2台のDGX Sparkを相互接続して無事にvLLMを動作させるまでのメモ
DGX Sparkは,「デスク上の Grace Blackwell AI スーパーコンピューター」を謳うMac miniサイズのAIワークステーションです.
今回これを2台購入して相互接続し,vLLMによってマルチノード構成のTensor Parallelismでgpt-oss-120bを動作させてみたので,本記事にその際の初期設定に関してメモしておきます.公式ガイドの通りに進めるとエラーが多く発生したため,それを解決する方法について書いていきます.
用意したもの
- NVIDIA DGX Spark x2
- QSFP112 ダイレクトアタッチケーブル
参考資料
- ユーザガイド(初期設定方法込み): DGX Spark User Guide
- How-toガイド
- DGX Spark上でFLUX.1やvLLMなどいろいろなソフトウェアを動かすためのガイド集: Start Building on DGX Spark
初期設定の手順
DGX Sparkの物理的な相互接続
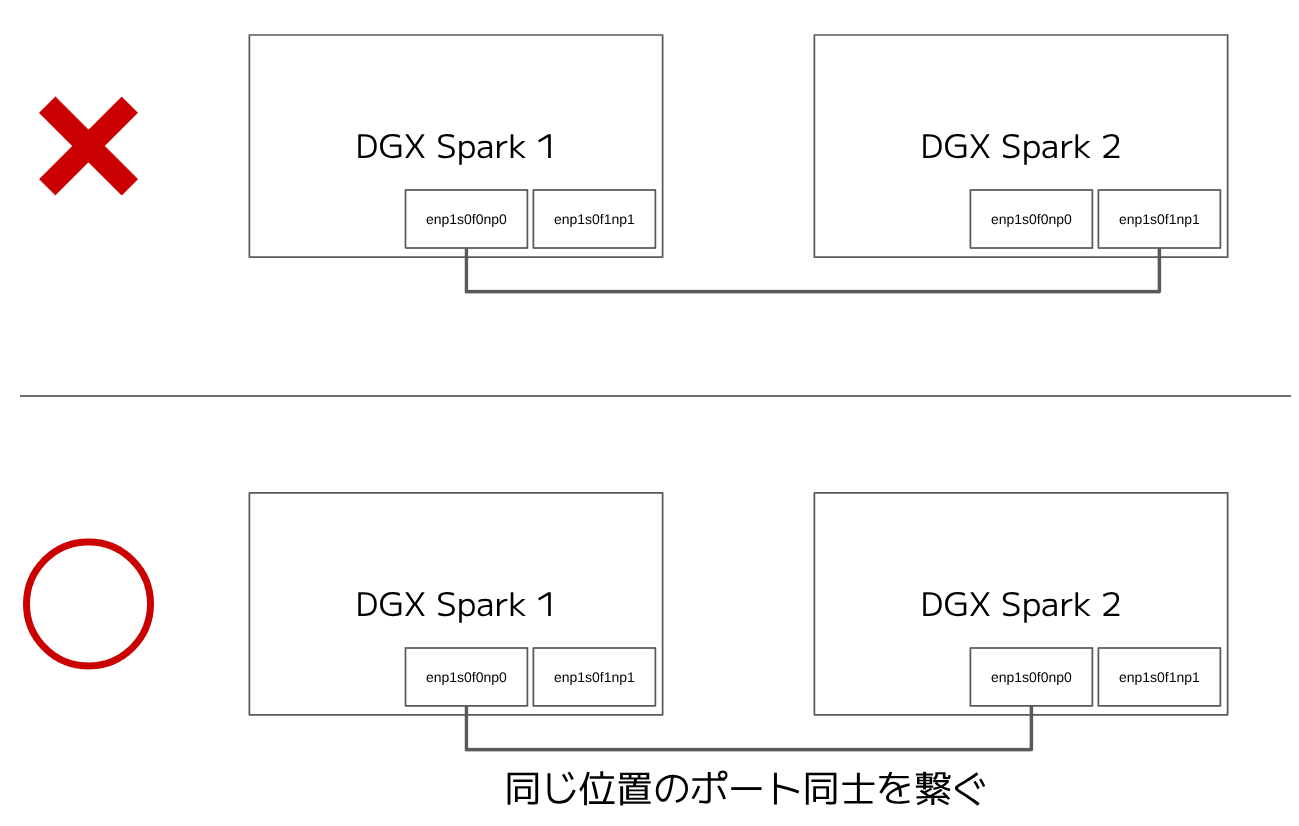
QSFPケーブルでDGX Sparkを相互接続します.注意点として,以下の図の下の例のようにデバイス上で同じ位置にあるポート同士を接続するようにしてください.(公式ガイド内で明示的に指示されているわけではありませんが,異なる位置のポートを接続すると後の接続テストが失敗しますので,念のため同じポート同士を接続することを推奨します)
ここではenp1s0f0np0というインターフェース同士を接続したものとします.
