本記事は、Snowflake Advent Calendar 2023 の 25 日目です。
データエンジニアの是枝です。
Snowpark Container Service、とうとうGAが始まりましたね...!
Powered by Snowflakeを体現しようと尽力している弊社にとって大変強力な機能です。そこで早速、Tutorialにトライしてみて公式ドキュメントを調査してみたところ、snowflakeをアプリケーション開発に用いている企業にとっては革命的で有ることがわかりました。その記録をこちらの記事で紹介していこうと思います。
(追記)
Snowpark Container Serviceに関する記事を一番に出そうとしたら、masuoさんに先越されました...笑
しかし、Masuoさんの記事はQuick startを取り扱ってるので、私のTutorialといい感じで棲み分けられそうです!両方の記事をご参考ください!!
(GAになってからsnowflake社員以外では一番?)
(2024年8月2日 追記2)
Snowflake社がSPCSのコンピューティング料金を50%オフにしてくれました!!コストで使用を諦めていた方も再度検討の余地がありそうですね!
Snowpark Container Serviceとは?
公式ドキュメントを日本語訳にかけて要点だけを読んでみます。
Snowpark Container Services は、Snowflake エコシステム内でコンテナ化されたアプリケーションのデプロイ、管理、スケーリングを容易にするように設計されたフルマネージドのコンテナ製品です。このサービスにより、ユーザーはコンテナ化されたワークロードを Snowflake 内で直接実行できるため、処理のためにデータを Snowflake 環境の外に移動する必要がなくなります。Snowpark Container Services は、Snowflake に特化して最適化された OCI ランタイム実行環境を提供します。この統合により、Snowflake の堅牢なデータ プラットフォームを活用して、OCI イメージをシームレスに実行できるようになります。
Snowpark Container Services は、サードパーティのツールとも統合されています。これにより、サードパーティ クライアント (Docker など) を使用して、アプリケーション イメージを Snowflake に簡単にアップロードできるようになります。
Snowpark Container Services でコンテナ化されたアプリケーションを実行するには、データベースやウェアハウスなどの基本的な Snowflake オブジェクトの操作に加えて、イメージ リポジトリ、 コンピューティング プール、サービス、および*ジョブ のオブジェクトも操作します。
つまり、Snowpark Container Servicesは、Snowflake内で簡単にアプリケーションを実行できるツールです。GPU を用いた LLM を含む機械学習モデルの学習及び実行やあらゆる言語の実行が可能になります。それも外部にデータを移すことなく、Snowflake上で直接アプリを動かせるようになります。
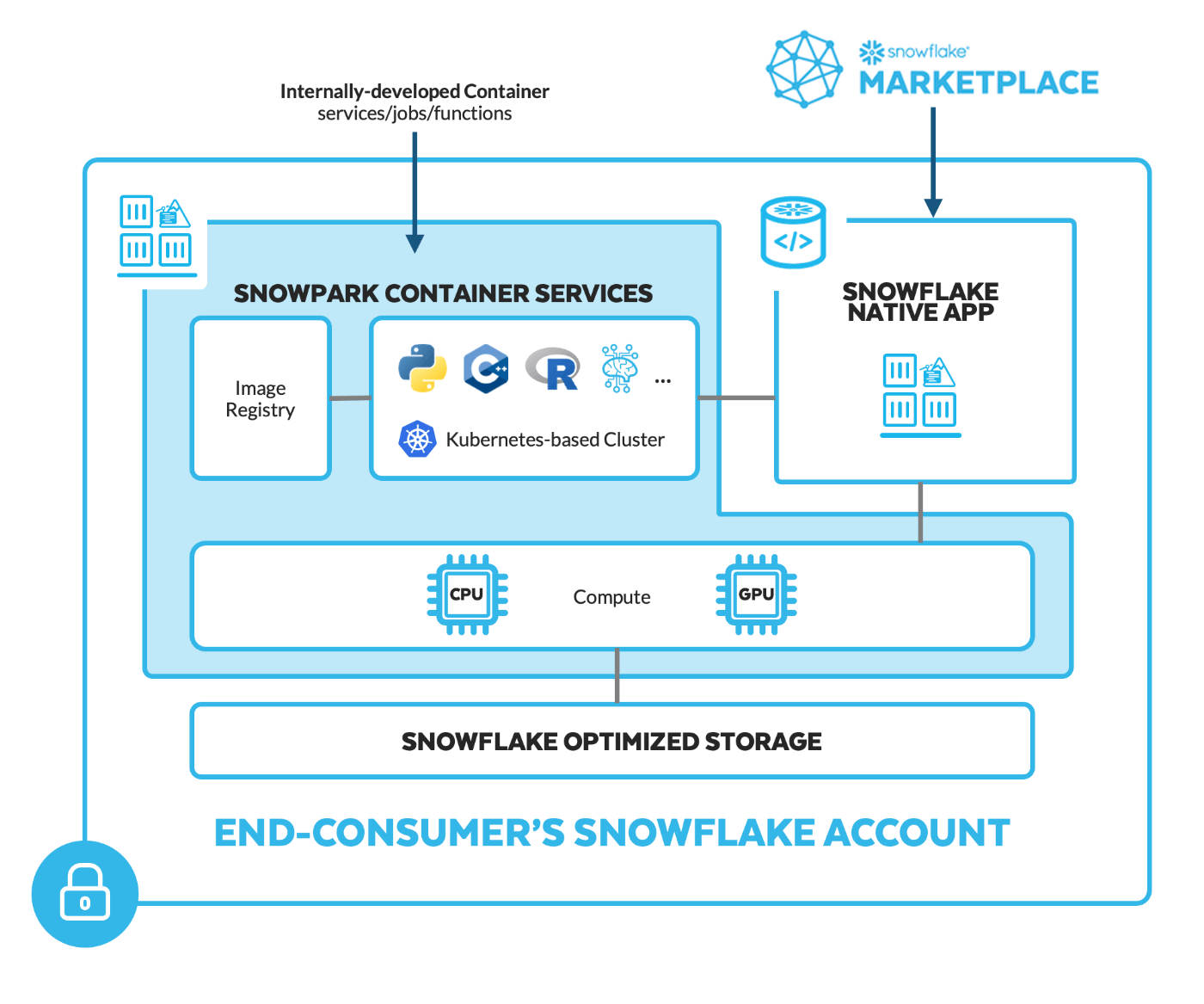
Snowflake は、イメージを保存するためのOCIv2準拠サービスであるイメージ レジストリを提供します 。これにより、OCI クライアント (Docker CLI や SnowSQL など) が Snowflake アカウントのイメージ レジストリにアクセスできるようになります。
