基本的なグラフアルゴリズムの解説とPython実装【グラフ入門】
グラフアルゴリズム
初めに
部活のアルゴリズム講座で使った資料を公開します。
グラフとは
グラフとは、以下の図のように、頂点とそれを結ぶ辺からなる構造のことを言います。

図 1: グラフの例
グラフの例
グラフってなんの役に立つの?と思うかもしれませんが、実はグラフは私たちの身の回りにたくさん存在しています。
- 友達関係
友達関係や家族関係、SNS のフォロー関係などは、人を頂点、人と人の関係を辺として、グラフで表すことができます。
- 道路網
道路網は、交差点を頂点、道路を辺として、グラフで表すことができます。
- ネットワーク
ネットワークは、コンピュータを頂点、コンピュータ間の通信を辺として、グラフで表すことができます。
グラフの用語
グラフの用語の性質について説明します。
有向グラフ・無向グラフ
グラフには、有向グラフと無向グラフの 2 種類があります。
有向グラフは辺に方向があるグラフで、SNS のフォロー関係などはフォローしている人からフォローされている人への辺に向きを持たせることができます。
無向グラフは辺に方向がないグラフで、SNS の相互フォロー関係などで向きがない辺になります。
重み付きグラフ・重みなしグラフ
重み付きグラフは、辺に重みがあるグラフで、道路網などは道路の長さを重みとして持つことができます。
次数
頂点につながっている辺の数を次数と言います。
上の画像でいうと、頂点 1 の次数は 2、頂点 3 の次数は 1 となります。
隣接・連結
頂点 A と頂点 B が辺でつながっているとき、頂点 A と頂点 B は隣接していると言います。
また、どの頂点間も隣接している頂点を辿ることで到達可能である時、グラフは連結であると言います。
図 1 のグラフは連結であると言えますが、以下のグラフは連結ではありません。

図 2: 連結でないグラフ
閉路
頂点 A から辿って頂点 A に戻ってくることができるとき、頂点 A を始点とする閉路が存在すると言います。
図 1 のグラフでは、4->5->2->4 という閉路が存在します。
パス
頂点 A から辿って頂点 B に到達できるとき、頂点 A から頂点 B へのパスが存在すると言います。特に、同じ辺を 2 度以上通らないパスを単純パスと言います。
二部グラフ
頂点を 2 つのグループに分けて、同じグループの頂点同士は辺でつながっていないグラフを二部グラフと言います。

図 3: 二部グラフ
木
閉路を持たず、連結なグラフを木と言います。任意の木は、頂点数が
(暇な人は証明してみて下さい。数学的帰納法を使うとよいでしょう。)
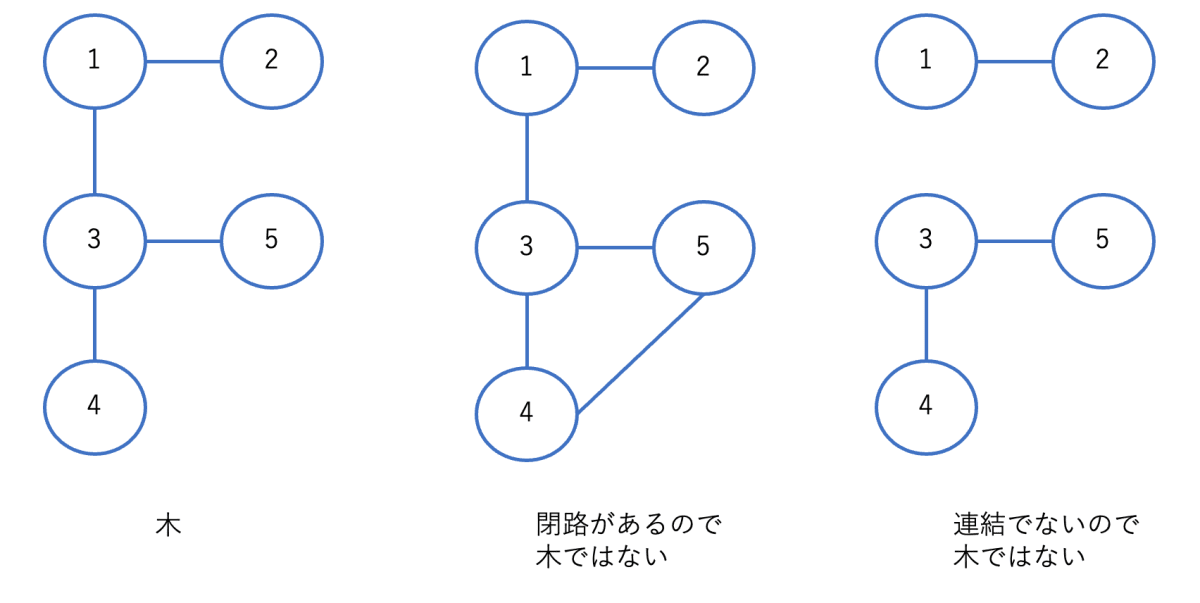
図 4: 木
また、木はある頂点を根として根付き木として表すことができます。この時、根以外で次数が 1 の頂点を葉と言います。
根付き木において、一つ上の頂点を親、一つ下の頂点を子と言います。
下の例は、頂点 1 を根とする根付き木を表しています。たとえば、頂点 4 の親は頂点 2、頂点 3 の子は頂点 5 と頂点 6 です。葉は頂点 5、頂点 6、頂点 7 です。
ある頂点から根までの長さ(たどった辺の数)を深さと言います。たとえば、頂点 4 の深さは 2 です。

図 5: 根付き木
Union-Find
Union-Find は、グラフの連結成分を管理するデータ構造です。
木をイメージするのに適しているのでこの段階で紹介します。
以下の動画がわかりやすいので、まずは見てみて下さい。
練習
2 は難しいので、1 時間考えてわからなかったら解説を見て下さい。
解答例
まず普通に union-find 木を構築します。union-find 木の構築には、atcoder のライブラリを使うと便利です。