DGX OSの初期設定
DGX Sparkの電源をそれぞれ投入してから,Initial Setup - First Bootの通りに進めればOKです.以降では1台目のDGX Sparkのホスト名をspark-xxxx, 2台目のホスト名をspark-yyyyとします.
DGX Sparkの論理的な相互接続
Connect Two Sparksの通りに進めます.ただし,Step 3において公式ガイド上ではOption 1 (リンクローカルアドレス (169.254.xxx.xxx) を自動で割り当てる方法) が推奨されていますが,この方法だと再起動時にIPアドレスが変化する可能性があります.私はIPアドレスを固定したかったので,ここではOption 2 (IPアドレスの手動設定) を選び,以下のように実施しました:
- まず
ibdev2netdevコマンドを実行してenp1s0f0np0インターフェースが有効になっていることを確認します.(enP2p1s0f0np0はenp1s0f0np0と物理的には同じものですので無視してください)nvidia@spark-xxxx:~$ ibdev2netdev rocep1s0f0 port 1 ==> enp1s0f0np0 (Up) rocep1s0f1 port 1 ==> enp1s0f1np1 (Down) roceP2p1s0f0 port 1 ==> enP2p1s0f0np0 (Up) roceP2p1s0f1 port 1 ==> enP2p1s0f1np1 (Down) - それぞれのDGX Sparkでネットワーク設定用のファイルを書きます.相互接続用インターフェースのIPアドレスは有線LAN/WiFiのインターフェースのIPアドレスとプレフィックスが被らなければ (異なるネットワークに属していれば) 何でも構いません.spark-xxxxでは以下のようにしました:/etc/netplan/40-cx7.yaml
network: version: 2 ethernets: enp1s0f0np0: (←これは上で確認したインターフェース名) addresses: - 172.16.100.1/30 (spark-yyyyでは172.16.100.2/30) dhcp4: no -
sudo netplan applyを実行します. - spark-xxxxから
ping 172.16.100.2を, spark-yyyyからping 172.16.100.1を実行して,ICMP Echo Replyがあることを確認します.
Step 4以降は公式ガイドの通りです.
NCCL (NVIDIA Collective Communication Library)のビルドとテスト
NCCL for Two Sparksの通りに進めます.
vLLMの設定手順
Install and Use vLLM for Inferenceに2台のDGX Sparkを使ってvLLMでLlama-3.3-70B-Instructを動作させる例が載っていますので,これを参考にgpt-oss-120bを動かしてみます.ただ,この公式ガイドにそのまま従うと上手く行かないので,各ステップを以下のように読み替えてください.
Step 2
Step 2ではrun_cluster.shというスクリプトをダウンロードしていますが,このファイルをそのまま使うと後ほどrayクラスタのheadノードのIPアドレスが相互接続用インターフェースのものではなくLAN側インターフェースのものになってしまうことがあり,その結果ノード間のコミュニケーションがとれずエラーが出ることがあります[1].そこで,スクリプト内のrayコマンドを一部修正するために以下を実行します.
# Download on both nodes
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/examples/online_serving/run_cluster.sh
# 以下でスクリプトを書き換え,headノードのIPアドレスをコマンド引数として指定するようにします
sed -i 's/RAY_START_CMD+=" --head --port=6379"/RAY_START_CMD+=" --head --node-ip-address=${HEAD_NODE_ADDRESS} --port=6379"/' run_cluster.sh
chmod +x run_cluster.sh
Step 3
公式ガイドのコマンドではnvcr.io/nvidia/vllm:25.09-py3を使っていますが,gpt-ossを動作させるためにはvLLMが0.10.2以上である必要があります.そこで,vLLM | NVIDIA NGCを参照して最新のvLLMのイメージをpullしましょう.本記事の執筆時点における最新のタグは25.11-py3です.
docker pull nvcr.io/nvidia/vllm:25.11-py3
export VLLM_IMAGE=nvcr.io/nvidia/vllm:25.11-py3
Step 4
Step 4, 5では,上の「DGX Sparkの論理的な相互接続」で固定したIPアドレスを使用してコマンドを実行します.
# On spark-xxxx, start head node
export MN_IF_NAME=enp1s0f0np0 # (←上でUpになっていたインターフェースを記入します)
