Vertex AI Experiments をコードから読み解いてみた
2024 年 11 月 25 日に行われた Jagu'e'r AI/ML 分科会 Meetup#8 に登壇させていただきました。
現在携わっているプロダクトで MLFlow を利用しているのですが、パフォーマンスが出づらかったりと課題が浮き彫りになったのでリプレイスを検討した話を入りに LT をさせていただきました。
ここでは、代替プロダクトとして Vertex AI Experiments(以降 VAE と略します、この記事内のみの略称と思ってください)が候補にあがったため調査した結果の一部をまとめていこうと思います。
資料の中で MLFlow と Vertex AI Experiments の互換性の検証を進め、MLFlow を扱う際の set_tags メソッドが置き換えづらいという課題に触れています。この記事では資料中に割愛したVAE を利用するために必要な Python ライブラリである google-cloud-aiplatform でどのような構造になっているかを読み解いたという点にフォーカスしています!
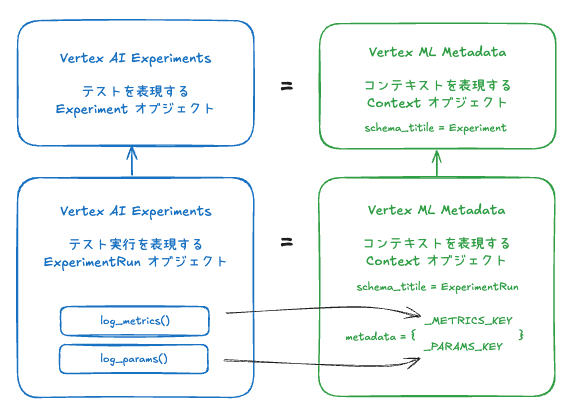
結論としては、Vertex AI Experiments のオブジェクトは Vertex ML Metadata のオブジェクトに紐づいていることがわかりました。つまり、Vertex AI Experiments は Vertex ML Metadata に記録されている情報が実験管理という観点で操作しやすくラップされているサービスであることと捉えることができそうです。
このことが登壇資料の中で大きな課題となっていた set_tags メソッドを代替する大きなヒントとなりました。
対象となる読者
- 分析における実験管理サービスに興味がある方
- Vertex AI Experiments の導入を検討されている方
Vertex AI Experiments とは?
まずは、VAE が何ものかという話ですが、データ分析における実験管理という文脈で重要となるサービスです。実験管理の目的は、実験 = モデルの評価状況を記録することで後から比較・モデル選定を可能とすることです。一般的に管理対象となるのは、下記の要素が挙げられるようです。
- コードバージョン
- どのようなコードで実験を行ったか
- データバージョン
- どのようなデータで学習・テストを行ったか
- ハイパーパラメータ
- ハイパーパラメータとして何を使用したか
- メトリクス
- 実験の結果、どのような結果が得られたか
- 環境
- 実際に動作したときのマシンとしてどのようなものを使用していたか
つまるところ、実験を再現するための情報とその結果の記録が主要な機能と言えそうです。また、VAE の概要については公式ドキュメントで下記のように記述されています。
Vertex AI Experiments は、さまざまなモデル アーキテクチャ、ハイパーパラメータ、トレーニング環境を追跡および分析し、テストの実行の手順、入力、出力を追跡する際に役立つツールです。Vertex AI Experiments では、テスト データセットに対して、トレーニングの実行中に、モデルの集計のパフォーマンスを評価することもできます。この情報を使用して、特定のユースケースに最適なモデルを選択できます。
公式ドキュメント - Vertex AI Experiments 概要
上述した一般的な要素に加えて実行順序や関連したオブジェクトの紐付けといったところも可能になっているようです。
次に Vertex AI Experiments を理解する上で主要な要素となるテスト、テスト実行、サマリー指標、パラメータをピックアップして説明します。
テスト
実験は管理する対象として一番大きな概念で、後述するテスト実行をグルーピングする存在です。
テストは、ユーザーが入力アーティファクトやハイパーパラメータなどのさまざまな構成をグループとして調査できるパイプライン実行に加えて、一連の n 個のテスト実行を含むことができるコンテキストです。
公式ドキュメント - Vertex AI Experiments の用語:テスト

テスト実行
テスト実行は実験に内包される形の実際のモデルの評価状況のレコードです。後述するサマリー指標やパラメータを保有しています。
テスト実行には、ユーザー定義の指標、パラメータ、実行、アーティファクト、Vertex リソース(たとえば、PipelineJob)を含めることができます。
公式ドキュメント - Vertex AI Experiments の用語:テスト実行
サマリー指標
テスト実行はいくつかの値を持つことができます、サマリー指標はその 1 つでメトリクスと言ったりします。記録する値としては、テスト実行ごとの精度などが想定されているようです。
サマリー指標はテスト実行の各指標キーの単一の値です。たとえば、テストのテスト精度は、トレーニング終了時にテスト データセットに対して計算された精度であり、単一の値のサマリー指標としてキャプチャできます。
公式ドキュメント - Vertex AI Experiments の用語:サマリー指標
コードベースでは log_metrics という関数で記録することができます。

パラメータ
こちらもサマリー指標同様にテスト実行に値を持たせることの一種です。名の通り、テスト実行ごとに変化させるパラメータを記録します。記録する値としては、学習率やドロップアウト率といったものが想定されているようです。
パラメータは、実行を構成し、実行の動作を調整して、実行の結果に影響を与えるキー付きの入力値です。例としては、学習率、ドロップアウト率、トレーニングの手順の数などがあります。
公式ドキュメント - Vertex AI Experiments の用語:パラメータ
コードベースでは log_params という関数で記録することができます。

Vertex ML Metadata とは?