また、Dockerのような他のツールとも連携して、アプリのアップロードが簡単になります。
普段、コンテナ環境でデプロイされているアプリケーション開発されている方にとってはかなり親和性が高い機能なのではないでしょうか?
Snowpark Container Servicesのチュートリアルをやってみる
では、早速Snowpark Container Servicesのチュートリアルをやってみようと思います。参考にしたドキュメントはこちらになります。
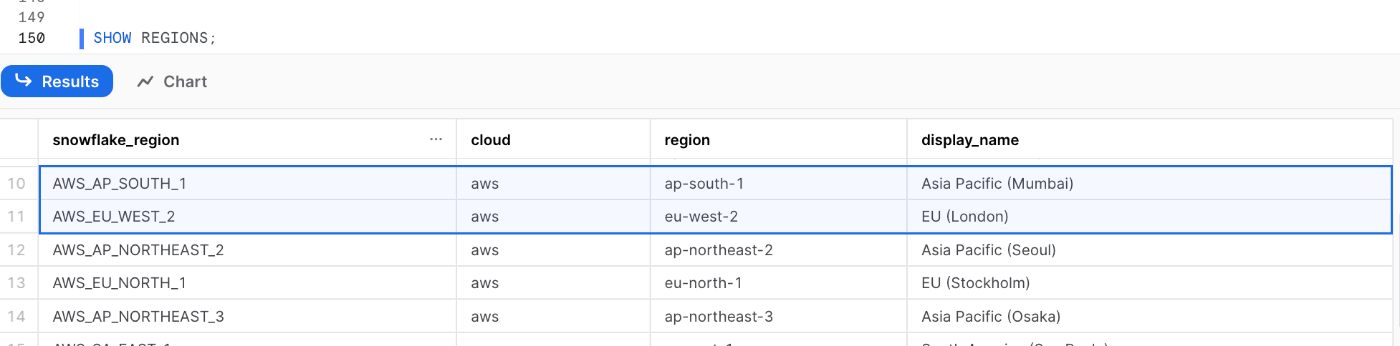
ムンバイまたはロンドンリージョンに環境を作る (しなくて良い)
チュートリアルを始める前に、orgadminロールを使用して、create accountコマンドでムンバイまたはロンドンリージョンに環境を作る必要があります。
ロンドンリージョンで作るならaws_eu_west_2 、ムンバイリージョンでつくるならap-south-1 です。
use role ORGADMIN;
CREATE ACCOUNT SNOWPARK_CONTAINER_TEST
ADMIN_NAME = TATSUYA_KOREEDA
ADMIN_PASSWORD = [passwordを入力]
EMAIL = '[メールアドレスを入力]'
EDITION = 'ENTERPRISE'
REGION = aws_eu_west_2;
ちなみにリージョンの識別子が知りたい場合は SHOW REGIONS で調べることが可能です。
SHOW ORGANIZATION ACCOUNTS のaccount_locator_urlを見ると、ログインURLを調べることができます。新しいアカウント管理者ユーザーは、最初のログイン時にパスワードを変更する必要があります。これで準備完了です。

Snowflakeの各種オブジェクトを用意する
ACCOUNTADMIN ロールを使用して、usernameをSnowflake ユーザーの名前に置き換えて次のスクリプトを実行します。
//チュートリアルで使用するロール作成
CREATE ROLE test_role;
GRANT ROLE test_role TO USER <username>;
ALTER USER <username> SET DEFAULT_ROLE = test_role;
//サービスとジョブを実行するコンピューティング プールを作成
CREATE COMPUTE POOL tutorial_compute_pool
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = CPU_X64_XS;
GRANT ALL ON COMPUTE POOL tutorial_compute_pool TO ROLE accountadmin;
GRANT OWNERSHIP ON COMPUTE POOL tutorial_compute_pool TO ROLE test_role;
//使用するウェアハウス作成
CREATE OR REPLACE WAREHOUSE tutorial_warehouse WITH
WAREHOUSE_SIZE='X-SMALL'
AUTO_SUSPEND = 180
AUTO_RESUME = true
INITIALLY_SUSPENDED=false;
//使用するウェアハウス作成
GRANT ALL ON WAREHOUSE tutorial_warehouse TO ROLE test_role;
//データベース作成
CREATE DATABASE tutorial_db;
//データベースに対する OWNERSHIP権限を付与
