1歩目の衛星データの取得判読解析予測の基礎

1歩目の衛星データの取得判読解析予測の基礎
概要
本編
よくやる簡単な衛星データの扱いや利用について記載しまーす!
検証事象の紹介

今回は 山火事 を題材にします。
特に、長野県諏訪市と茅野市の境にある霧ヶ峰高原の山火事を検証事象に進めていきます。
ニュース記事
Youtube
まずは地道に対象エリアの座標や時事関係を整理するためにニュースなどから調査します。
- 事象は
2023 5/4 ~ 5/5 - 場所は
36.103056, 138.196667
は最低限、撮像検索のために特定します
衛星の撮像検索

今回はSentinel Hub の EO Browserを使って検索していきます。
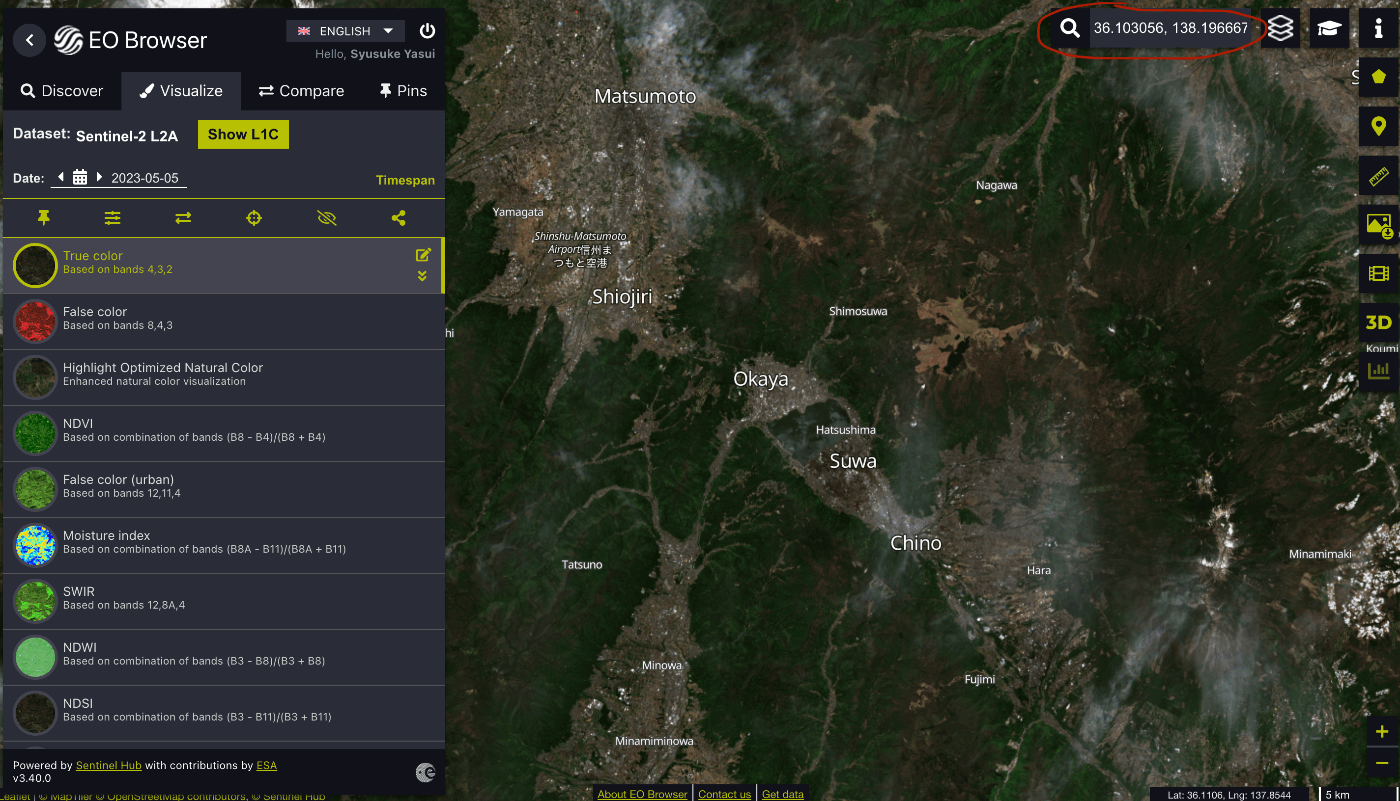
まず、右上の赤丸の部分に座標を打ち込んで場所検索します

