GKE で手間をかけずに Let's オブザーバビリティ!-前編-
運用している GKE 上のアプリケーションでバグが発生すると、解析するのログをひたすら眺めるデバッグ大会が最近よく開催され、アプリケーションに詳しい人物がいるとログの範囲を絞っていき原因を発見することができるのですが、自分のように最近ジョインした人間からするとこの絞り込みすらままなりません。
これはデバッグの負担が偏る話でもありますし、バグの発生地点の切り分けがしづらいという点でも運用のあるべき姿ではないと思いオブザーバビリティに注目したいと考えました!
今回は極力手間をかけずに仕組みを構築するという点にフォーカスしながら GKE の監視/可視化周りに関する手段について調査しました。

こちらの前編では概要と Google Cloud Managed Service for Prometheus を中心に、後編では Fluentbit, Grafana, Hubble UI について記載します。
GKE で手間をかけずに Let's オブザーバビリティ! - 後編 -
Overview
GKE の監視/可視化の手法について検証
-
Google Cloud Managed Service for Prometheus + Fluentbit + Grafana + Hubble UI で極力手間をかけずに監視/可視化の仕組みを実現できました
-
Google Cloud Managed Service for Prometheus と Fluentbit は設定をオンにすることで自動でデプロイされます(Standard と Autopilot で多少異なります)
-
可視化のための Prometheus UI ・ Grafana ・ Hubble UI の追加のデプロイも比較的簡単で、各種連携も労力少なくできました
-
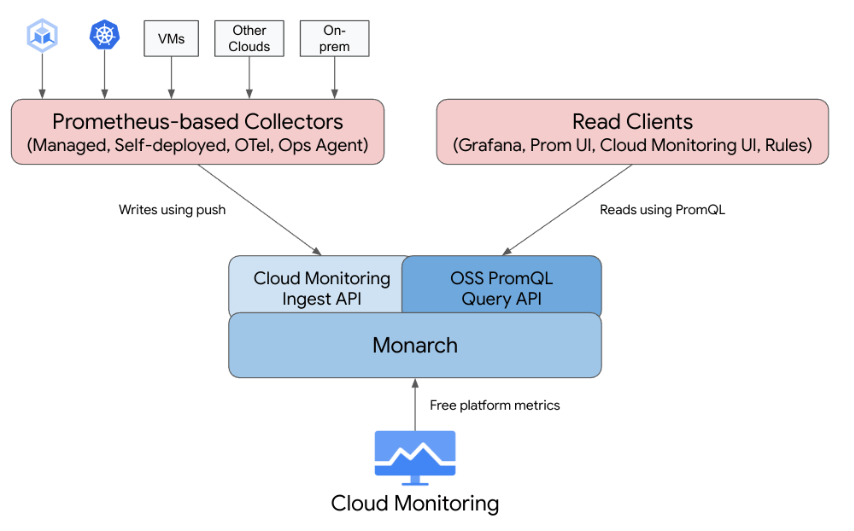
Google Cloud Managed Service for Prometheus には複数のデータ収集方法があり、管理コストと収集できるメトリクスのトレードオフで選択可能となっていました
所感
監視/可視化の手法は様々な選択肢があると思いますが、初手は作り込みすぎずマネージドなものを中心に仕組みを構築できればと思い調べ始めましたが、思いの外多くの機能が用意されていて驚きました。 一方で公式ドキュメントは機能が追加されていったこともあり、異なる項目に関連事項が入ってたりして読みづらさも感じました。
今回のテーマに関連しているものがどこかに体系的にまとまっていたら嬉しいなという思いもあり、こちらと次の記事でまとめたいと思いました。どなたかの役に立てたなら幸いです!