Vertex AI Experiments を深掘る上で Vertex ML Metadata (以降 VMM と略します、この記事内のみの略称と思ってください)の存在が重要となるので、こちらも基本情報をまとめておきます。
サービス名の通りですが、Vertex AI で利用されるメタデータ全般を扱うものとなっています。公式ドキュメントでは、下記のような記述があります。
Vertex ML Metadata を使用すると、ML システムによって生成されたメタデータとアーティファクトを記録し、そのメタデータに対してクエリを実行できます。これにより、ML システムまたはアーティファクトの生成状況の分析、デバッグ、監査を行うことができます。
公式ドキュメント - Vertex ML Metadata の概要
こちらでは基本的な用語のうち、この後の関係性を深堀りする上で重要なのでコンテキストついてのみ解説を引用します。
コンテキスト
コンテキストは、アーティファクトと実行を単一のクエリ可能なタイプ付きカテゴリにグループ化するために使用されます。コンテキストを使用してメタデータのセットを表すことができます。コンテキストの例としては、機械学習パイプラインの実行があります。
公式ドキュメント - Vertex ML Metadata の用語:コンテキスト
関係性
ここから本題の Veretex AI Experiments と Vertex ML Metadata の関係性をコードで読み解いてみます。
Vertex AI などを Python から利用する時のライブラリである python-aiplatform のリポジトリとしてこちらを見ていきます。
__init__.py から始める
この aiplatform ライブラリを使う時には、初期化から始まります。
aiplatform.init(
project='my-project',
location='us-central1',
staging_bucket='gs://my_staging_bucket',
credentials=my_credentials,
encryption_spec_key_name=my_encryption_key_name,
experiment='my-experiment',
experiment_description='my experiment description'
)
init メソッド含めて利用可能な関数やオブジェクトが定義されているのが python-aiplatform/google/cloud/aiplatform/__init__.py です。
aiplatform ライブラリで実装を追う時には、このファイルからスタートすることになると思います。
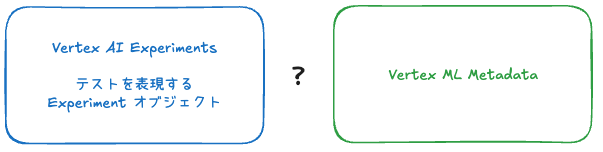
VAE のテストに注目
テストの作成は上記の init メソッドの中で experiment にテスト名を渡すことで作成されます。init メソッドの中を見ておくと、引数に応じて様々なセットアップが行われていることがわかります。
この中でも下記のテストに関わるコードに注目すると、metadata の何某が叩かれていることがわかります。
・・・
if experiment:
metadata._experiment_tracker.set_experiment(
experiment=experiment,
description=experiment_description,
backing_tensorboard=experiment_tensorboard,
)
・・・
さっそく python-aiplatform/google/cloud/aiplatform/metadata/metadata.py を見てみます。その中でも set_experiment メソッドを追っていきます。
ここで注目したいのがこちらの部分です。
・・・
experiment = experiment_resources.Experiment.get_or_create(
experiment_name=experiment,
description=description,
project=project,
location=location,
)
・・・
Experiment オブジェクトが持つ get_or_create メソッドに適切な引数を渡すことで Experiment
オブジェクトを生成しています。さらに python-aiplatform/google/cloud/aiplatform/metadata/experiment_resources.py 内にある Experiment オブジェクトの get_or_create メソッドを追います。
ここでとても重要なのが下記のコードです。急に Context オブジェクトが登場して get_or_create メソッドが叩かれています。
・・・
with _SetLoggerLevel(resource):
experiment_context = context.Context.get_or_create(
resource_id=experiment_name,
display_name=experiment_name,
description=description,