今回使用する衛星は Sentinel-2 という光学衛星を使用します
ESA(欧州宇宙機関)の地上観測の人口衛星の1つです。
無料で撮像画像を公開している大変 ありがたーい ですね!
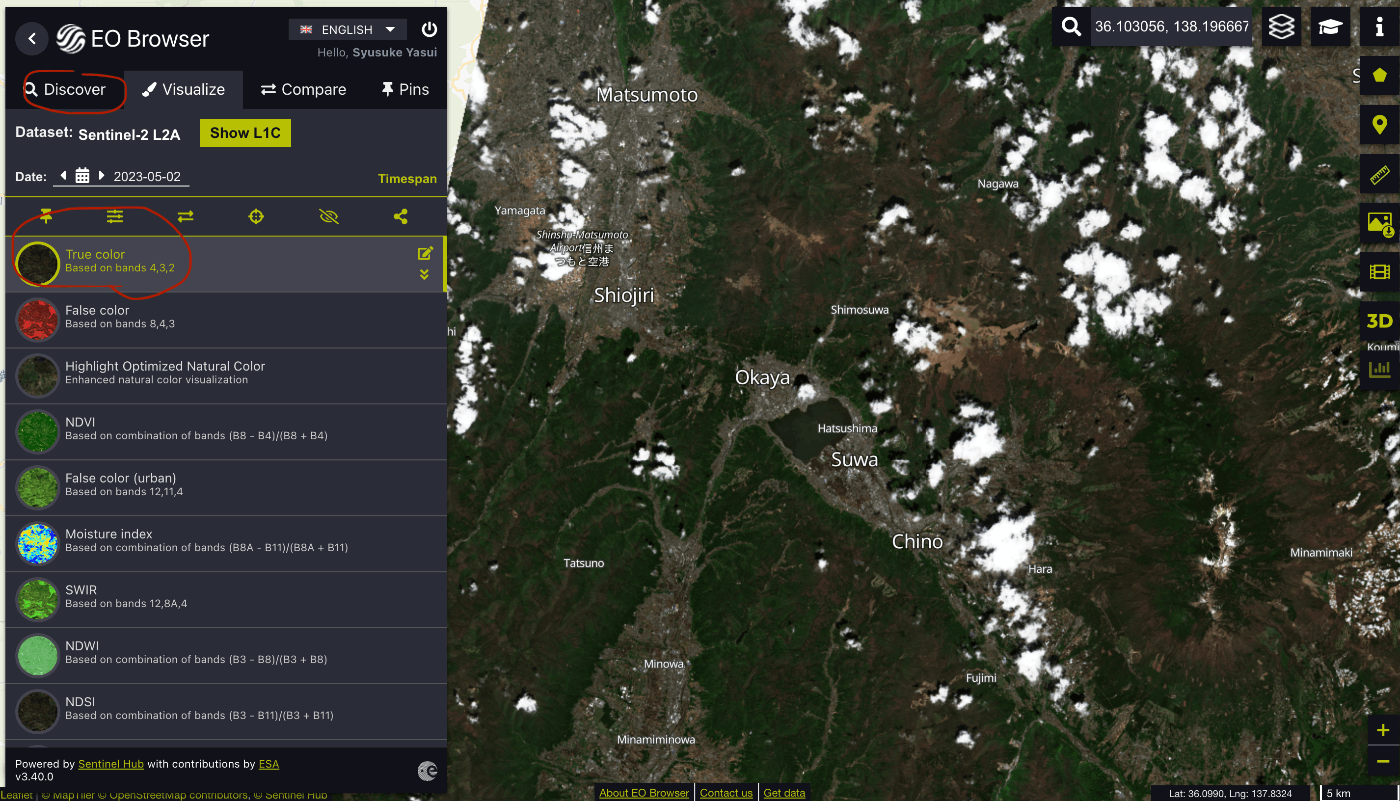
次に左上の Discover の Sentinel-2 を選択して検索しましょう
場所選択は先ほど調査した山が含まれているエリアを選択します
そして、Visualize の TrueColor を選択しましょう。
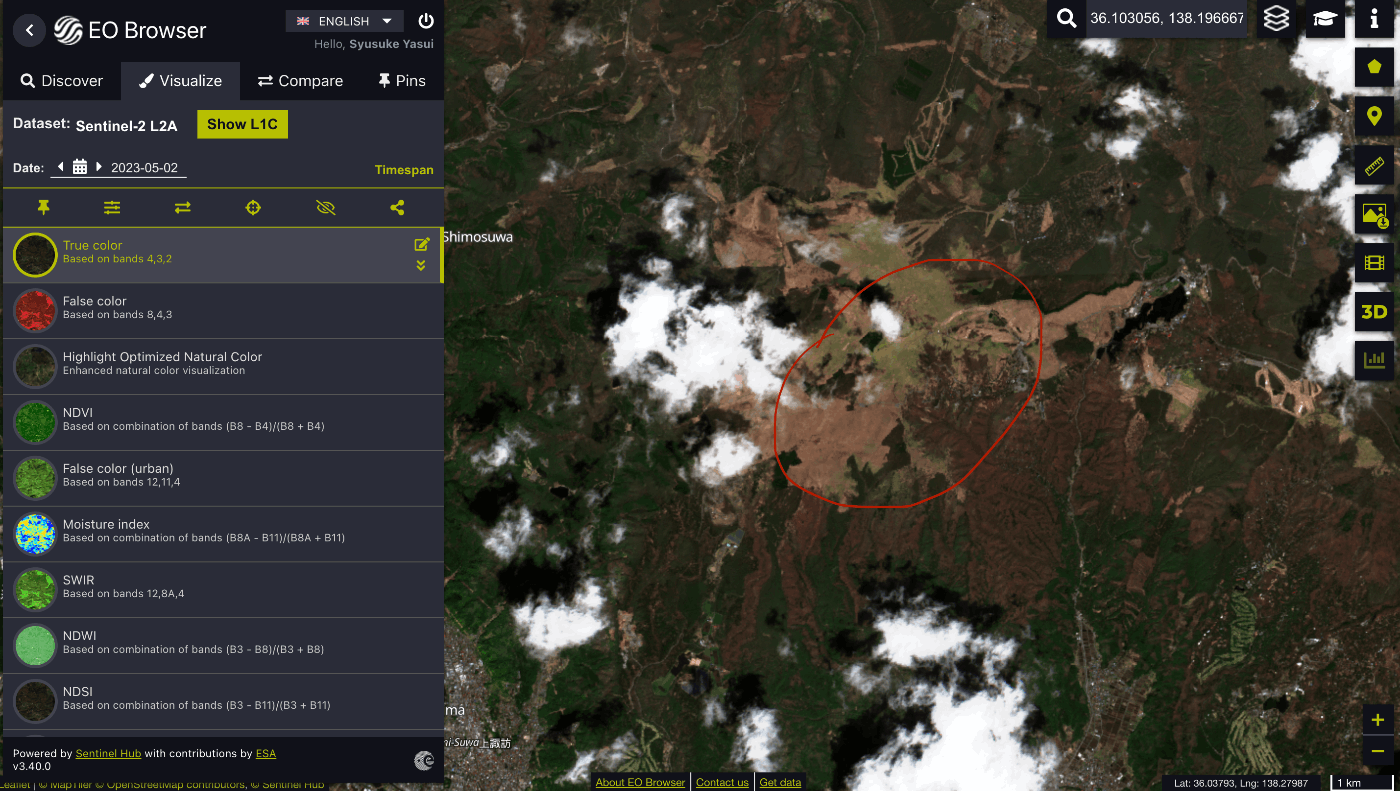
山火事エリア(山火事前なので頑張って探す笑)が見えてくると思います。
この辺りの地理的な知識や判読は慣れてくれば、探せるようになってきます。