その後、各辺がない場合の union-find 木を構築します。元々構築した union-find 木のグループ数よりも、各辺がない場合の union-find 木のグループ数より増えた場合、その辺は橋であると言えます。
from atcoder.dsu import DSU
N, M = map(int, input().split())
dsu = DSU(N+1)
A, B = [], []
for _ in range(M):
a, b = map(int, input().split())
A.append(a)
B.append(b)
dsu.merge(a, b)
groups = dsu.groups()
count = 0
for a, b in zip(A, B):
check_uf = DSU(N+1)
for aa, bb in zip(A, B):
if aa == a and bb == b:
continue
else:
check_uf.merge(aa, bb)
if len(check_uf.groups()) > len(groups):
count += 1
print(count)
【Python3】 AtCoder Beginner Contest 120 D – Decayed Bridgesが参考になります。
from atcoder.dsu import DSU
N, M = map(int, input().split())
dsu = DSU(N)
A, B = [], []
for _ in range(M):
a, b = map(int, input().split())
A.append(a-1)
B.append(b-1)
# 答えを格納する配列
# 最初はすべて繋がっていないのでNから2つ選ぶ組み合わせを入れる
ans = [-1] * M
ans[-1] = int(N * (N - 1) * 0.5)
for i in range(M-1, 0, -1):
# 同じグループなら変化しない
if dsu.same(A[i], B[i]):
ans[i - 1] = ans[i]
else:
# 橋をつけることでグループの島それぞれに対して行き来可能になる
# 例えば、2つのグループと3つのグループがくっつくと、6だけ不便さが減る
ans[i - 1] = ans[i] - dsu.size(A[i]) * dsu.size(B[i])
dsu.merge(A[i], B[i])
for x in ans:
print(x)
グラフの実装
以下の問題を考えてみましょう。
この問題は、
例えば図 1 のグラフの場合、頂点 4 の隣接した頂点は頂点 2 と頂点 5 です。
これを各頂点について出力します。
隣接リスト
グラフをプログラムで扱う場合、隣接リストと隣接行列の 2 種類の方法があります。この資料では隣接リストについて説明します。
隣接リストは、各頂点について、隣接する頂点をリストで持つ方法です。
プログラム上で配列
例えば図 1 を隣接リストで表した場合、
実装
隣接リストを用いて、上の問題を解いてみましょう。
解答例
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(1, N+1):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(1, M+1):
A, B = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A].add(B)
G[B].add(A)
for key in G.keys():
# 頂点keyに隣接する頂点がない場合は、空集合を出力
if len(G[key]) == 0:
print(f"{key}:", "{}")
else:
print(f"{key}:", G[key])
グラフの探索