# Usage: bash run_cluster.sh docker_image head_node_ip --head|--worker path_to_hf_home [additional_args...]
bash run_cluster.sh $VLLM_IMAGE 172.16.100.1 --head ~/.cache/huggingface \
-e VLLM_HOST_IP=172.16.100.1 \
-e UCX_NET_DEVICES=$MN_IF_NAME \
-e NCCL_SOCKET_IFNAME=$MN_IF_NAME \
-e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \
-e GLOO_SOCKET_IFNAME=$MN_IF_NAME \
-e TP_SOCKET_IFNAME=$MN_IF_NAME \
-e RAY_memory_monitor_refresh_ms=0 \
-e MASTER_ADDR=172.16.100.1
Step 5
# On spark-yyyy, join the cluster as worker
export MN_IF_NAME=enp1s0f0np0 # (←上でUpになっていたインターフェースを記入します.Step4のインターフェース名と同じになるはずです)
bash run_cluster.sh $VLLM_IMAGE 172.16.100.1 --worker ~/.cache/huggingface \
-e VLLM_HOST_IP=172.16.100.2 \
-e UCX_NET_DEVICES=$MN_IF_NAME \
-e NCCL_SOCKET_IFNAME=$MN_IF_NAME \
-e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \
-e GLOO_SOCKET_IFNAME=$MN_IF_NAME \
-e TP_SOCKET_IFNAME=$MN_IF_NAME \
-e RAY_memory_monitor_refresh_ms=0 \
-e MASTER_ADDR=172.16.100.1
Step 6
公式ガイドには docker exec node ray status というコマンドを実行するように書いてありますが,spark-xxxx上で docker ps を実行すると上のrun_cluster.shで起動された実際のコンテナ名はnode-12345のようになっており,5桁のランダムなsuffixがついていることがわかります.これをコンテナ名に指定して先のコマンドを実行します.以下のように 0.0/2.0 GPU という行が出力されれば成功です.
nvidia@spark-xxxx:~$ docker exec node-12345 ray status
======== Autoscaler status: 2025-11-27 05:40:44.748178 ========
Node status
---------------------------------------------------------------
Active:
1 node_05998750f099112880d000f5700c79df48ebcd778f3a4be7d1d6a23a
1 node_214c8e5a23496c3c7f302fdbe2849a9f9e759bac7daf86c8a5952196
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Total Usage:
0.0/40.0 CPU
0.0/2.0 GPU
0B/218.56GiB memory
0B/19.46GiB object_store_memory
Total Constraints:
(no request_resources() constraints)
Total Demands:
(no resource demands)
次に docker exec -it node-12345 /bin/bash でコンテナ内のbashシェルに入ります.このシェルからはクラスタに参加している2つのDGX Sparkのリソースをあたかも単一のマシンであるかのように使用できます.
ということで,いつも通りvLLMを起動します. --tensor-parallel-size 2 を指定することでTensor Parallelismによって2つのGPU (実際は物理的に異なるマシンである2台のDGX Spark) にモデルを分散させます.
# run the server inside the container
root@spark-xxxx:/workspace$ vllm serve openai/gpt-oss-120b \
--tensor-parallel-size 2 \
--host 0.0.0.0 \
--port 8000 \
--tool-call-parser openai \
--enable-auto-tool-choice
初回起動時にはgpt-oss-120bのダウンロードが行われますが,ファイルは全部で196GBありますので[2]かなり時間がかかります.気長に待ちましょう.
(APIServer pid=1061) INFO: Application startup complete. のような行が表示されたら準備OKです.試しにもう1つターミナルを起動して,PythonのopenaiライブラリのCLIインターフェースからリクエストを出してみます.
nvidia@spark-xxxx:~$ OPENAI_BASE_URL="http://localhost:8000/v1" \
OPENAI_API_KEY="sk-dummy" \
python -m openai api chat.completions.create \
-g user "GPUに関する川柳を詠んでください.その後に短い解説をつけてください." \
-m "openai/gpt-oss-120b"
**GPUの俳句(川柳)**
熱く走る
シリコンの羽根で
星も描く
**解説**
- 「熱く走る」は、GPUが大量の演算を高速で処理し、熱を多く発生させる様子を表しています。
- 「シリコンの羽根で」は、GPUのコアがシリコンでできた微小な「羽根」のように、並列に大量の計算を飛び回ることを比喩しています。
- 「星も描く」は、GPUがグラフィックスだけでなく、AIの学習や科学シミュレーションなどで、星(宇宙)や複雑なデータを「描く」ほど高性能であることを示しています。
ちゃんと動いています!あとはいつも通りのOpenAI-compatible APIとして使えますので,例えばOpenWebUIをクライアントとして使用すればgpt-oss-120bと快適におしゃべりすることができます.
おわりに
今回はデフォルト設定でvLLMを起動しましたが,ここからSpeculative Decodingなどを構成することでさらに推論を高速化することができます.興味のある方はStart Building on DGX Sparkを見てみてください.
DGX Sparkは発売直後ということもあり情報が少ないので,この記事が誰かの役に立てば幸いです!
-
"No available node types can fulfill resource request" というエラーが出ます.詳細はこちら: https://docs.vllm.ai/en/latest/serving/distributed_troubleshooting/#no-available-node-types-can-fulfill-resource-request ↩︎
-
gpt-ossはMXFP4 (4.25bits/param) で量子化されているため,gpt-oss-120bのweightのサイズはおよそ63.75GBのはずなのですが,Hugging Face上でFiles and versionsを見てみるとモデル本体以外にも複数の大容量ファイルが含まれているようです. ↩︎
Discussion
vLLMで詰まっていたものです。助かりました。
ソフトウェア周りの更新が活発すぎるのか、公式ドキュメントが追いつけていないようですね...お役に立てて何よりです!