キーワード
- GKE Dataplane V2(公式ドキュメント)
- Google Cloud Managed Service for Prometheus(公式ドキュメント)
- GKE Dataplane V2 Observability(公式ドキュメント)
検証環境の準備
GKE のプロビジョニング
GKE は Standard でも Autopilot でも今回は関係ないので、Standard とします。ポイントとなるのが、オブザーバビリティに関連する 4 つのオプションです。
# GKE Standard クラスタを構築
gcloud container clusters create sample-cluster \
--enable-dataplane-v2 \
--enable-dataplane-v2-metrics \
--enable-managed-prometheus \
--dataplane-v2-observability-mode=INTERNAL_VPC_LB \
--location asia-northeast1-a
-
--enable-dataplane-v2: GKE Dataplane V2 を有効化 -
--enable-managed-prometheus: Google Cloud Managed Service for Prometheus を有効化 -
--enable-dataplane-v2-metrics: GKE Dataplane V2 Metrics を有効化 -
--dataplane-v2-observability-mode=...:GKE Dataplane V2 Observability Tool を有効化
1. GKE Dataplane V2
GKE のネットワークに Cilium と eBPF を使用して実装されます。従来のパケットルーティングがこれらによって効率的に処理することができ、ネットワーキングに関してスケーラビリティやより高いセキュリティを獲得することができます。(参考)

コンソール画面ではこちらが有効化されます。余談ですが従来のネットワーキングには Calico が利用されており、この設定で Cilium が利用されることから Calico は無効化されてるみたいです。

2. Google Cloud Managed Service for Prometheus(GMP)
その名の通りでマネージドの Prometheus が利用可能です。4 つのモードが存在していて、それぞれで管理コストと収集できるメトリクスが異なってくるようです。(参考)
- マネージドデータ収集
- セルフデプロイのデータ収集
- OpenTelemetry Collector
- Ops エージェント
今回は手間をかけずにがポイントなのでマネージドデータ収集のモードを利用します。詳細は後述します。
コンソール画面ではこちらが有効化されます。

3. GKE Dataplane V2 Metrics
GKE Dataplane V2 Observability が Preview になったことで利用可能となった機能です。この機能では下記のトラフィック情報を提供してくれます。(参考)
- トラフィック フロー: GKE が Pod と Service の間のフローを処理する方法に関する分析情報。
- ネットワーク ポリシーの適用: GKE が Kubernetes ネットワーク ポリシーを適用する方法に関する情報。
これらの情報は GMP や Cloud Monitoring でメトリクスを確認することができます。デフォルトでは下記のメトリクスを収集可能です。

4. GKE Dataplane V2 Observability Tool
こちらも Metrics 同様に GKE Dataplane V2 Observability が Preiview になったことで利用可能となった機能です。
利用方法は後述しますが、GKE のプロビジョニングと同時に下記の Hubble に関連するリソースがデプロイされます。(参考)
$ kubectl get po -n kube-system | grep hubble
NAME READY STATUS RESTARTS AGE
hubble-generate-certs-init-lgslx 0/1 Completed 0 7d14h
hubble-relay-66859b686c-dz8m5 2/2 Running 0 7d14h
これらのリソースに加えて、Hubble-UI コンポーネントをデプロイするとトラフィックフローを簡単に可視化することができます!
サンプルアプリのデプロイ
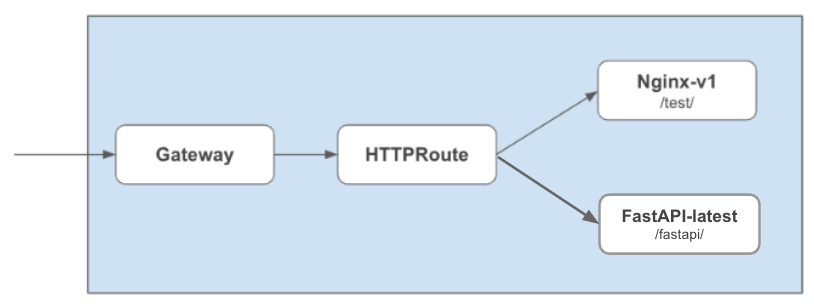
前回のGKE Gateway Controller でサービスネットワーキング で利用した Nginx のアプリを利用します。
加えて、Fast API で実装した簡易アプリもデプロイしておきます。
Dockerfile
FROM python:3
USER root
RUN mkdir /src
RUN mkdir /src/app
COPY ./main.py /src/app/main.py
COPY ./requirements.txt /src/requirements.txt
RUN pip3 install --upgrade pip
RUN pip3 install -r /src/requirements.txt
WORKDIR /src/app
ENTRYPOINT ["uvicorn", "main:app", "--host", "0.0.0.0", "--reload"]
main.py
from fastapi import FastAPI, status
import logging
logger = logging.getLogger('uvicorn')
app = FastAPI()
@app.get("/", status_code=status.HTTP_200_OK)
async def root():
logger.info('info-test')
return {"message": "Hello World"}