schema_title=constants.SYSTEM_EXPERIMENT,
schema_version=metadata._get_experiment_schema_version(),
metadata=constants.EXPERIMENT_METADATA,
project=project,
location=location,
credentials=credentials,
)
・・・
最初自分もこの Context オブジェクトが何者か検討がつかなかったのですが、この Context オブジェクトは文字通り Vertex ML Metadata のコンテキストという要素を表しているものでした。
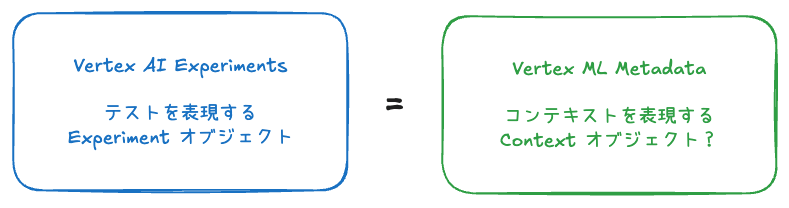
続けて、python-aiplatform/google/cloud/aiplatform/metadata/context.py内にある Context オブジェクトの _create メソッドも追ってみます。
詳細な中身はともかく返り値のデータ型から Context オブジェクトを返していることがわかります。実際に Context オブジェクトを生成部分をラップしているのは下記のコードです。
・・・
resource = cls._create_resource(
client=api_client,
parent=parent,
resource_id=resource_id,
schema_title=schema_title,
display_name=display_name,
schema_version=schema_version,
description=description,
metadata=metadata,
)
・・・
ようやくここで Context オブジェクトを生成するリクエストを投げているコードに辿り着きました。
リクエストを投げているであろうメソッドに渡している Context オブジェクトには気になる引数として、schema_title, metadata という 2 つがあります。ここらへんが Vertex AI Experiments の Experiment オブジェクトが Vertex ML Metadata の Context オブジェクトとの関係をさらに紐解くキーワードになりそうです。
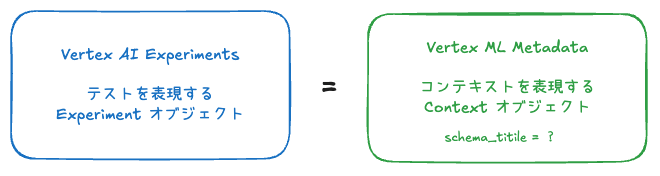
Context オブジェクトの深掘り
Context オブジェクトの create メソッドを見ると schema_title は下記のような説明になっています。
・・・
"""Creates a new Metadata Context.
Args:
schema_title (str):
Required. schema_title identifies the schema title used by the Context.
Please reference https://cloud.google.com/vertex-ai/docs/ml-metadata/system-schemas.
・・・
リファレンスページに飛ぶとシステムスキーマの公式ドキュメントでした。システムスキーマの説明があったので引用します。
各メタデータ リソースは、特定の MetadataSchema に関連付けられます。メタデータ リソースの作成プロセスを簡素化するために、Vertex ML Metadata では、一般的な ML のコンセプトに対応するシステム スキーマという事前定義のタイプを公開しています。システム スキーマは名前空間 system に存在します。システム スキーマは、Vertex ML Metadata API の MetadataSchema リソースとしてアクセスできます。
公式ドキュメント - システムスキーマ
ここにある MetadataSchema とは Vertex ML Metadata の用語として、下記のように記述されています。
MetadataSchema
MetadataSchema は、特定のタイプのアーティファクト、実行、コンテキストのスキーマを記述します。MetadataSchemas は、対応するメタデータ リソースの作成時に Key-Value ペアを検証するために使用されます。スキーマの検証は、リソースと MetadataSchema の間で一致するフィールドに対してのみ実行されます。型スキーマは、OpenAPI Schema Objects として表現します。これは、YAML を使用して記述する必要があります。
公式ドキュメント - データモデルとリソース:Vertex ML Metadata の用語
二つの記述を合わせると、Vertex AI 周りで出てくるメタデータリソースはすべて特定のタイプのアーティファクト・コンテキスト・実行に紐づいているとのこと。つまり、今回でいう Vertex AI Experiments のテストの実態である Experiment オブジェクトは、Vertex ML Metadata の Context オブジェクトの何かしらのタイプに該当しているとわかります。
最後にこの Context オブジェクトのどのタイプが Experiment オブジェクトとなっているかを調べてみます!