グラフを探索するには、幅優先探索と深さ優先探索の 2 種類の方法があります。ここではまず、これらを実装するのに必要なデータ構造である「スタック」と「キュー」について説明します。
スタック
スタックは、先入れ後出しのデータ構造です。具体例で考えたほうがわかりやすいので、以下の問題を考えてみましょう。
図解してみましょう。
まずからの箱があり、Aを入れ、次に B を入れます。そして一番上を取り出すと、B が取り出されます。
これは、先に入れたものが後に取り出されているので、先入れ後出しと言えます。先入れ後出しのデータ構造をスタックと言います。

実装してみましょう。
pythonでは、リストをスタックとして使うことができます。リストの append メソッドで要素を追加し、pop メソッドで要素を取り出すことができます。また、いちばん上の要素を取り出すだけなら、リストのインデックス -1 でアクセスすることもできます。
Q = int(input())
stack = []
for _ in range(Q):
line = input()
query = line[0]
if query == "1":
book = line.split()[1]
stack.append(book)
elif query == "2":
print(stack[-1])
else:
stack.pop()
|
練習問題
5
({}){()(())}のような、(と)、{と}からなる文字列が与えられるので、この文字列が正しい括弧列であるかどうかを判定して下さい。
例えば、({})は正しい括弧列ですが、({)}は正しくありません。
スタックを使って簡単に実装することができます。
S = input()
stack = []
ok = True
for s in S:
if s == '(' or s == '{':
stack.append(s)
else:
if len(stack) == 0:
ok = False
break
l = stack.pop()
if s == ')' and l != '(':
ok = False
break
if s == '}' and l != '{':
ok = False
break
print(ok)
キュー
キューは、先入れ先出しのデータ構造です。具体例で考えてみましょう。
先ほどのスタックとは異なり、先に入れたものが先に取り出されているので、先入れ先出しと言えます。
pythonではdequeを使うとキューを実装することができます。
- 最後尾に追加する:
append - 先頭から取り出す:
popleft - 先頭を見る: インデックス 0 でアクセスする
from collections import deque
Q = int(input())
queue = deque()
for _ in range(Q):
line = input()
query = line[0]
if query == '1':
name = line.split()[1]
queue.append(name)
elif query == '2':
print(queue[0])
else:
queue.popleft()
幅優先探索(BFS)
まずは幅優先探索について説明します。以下の問題を考えてみましょう。
この問題は、グラフの頂点数
解き方を解説します。まず頂点1からの最短距離を格納しておく配列を用意します。最初はすべての頂点の最短距離を-1にしておきます。また、頂点1は頂点1からの距離が0なので、最初から0にしておきます。
ans = [-1] * N
ans[0] = 0
次に頂点1に隣接している頂点の要素を1にします。そして、次はその頂点に隣接している頂点の要素を2にします。これを繰り返していきます。
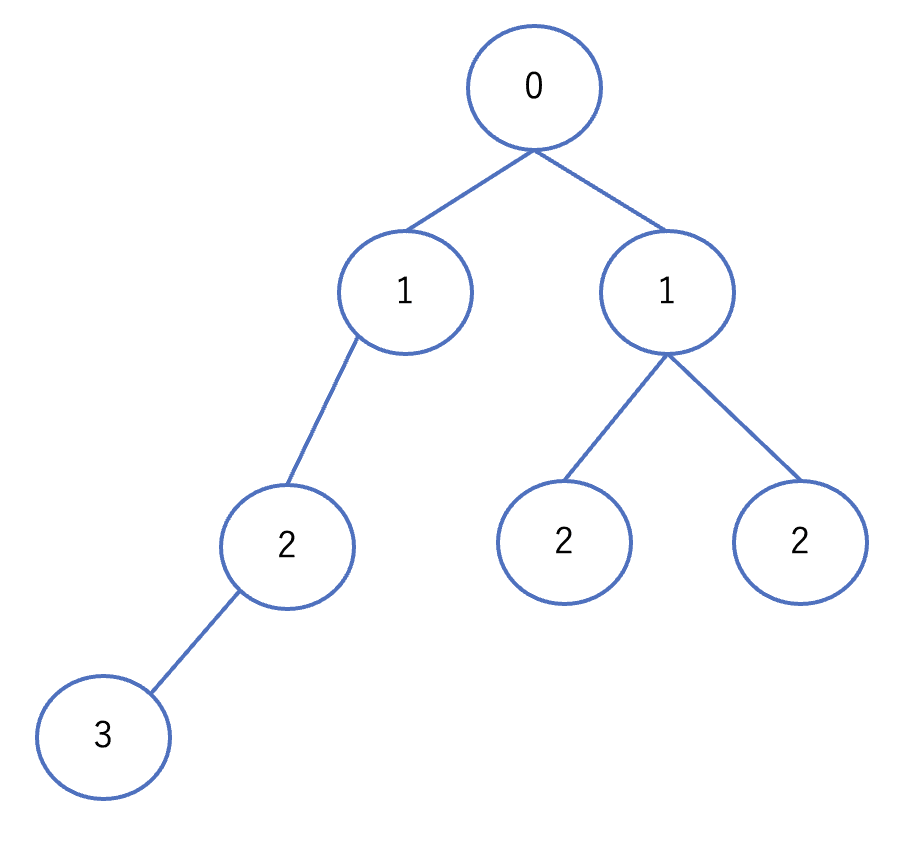
図 6: 幅優先探索