余談ですが Compare の項目を利用すれば以下のように山火事差分を可視化できます。
衛星画像の取得
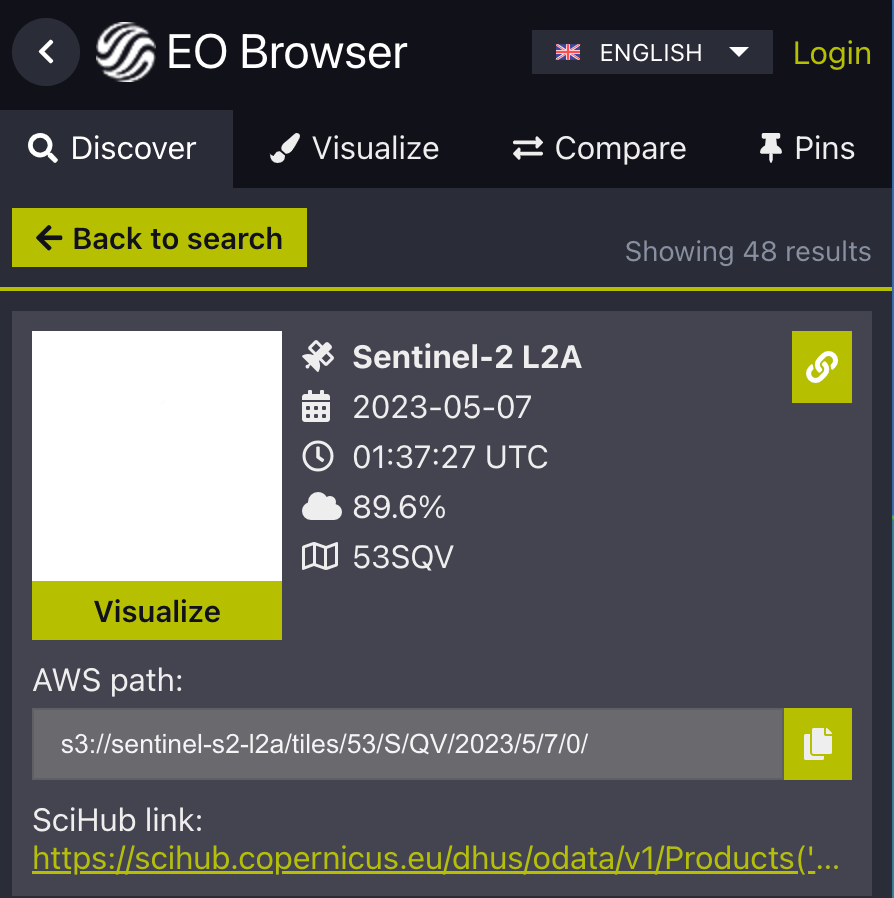
EO Browser の検索画面で コピーマークを押下すると、AWSS3のパスが出ます。
AWS とは Cloud サービスの1つなんですがここでは Sentinel-2 衛星のデータを保管してくれているサービスと思ってもらったらと思います!
ブラウザからダウンロードしても良いですが、探すのが大変なのでおすすめは CLI を利用しましょう
AWS CLI インストール方法
pip install awscli
以下で取得できます
aws s3 cp --request-payer=requester <コピーしたパス> <自分のPCの保存したい場所>