Context オブジェクトのスキーマタイトル
公式ドキュメントにある下記のコマンドを叩くと、Vertex ML Metadata のメタデータリソースのスキーマ一覧を取得することができます。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://asia-northeast1-aiplatform.googleapis.com/v1/projects/xxx/locations/asia-northeast1/metadataStores/default/metadataSchemas?pageSize=100&filter=schema_title=%22system*%22+OR+schema_title=%22google*%22"
取得したデータを見ると schemaType がメタデータリソースとなっていて、アーティファクトやコンテキストについての情報だとわかります。schemaType が CONTEXT_TYPE となっているものを探すと schema.title が system.Experiment と system.ExperimentRun が見つかりました。
{
"metadataSchemas": [
{
"name": "projects/xxx/locations/asia-northeast1/metadataStores/default/metadataSchemas/google-vertex-model-v0-0-1",
"schemaVersion": "0.0.1",
"schema": "title: google.VertexModel\ntype: object\nproperties:\n resourceName:\n type: string\n",
"schemaType": "ARTIFACT_TYPE",
"createTime": "2023-07-09T09:26:25.757Z"
},
・・・
{
"name": "projects/xxx/locations/asia-northeast1/metadataStores/default/metadataSchemas/system-pipeline-v0-0-1",
"schemaVersion": "0.0.1",
"schema": "title: system.Pipeline\ntype: object\n",
"schemaType": "CONTEXT_TYPE",
"createTime": "2023-07-09T09:26:25.646Z"
},
{
"name": "projects/xxx/locations/asia-northeast1/metadataStores/default/metadataSchemas/system-experiment-run-v0-0-1",
"schemaVersion": "0.0.1",
"schema": "title: system.ExperimentRun\ntype: object\nproperties:\n experiment_id:\n type: string\n",
"schemaType": "CONTEXT_TYPE",
"createTime": "2023-07-09T09:26:25.640Z"
},
{
"name": "projects/xxx/locations/asia-northeast1/metadataStores/default/metadataSchemas/system-experiment-v0-0-1",
"schemaVersion": "0.0.1",
"schema": "title: system.Experiment\ntype: object\nproperties:\n tensorboard_link:\n description: \u003e\n A link to a Tensorboard.\n type: string\n",
"schemaType": "CONTEXT_TYPE",
"createTime": "2023-07-09T09:26:25.626Z"
},
・・・
]
}
これで Vertex AI Experiments と Vertex ML Metadata の関係性として、Vertex AI Experiments の主要なオブジェクトは Vertex ML Metadata のオブジェクトに紐づいていることがわかりました!
同様に Vertex AI Experiments のテスト実行の実態である ExperimentRun オブジェクトは Vertex ML Metadata の Context オブジェクトの schema.title が ExperimentRun となっていました。
長かったですね(笑)

VAE のサマリ指標とパラメータ
ついでに、Vertex AI Experiments のテスト実行に記録できるサマリ指標とパラメータについてもどのように Vertex ML Metadata に記録されているかもまとめておきます。
サマリ指標とパラメータの記録は、python-aiplatform/google/cloud/aiplatform/__init__.py で log_metrics 関数と log_params 関数で利用できるようになっています。
上記と同様に追っていくと、_ExperimentTracker クラスの下記の部分で ExperimentRun オブジェクトの log_metrics メソッドを叩いています。
最終的には Context オブジェクトのメタデータである metadata フィールドの _METRIC_KEY が更新されていることがわかりました。
つまり、Vertex AI Experiments のテスト実行で記録していたサマリ指標やパラメータは、実は Vertex ML Metadata の Context オブジェクトの schema.title が ExperimentRun のメタデータに記録されているということでした。
まとめ
一連の流れから Vertex ML Metadata にメタデータは集約されていて、特定の見せ方をしたい場合(今回は実験管理機能として)には Vertex AI Experimetns という名のをラッパーを被せて利用しやすくなっているのだなとコードを紐解くことで感じることができました!
改めて、公式ドキュメントを読んでみるとこの記載がありました(笑)
ぜひ、探してみてください。

さいごに
学びとしては、登壇資料の最後にも記載していますが、エンジニアとして「微妙に気持ち悪い」と思える感性って重要だなと感じました。
今回でいえば、log_params メソッドでも代替できたところを「ものによってはどう考えてもパラメーターではない」という感じだったので、妥協せずにコードを読み解いてみて腑に落ちる実装に辿り着くことができました。
Discussion