同じ高さにある要素が同じ値になっており、幅を意識している感じがしますよね。これが幅優先探索です。
またこれは、キューを使って、次のように言い表すことができます。
- キューに頂点1を入れる
- キューから頂点を取り出す
- 取り出した頂点に隣接している頂点をキューに入れ、その頂点の要素を取り出した頂点の要素+1にする
- キューが空になるまで繰り返す
キューに入れることで、先に入れたものから順番に取り出すことができ、隣接しているものを優先できるので、幅優先探索が実現できます。
以下の記事を見ると視覚的にわかりやすいです。
ここまでの説明を踏まえて、実装してみましょう。
解答例
from collections import deque
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A-1].add(B-1)
G[B-1].add(A-1)
q = deque() # デックを定義
ans = [-1] * N # 未探索は-1にする
ans[0] = 0 # 最初は距離0
q.append(0) # キューに0を追加する
# キューが空になるまで続ける
while len(q) != 0:
s = q.popleft() # キューから取り出す
for e in G[s]: # キューから取り出した要素の隣接要素を見る
if ans[e] != -1: # 訪問済みだったらパス
continue
ans[e] = ans[s] + 1 # 前の要素に1を足せば自分に到達可能である
q.append(e) # キューに追加する
# 答えの出力
for a in ans:
print(a)
練習問題
8
迷路の最短経路を求める問題です。チャレンジしてみましょう。
9
「木の直径」を求める問題です。木の直径とは、木の中で最も距離が長い 2 頂点間の距離のことを言います。
適当な頂点
最も遠い頂点の求め方を考えてみましょう。
深さ優先探索(DFS)
次に深さ優先探索について説明します。以下の問題を考えてみましょう。
グラフが連結であるかどうかを判定する単純な問題です。深さ優先探索を使って解いてみましょう。
深さ優先探索とは、以下の図のように、ある頂点から隣接する頂点を探索していき、それができなくなったら、一つ前の頂点に戻って、別の頂点を探索していく方法です。深いところから先に探索しているので、深さ優先探索と言います。

図 7: 深さ優先探索
深さ優先探索は、スタックを使って実装することができます。具体的には、以下のようになります。
- 訪問済みの頂点を記録する配列を用意する
- スタックに頂点 1 を入れる
- スタックから頂点を取り出す
- 取り出した頂点に隣接している頂点をスタックに入れる。ここで、訪問済みの頂点はスタックに入れないようにする
- スタックが空になるまで、3と4を繰り返す
これで深さ優先探索が実現できます。最後に訪問済みの頂点を数えて、頂点数と同じなら連結であると言えます。
解答例
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A - 1].add(B - 1)
G[B - 1].add(A - 1)
stack = [0] # スタックを用意する
# 訪問済み頂点を記録する配列を用意する
vis = [False] * N
vis[0] = True
while len(stack) != 0:
s = stack.pop()
for e in G[s]:
if vis[e]:
continue
vis[e] = True
stack.append(e)
# この文法がわからない人は「python 三項演算子」で検索しよう
print(
"The graph is connected."
if not False in vis
else "The graph is not connected."