# 例 閲覧のみ
aws s3 ls --request-payer=requester s3://sentinel-s2-l2a/tiles/54/S/TE/2023/5/2/0/R10m/
# 例 ダウンロード
aws s3 cp --request-payer=requester s3://sentinel-s2-l2a/tiles/54/S/TE/2023/5/2/0/R10m/ . --recursive
衛星データゲットですね ♪───O(≧∇≦)O────♪
事象の判読
さて、これから山火事の場所を見つけて見分けていきましょう!
ここでは、衛星などの地理情報を付与した無料可視化ツールとして QGISを使っていきたいと思います。
このQGISで先ほど取得した画像(B04.jp2など)をドラッグ&ドロップしてみると、
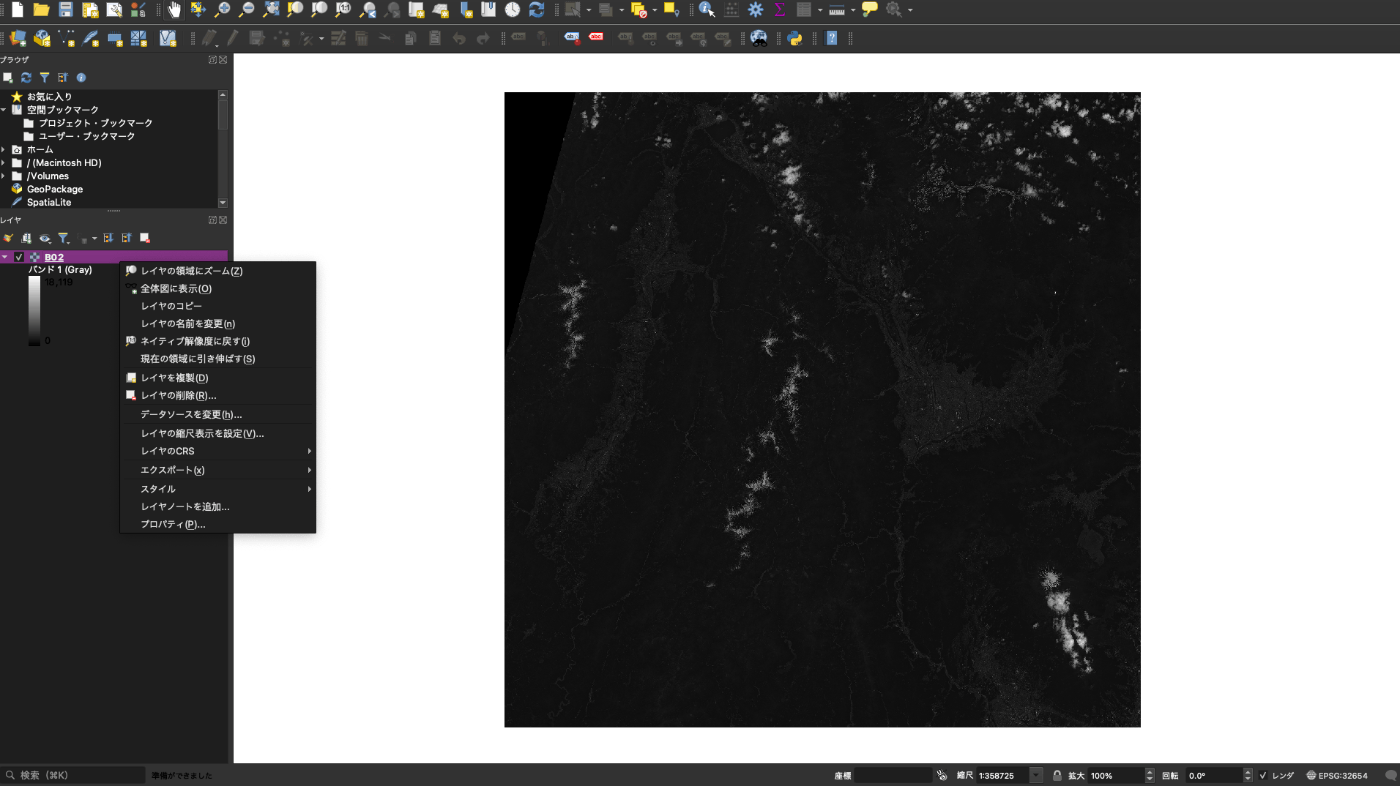