GRANT OWNERSHIP ON DATABASE tutorial_db TO ROLE test_role;
test_role ロールがデータベース内に他のリソースを作成してタスクを実行できるようにします。
GRANT BIND SERVICE に関するドキュメントが見つけられませんでしたが、名前から察するにサービスで定義するエンドポイントにアクセスするための権限を、ロールに付与しているのだと思われます。
GRANT BIND SERVICE ENDPOINT ON ACCOUNT TO ROLE test_role;
ACCOUNTADMIN ロールを使用して、次のステートメントを実行します。Snowpark Container Servicesでは、認証に Snowflake OAuth を使用します。こちらのコマンドでは新しいOAuthセキュリティ snowservices_ingress_oauth を作成しています。
CREATE SECURITY INTEGRATION IF NOT EXISTS snowservices_ingress_oauth
TYPE=oauth
OAUTH_CLIENT=snowservices_ingress
ENABLED=true;
データベース内での各種オブジェクトを作成していきます。
USE ROLE test_role;
USE DATABASE tutorial_db;
USE WAREHOUSE tutorial_warehouse;
CREATE SCHEMA data_schema;
その後、CREATE OR REPLACE IMAGE REPOSITORY にてDockerイメージをアップロードするリポジトリを作成します。
//リポジトリの作成。Dockerイメージをこのリポジトリにアップロードします。
CREATE OR REPLACE IMAGE REPOSITORY tutorial_repository;
そして、ステージを作成し仕様ファイルをアップロードしていきます。各サービスまたはジョブ イメージには、サービスまたはジョブの実行に必要なSnowflake情報を提供する仕様ファイルが含まれています。
//ステージ作成
CREATE STAGE tutorial_stage DIRECTORY = ( ENABLE = true );
SHOW COMPUTE POOLS または DESCRIBE COMPUTE POOL tutorial_compute_pool でコンピューティング プールの存在を確認してみましょう。
SHOW COMPUTE POOLS;
DESCRIBE COMPUTE POOL tutorial_compute_pool;
きちんとコンピューティング プールの存在を確認できます。

Imageを作成してsnowflakeリポジトリにプッシュする
ここまででSnowpark Container Services上でサービスを作成する準備が整いました。このチュートリアルでは、入力として提供したテキストを単にエコーバックするサービス ( という名前) を作成していきます。
サービスに必要なコードをダウンロードしていきます。今回はsnowflake社が用意しているfileを使用していきますので、こちらにアクセスして、zip fileをクリックしてダウンロードを開始して下さい。

ターミナルで解凍したファイルが含まれるディレクトリに移動、現在の作業ディレクトリ (.) を指定して次のコマンドを実行します。
docker build --rm --platform linux/amd64 -t my_echo_service_image:tutorial .