)
練習問題
10
幅優先探索で解いた問題を深さ優先探索で解いてみましょう。
再帰関数を用いた深さ優先探索
再帰関数を用いて競技プログラミングの鉄則 演習問題集 A62 - Depth First Searchを実装してみましょう。
再帰関数の設計を擬似言語で書くと以下のようになります。
def dfs(G, v):
vを訪問済みにする
vに隣接するすべての頂点sについて:
if sが訪問済み:
パスする
sについて再帰的に探索する
解答例
import sys
# pythonは再帰呼び出しの上限があるので、解除する
# Nと同じくらいにしておく
sys.setrecursionlimit(200000)
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A - 1].add(B - 1)
G[B - 1].add(A - 1)
# 訪問済み頂点を記録する配列を用意する
vis = [False] * N
def dfs(G, v):
vis[v] = True
for s in G[v]:
if vis[s]:
continue
dfs(G, s)
dfs(G, 0)
# この文法がわからない人は「python 三項演算子」で検索しよう
print(
"The graph is connected."
if not False in vis
else "The graph is not connected."
)
二部グラフ判定
深さ優先探索を使って、与えられたグラフ
二部グラフについて思い出してみましょう。二部グラフとは、以下の図のように、頂点を二つのグループに分けて、同じグループの頂点同士は辺で結ばれていないグラフのことです。
図 3: 二部グラフ
二部グラフの判定は、深さ優先探索を使って以下のように行うことができます。
- 頂点 1 をグループ 1 に入れる
- グループ 1 に属する頂点に隣接する頂点のうちグループが定まっていないものをグループ 2 に入れる
- グループ 2 に属する頂点に隣接する頂点のうちグループが定まっていないものをグループ 1 に入れる
- 2と3を繰り返す
- 2と3を繰り返す過程で、同じグループに属する頂点同士が辺で結ばれていたら、二部グラフではないと判定する
- 正常にループを抜けたら二部グラフである
以上のフローは頂点1と連結なグラフについて判別することができますが、グラフが連結でない場合もあるので、全ての頂点に対して探索を行う必要があります。
解答例
import sys
sys.setrecursionlimit(400000)
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A - 1].add(B - 1)
G[B - 1].add(A - 1)
# 訪問済み頂点を記録する配列を用意する
group = [-1] * N
group[0] = 0
def dfs(G, v):
for s in G[v]:
if group[s] != -1:
if group[s] == group[v]:
return False
continue
group[s] = 1 if group[v] == 0 else 0
if not dfs(G, s):
return False
return True
# グラフが連結でない可能性があるので全ての要素に対してdfsを行う
ok = dfs(G, 0)
for v in range(1, N):
if group[v] != -1:
continue
if not dfs(G, v):
ok = False
break
print("Yes" if ok else "No")
ダイクストラ法
何個か前の章で、重みなしグラフについての最短経路問題を解きました。重みつきグラフの最短経路問題はダイクストラ法という方法を使って解くことができます。
ヨビノリさんが解説動画を出しているので、まずは見て来て下さい。
動画で示されている手順をそのまま記します。
- 始点に0を書き込む
- 未確定の地点の中から最も小さい値を持つ地点1つを選び、その値を確定させる
- 2で確定した地点から直接繋がっていて、かつ未確定な地点に対し、かかる時間を計算し、書き込まれている数より小さければ更新する
- 全ての地点が確定していれば終了。そうでなければ2に戻る
これをそのまま実装すれば良いです。
解答例
# 辺に重さを持たせるためにクラスを定義
class Edge:
def __init__(self, to, weight) -> None:
self.to = to
self.weight = weight
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B, C = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A - 1].add(Edge(B - 1, C))
G[B - 1].add(Edge(A - 1, C))
INF = 10e9
ans = [INF] * N
confirm = [False] * N
ans[0] = 0
while True:
position = -1
min_ = INF
for i in range(N):
if confirm[i]:
continue
if min_ >= ans[i]:
position = i
min_ = ans[i]
if position == -1:
break
confirm[position] = True
curr = ans[position]
for v in G[position]:
if curr + v.weight <= ans[v.to]:
ans[v.to] = curr + v.weight
for d in ans:
print(d)
このままでも動作しますが、atcoderに提出するとTLEになってしまいます。これは、毎回最小値を探すためにループを回しており、計算量が
これを改善するために、最小値を探すときに優先度付きキューと呼ばれるデータ構造を使うと、計算量を
優先度付きキュー
まずは優先度付きキューについて説明します。通常のキューは、先に入れたものを先に取り出すというデータ構造でしたが、優先度付きキューは、今キューに入っている要素のうち最小のものを取り出すというデータ構造です。
データ構造の章で詳しく扱いますが、計算量は要素の追加に
pythonではheapqを使うと優先度付きキューを実装することができます。
以下の問題を解いてみましょう。
簡単なので、解説は省略します。
計算量の改善
優先度付きキューを使って、ダイクストラ法の計算量を改善してみましょう。
手順を以下のように修正します。
- 0を優先度付きキューに入れる
- 優先度付きキューから最小値を取り出す
- 取り出した値を確定させる
- 3で確定した値から直接繋がっていて、かつ未確定な地点に対し、かかる時間を計算し、書き込まれている数より小さければ更新し、優先度付きキューに入れる
- 全ての地点が確定していれば終了。そうでなければ2に戻る
解答例
import heapq
class Edge:
def __init__(self, to, weight) -> None:
self.to = to
self.weight = weight
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
for i in range(M):
A, B, C = map(int, input().split())
# 無向グラフなので、両方向に辺を張る
G[A - 1].add(Edge(B - 1, C))
G[B - 1].add(Edge(A - 1, C))
INF = 10e9
ans = [INF] * N
confirm = [False] * N
ans[0] = 0
queue = [(0, 0)]
while queue:
_, position = heapq.heappop(queue)
if confirm[position]:
continue
confirm[position] = True
for v in G[position]:
if ans[position] + v.weight <= ans[v.to]:
ans[v.to] = ans[position] + v.weight
heapq.heappush(queue, (ans[v.to], v.to))
for d in ans:
if d == INF:
print(-1)
else:
print(d)
最小全域木
最小全域木とは、重み付きグラフの中で、全ての頂点を含み、辺の重みの総和が最小になるような木のことです。
どんなものに応用できるかというと、例えば、都市間を結ぶ道路の建設費を最小にするような問題に応用できます。
以下の問題を解いてみましょう。
最小全域木を求めるアルゴリズムはいくつかありますが、ここではクラスカル法について説明します。
クラスカル法は、以下の手順で最小全域木を求めるアルゴリズムです。
- 採用されていない辺のうちもっとも重みが小さいものを選び、閉路ができないなら採用する
- 2を繰り返す
- 全ての頂点がつながっていれば終了
最も小さい辺を選ぶときに、優先度付きキューを使うと計算量を改善することができます。
また、閉路ができないかどうかは、Union Find を使えば簡単に判定できます。
解答例
from atcoder.dsu import DSU
import heapq
N, M = map(int, input().split())
G = {} # 隣接リストを表す辞書
for i in range(N):
G[i] = set() # 頂点iに隣接する頂点の集合
# (重み, 頂点1, 頂点2)の優先度付きキュー
edges = []
for i in range(M):
A, B, C = map(int, input().split())
heapq.heappush(edges, (C, A-1, B-1))
uf = DSU(N)
ans = 0
while edges:
C, A, B = heapq.heappop(edges)
# AとBのルートが同じなら、この辺を追加すると閉路になる
if uf.leader(A) == uf.leader(B):
continue
# 採用するなら辺を張り、重みを加算する
uf.merge(A, B)
ans += C
print(ans)
まとめ
長くなってしまいましたが、グラフの考え方に親しむことはできたでしょうか。
グラフ最高!
Discussion