レイヤー領域にズーム で画像のエリアに飛べます。
地図上だとこんな感じです
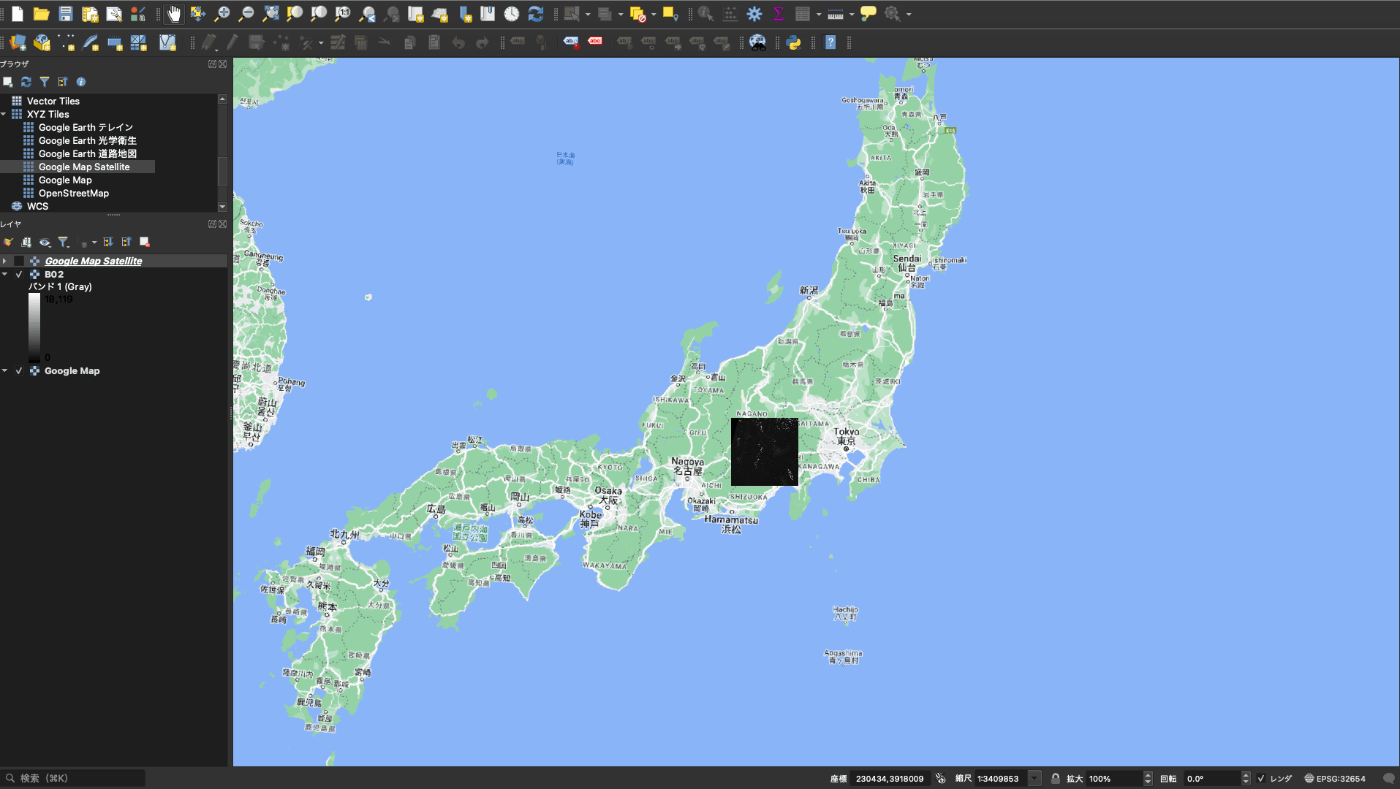
ここで 5/5 の画像を可視化すると、山火事と思われるエリアが見えます。
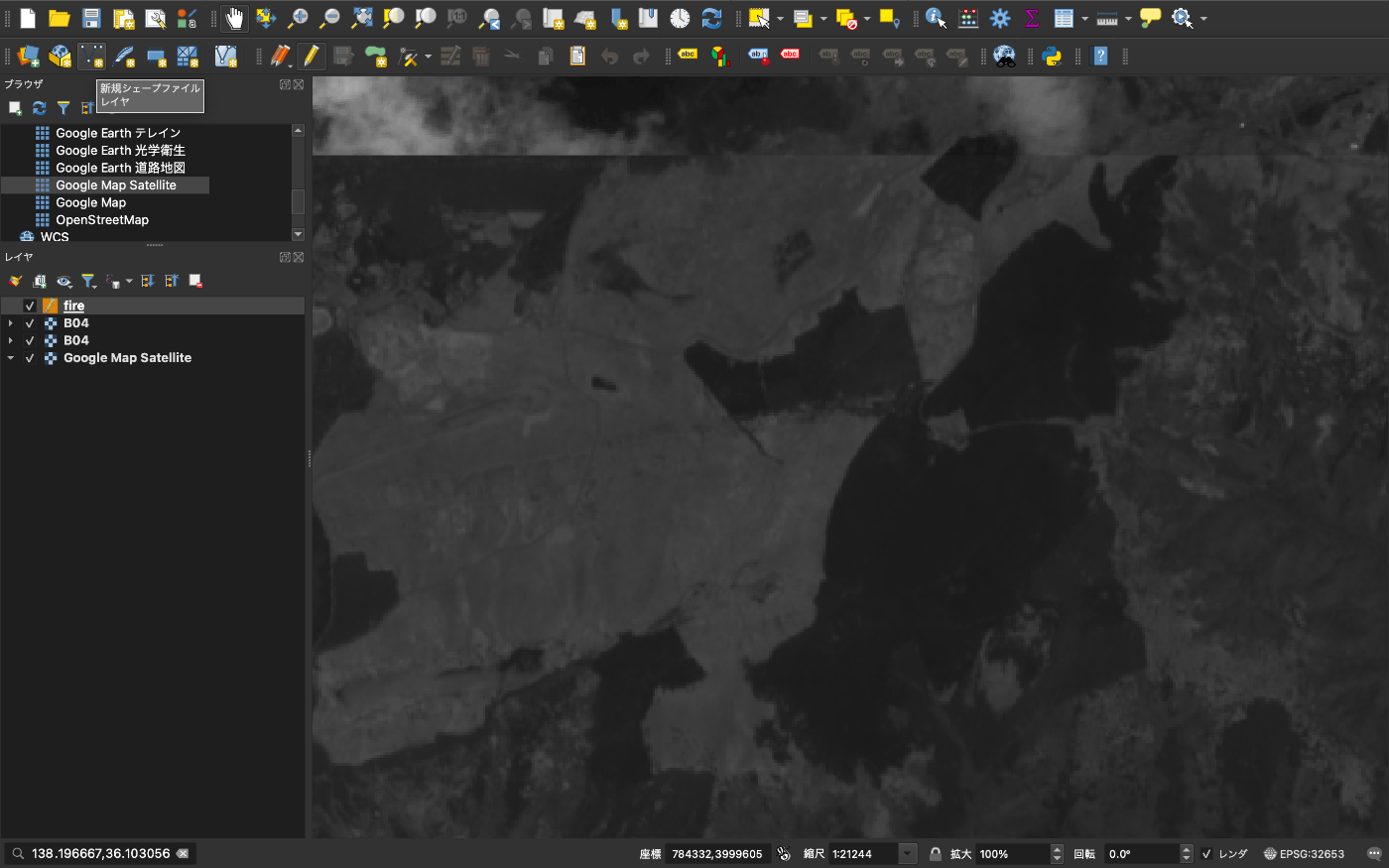
この領域を解析するためにポリゴンで囲っていきます。
上から2段目の左から3列目の 新規シェープファイルレイヤ を選択
上から2段目の左から9列目の 編集モード切り替え を選択
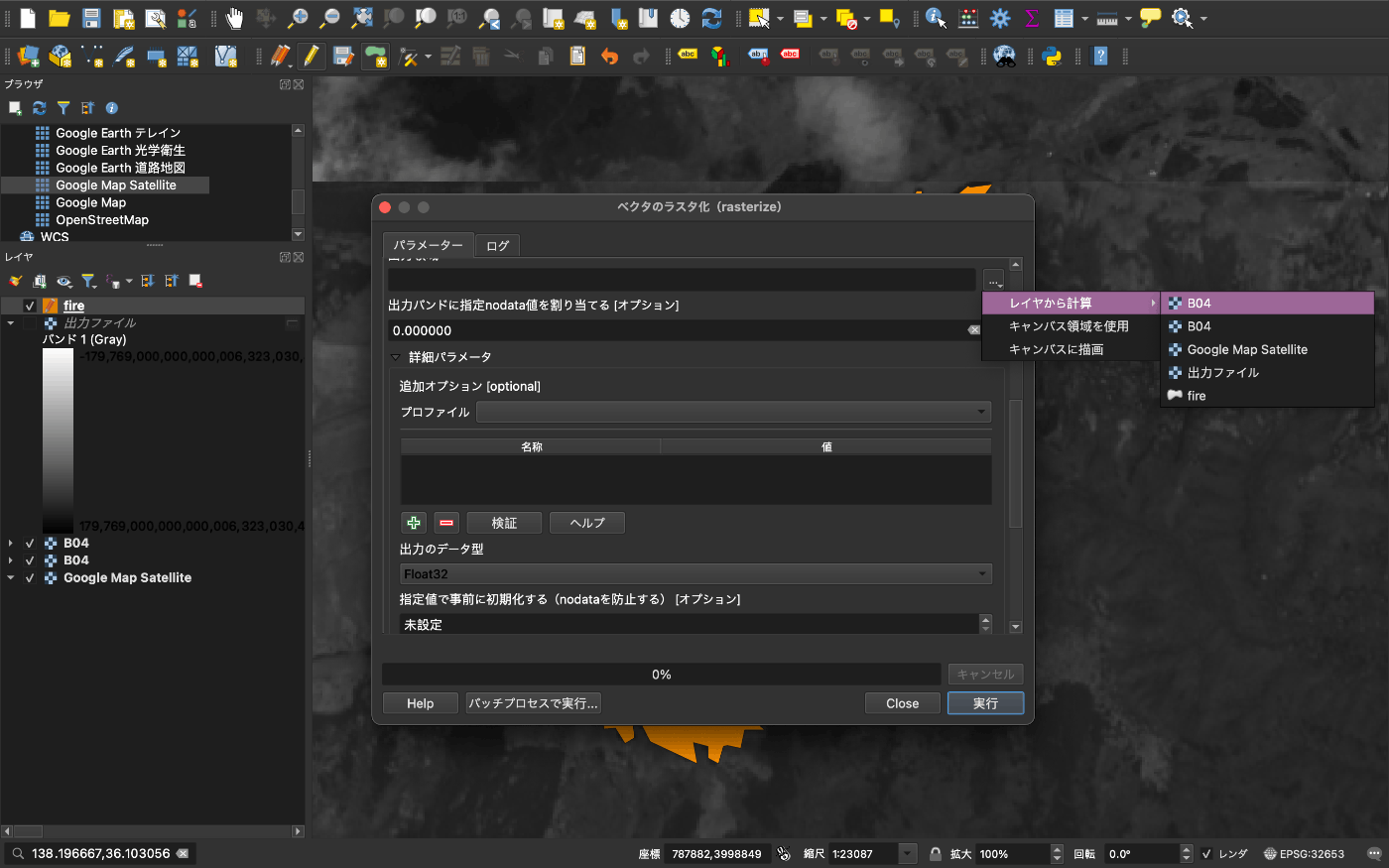
上から2段目の左から11列目の ポリゴン地物を追加 を選択
これでポチポチするとポリゴンが作成できます。これは触った方が理解しやすいかも、、、