image URL ( <repository_url>/<image_name>) をタグ付けします。
docker tag my_echo_service_image:tutorial <repository_url>/my_echo_service_image:tutorial
# 例
# docker tag my_echo_service_image:tutorial \
# myorg-myacct.registry.snowflakecomputing.com/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:tutorial
<repository_url>を把握したい場合は、SHOW IMAGE REPOSITORIESでrepository_url列を参照してください。
SHOW IMAGE REPOSITORIES;

Snowflake レジストリを使用して Docker を認証していきます。
docker login <registry_hostname> -u <username>
<registry_hostname>は SHOW IMAGE REPOSITORIES SQL コマンドを使用してリポジトリ URL として取得されるURLです。URL内のホスト名はレジストリのホスト名です。(例:myorg-myacct.registry.snowflakecomputing.com)
<username>は Snowflake ユーザー名です。
コマンド入力しますとpasswordが求められますので、Snowflakeユーザーのpasswordを入力すると「Login Succeeded」となります。
それではsnowflake上に作成したリポジトリにイメージをPushしていきましょう。<repository_url>を置き換えて実行してください。
docker push <repository_url>/my_echo_service_image:tutorial
# 例
# docker push myorg-myacct.registry.snowflakecomputing.com/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:tutorial
pushが成功するとターミナルの画面では、以下のようになります。
(base) t_koreeda@user Tutorial-1 % docker push [レポジトリURL]/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:tutorial
The push refers to repository [レポジトリURL]/tutorial_db/data_schema/tutorial_repository/my_echo_service_image]
0a8710dddce3: Pushed
ec7c17e51604: Pushed
77bac83053e8: Pushed
c5321f7f53ff: Pushed
df6c1b185b95: Pushed
b23fedba7dbd: Pushed
ae2d55769c5e: Pushed
e2ef8a51359d: Pushed
tutorial: digest: sha256:a0f8e6eb8f4377e8328938902f51 size: 1996
サービスの作成
次は、サービスの作成していきます。
以下のコマンドで、echo_service というサービスを作成していきます。サービスの仕様は SPECIFICATION内のYAMLで記述します。
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
FROM SPECIFICATION $$
spec:
containers:
- name: echo
image: /tutorial_db/data_schema/tutorial_repository/my_echo_service_image:tutorial
env:
SERVER_PORT: 8000
CHARACTER_NAME: Bob
readinessProbe:
port: 8000
path: /healthcheck
endpoints:
- name: echoendpoint
port: 8000
public: true
$$
MIN_INSTANCES=1
MAX_INSTANCES=1;
(Service specificationのシンタックスに関してはこちらにまとまっています。)
YAMLのコードを解説していきます。
-
containers: コンテナのリストです。
echoという名前のコンテナが定義されており、先程リポジトリにプッシュしたイメージ(my_echo_service_image:tutorial)から作成されるよう定義します。envセクションは環境変数を設定し、readinessProbeはサービスのヘルスチェックに使われる設定です。 -
endpoints: サービスのエンドポイントを定義します。ここでは
echoendpointという名前のエンドポイントがポート8000で公開されています。チュートリアルでは、TCP ネットワーク ポートの名前のリストを指定して、public: trueによってPublic endpointを作成しています。
サービス関数の作成
サービスと通信するためのサービス関数を作成していきます。サービス関数は、サービスとの通信に使用できる方法の1つです。サービス エンドポイントに関連付けるユーザー定義関数 (UDF) になります。サービス関数が実行されると、サービス エンドポイントにリクエストが送信され、応答が受信されます。
