SenNet + HOA 上位解法と復習まとめ
はじめに
Kaggleにて、3D CT 画像から腎臓の血管を見分ける画像コンペティション SenNet + HOA - Hacking the Human Vasculature in 3D が開催されていました。
受賞者の皆様おめでとうございます!そして参加者の皆様お疲れ様です!
こちらに筆者も2週間強ですが、本気で参加して楽しみました。上位解法を勉強と復習のためにまとめます。参考になれば幸いです。
解法自体の紹介は後半なので概要は飛ばしても良いかも
コンペ概要
このコンペは与えられた CT画像から動脈の部分のみをいかに正確にアノテーションするかを競います。
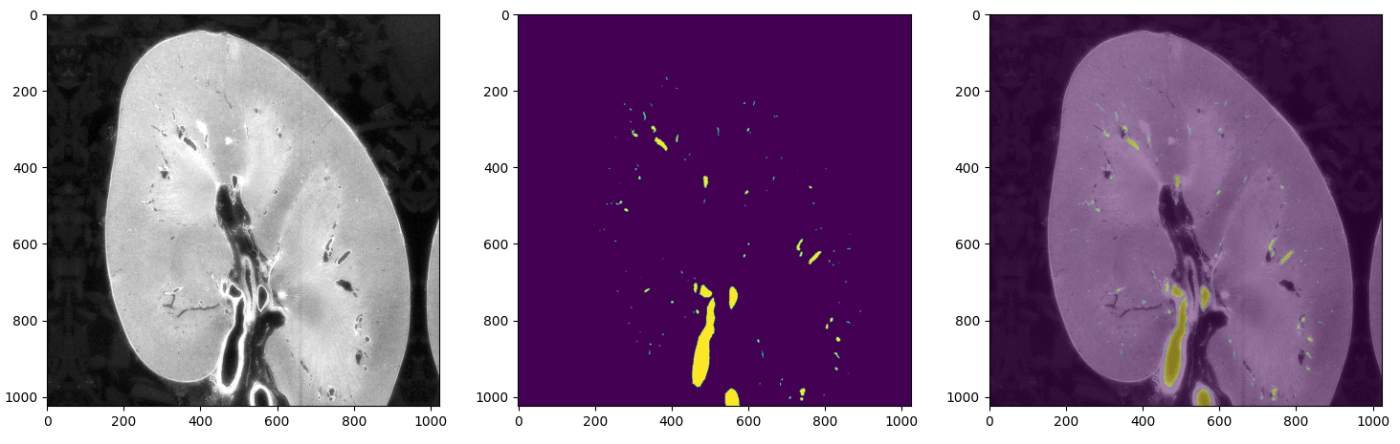
精度指標は Surface Dice というちょっと聞き馴染みのない指標です。
Kaggle Notebook でも実装は公開されています。
計算的には、時系列の画像の前のフレームを合わせた 2x2x2 のボクセル内での予測精度が正しいかを見分ける指標です。
- 9時間制限のノートブックコンペ
- GPU 利用あり
- 賞金とメダルは共にあり
のコンペ設定になっていました。
コンペ特色
- データ処理形式(2D, 2.5D, 3D)
- 指標が風変わり
- データとアノテーションの種類
が特徴的だったと思っています。
1. データ処理形式(2D, 2.5D, 3D)
コンペの配布は .tif による画像形式です。しかしながら、 CT画像を時系列に並べると、3D構造のデータになります。

画像はディスカッション より
これによって、2Dで一般的な CNN を時系列で処理するのか、2.5D で行うのか、3D モデルで全体を処理していくのかなどモデル作成にバリエーションが生まれます。
タスクは基本的に、セマンティックセグエンテーションでインスタンスセグメンテーション(2D, 3D)はみなかったです。1つ1つ分離しなくて良いし、おそらく、セグメントが細かいのでインスタンスにする意味がないからでしょう。
それに加えて、可視化する際もいわゆる 2D の画像で見るだけではわかりずらく、3D での可視化方法などが議題に挙げられていた印象です。

特に、このコンペでは X,Y,Z 方向でのアンサンブルは効果的で、それぞれの方向からの予測と処理が必要でした。
これは予測だけでなく、学習時もデータを増やす効果がありました。
2. 指標が風変わり
Surface Dice という指標が設定されていましたが、一般的には浸透しておらず最適化情報が多くなかったです。
大きな血管だと、Dice (F1 スコア)のような挙動をします。しかしながら、細かい血管ではそうでもなく、スコアが安定しない傾向がありました。細かいセグメンテーションは難しいことが多く、このコンペでも精密な検出が求められました。
この指標は、2値分類後の計算指標なので閾値にも左右されます。
安定した閾値の解析やその定め方が重要でした。
さらに、これは単一フレームでは計算できないために統計量がサンプル数(3名ぶんだけ)と同じで少なかったです。
指標が不安定で統計情報も不安定で CV:LB を相関させるのが大変だった要因の1つだったと思います。
このノートブックでは GPU 処理かつ、カーネル並列で高速化していて参考になりました。検証時間の短縮はとても大きいからです。
3. データとアノテーションの種類
提供されたアノテーションには dense と sparse の2種類のアノテーションがありました。
dense は専門の方が丁寧につけたもので、 sparse はそれよりは劣る質のものです。
アノテーションの領域も重複していたりしていなかったりです。
そして顕微解像度の違いもありました。全体的には 50um くらいがほとんどでしたが 5.2um のものもありました。
データセット全体では 3サンプルで以下のような感じです。
| 名前 | 解像度 | アノテーション |