山火事を囲んで保存するとこんな感じ
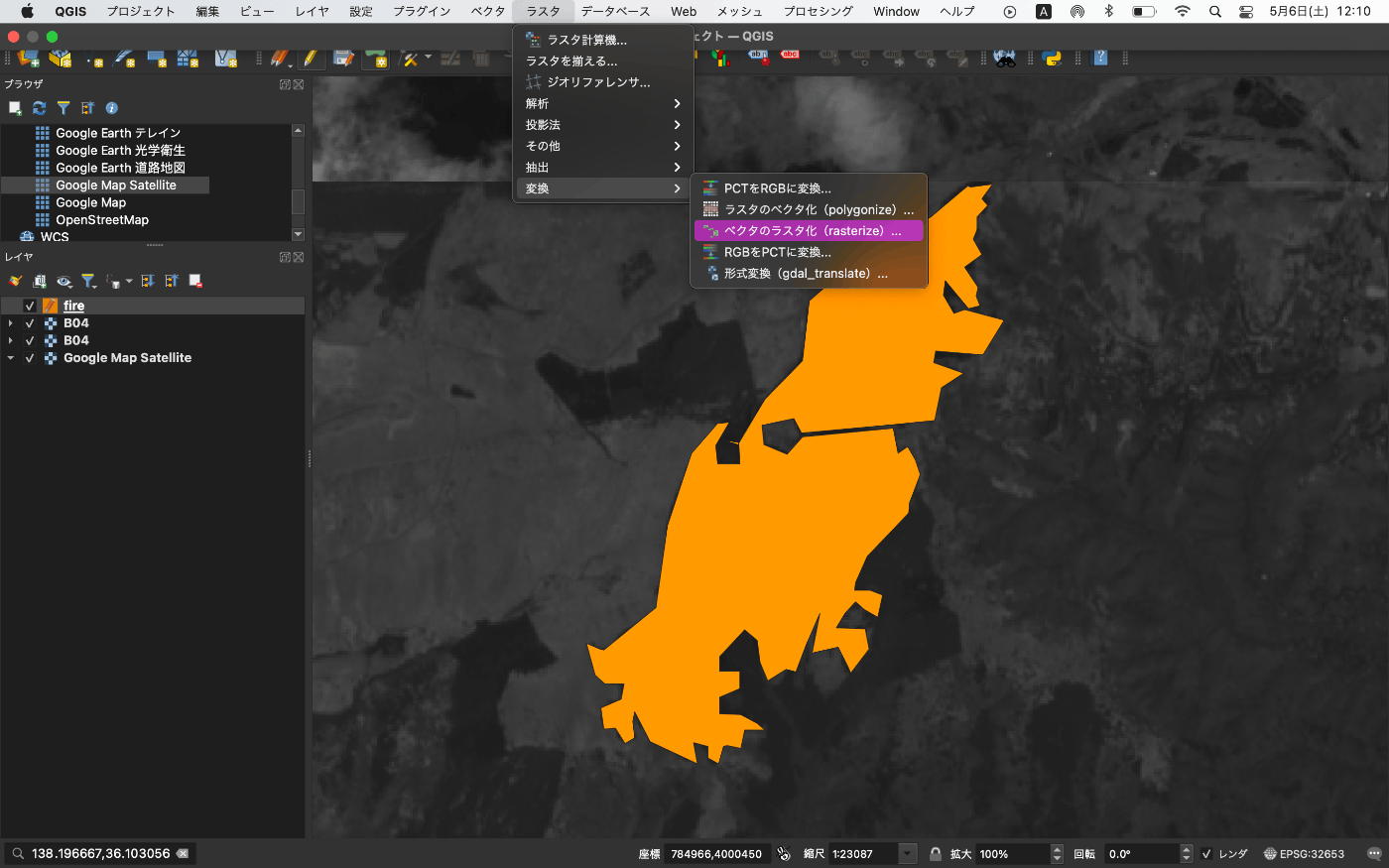
こちらを画像上のラスター変換します。

作成する画像は元の Sentinel-2 と同じ 10980 です

位置座標も元の Sentinel-2 と同じ設定をしましょう

新しいレイヤーができます。

保存して出力しましょう

山火事の教師データの完成です。
地理空間処理
次に2回の撮像エリアが異なるので同一領域を切り抜きましょう
最初に QGIS で切り取る 左上 と 右下 の座標を取得します


今回は座標変換などを行ってくれるツールの Gdalを利用します。
Gdal インストール
# Anaconda latest
conda install -c conda-forge gdal
# 比較的安定?
conda install gdal==3.0.2
環境構築で汚したくない場合は Docker を利用して以下などがあります。
以下で切り抜けます。
gdalwarp -te <切り抜く座標> -te_srs <元座標系> -t_srs <先座標系> <切り抜き画像> <切り抜かれた画像>
# 例
gdalwarp -te 769808 3926343 808462 3999898 -te_srs EPSG:32653 -t_srs EPSG:32653 ./fire_32653.tif ./fire_32653_cut.tif
それぞれ B02 ~ B08 の4枚の2日間で作業しましょう
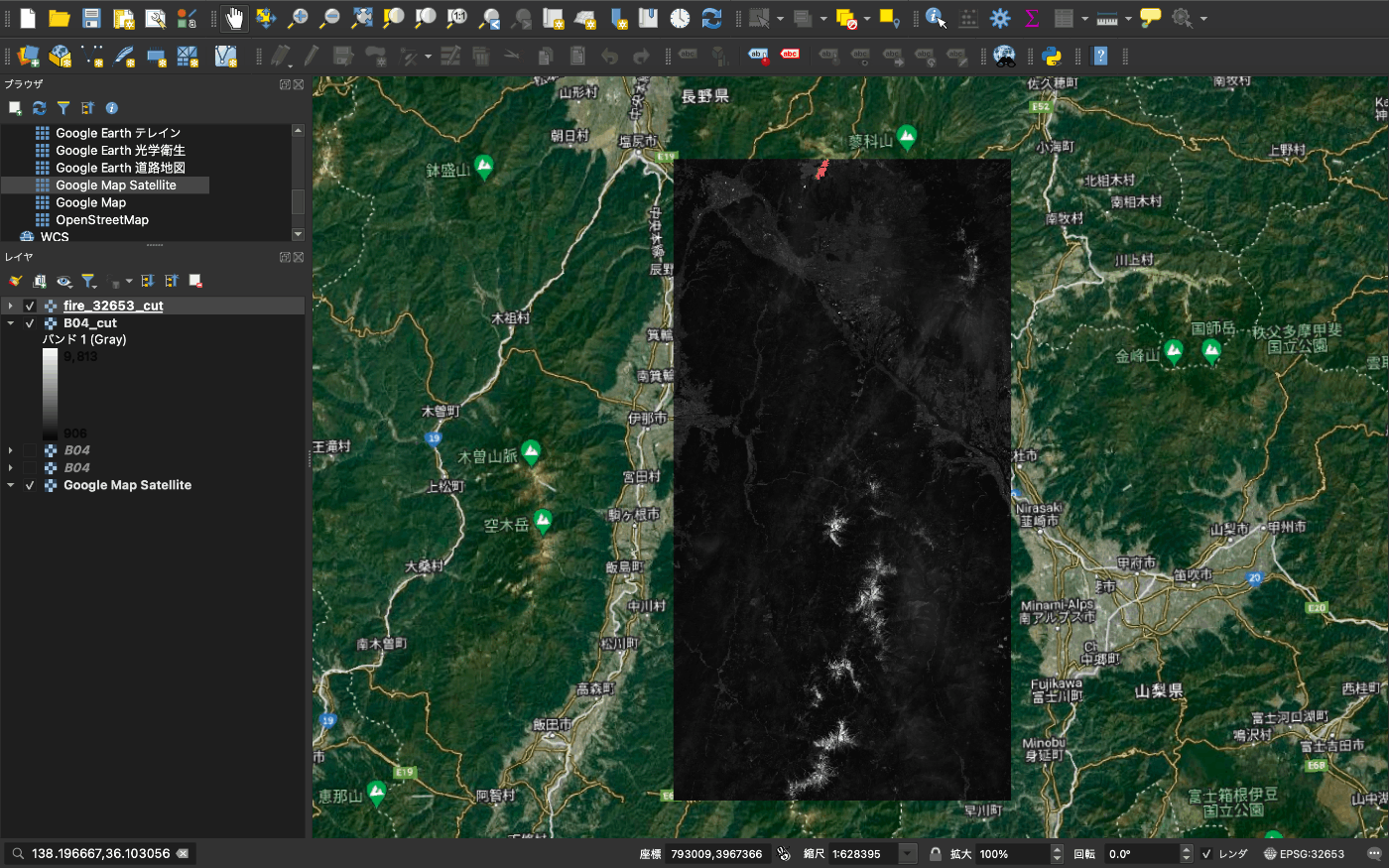

