Cloud Run の恩恵を受けている機能の紹介
2024 年 2 月 22 日に行われた 【Google Cloud】 GDG Tokyo Monthly Online Tech Talks に登壇させていただきました。
5 分枠だったので、こちらの記事で深掘りしたいポイントについてまとめようと思います。
感謝している Cloud Run の機能が気になる方はこちらからお読みください!
Google Cloud × Observability
短い尺だったので何か引きのあるトピックで話がしたいと思い、Google Cloud を利用する中で最近注力している Observability 領域との掛け合いということでこんな表現にしてみました。
なんで頑張りたいのか?
せっかく頑張りたいと伝えたので簡単に何がつらみなのかも話したいと思い、2 点挙げました。少ない時間でストーリー重視の話をすると、前段が多くて時間取られるなぁと少し反省するところでした。
アプリパフォーマンスのボトルネックを把握しづらい
今回は携わっているプロダクト(=WEBアプリケーション)の紹介も兼ねて聞き手が想像しやすい困りポイントを話せればと思って、1 点目はこちら。開発/運用しているアプリケーションはマイクロサービスで構築しています。そのため、リクエストという切り口でアプリケーションを見ようとすると複数のコンポーネントを行き来することでどの処理が走っているのか・どのくらい処理に時間がかかっているのかといった処理工程の詳細が把握しづらくなっています。
こちらが把握しづらいとパフォーマンス改善の糸口が見つけにくいというのが解決したいポイントです。日々、こういったパフォーマンス改善をすることで利用者に「快適な」体験をしてほしいと思っています。
バグ発生時に歴戦の戦士しか発生箇所を発見できない
2 点目は色々なプロダクトであるあるではないでしょうか?プロダクトに異常が発生した際にログを眺めるものの何か異常が起こっているのはわかるが原因はわからないといった情報不足なログが流れている。そして、そういったログからバグ発生原因に当たりをつけられるのは歴戦の戦士のみといった状況です。
特にコンポーネントが多く、複雑に入り組んでいるとログからだけでは発見は難しかったりするのではないでしょうか。その結果、原因の特定が遅れて利用者に迷惑をかけるケースが出てきてしまうというのが解決したいポイントです。誰でも迅速に原因を特定して利用者に「安定した」体験をしてほしいと思っています。
Observability の強化に挑戦したい
こういった課題に対して Site Reliability Engineering の一環として、より高度なモニタリングへ強化したいと考えました。
現状は異常があれば Logging に収集されるログを見たり、過去にバグが起因した指標にアラートを仕掛て slack に流すという程度の運用となっています。
今回の話はその Observability の強化の準備として基盤という形でテレメトリーを収集/可視化を目的としています。イベントテーマが【Google Cloud】 ということだったので、基盤でどう Google Cloud を活用しているかに最後スポットを当てています。
OpenTelemetry の導入
界隈が盛り上がっている(と思っている) OpenTelemetry を採用しようと考えています。こちらはチーム内の技術力の高いメンバーたっての希望で選択して、検証中です。
デプロイパターンは Gateway パターンとして Otel Collector 以降のツール群はアプリケーションから分離する形としています。今回は Google Cloud にスポットを当てるということで、こちらについてはまた別の機会に執筆しようと思います。
Google Cloud で構築
下記の 2 点を注力ポイントととして基盤の構築および活用にチャレンジしています。
- Otel Collector 以降を Cloud Run でホスティングする
- 「可視化ツールとしては Grafana を選択して Cloud Logging や Cloud Monitoring などの Cloud Operations と連携する」
ホスティングするサービスとして Cloud Run で選択したのは、自分自身触ってみたいけどちょっと難しそうと思ってたサービスをあえて触ってみる選択をしました。ドキュメントを読みユースケースが合っていそうなことを確認した上で採用してみた結果として、素晴らしいサービスであることがわかり今回の「Cloud Run に日々感謝」というタイトルに至りました。
Cloud Run の有能さに日々感謝
短い尺の中でも Cloud Run 関連の機能を伝えたいと思い、本 LT の大部分をこちらのスライドに費やしました。テキストだけだと伝わりづらい部分もあるため、本ブログでは補足を交えつつ紹介したいと思います。
Auto Scaling:Minimum Number of Instances = 0
1 つ目に紹介したのは、Cloud Run の特徴の 1 つでもある Cloud Run Service のゼロインスタンスへの自動スケーリングです。発表では割愛しましたが、サービスの従量課金制には料金モデルが 2 つあります。(下記の説明は公式ドキュメントの抜粋です。)
- リクエストベース
インスタンスがリクエストを処理していない場合、CPU は割り当てられず、課金もされません。リクエストごとの料金が発生します。
- インスタンスベース
インスタンスの全期間に対して課金され、CPU が常に割り当てられます。リクエストごとの料金は発生しません。
今回はリクエストベースの料金モデルを選択しているため、リクエストを捌いていない間は課金が発生せずにコストダウンが見込める形にできました。
具体的には Grafana などは運用のためにチームの開発者が閲覧する想定のため、リクエストが四六時中発生しているわけではありません。そのため、こちらの設定によるコストダウン効果は大きいと考えています。
参考
URL Mask
2 つ目は、Cloud Load Balancing とサーバーレス NEG との組み合わせで利用できる URL Mask 機能です。今回はサブドメインをサービス名でマスクする形を取りました。なので、Cloud Run Service をデプロイするたびに <サービス名>.operations.com でアクセスできるようになっています。
厄介なところでいうと、サブドメインをサービス名にしたことで URL ごと証明書が必要になる点です。この点は工夫したところで、Certificate Manager を用いてワイルドカード証明書を導入しました。その結果、URL ごとに必要な証明書が必要なくなり、一度設定すれば追加するリソースや設定が抑えられるので非常に便利になりました!