|---|---|---|
| kidney_1_dense | 50um | dense |
| kidney_1_voi | 5.2um | dense |
| kidney_2 | 50um | sparse |
| kidney_3_dense | 50.16um | dense (上部のみ) |
| kidney_2 | 50.16um | sparse |
LB のデータ
| 名前 | 解像度 | ピクセルサイズ |
|---|---|---|
| kidney_5 | 50.28um | 2 |
| kidney_6 | 63.08um | 4 |
同じ提供者でも情報が違うデータが部分的にあるのでどれが汎化するデータで、どのように利用するかが鍵になってと思います。
それに LB の public と private の割合も 67%:33% と珍しいです。
これが画像フレーム数の 1500枚と500枚とで推論時に処理するパッチサイズの選択に影響してくるあたりを考慮する必要もあったようです。
3名というサンプルの少なさは検証もしにくく、 dense の質の良いアノテーションも限られていました。
LB の情報からも解像度とビンのサイズが違うのでシェイクシェイクして当然ですね、、、
上位解法
解法概要
基本的には、フレームごとに処理をして UNet の 2D モデルでセグメンテーションを XYZ軸のそれぞれでアンサンブルでした。
推論時間との関係で、バックボーンは小さめのモデル構成が多いです。
工夫の点としては、
- Pseudo Label
- Augmentation の調整
- データ追加や選択
が勝因だったのではと思いました。
上位者
前処理
- 16bit の 01 正規化のみ
- 1536 にリサイズ
- 3D 回転による Augmentation
- loss(Focal, Dice, Boundry)
モデル
- 2.5D
- convnext tiny
- UNet
データ
- 提供データ全て (voiあり)
推論時
- TTA 8種類(XYZ 3軸と Filp あたり?)
- 画像サイズの拡大(スケールを2倍にする)
-
torch.compile()で高速化
前処理
- ???
モデル
- 2D
- MaxViT, Efficiennet_v2, SeResNext
- UNet
- 強めの Augmentation
データ
- 提供データ(1,3 dense)
- 擬似ラベル(-> 2, 3 sparse)
- 3 dense の正解部分の閾値を利用して擬似ラベルを正確にする
推論時
- TTA 8種類(XYZ 3軸)
- 閾値の変動調査からモデル選定
- 500フレームを考慮した推論
前処理
- 患者単位でのパーセンタイル処理
- 512x512 サイズ
モデル
- 2D, 3D
- efficientnet-b5
- UNet++
- Augmentation CutMix
- BoundaryDOULoss
データ
- 提供データの全て(voi除く)
- サンプリングに重み付け
- 擬似ラベル(論文でのデータ元)
推論時
- TTA (XYZ 3軸)
- 2Dのオーバラップ処理とガウシアンで平均化
- Opencv2 Canny Filter
前処理
- 512 -> 1024 へ拡大
モデル
- 2D
- effnet_v2, maxvit, dpn
- UNet
- Loss(CE, Dice, Focal, Boundry, Twersky)
データ
- 1_dense, 3_dense
- サンプリングに重み付け
- 擬似ラベル(腎臓+脾臓)
推論時
- 3Dリサイズ
前処理
- 512 -> 1024 へ拡大
モデル
- 5スライス 2.5D
- EfficientNet B5
- UNet
- Augmentation
- Crop -> CutMix
- Loss(BoundaryLoss + Focal)
データ
- 1_dense 学習?