その画像の可視化結果です。
画像解析
環境については Google Colabを利用します。
理由は解析環境が整っていることと無料 GPU があるからです。
今回利用する Colab のリンク
Github の Notebook (ファイルが大きくて表示できないかな)
これまで頑張って作成してきた教師データと解析するファイルを以下のようにアップロードしましょう
data
├── 5_2
│ ├── B02_cut.jp2
│ ├── B03_cut.jp2
│ ├── B04_cut.jp2
│ └── B08_cut.jp2
├── 5_5
│ ├── B02_cut.jp2
│ ├── B03_cut.jp2
│ ├── B04_cut.jp2
│ └── B08_cut.jp2
└── fire_32653_cut.tif
環境構築
pip install -qU segmentation-models-pytorch albumentations opencv-python opencv-python seaborn tifffile
可視化
PATH = './data/5_2/B08_cut.jp2'
img = cv2.imread(PATH).astype(np.float32)
img = img / img.max()
plt.figure(figsize=(10, 8))
plt.title('before wild fire band infred')
plt.imshow(img, vmax=1e-2)
plt.colorbar()
plt.savefig('before_B08.png')
plt.show();
plt.clf()
plt.close()

解析
days, bands = ['5_2', '5_5'], ['B02', 'B03', 'B04', 'B08']
for band in bands:
# 可視化設定
plt.figure(figsize=(16, 4))
plt.title(f'Band {band} Histgram')
features = []
for day in days:
# I/O
PATH_IMG = f'./data/{day}/{band}_cut.jp2'
img = cv2.imread(PATH_IMG).astype(np.float32)
# 前処理
img = img / img.max()
img = cv2.resize(img, (3866, 7356))
# 特徴取得
img_fire = img[np.where(mask == 1., True, False)]
features.append(img_fire.flatten())
# 日付比較で可視化
plt.hist(features, bins=20, label=days)
plt.legend()
# 保存
plt.savefig(f'hist_{band}.png')
plt.show();
plt.clf()
plt.close()




少し遅くなってしまったんですが B**.jp2 というファイルがいくつかあります。
上記のヒストグラムから得られることは B02 というバンドでは山火事のエリアでは事象の前後で値の分布がはっきりと分離できていることがわかるということです。
他にもバンドの組み合わせで地上の状態を観測できる訳なんですが今回はその1つで NDVI という指標を紹介します。
定義は以下です。
これは植物の特性を反映しているとされていて実際に山火事前後で可視化すると以下のようになります。
山火事にて植生がなくなったので緑色が白くなって(値が低くなって)いるのがわかると思います。
事象のモデリング
この山火事を今度は予測または検知するモデリングをしていきます。
正直、ヒストグラムでここまではっきり分離できているので単純に閾値設けて線形回帰などでも十分かもしれませんが、今回はお遊びなので Deep Learning を用いてモデルを作成をしてみましょう
まずは学習するためにパッチに切っていきます
IMG_SIZE = 128
features = []
for band in bands:
for day in days:
# I/O
PATH_IMG = f'./data/{day}/{band}_cut.jp2'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED).astype(np.float32)
# 前処理
img = img / img.max()
img = cv2.resize(img, (3866, 7356))
features.append(img)
features.append(mask)
imgs = np.stack(features, axis=2) # Hight, Width, Channel:9
for h in range(7356 // IMG_SIZE):
for w in range(3866 // IMG_SIZE):
patch = imgs[h*IMG_SIZE:(h+1)*IMG_SIZE, w*IMG_SIZE:(w+1)*IMG_SIZE]
if np.sum(patch[:,:, -1]) > 0:
PATH_PATCH = f'data/patch_h{str(h).zfill(3)}_w{str(w).zfill(3)}_fire.npy'
else:
PATH_PATCH = f'data/patch_h{str(h).zfill(3)}_w{str(w).zfill(3)}_.npy'
np.save(PATH_PATCH, patch)
パッチ画像の可視化
PATH_PATCH = './data/patch_h000_w000_.npy'
patch = np.load(PATH_PATCH)
plt.figure(figsize=(8, 8))
plt.title('Patch 3channel')
plt.imshow(patch[:, :, :3])
plt.savefig('patch.png')
plt.show();

できたパッチの学習ループの処理と Augmentation などの定義です
class DataTransform():
def __init__(self):
self.data_transform = {
"train": A.Compose(
[
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Transpose(p=0.5),
# A.Cutout(p=0.25),
ToTensorV2()
]
),
"val": A.Compose(
[
ToTensorV2(),
]
)
}
def __call__(self, phase, img, anno_class_img):
return self.data_transform[phase](image=img, mask=anno_class_img)
class FireDataset(Dataset):
def __init__(self, img_list, phase, transform):
self.img_list = img_list
self.phase = phase
self.transform = transform
def __len__(self):
return len(self.img_list)
def __getitem__(self, index):
return self.pull_item(index)
def pull_item(self, index):
image_file_path = self.img_list[index]
features = np.load(image_file_path)
img, anno = features[:,:,:8], features[:,:,-1]
img_and_anno = self.transform(self.phase, img, anno)
img = img_and_anno["image"]
anno = img_and_anno["mask"]
return img, anno
意外と知られていないですが、解像度に敏感な衛星データは回転などで壊れやすいです。
統計量の確認
PATHS_FIRE = glob.glob('data/*_fire.npy')
PATHS_SAFE = glob.glob('data/*_.npy')
print('Num Fire:', len(PATHS_FIRE), 'Num None:', len(PATHS_SAFE))
# Num Fire: 5 Num None: 1710
# 不均衡比率 0.2923%
5 / 1710
学習データと検証データの分離です
IDX_SPLIT, BATCH_SIZE = 128, 32
PATHS_TRAIN = PATHS_SAFE[IDX_SPLIT:]+ PATHS_FIRE
PATHS_VALID = PATHS_SAFE[:IDX_SPLIT] + PATHS_FIRE
train_dataset = FireDataset(PATHS_TRAIN, phase="train", transform=DataTransform())
val_dataset = FireDataset(PATHS_VALID, phase="val", transform=DataTransform())
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
dataloaders_dict = {"train": train_dataloader, "valid": val_dataloader}
学習がわかりやすいように開発で山火事エリアは重複させています
model = smp.Unet(
encoder_name='timm-efficientnet-b0',
encoder_weights='imagenet',
in_channels=8,
classes=1,
activation=None,
)
# loss = smp.utils.losses.DiceLoss()
loss_fn = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam([dict(params=model.parameters(), lr=1e-4), ])
モデルは UNet、最適化手法は速度重視で Adamと基本構成でいきます。