サービス関数を作成していきます。下記コマンドを実行してください。
CREATE FUNCTION my_echo_udf (text varchar)
RETURNS varchar
SERVICE=echo_service
ENDPOINT=echoendpoint
AS '/echo';
- SERVICE プロパティは、UDF を
echo_serviceサービスに関連付けます。 - ENDPOINT プロパティは、UDF を
echoendpointサービス内のエンドポイントに関連付けます。 - AS '/echo' は、Echo サーバーへの HTTP パスを指定します。このパスはサービス コード (
echo_service.py) で見つけることができます。
サービスを利用する
それでは実際に作成したサービスを利用してみましょう。サービス関数の使用ではクエリで呼び出すことができます。サンプルのサービス関数 (my_echo_udf) は、単一の文字列または文字列のリストを入力として受け取ることができます。
SELECT my_echo_udf('hello!');
Snowflake は、POST リクエストをサービス エンドポイント ( echoendpoint) に送信します。リクエストを受信すると、サービスは応答内の入力文字列をエコーします。
+--------------------------+
| **MY_ECHO_UDF('HELLO!')**|
|------------------------- |
| Bob said hello! |
+--------------------------+
文字列のリストをサービス関数に渡すと、Snowflake はこれらの入力文字列をバッチ化し、一連の POST リクエストをサービスに送信します。サービスがすべての文字列を処理した後、Snowflake は結果を結合して返します。次の例では、テーブル列を入力としてサービス関数に渡します。
次に複数の文字列を含むテーブルを作成して、サービス関数を呼び出します。テーブルの行を入力として渡して、SELECT ステートメントを実行します。
CREATE TABLE messages (message_text VARCHAR)AS (SELECT * FROM (VALUES ('Thank you'), ('Hello'), ('Hello World')));
SELECT my_echo_udf(message_text) FROM messages;
以下のような結果が返ってきたら成功です!
+---------------------------+
| MY_ECHO_UDF(MESSAGE_TEXT) |
|---------------------------|
| Bob said Thank you |
| Bob said Hello |
| Bob said Hello World |
+---------------------------+
web browser経由で利用する方法
サービスはエンドポイントをパブリックに公開する機能を持っていることは先程解説いたしました。そのためサービスがインターネットに公開する Web UI にログインし、Web ブラウザからサービスにリクエストを送信することができます。
DESCRIBE SERVICE コマンドで サービスが公開するパブリック エンドポイントの URLを見つけます。
DESCRIBE SERVICE echo_service;
本来ならばここでpublic_endpoints列が返ってきて、下記のようなエンドポイントが確認できるのですが、私の環境ではpublic_endpointsが確認できませんでした。こちらはsnowflake社に問い合わせ中です。
({"echoendpoint":"asdfg-myorg-myacct.snowflakecomputing.app"})
(追記)
snowvillageのslackにてchatworkのみっつさんより、snowflake内部で動くk8sの仕様であることをおしえていただきました!
active-nodeがすぐに確保出来なかったから、表示されない状態になる可能性があるようです。compute-poolはすぐ起動して処理できるワケではなくactive-nodeを確保して動き始めるので、この場合、active-nodeが確保してからSERVICEが動く事になるので、その段階にならないとendポイントも作られず表示されないとのことです!
また、KDDIのsakatokuさんより、エンドポイントを確認する専用コマンドがあることをおしえていただきました!
SHOW ENDPOINTS IN SERVICE echo_service;
なにか壁に当たったときに皆で一緒に問題を議論できるのはコミュニティのいいところですね〜
私がこちらを叩いたところ以下の表示になっていたので、数分待ってみると無事エンドポイントが確認できるようになりました。
「Endpoints provisioning in progress... check back in a few minutes」
というわけで引き続き「web browser経由で利用する方法」をやっていきます。
ingress_url列に表示されたエンドポイントに「/ui」をつけてbrowserよりアクセスしてみます。
https://[ingress_url列に表示されたエンドポイント]/ui
アクセスできました!!初回はログインを要求されるので、snowflakeアカウントにログインするときのlogin_nameとpasswordを入れてください。
UIが表示されました!

様々な文字列をinputに入力すると、同期的にoutputに返してくれます...!これは夢が広がりますね...!