@app.get("/fastapi/", status_code=status.HTTP_200_OK)
async def test():
logger.info('info-test')
logger.warning('warning-test')
return {"message": "Hello World FastAPI"}
requirements.txt
fastapi
uvicorn
service-fastapi.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: fastapi-latest
namespace: sample
labels:
apps: fastapi-latest
spec:
replicas: 1
selector:
matchLabels:
app: fastapi-latest
template:
metadata:
labels:
app: fastapi-latest
spec:
containers:
- name: fastapi-latest
image: asia-northeast1-docker.pkg.dev/sample-project/sample/fastapi:latest
imagePullPolicy: Always
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: fastapi-latest
namespace: sample
annotations:
cloud.google.com/app-protocols: '{"my-http-port":"HTTP"}'
cloud.google.com/neg: '{"exposed_ports": {"80":{}}}'
spec:
selector:
app: fastapi-latest
type: ClusterIP
ports:
- name: my-http-port
port: 80
targetPort: 8000
httproute-fastapi.yaml
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
metadata:
name: fastapi-httproute
namespace: sample
spec:
parentRefs:
- kind: Gateway
name: sample-gateway
namespace: sample
# hostnames:
# - "*"
rules:
- matches:
- path:
value: /fastapi/
backendRefs:
- name: fastapi-latest
port: 80
Google Cloud Managed Service for Promethus(GMP)
マネージドのデータ収集モード(マネージドコレクション)の特徴は下記です。(公式ドキュメント抜粋)
- すべての Kubernetes 環境で Google が推奨するアプローチです。
- GKE UI、gcloud CLI、kubectl CLI、または Terraform を使用してデプロイします。
- スクレイピングとルールは、軽量のカスタム リソース(CR)を使用して構成されます。
- 簡単に使用できるフルマネージド環境が必要な場合に適しています。
- prometheus-operator 構成ファイルから簡単に移行できます。
- 現在の Prometheus のユースケースのほとんどに対応しています。
ということでより手間をかけずにという点においては良さそうです。マネージドコレクションでは Prometheus ベースのコレクタを Deamonset として実行して同一ノード上のデータを収集してくれます。
マネージドコレクションではノードのサービスアカウントの権限で Cloud Monitor に転送してくれるため Monitoring Metric Writer ロールの付与が必要です。
また、データについては追加料金なしに 24 ヶ月間保管されるようです。ありがたいですね。
ポイント① - 自動デプロイリソース -
--enable-managed-prometheus 有効化すると GKE プロビジョニング時に gmp-system という Namespace に下記のリソースがデプロイされています。(参考)
$ kubectl get po -n gmp-system
NAME READY STATUS RESTARTS AGE
alertmanager-0 2/2 Running 0 43m
collector-8rz8j 2/2 Running 0 41m
collector-qqcrv 2/2 Running 0 41m
collector-wrlnv 2/2 Running 0 41m
gmp-operator-859cf8894c-rls2k 1/1 Running 0 43m
rule-evaluator-7c9848c877-wkgt5 2/2 Running 1 (41m ago) 41m
gmp-operator: Deployment : Google Cloud Managed Service for Prometheus の Kubernetes オペレーターrule-evaluator: Deployment : アラートルールと記録ルールの構成と実行に使用collector: DaemonSet : 各コレクタと同じノードで実行されている Pod からの指標のみを取得し、コレクションを水平にスケーリングalertmanager: StatefulSet : トリガーされたアラートを推奨通知チャネルに送信するように構成
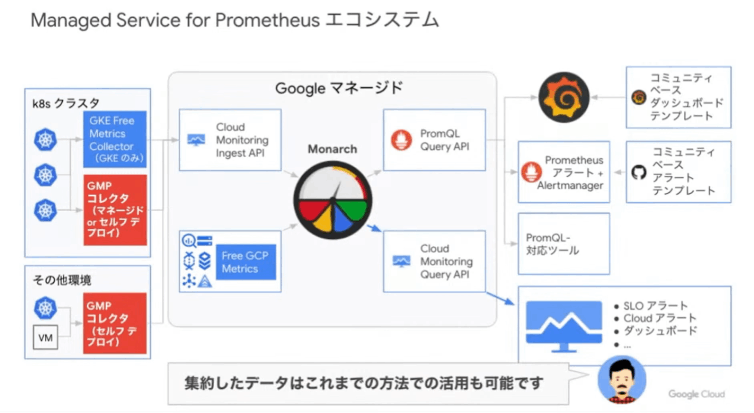
こちらの図をみるとマネージドコレクションは Cloud Monitoring の Ingest API を経由して Monarch に集約されて PromQL Query API や Cloud monitoring Query API で取得できるようになっていますね。 Google Cloud のメトリクスも Monarch に集約されていることから Prometheus でも取得できると!勉強になりました。