モデルのイメージはこんな感じです。差分は明示的にせずにモデルに考えさせています。
EPOCHS = 30
best_score = 1E5
train_loss = []
valid_loss = []
model = model.cuda()
os.makedirs("weights/", exist_ok=True)
for i in range(0, EPOCHS):
loss_epoch = []
for phase in ['train', 'valid']:
print(f'Epoch: {i} Phase {phase}')
for (img, anno) in tqdm(dataloaders_dict[phase]):
img, anno = img.cuda(), anno.cuda()
if phase == 'train':
model.train()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss = loss.cpu().detach().numpy()
else:
with torch.no_grad():
model.eval()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss = loss.cpu().numpy()
loss_epoch.append(loss)
if phase == 'train':
train_loss.append(np.array(loss_epoch).mean())
else:
loss_mean = np.array(loss_epoch).mean()
valid_loss.append(loss_mean)
if best_score > loss_mean:
best_score = loss_mean
torch.save(model, os.path.join("weights/", 'best_model.pth'))
学習させてみましょう! 10分くらい?以内だったと思います。
plt.figure(figsize=(12, 4))
plt.title('Loss trail')
plt.plot(np.array(train_loss), label='train')
plt.plot(np.array(valid_loss), label='valid')
plt.legend()
plt.savefig('loss.png')
plt.show();

学習した結果の可視化です。
予測の可視化
test_dataset = FireDataset(PATHS_FIRE, phase="val", transform=DataTransform())
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model.eval()
for i, (img, anno) in tqdm(enumerate(test_dataloader)):
with torch.no_grad():
img, anno = img.cuda(), anno.cuda()
output = model(img)
output, anno = output.squeeze(dim=1), anno.squeeze(dim=1)
loss = loss_fn(output, anno)
preds = torch.sigmoid(output)
loss = loss.cpu().numpy()
print(f"Loss: {loss}")
for pred, an in zip(preds.cpu().numpy(), anno.cpu().numpy()):
plt.figure(figsize=(12, 4))
plt.title('Prediction with Maks')
plt.imshow(an, alpha=0.7, cmap='gray')
plt.imshow(pred, cmap='jet', alpha=0.3)
plt.colorbar()
plt.show();
作ったモデルで予測してみましょう!



山火事の白いエリアが赤く(山火事確率が高く)なっています。
これでもし山火事が起きたら自動で検知できそうですね!
山火事の影響
山火事は起きると良くないことはわかりますが具体的にはどうでしょうか?
主な影響としてはバイオマスやCO2増加などです。
地球の大切な資源が減ってしまいます
CO2は環境だけではなく、生態系に影響を与えるエーロゾルを放出します
って思ってたら製品化されているものもあるようです
Github
詳細のコードや使用例、環境などは以下に記載しております。
作成したポリゴンも以下においてあります。
お疲れ様です長かったですが、読んで頂きありがとうございます
おまけ もあるので読んでくれると嬉しいです
おまけ
きっかけ
こちらの方が先に可視化されていて、調査がわかりやすく、ここまではっきりとわかればモデリングとかのことも、まとめて書いてもいいかなと思った次第です。感謝です。
モチベーション
最近は PyTroch Lightning や MMシリーズを触っていて Pure Pytorch を書かないと、Torch 2.0 の高速化を体感できていないのと技術が遅れていないかなどの復習のためでした
加えて QGIS 系の作業は忘れることが多いのでアイコンなどのスクショで備忘録のためです。私がアホすぎる、、、ので
最近記事を書いていなかったのでリハビリがてらです。他の記事も参考になればと思います。
ドキュメント作成は課題だと思っているのでその練習です。
あと、衛星データの利用が広まってくれると嬉しいです。
実際の処理作業フロー
参考までに次回同じようなことが起きた時のムーブです。参考までに
参考
- https://ja.wikipedia.org/wiki/山火事
- https://www.restec.or.jp/satellite/sentinel-2-a-2-b.html
- https://news.yahoo.co.jp/articles/f94e1e9464de4eb9a5bbcfb24c4cfd614600c871
- https://www.youtube.com/watch?v=Tnm0jrNhoMY
- https://www.sentinel-hub.com/explore/eobrowser/
- https://aws.amazon.com/jp/free/?gclid=Cj0KCQjwmN2iBhCrARIsAG_G2i47WNuBXze1bT2o7_Li-7IprUxqrqzFsyuypcmGSq4cqdMDT_pIwKsaAjSLEALw_wcB&trk=94c18984-27d1-4395-8dae-cdbf523f1ae5&sc_channel=ps&ef_id=Cj0KCQjwmN2iBhCrARIsAG_G2i47WNuBXze1bT2o7_Li-7IprUxqrqzFsyuypcmGSq4cqdMDT_pIwKsaAjSLEALw_wcB:G:s&s_kwcid=AL!4422!3!568105078079!e!!g!!aws&all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free Tier Types=*all&awsf.Free Tier Categories=*all
- https://registry.opendata.aws/sentinel-2/
- https://qgis.org/ja/site/
- https://gdal.org/
- https://www.docker.com/
- https://gdal.org/programs/gdalwarp.html
- https://kewton.blog/archives/977
- https://colab.research.google.com/?hl=ja
- https://ja.wikipedia.org/wiki/NDVI
- https://github.com/qubvel/segmentation_models.pytorch
- https://albumentations.ai/
- https://arxiv.org/abs/1505.04597
- https://arxiv.org/abs/1412.6980
- https://www.natureasia.com/ja-jp/research/highlight/13818
- https://www.maff.go.jp/j/shokusan/biomass/
- https://spectee.co.jp/report/climate_change_expand_wildfire_world/
- https://github.com/syu-tan/Sentinel-2-Wildfire-detection
Discussion