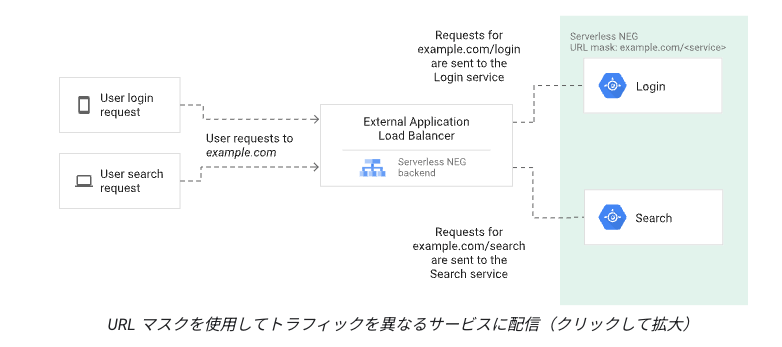
引用:https://cloud.google.com/load-balancing/docs/negs/serverless-neg-concepts?hl=ja#url_masks
参考
- URL マスク
- Cloud Certificate Manger による Wildcard Certificate を用いた Cloud Run の活用
- 爆誕予定のテレメトリー収集/可視化基盤を晒してみる
Mount a Cloud Storage Volume
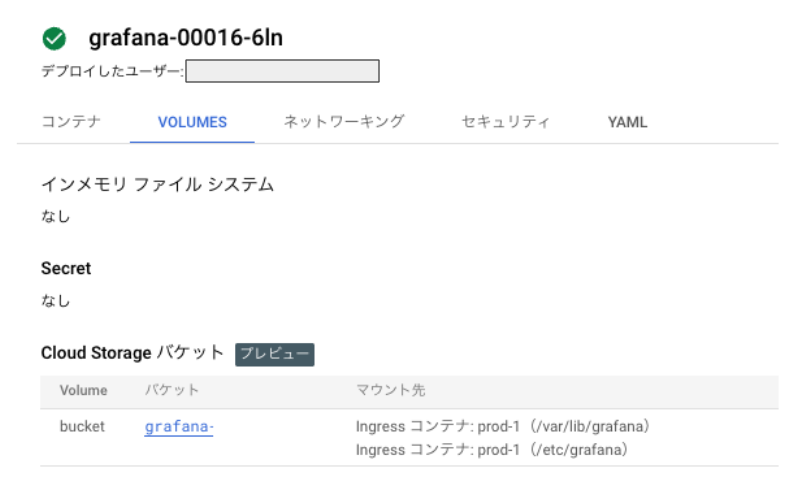
最後は、先日 Preview となった Cloud Run のボリュームマウントを使用して Cloud Storage バケットをストレージボリュームとしてマウントすることをネイティブとしてサポートした機能です。
ネイティブと言っているのは、以前まで Cloud Run Service で Cloud Storage バケットをマウントするには Cloud Storage FUSE を明示的にセットアップする必要があったところを Google Cloud 側で巻き取ってくれたからのようです。(下記の説明は公式ドキュメントの抜粋です。)
制限事項
Cloud Run は、このボリューム マウントに Cloud Storage FUSE を使用します。そのため、Cloud Storage バケットをボリュームとしてマウントする場合は、次の点に注意してください。
自分も Cloud Storage FUSE を一度試してみましたが、すんなり実装できずに頭を悩ませていたところをこちらの機能であっという間に実装できて非常に助かりました。今回は Grafana Loki や Grafana Tempo のログやトレースの保存どころとして使用しています。
参考
今後の展望
基盤の構築およびアプリケーションへのテレメトリ送出の実装を追加して Grafana で可視化するところ、特にアプリケーションメトリクスやシステムメトリクスのダッシュボード化やトレーシングとログの紐付けなどの準備を進めたいと思います。
実際に運用してみて得られた知見はまたこちらのブログで執筆します。
さいごに
GDG Tokyo Monthly Online Tech Talk では初めての登壇となり緊張もしましたが、運営の方の説明が丁寧で安心して登壇にのぞむことができました。
裏側で登壇者の知人とわちゃわちゃしながら楽しめたのも非常によかったです。また、機会があれば登壇してみたいと思います!!
Discussion