ポイント② - Prometheus UI -
この GMP ですがデプロイされたリソースと合わせて PodMonitoring カスタムリソースなるものを使用して、コンテナのデータを収集をするようです。
$ kubectl get podmonitoring -A
NAMESPACE NAME AGE
kube-system advanced-datapath-observability-metrics 7d16h
私の Standard 環境では Kube-system にインストールされていることを確認しました。実際にメトリクスを収集できているかを確認するために Prometheus UI をデプロイします。(Cloud Monitoring でも確認できますが、次の記事にまとめる Grafana での認証プロキシとしても必要となるためデプロイします)
マニフェストはこちらです。名称あたりを適当に変更して port-forward でアクセスします。
prometheus-ui.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-ui
spec:
replicas: 2
selector:
matchLabels:
app: prometheus-ui
template:
metadata:
labels:
app: prometheus-ui
spec:
automountServiceAccountToken: true
nodeSelector:
kubernetes.io/os: linux
kubernetes.io/arch: amd64
containers:
- name: prometheus-ui
image: gke.gcr.io/prometheus-engine/frontend:v0.7.0-gke.0
args:
- "--web.listen-address=:9090"
- "--query.project-id=$PROJECT_ID"
ports:
- name: web
containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: web
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- all
privileged: false
runAsGroup: 1000
runAsNonRoot: true
runAsUser: 1000
livenessProbe:
httpGet:
path: /-/healthy
port: web
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-ui
spec:
clusterIP: None
selector:
app: prometheus-ui
ports:
- name: web
port: 9090
$kubectl apply -f prometheus-ui.yaml
$kubectl port-forward -n gmp-system svc/prometheus-ui 9090
GKE Dataplane V2 Metrics で取得可能になった pod_flow_ingress_flows_count で検索してみると、 job="advanced-datapath-observability-metrics", location="asia-northeast1-a", namespace="kube-system" という表記があり、デプロイされている kube-system の advanced-datapath-observability-metrics という PodMonitoring リソースから取得できていることがわかります!!
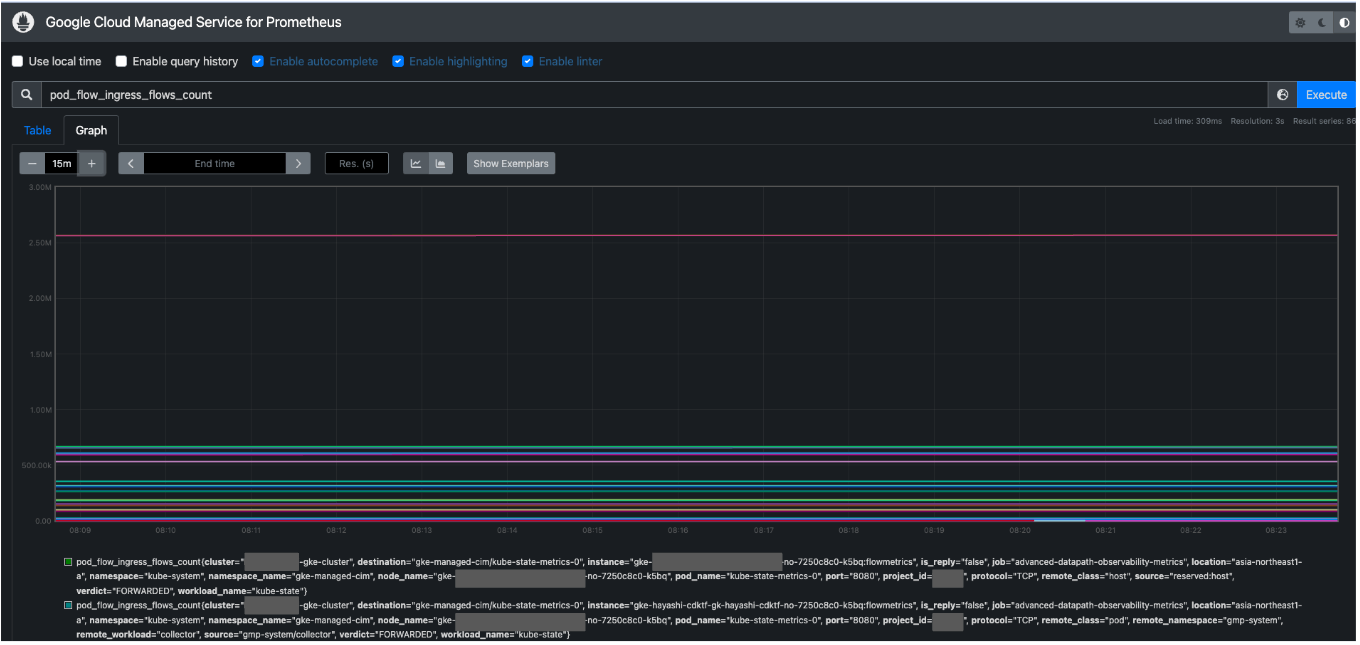
今回の場合は、kube-system の PodMontoring リソースが各 Namespace から Prometheus にメトリクスを転送しているようで、pod_flow_ingress_flows_count{namespace_name="sample"} で検索すると、sample に存在する Pod のメトリクスも確認できました。

また、Cloud Monitoring でも同様のメトリクスを確認することができます。
ポイント③ - ClusterPodMonitoring -
上記は Standard クラスタの話で、 Autopilot クラスタでは GMP を有効化しただけではメトリクスを取得することができません。下記の ClusterPodMonitoring リソースをデプロイする必要があるようです。(参考)
clusterpodmonitoring.yaml
apiVersion: monitoring.googleapis.com/v1
kind: ClusterPodMonitoring
metadata:
name: advanced-datapath-observability-metrics
spec:
selector:
matchLabels:
k8s-app: cilium
endpoints:
- port: flowmetrics
interval: 60s
metricRelabeling:
# only keep denormalized pod flow metrics
- sourceLabels: [__name__]
regex: 'pod_flow_(ingress|egress)_flows_count'
action: keep
# extract pod name
- sourceLabels: [__name__, destination]
regex: 'pod_flow_ingress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${2}'
targetLabel: pod_name
action: replace
