Open4
GKE Dataplane V2 についてまとめてみる
ピン留めされたアイテム
ネットワークポリシーについて
- ネットワーク ポリシー ロギングを使用する
- ネットワーク ポリシーが予期したとおり機能していることを確認
- クラスタ内のどの Pod がインターネットと通信しているかを把握
- 互いに通信している Namespace を把握
- サービス拒否攻撃を認識
Cloud Logging が有効になっている場合、ネットワーク ポリシーのログは Cloud Logging にアップロードされて保存され、検索、分析、アラートに使用されます。新しいクラスタでは、Cloud Logging がデフォルトで有効になります。詳細については、GKE 用 Cloud Operations サポートのインストールをご覧ください。
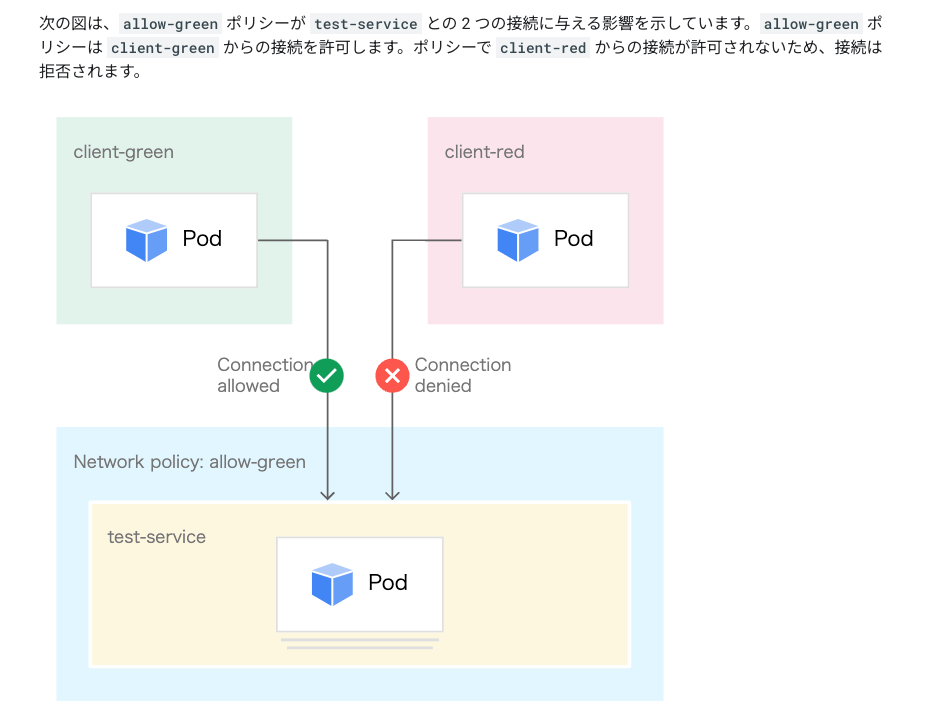
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-green
namespace: default
annotations:
policy.network.gke.io/enable-logging: "true"
spec:
podSelector:
matchLabels:
app: test-service
ingress:
- from:
- podSelector:
matchLabels:
app: client-green
policyTypes:
- Ingress
Dataplane V2 Observability について
Dataplane V2 Metrics を取得可能
- トラフィックフロー:GKE が Pod と Service の間のフローを処理する方法に関する分析情報
- ネットワーク ポリシーの適用:GKE が Kubernetes ネットワーク ポリシーを適用する方法に関する情報
Dataplane V2 Metrics の収集/可視化
- Google Cloud Managed Service for Prometheus: GKE Dataplane V2 の指標を表示、分析
- Google Cloud Managed Service for Prometheus の構成を変更して、Google Cloud Managed Service for Prometheus の取り込みに関する任意の指標を追加または削除できる
- Cloud Monitoring Metrics Explorer: Pod レベルのトラフィック フローの詳細を表示
- Cloud Operations for GKE: アラートなど、指標に Cloud Monitoring 内のツールを使用
- GKE Dataplane V2 の指標が特定のしきい値を超えた場合にトリガーされるアラートを作成できる
- セルフマネージド Grafana: Google Cloud Managed Service for Prometheus によって収集された指標を可視化
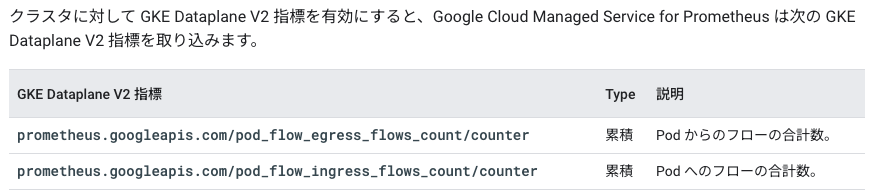
Metrics の追加
- デフォルトで GMP で使用できる指標は下記
- Hubble によって指標の追加が可能
- GMP はデフォルトでは使用できないがカスタムリソースによって取得可能

提供される Hubble ソリューション
- Relay と CLI が自動でデプロイ?
- UI は手動でデプロイ?

