github code
create or replace streamlit tb_streamlit_app
root_location = @demodb.dev.upatel_snowpark_workshop/branches/main/
main_file = '/tastybyte_sis.py'
query_warehouse = 'DEMO_WH';
ParquetファイルでBOOLEAN型カラムは元々0,1で管理されていた場合、そのままCASTしようとするとVARIANT型と認識されてエラーになる
SELECT
TO_BOOLEAN($1:is_sample)
FROM
'@external_stage'
(FILE_FORMAT => 'parquet_format', PATTERN => '.*part.*');
Failed to cast variant value 0 to BOOLEAN
型を明示してあげる必要がある
SELECT
TO_BOOLEAN($1:is_sample::INTEGER)
FROM
'@external_stage'
(FILE_FORMAT => 'parquet_format', PATTERN => '.*part.*');
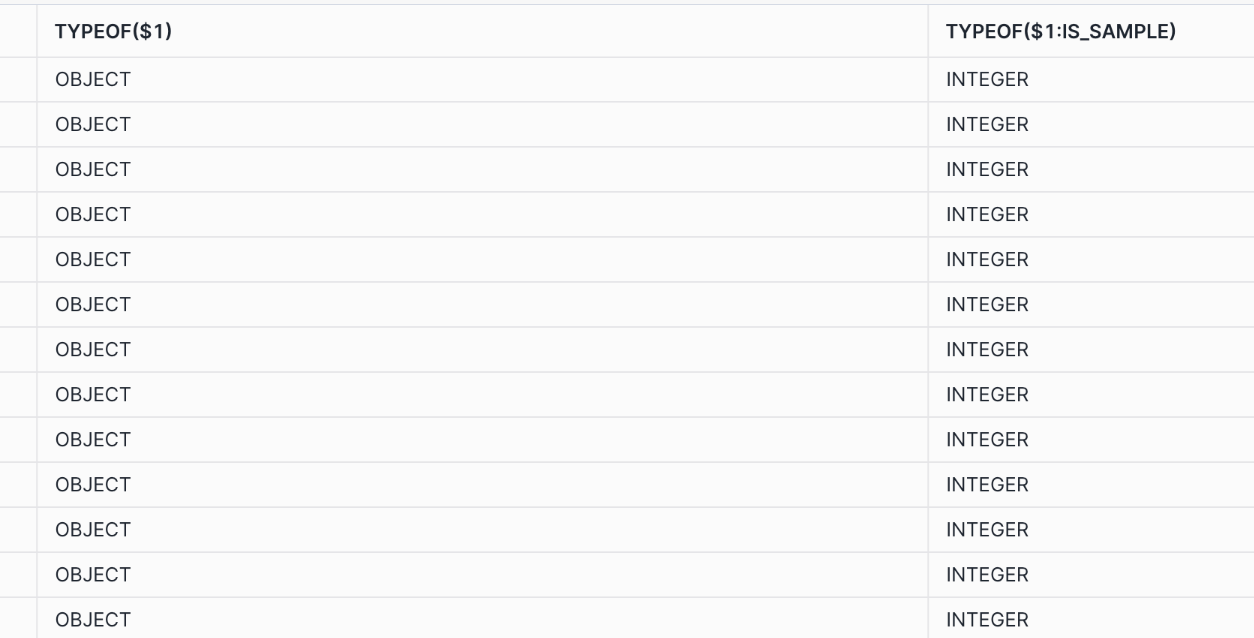
カラム型を調べるのはTYPEOF関数を使う
TYPEOF関数を使ってみるとsnowflakeではInteger型で認識される
SELECT
TYPEOF($1),
TYPEOF($1:is_sample)
FROM
'@external_stage'
(FILE_FORMAT => 'parquet_format', PATTERN => '.*part.*');
result
外部テーブル作成時にinfer_schemaを使う場合、パーティションの設定は可能か。
どうやらできないらしい。回避策としてGENERATE_COLUMN_DESCRIPTIONをつかってカラムを把握してからパーティション指定してということが書いてある。
CREATE OR REPLACE EXTERNAL TABLE raw_data (
"id" NUMBER(38, 0) AS ($1:id::NUMBER(38, 0)),
"is_making" NUMBER(38, 0) AS ($1:is_making::NUMBER(38, 0)),
"updated_at" TIMESTAMP_NTZ AS ($1:updated_at::TIMESTAMP_NTZ),
"bin" BINARY AS ($1:bin::BINARY),
"inbox_id" NUMBER(38, 0) AS ($1:inbox_id::NUMBER(38, 0)),
"created_at" TIMESTAMP_NTZ AS ($1:created_at::TIMESTAMP_NTZ),
"segment_id" NUMBER(38, 0) AS ($1:segment_id::NUMBER(38, 0))
)
PARTITION BY ("created_at")
LOCATION = @DB_STAGE
FILE_FORMAT = parquet_format
AUTO_REFRESH = true
;
Function GET is not supported in an external table partition column expression.