- sourceLabels: [__name__, source]
regex: 'pod_flow_egress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${2}'
targetLabel: pod_name
action: replace
# extract workload name by removing 2 last "-XXX" parts
- sourceLabels: [pod_name]
regex: '([a-zA-Z0-9-\.]+)((-[a-zA-Z0-9\.]+){2})'
replacement: '${1}'
targetLabel: workload_name
action: replace
- sourceLabels: [pod_name]
regex: '([a-zA-Z0-9\.]+)((-[a-zA-Z0-9\.]+){1})'
replacement: '${1}'
targetLabel: workload_name
action: replace
# extract pod namespace
- sourceLabels: [__name__, destination]
regex: 'pod_flow_ingress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${1}'
targetLabel: namespace_name
action: replace
- sourceLabels: [__name__, source]
regex: 'pod_flow_egress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${1}'
targetLabel: namespace_name
action: replace
# extract remote workload name
- sourceLabels: [__name__, source]
regex: 'pod_flow_ingress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${2}'
targetLabel: remote_workload
action: replace
- sourceLabels: [__name__, destination]
regex: 'pod_flow_egress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${2}'
targetLabel: remote_workload
action: replace
# extract remote workload namespace
- sourceLabels: [__name__, source]
regex: 'pod_flow_ingress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${1}'
targetLabel: remote_namespace
action: replace
- sourceLabels: [__name__, destination]
regex: 'pod_flow_egress_flows_count;([a-zA-Z0-9-\.]+)/([a-zA-Z0-9-\.]+)'
replacement: '${1}'
targetLabel: remote_namespace
action: replace
# default remote workload class to "pod"
- replacement: 'pod'
targetLabel: remote_class
action: replace
# extract remote workload class from reserved identity
- sourceLabels: [__name__, source]
regex: 'pod_flow_ingress_flows_count;reserved:([^/]*)'
replacement: '${1}'
targetLabel: remote_class
action: replace
- sourceLabels: [__name__, destination]
regex: 'pod_flow_egress_flows_count;reserved:([^/]*)'
replacement: '${1}'
targetLabel: remote_class
action: replace
targetLabels:
metadata: []
こちらの ClusterPodMonitoring リソースと Collector が連携してメトリクスが取得可能になります。
まとめ
GKE で手間をかけずに監視/可視化の仕組みを手間なく構築するというテーマで、まずは Google Cloud Managed Service for Prometheus について調べてみました。
マネージドな Promethus ということで GKE のプロビジョニングに設定をオンにするだけで必要最低限のリソースがデプロイされて、すぐに利用可能な状態となっていました。
可視化では Cloud Monitoring か Promethus UI をデプロイするかということで、こちらも使い慣れているものを選択可能という点も良かったです。
参考記事
- Google Cloud Managed Service for Prometheus がパブリックプレビューになったので試してみた
- PromQL事始め
- 「Google Cloud Managed Service for Prometheus」について
さいごに
AWS と Google Cloud で構築したデータ基盤の開発・運用に携わっているデータエンジニアです。5 年くらい携わっていて、この業務がきっかけで Google Cloud が好きになりました。
現在は React のフロントエンジニアとして修行中です。
X では Google Cloud 関連の情報を発信をしています。
Discussion