ここまでがTutorial 1になります。
Tutorial 2と3はJob機能を使用していきますが、2023年12月現在では PrPrですので、またの機会に紹介していきたいと思います。ドキュメントを読むだけでも夢が広がる機能なので、楽しみに待っていたいですね。
コンピューティング プールの削除
アクティブなコンピューティングプールノードに対して料金が発生しますので、Tutorial 2, 3をやらない方は不要な料金が発生しないようにコンピューティング プール ノードを削除していきます。
まず、コンピューティング プールで現在実行されているすべてのサービスを停止します。次に、コンピューティング プールを一時停止するか (後で再度使用する場合)、削除します。
コンピューティング プール上のすべてのサービスとジョブを停止します。
ALTER COMPUTE POOL tutorial_compute_pool STOP ALL;
コンピューティング プールを削除します。
DROP COMPUTE POOL tutorial_compute_pool;
イメージ レジストリ (すべてのイメージを削除) や内部ステージ (仕様を削除) をクリーンアップすることもできます。
DROP IMAGE REPOSITORY tutorial_repository;
DROP STAGE tutorial_stage;
Snowpark Container Serviceのコンテナ費用
snowpark container service の費用はこちらにまとまっています。Snowpark Container Serviceのコンテナ費用は「保管コスト」、「コンピューティングプールのコスト」、「データ転送コスト」の3つがかかります。
保管コスト
Snowpark Container Services を使用する場合、Snowflake ステージの使用量やデータベース テーブル ストレージのコストを含む、Snowflake に関連するストレージ コストが適用されます。
- イメージリポジトリのストレージコスト: イメージリポジトリにはSnowflakeステージを使用します。そのため、Snowflakeステージの利用に関連するコストが発生します。
- ログストレージコスト: ローカルコンテナーログをイベントテーブルに保存する場合、イベントテーブルストレージのコストが適用されます。
-
ボリュームマウントのコスト:
- Snowflakeステージをボリュームとしてマウントする際は、Snowflakeステージの使用によるコストが発生します。
- コンピューティングプールノードからストレージをボリュームとしてマウントする場合、そのストレージはコンテナー内のローカルストレージとして扱われます。こちらの場合、ローカルストレージのコストはコンピューティングプールノードのコストに含まれるため、追加のコストは発生しません。
コンピューティングプールのコスト
コンピューティングプールのコストはコンピューティング プール内のノードの数とインスタンス ファミリータイプ(「CREATE COMPUTE POOL 」を参照) によって、消費されるクレジットが決まり、したがって支払うコストが決まります。
CreditConsumptionTable.pdfとcreate-compute-poolを参照すればコスト見積もりが可能です。

| Mapping | INSTANCE_FAMILY | vCPU | Memory (GiB) | Storage (GiB) | GPU | GPU Memory (GiB) | Description |
|---|---|---|---|---|---|---|---|
| CPU / XS | CPU_X64_XS | 2 | 8 | 250 | 該当なし | 該当なし | Snowpark コンテナで利用可能な最小のインスタンス。コスト削減や入門に最適です。 |
| CPU / S | CPU_X64_S | 4 | 16 | 250 | 該当なし | 該当なし | コストを節約しながら複数のサービス/ジョブをホストするのに最適です。 |
| CPU / M | CPU_X64_M | 8 | 32 | 250 | 該当なし | 該当なし | フルスタック アプリケーションまたは複数のサービスを使用する場合に最適 |
| CPU / L | CPU_X64_L | 32 | 128 | 250 | 該当なし | 該当なし | 異常に大量の CPU、メモリ、ストレージを必要とするアプリケーション向け。 |
| ハイメモリCPU / S | HIGHMEM_X64_S | 8 | 64 | 250 | 該当なし | 該当なし | メモリを大量に使用するアプリケーション向け。 |
| ハイメモリCPU / M | HIGHMEM_X64_M | 32 | 256 | 250 | 該当なし | 該当なし | 単一マシン上で複数のメモリ集中型アプリケーションをホストする場合。 |
| ハイメモリCPU / L | HIGHMEM_X64_L | 128 | 1024 | 250 | 該当なし | 該当なし | 大規模なメモリ内データの処理に利用できる最大の高メモリ マシン。 |
| GPU / S | GPU_NV_S | 8 | 32 | 250 | 1 NVIDIA A10G | 24 | Snowpark Container を開始するために利用できる最小の NVIDIA GPU サイズ。 |
| GPU / M | GPU_NV_M | 48 | 192 | 250 | 4 NVIDIA A10G | 24 | コンピューター ビジョンや LLM/VLM などの集中的な GPU 使用シナリオ向けに最適化 |
| GPU / L | GPU_NV_L | 96 | 1152 | 250 | 8 NVIDIA A100 | 40 | LLM やクラスタリングなどの特殊かつ高度な GPU ケース向けの最大の GPU インスタンス。 |