- 2,3 検証
推論時
- um/voxel でのサイズの統一
- 512 スライディングウィンドウで 50% オーバラップ
- TTA (XYZ)
モデル
- 2D
- MaxVit
- UNet カスタム
- EMA
- Augmentation
- 激しめ + Mixup + CutMix
- Loss(Dice smooth)
データ
- 1,3
推論時
- 確率閾値
- 512 スライディングウィンドウで 50% オーバラップ(256)
- TTA (XYZ)
前処理
- 患者ごとにパーセンタイル処理(2−98)
モデル
- 2D
- MaxVit (4パネル分割)
- UNet
- Augmentation
- 単純なもののみ
- Loss(Dice smooth)
推論時
- TTA (XYZ)
前処理
- 患者ごとにパーセンタイルで最大最小で01正規化処理
- 腎臓エリアのみのクロップ
- 高解像度化(1536, 1920)
モデル
- 2.5D (5, 7スライス)
- resnest14d、resnest50d、maxvit_tiny + efficientnet_b4
- UNet
- Augmentation
- 単純なもののみ
- Loss(Dice smooth)
データ
- 学習1、検証3
推論時
- TTA (XYZ, Flip, Transpose, Brightness)
- サイズ復元時にピクセルずれの修正
- 確率閾値で 0.25
まだ出来っていない解法もあるので適宜追加していきたいと思います!
上位者との差異と効果的なこと
Gold 圏内でいくつかみられるのは以下です。
-
- 高解像度化
-
- 学習データの増加(擬似ラベルも含めて)
-
- BoundryLoss
1. 高解像度化
高解像度が良いというよりは、解像度を調整することで private の推論時での解像度誤差をなくしているように感じます。モデルの学習データに近いほどモデルも正確になり、解像度が高いとポジティブの領域が増えて小さい場所も検知しやすくなるからだと思います。
bin x4 の解像度の情報から備えていたように感じます。
2. 学習データの増加(擬似ラベルも含めて)
特に、入賞者は全データでの学習や外部データを入れていて、それらが汎化性能に反映しているようです。
これもCVが安定しないので検証が不安定なままよく決断できて、しゅごぃ〜と感じます。
サンプルデータ自体が少ない時はとりま、全部入れちゃえ?!
3. BoundryLoss
Surface Dice の指標に近い最適化の損失関数が BoundryLoss だったようです。
境界誤差の距離を狭めるので全体統計分布で Dice 最適よりも小さな物体について良い予測ができる?的な感じでしょうか
何より、このコンペは 検証 方法が一番大事だったと思います。
サブ選択にしても、CV:LBバラバラで効果性の判断が難しかったからです。
それ以外の解法にも、色んな人の様々な検証や方法がとても多く、手法自体のバリエーションという意味では豊かだったのではないでしょうか。他の人の 努力や工夫 が見えて本当に楽しいです。
その他
他にもこちらのディスカッションでの議論は有用なことが多く、参考になりました。読むことをお勧めします。
他にも議題に上がっていた閾値や前処理ですが、上位を見るとあまり関係ないように思います。
強いモデルができれば閾値に関係なく予測できるからそちらの方が堅牢でしょう。
実際に、動脈の部分の予測ですが閾値を変えると、まずは静脈が FP として上がってきます。
この差は周辺の輝度が特に関係していて前処理のパーセンタイルの幅を狭めるとこのエッジが判断しにくくなり、モデルの精度が低下します。さらにこれは解像度が変更されると領域の広さが変更されるので、検知が曖昧になり領域が広いエリアも精度低下を起こすためでした。(著者のLate submission と CV の画像判読の挙動から)
なので短期的には閾値をかなり低く予測すれば、広い領域も検知できて、private でも高いスコアは出ましたが根本の解決ではないからです。
Kaggle に本気参加するのは3回目くらいですがシェイクの激しい転落コンペばかりだったので勉強にはなりましたが大変です。
教訓ですが個人的には、 サンプル数が少ない , 指標が一般的でない ものは要注意です。
さいごに
最後まで読んで頂きありがとうございます。
皆さんのご参考になれば嬉しいです。また、間違ってるところがあれば教えて欲しいです。
医療データのコンペは多く 2D, 2.5D, 3D 処理は当たり前になりつつあるのでそこでの精度低下の要因や向上のための検証方法などのコツを掴んでいきたいですね。
またコンペで一緒になった際はよろしくお願いします!
おまけ
こちら以外にも記事執筆やコンペ解法記載をしているのでご参考になれば幸いです
衛星データ解析として、宙畑のライターもしています。
SAR 解析をよくやっていますが、画像系AI、地理空間や衛星データ、点群データに関心があります。
勉強している人は好きなので楽しく絡んでくれると嬉しいです。
Discussion