Dataplane V2 Observability & Metrics の仕組み
- Dataplane V2:eBPF に基づいて Dataplane V2 のデータパスを使用して特定のワークロードに基づいて Pod のトラフィックフローとネットワークポリシーの適用に関する指標を収集
- Google Cloud Managed Service for Prometheus: GKE Dataplane V2 の指標により、集約された指標を Google Cloud Managed Service for Prometheus に取り込むように Google Cloud Managed Service for Prometheus エージェントが構成
⇒ 大量のデータを取り込み、保存できる拡張可能なモニタリング ソリューションで、Google Cloud のオペレーション スイートも活用可能 - Hubble: GKE Dataplane V2 Observability は、オープンソースのオブザーバビリティ プロジェクトである Hubble を使用
- eBPF Dataplane でデプロイされた Kubernetes ワークロードのネットワーク オブザーバビリティとセキュリティ分析情報を有効
- Hubble 指標: 使用できる Kubernetes クラスタ内のフローイベントの数をカウントすることで、相互に通信している Pod を識別
- 指標とオブザーバビリティの有効化: GKE Dataplane V2 とオブザーバビリティを個別に有効、オープンソースの Hubble UI 機能でネットワーク トポロジの可視化を有効にするにはネットワーク検査を有効にする必要あり
料金
GKE Dataplane V2 のオブザーバビリティは有料の機能であり、一般提供(GA)まで無料で利用可能
- GKE Dataplane V2 の指標: GKE Dataplane V2 の指標はクラスタレベルで有効になり無料で有効可能、GKE Dataplane V2 の指標は、Google Cloud Managed Service for Prometheus に取り込まれるように構成されていますが、このサービスには独自の取り込み費用がある
- GKE Dataplane V2 Observability Tool: GKE Dataplane V2 Observability はクラスタレベルで有効になり 1 時間あたり Pod ごとに課金される、GKE Dataplane V2 Observability には GKE クラスタのモニタリングとトラブルシューティングのための UI とオブザーバビリティ ツールが含まれる
有効化するコマンド
既存のクラスタで有効化
# Metrics
gcloud container clusters update cdktf-gke-cluster \
--enable-dataplane-v2-metrics \
--location=asia-notheast1
# Observability Tool
gcloud container clusters update cdktf-gke-cluster \
--dataplane-v2-observability-mode=INTERNAL_VPC_LB \
--location=asia-northeast1
⇒ deployment/hubble-relay がデプロイされる
# deployment/hubble-relay の状態確認/監視
kubectl exec -it -n kube-system deployment/hubble-relay -c hubble-cli -- hubble status
kubectl exec -it -n kube-system deployment/hubble-relay -c hubble-cli -- hubble observe
Hubble UI の利用
- トラフィックフローの可視化や正常にルーティングされているかがわかりそう

GKE Dataplane V2 の仕組み:eBPF & Cillium
Kubernetes ネットワーク基礎
- kubelet:Pod の起動停止、死活監視
- CNI(Container Network Interface) plugin:Pod の IP アドレス管理
- kube-proxy:Service の検出とネットワークルールの更新
Service Mesh
- モニタリングやロギング、プロキシなどアプリケーションに共通する関心ごとを効率的に実装するためのコンポーネント
- サイドカーコンテナとしてデプロイされてワークする
eBPF
- Extended Berkeley Packet Filter の略
- プログラムを Linux カーネル上で動作させることが可能
- 特定の sycall や NIC へのパケット到達といったイベントをトリガーに実行することが可能
- カーネル空間とユーザー空間での切り替えにかかるオーバーヘッドを削減することができる
- 基本的にはユーザー空間でアプリケーションは実行されるが I/O はオーバーヘッドがかかる
Cilium
- スリーアムと読む
- アプリケーション間の接続や透過的に保護・モニタリングすることができるソフトウェアで CNI Plugins と Service Mesh の側面を持っている
- eBPF という Linux カーネルの機能を利用している
特徴①:ネットーワーキング
- Cilium を利用しない:Service が公開されると kube-proxy が Service を管理していて、iptables に Service と内部 IP を紐づけてくれる
⇒ 公開サービスが多かったり参照が多いと iptables に負荷がかかりネックになる - Cilium を利用する:kube-proxy を利用せず Cilium が Service を管理する、つまり iptables を利用せずに負荷分散を行うことで効率的に処理していることにメリットがある
特徴②:Service Mesh
- Pod ごとのサイドカーモデルからサイドカーフリーモデルへ
⇒ Pod がシンプルになりコンテナがへることによって起動時間も改善、ユーザ空間とカーネル空間の切り替えにかかるオーバーヘッドを軽減
⇒ サイドカーモデル = Pod ごとに Envoy-proxy が必要、サイドカーフリーモデル = Node ごとに Envoy-proxy が必要
⇒ 性能差は多少あるものの構成がシンプルになることにメリットがある
特徴③:ネットワークポリシー
- L3 / L4 での制御に加えて、FQDN や L7 での制限が可能
特徴④:IPSec による透過的暗号化
- IPSec によって Pod 間の通信を透過的に暗号化
- Istio でも mTLS でやってくれる
特徴⑤:Hubble によるモニタリング
- Cilium 上で動作するネットワークを可視化するソフトウェア
- L3 / L4 / L7 の可視化が可能
- サイドカーなしでサービスマップやトラフィックを参照することが可能
Prometheus との連携
- Cilium, Hubble のメトリクスを Prometheus にて収集が可能
- Grafana で可視化することで L4 / L7 のメトリクス参照が可能
GKE Dataplane V2
- Calico から Cilium へ
- Standard は選択可能、Autopilot は強制
- NetworkPolicy での許可 or 拒否を Cloud Logging に出力
ユースケース
- 大規模なワークロードで低い霊天使を追求する必要があるケース
- サービスメッシュをモニタリングやセキュリティ目的で導入されている、または導入したいと考えている
⇒ マイクロサービスのトラフィックを管理するような機能は現時点では Istio の方が多く、実装しやすいためこれらの機能が必要な場合は Istio の方が管理しやすい