コンピューティング プールが IDLE、ACTIVE、STOPPING、RESIZING 状態の場合は料金が発生しますが、STARTING または SUSPENDED 状態の場合は料金が発生しません。(コンピューティングプールのリソース状態は「コンピューティング プールのライフサイクル」の項目を参照)
またAzureだけですが、GPU_NV_XSなどGPUインスタンスがより細かく選択できるようになっています。
| Mapping | INSTANCE_FAMILY | vCPU | Memory (GiB) | Storage (GiB) | GPU | GPU Memory (GiB) | Description |
|---|---|---|---|---|---|---|---|
| GPU_NV_XS (Azure) | GPU_NV_XS | 3 | 26 | 100 | 1 NVIDIA T4 | 16 | Our smallest Azure NVIDIA GPU size available for Snowpark Containers to get started. |
| GPU_NV_SM (Azure) | GPU_NV_SM | 32 | 424 | 100 | 1 NVIDIA A10 | 24 | A smaller Azure NVIDIA GPU size available for Snowpark Containers to get started. |
| GPU_NV_2M (Azure) | GPU_NV_2M | 68 | 858 | 100 | 2 NVIDIA A10 | 24 | Optimized for intensive GPU usage scenarios like Computer Vision or LLMs/VLMs |
| GPU_NV_3M (Azure) | GPU_NV_3M | 44 | 424 | 100 | 1 NVIDIA A100 | 80 | Optimized for memory-intensive GPU usage scenarios like Computer Vision or LLMs/VLMs |
| GPU_NV_SL (Azure) | GPU_NV_SL | 92 | 858 | 100 | 4 NVIDIA A100 | 80 | Largest GPU instance for specialized and advanced GPU cases like LLMs and Clustering etc. |
参考:https://docs.snowflake.com/en/sql-reference/sql/create-compute-pool#required-parameters
データ転送コスト
データ転送は、Snowflake にデータを移動 (入力) し、Snowflake からデータを移動 (出力) するプロセスです。
アウトバウンドデータ転送
- Snowflakeは、サービスやジョブから他のクラウドリージョンやインターネットへのアウトバウンドデータ転送に対して、標準のデータ転送レートを適用します。
Cross-AZデータ転送
- Cross-AZデータ転送は、Snowflake内の異なるコンピューティングエンティティ間(例えば、異なるコンピューティングプール間、またはコンピューティングプールとウェアハウス間)でのデータ移動を指します。
- 現在、SnowflakeではCross-AZデータ転送に対しては課金していませんが、将来的に課金を開始する予定です。
要するに、Snowflakeでデータを他のクラウドリージョンやインターネットに送ったり、Snowflake内の異なるコンピューティングプール間にデータを移動させたりすると、コストがかかります。
Snowpark Container Serviceが作るデータエンジニアリングの未来
Snowpark Container Serviceにより、データエンジニアリングの未来が一層豊かなものとなることは間違いありません。このサービスは、従来のデータ基盤開発の枠を超えて、データアプリケーションの開発領域を拡大しています。データエンジニアはこれまで、データ基盤の構築と維持に重点を置いてきましたが、Snowpark Container Serviceの登場により、私達の役割はより多岐にわたるものとなります。具体的には、Snowflakeをバックエンドとして利用することにより、データエンジニアはアプリケーション開発にも深く関与できるようになります。これには、Snowflake上でのエンドポイントの作成やAPI定義書の作成などが含まれるでしょう。また、Snowpark CortexのようなLLM(Language Learning Models)の実装にも携わることができるようになり、データエンジニアの担当範囲はこれまで以上に広がります。
データエンジニアが単にデータを管理し分析するだけでなく、データを活用したアプリケーションの開発においても主要な役割を担うようになるような気がしています。Snowpark Container Serviceは、データを活かしてさらなるアプリケーション開発の領域へ押し上げる可能性を秘めているのかもしれません。
終わりに
snowflakeはどんどん進化していきますね。我々データエンジニアもsnowflakeの進化に遅れを取らないように、知識のアップデートを進める必要があると感じました。SPCSはsnowflakeをアプリケーション開発に利用している弊社にとっては大変ありがたい機能です。早く東京リージョンでのGAが待ち遠しいですね。今後、使い倒していこうと思います。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion