【論文】基盤モデル DINOv3 を読んで動かしてみた
はじめに
遅ればせながら、DINOv3 について読んで動かしてみた記事です。
解説というほどではないですが、DINOシリーズの改善点や使い方のメモを残しています。

Meta AI DINOv3 より
前半は論文についての内容で、後半は実装についての内容です。
CV領域が専門ではないので間違っていたいらお許しください><
おさらい
背景:自己教師あり学習と画像基盤モデルでの発展
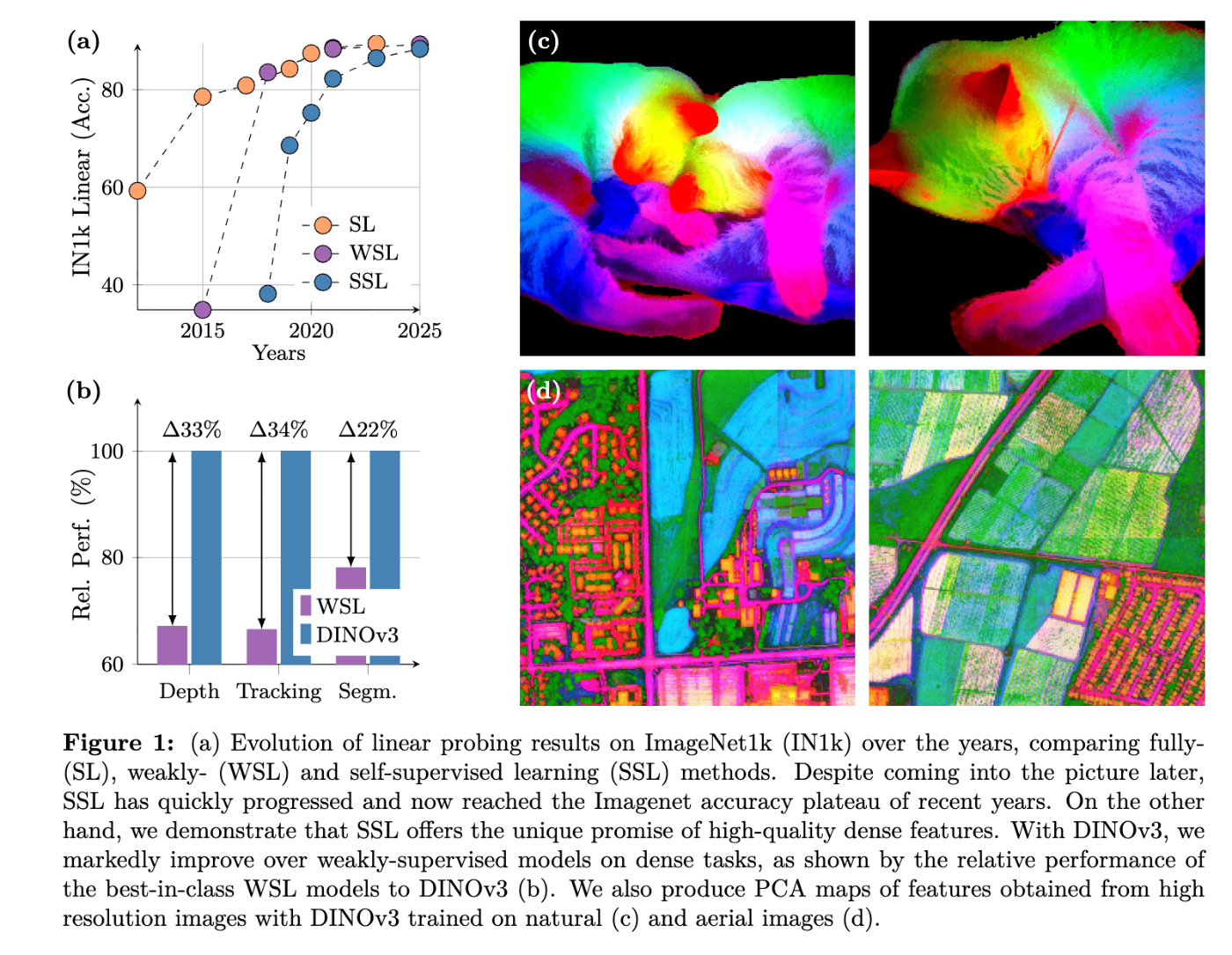
コンピュータビジョン(Computer Vision;CV) は「画像や映像をコンピュータに理解させる」ことを目指す分野です。身近な例では、スマートフォンの顔認証、SNSの画像検索、自動運転車の周囲認識などがあり、私たちの日常生活に深く浸透しています。これらの技術は「画像処理」や「機械学習」、特に近年では「深層学習(ディープラーニング)」によって支えられています。深層学習では大量のデータを入力し、ニューラルネットワークがその中からパターンを学び、分類や検出といったタスクを実行できるようになります。
1. 教師あり学習とその限界
従来、CVの研究や応用は「教師あり学習」に大きく依存してきました。教師あり学習とは、入力データに正解ラベルを付与し、それをもとにモデルを訓練する手法です。例えば犬や猫の画像を何千枚も集めて「これは犬」「これは猫」と人間がラベルを付け、その情報を使ってモデルを学習させるのです。この方法は非常に効果的で、ImageNet や COCO といった大規模なラベル付きデータセットの登場によって、画像認識の性能は飛躍的に向上しました。
しかし、この手法には明確な弱点があります。ラベル付けには膨大なコストと時間がかかる点です。一般的な物体(犬・猫・車など)なら比較的容易にラベルを付けられますが、医用画像や衛星写真のような専門的な分野では、高度な知識を持つ専門家がラベルを付与しなければなりません。さらに、実世界で新しいデータや多様なドメインが次々に現れる中で、常に正確なラベル付きデータを集め続けることは困難です。ここで「ラベルのいらない学習」、すなわち 自己教師あり学習(Self-Supervised Learning, SSL) が注目されるようになりました。

2. 自己教師あり学習(SSL)の登場
自己教師あり学習は「データそのものを教師として利用する」学習方法です。具体的には、ラベルの代わりにデータ内部の関係性を利用してモデルを訓練します。例えば、画像の一部を隠して残りから推測させたり、同じ画像を異なる角度や色調に変換して「これは同じ画像だ」と学習させたりします。こうすることで、モデルは自然に「画像の本質的な特徴」を捉える能力を獲得します。

Masked Autoencoders Are Scalable Vision Learners より
SSLの強みは、ラベルなしデータを無限に利用できる点にあります。インターネットや衛星から得られる膨大な画像データは、通常ラベルが付いていません。しかしSSLならそれらを直接使えるため、従来の教師あり学習に比べてはるかにスケーラブルです。さらに、一度学習した特徴表現は、ダウンストリームタスクと言われる、画像分類、物体検出、セグメンテーションなど多様なタスクに転用できるため、応用範囲も広がります。これが正に次で登場する基盤モデルの 基盤 の由来ですね。

Unsupervised Learning of Visual Features by Contrasting Cluster Assignments より
3. 基盤モデル(Foundation Models)の登場
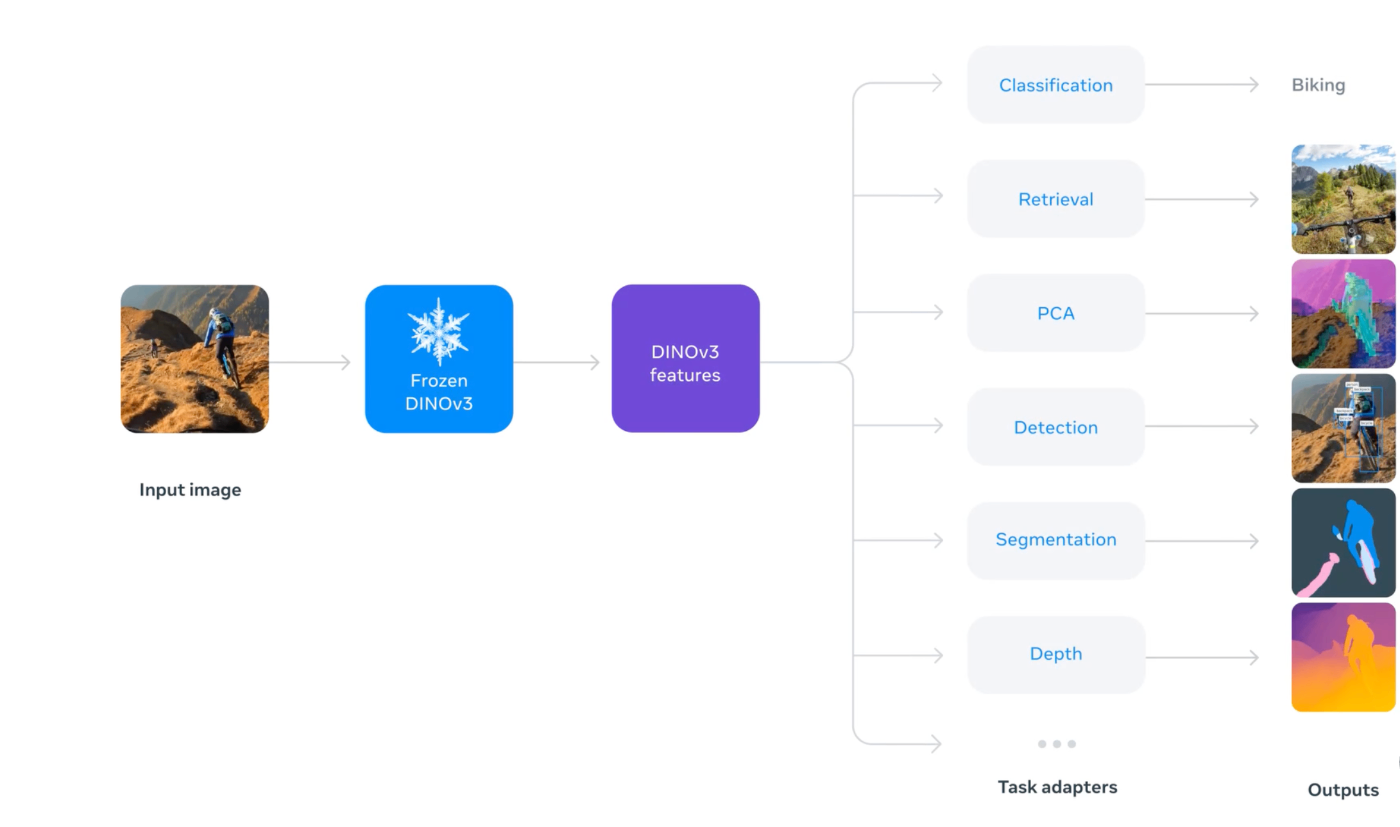
自然言語処理の分野では、大規模言語モデル(Large Language Model; LLM) が登場し、翻訳や要約、会話など多くのタスクを一つのモデルでこなせるようになりました。これは事前にAIが知識習得が可能になったことを示しています。この成功はCV分野にも影響を与え、「画像基盤モデル(Vision Foundation Models)」という考え方が広がっています。これは、膨大な画像データを使って汎用的な特徴を学習し、その結果得られるモデルを様々なダウンストリームタスクに再利用するアプローチです。こうしたモデルは、一度大規模に訓練すれば、追加のデータや計算コストをあまりかけずに幅広い問題に対応できるという大きな利点があります。
DINOv3 より
例えば、DINOシリーズのような自己教師ありモデルは、学習後に得られる特徴を固定して使うだけでも強力な性能を発揮します。これは、研究者やエンジニアが限られたリソースでも高性能なモデルを活用できることを意味し、応用の幅を一気に広げました。
4. グローバルとローカルの特徴量の重要性
ここで理解しておきたいのが、「特徴量」の種類です。画像を理解するには、大きく二つの観点があります。
- グローバル特徴量(global features):画像全体の意味を表す情報。例えば「この画像は猫だ」と判断するのに必要な抽象的な表現。分類タスクに強い。
- ローカル特徴量(密な特徴量, dense features):画像中の特定の位置や領域ごとの情報。例えば「この部分は猫の耳」「ここは草」などの細かい構造を捉える。セグメンテーションや物体検出、3D復元などに必須。
理想的な基盤モデルは、この両方をバランス良く学習できる必要があります。しかし、現実には「モデルを大きくして長時間学習するとグローバル特徴は良くなるがローカル特徴が弱まる」という課題が報告されています。このジレンマをどう解決するかが、最新のDINOv3の改善テーマとなっています。
こうした背景を踏まえて読むと、DINOv3のような最新の研究が「どの課題を解決しようとしているか」が一層理解しやすくなるでしょう。
DINOv3
DINOv3 とは、Facebook AI Researchの研究者らによって提案された DINO (self-distillation with no labels)というシリーズの第3弾です。DINOのアルファベットの取り方が頭文字から離れすぎて気になりますよね笑。論文間違えたかな?って確認するほどですね。恐竜(Dinosaur)とかの略??

https://ai.meta.com/dinov3/#applications より
DINOv1 の時は、自己教師あり学習と知識上流による新規提案でしたが、今となっては基盤モデルの構築方法そのものを示していますね。そして、この基盤モデルがシリーズがv2、v3を経るごとにより多くの ドメイン(画像の分野) や タスク(機械学習のソリューション) に適応して、高精度になるための改善手法が論文では紹介されています。
論文
では、実際に論文について注目していきましょう。
概要
全体の構成的には、以下の3点が主張となっております。
- 高解像度高密度特徴量
- 多用途な基盤モデル
- SOTA性能
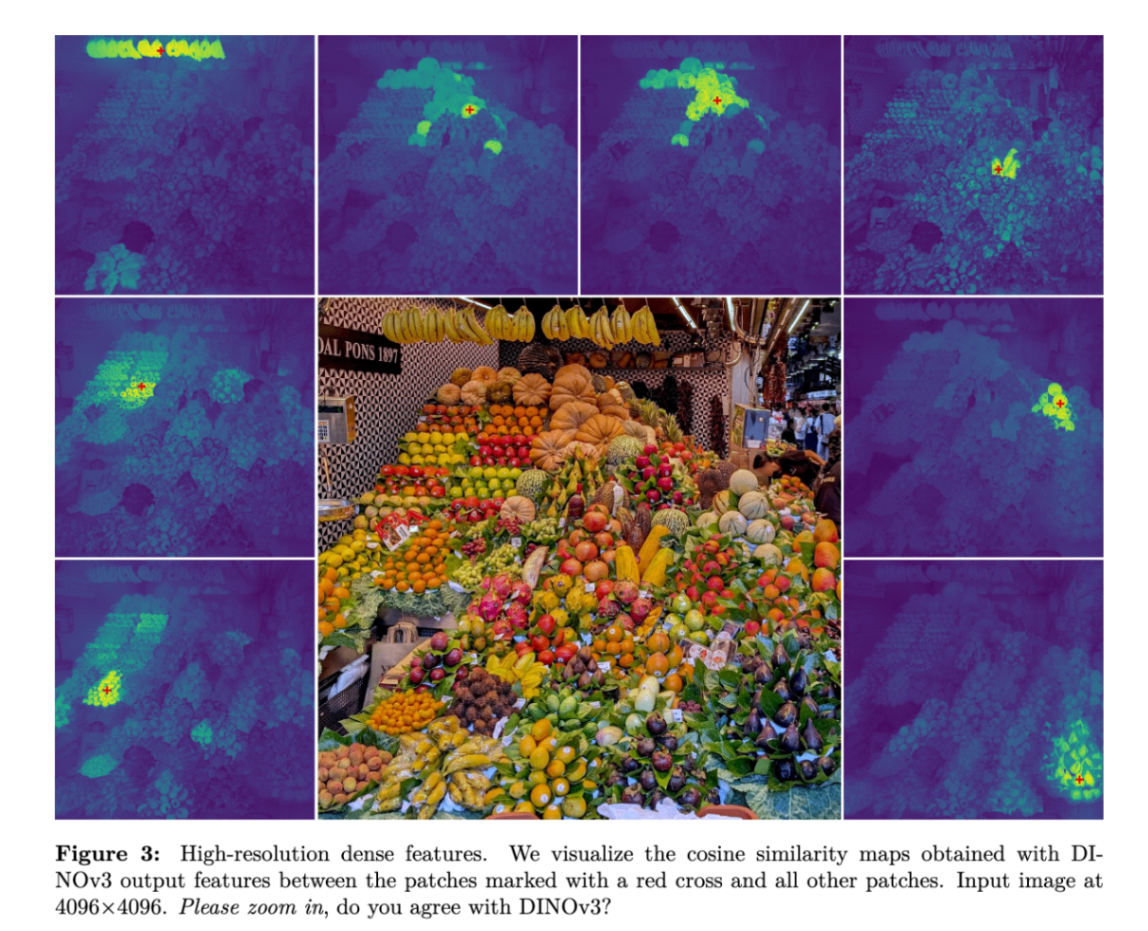
高解像度高密度特徴量
「高解像度高密度特徴量(High-resolution dense features)」 は、DINOv3などのビジョン基盤モデルが生み出す、画像内の各ピクセルやパッチに密接に関連する、詳細かつ質の高い視覚的表現を指します。これらの特徴量は、画像全体だけでなく、画像内のオブジェクトの境界、部分、さらにはテクスチャといった局所的な物体や詳細情報を含んでいます。
DINOv3 より
この種の特徴量は、以下のような点で極めて重要です。
- 汎用性と性能:DINOv3は、これらの特徴量を用いて、ファインチューニングなしで広範なビジョンタスクにおいて専門的な最先端モデルを凌駕する優れた性能を達成しています。いわゆる、ゼロショット(Zero Shot) での性能です。
-
多様なビジョンタスクへの応用:物体検出、セマンティックセグメンテーション、深度推定、3D構成、ビデオセグメンテーション追跡、樹高推定など、ピクセルレベルの予測や密な認識を必要とするタスクにおいて特に強力みたいです。
Versatileって単語が使用されていましたがトレンドにも出てきそうな感じですね。 - シーンの理解とロバスト性:自己教師あり学習モデルは、入力分布の変化に対して堅牢であり、画像内の主要なオブジェクトと背景を明確に区別し、オブジェクトの識別部分に焦点を当てる能力を示します。また、背景の変化やオクルージョン(画像上の邪魔をしているものを示す言葉)に対しても強いロバスト性や柔軟性を持っています。動的な適応は TransFormer の得意分野な気がしていてこのような恩恵を得ている気がします。
密度特徴量の抽出過程
DINOv3において、これらの特徴量の生成と品質向上は、複数の先進的な自己教師あり学習技術とモデルサイズのスケールアップ戦略の組み合わせによって実現されています。
DINOv3 より
-
自己教師あり学習(SSL):
- DINOv3は、ラベルなしデータから学習する自己教師あり学習(SSL) のアプローチを採用しており、手動でのデータアノテーションの必要性を排除し、大規模なデータセットとより大きなアーキテクチャへのモデルのスケーリングを可能にします。
- DINOv3の訓練レシピは、DINOとiBOTの損失関数を組み合わせています。
- DINOは、主にクラス([CLS]: BERTとか初登場?して事前学習する際に分類タスクのロス関数に使用されるから Class の短縮系で CLS)トークンから抽出される特徴に焦点を当てた画像レベルの目的に基づいています。これは、画像内のセマンティックなセグメンテーションやオブジェクトの境界に関する明示的な情報を含んでいます。
- iBOTは、マスクされたパッチトークンを用いて学習するパッチレベルの目的(Masked Image Modeling, MIM)に焦点を当てています。iBOTは、オンライントークナイザーを用いて、高レベルの視覚的セマンティクスを学習し、画像パッチのパターンレイアウトを発見する能力を示します。これにより、モデルは画像内の内部構造をモデル化する上で優位性を持つことができます。言葉は異なりますが割と定番の手法で、BERTのMLM(Masked Language Model)で知られていますね。
- さらに、特徴量をバッチ内で均一に分散させるために、KoLeo正則化項が追加されています。これは、DINOv2でも重要なコンポーネントとして導入されました。
-
データとモデルのスケーリング:
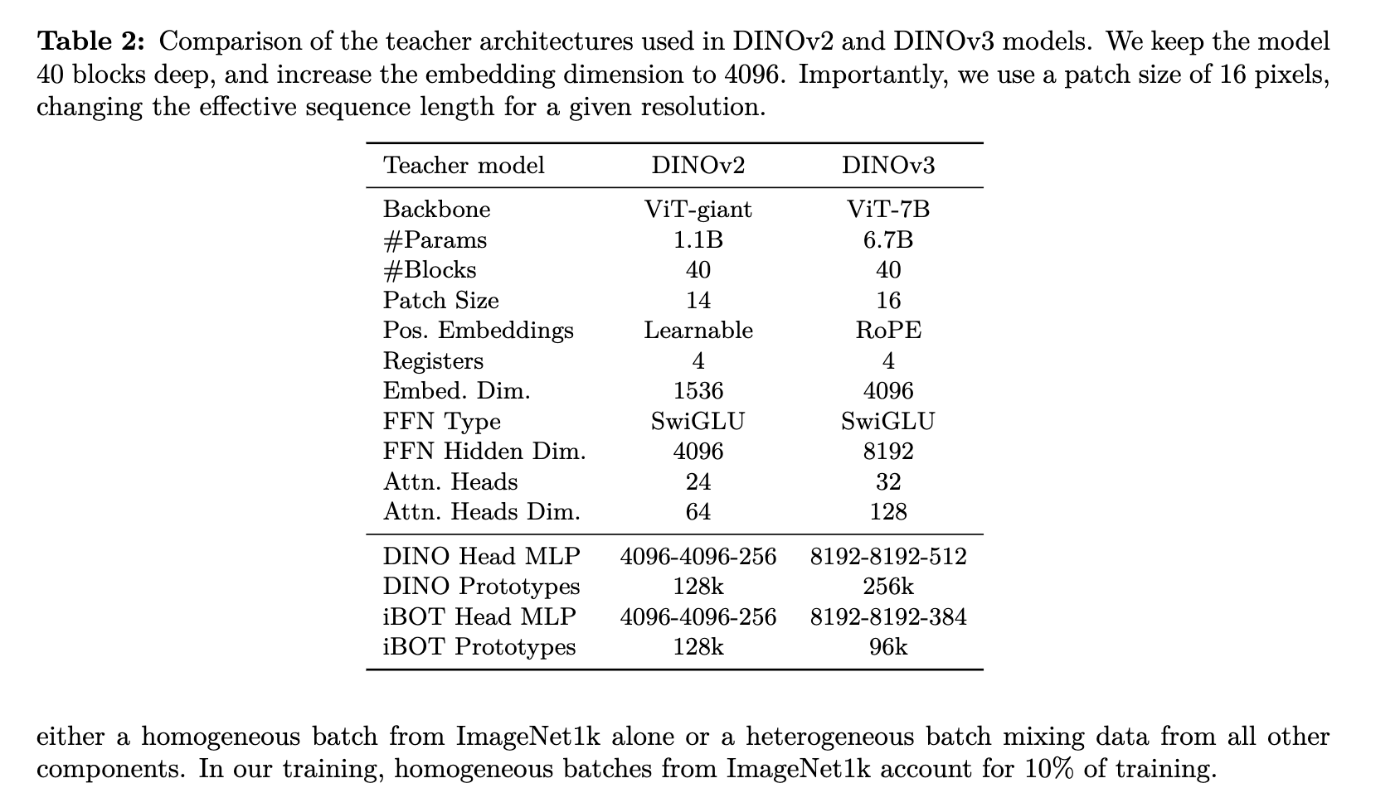
- DINOv3は、データセットとモデルサイズの両方をスケーリングするメリットを最大限に活用しています。Facebook AI ResearchがDINOv3のために構築したLVD-1689Mのような大規模で多様なデータセットを使用し、これはウェブ画像と専門データセットの組み合わせによって構成されています。
- モデルサイズは、DINOv2の1.1Bパラメーターモデルから7Bパラメーターモデルへと拡大されました。このような大規模モデルの知識は、より小さなViT-S, ViT-B, ViT-LやConvNeXtベースのアーキテクチャなどの「DINOv3ファミリー」モデルに蒸留され、リソース制約の異なる様々なマシンに対応しています。って言っても CNN とかに比べると大きいんですけどね、、、、
-
高密度特徴マップの安定化とピクセルレベルの適応:
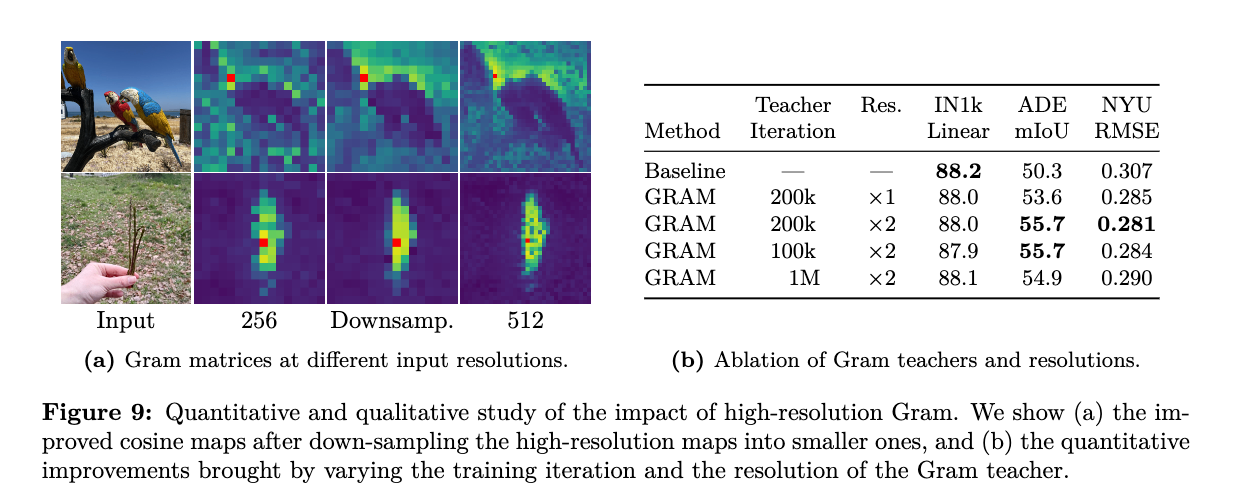
- DINOv3の主要な技術的貢献の一つは、Gramアンカリングという新しい手法の導入です。これは、長時間の訓練スケジュール中に発生する高密度特徴マップの劣化という既知の未解決問題に効果的に対処します。Gramアンカリングは、学生と教師のパッチ間のコサイン類似度が高くなるように正則化することで、密な表現の品質を向上させます。
- また、高解像度のピクセルレベルでの説明性が可視化できます。これは、事前学習の終わりに画像の解像度を短期間(例:518×518ピクセル)増加させることで、セグメンテーションや検出のようなピクセルレベルのタスクにおいて、小さなオブジェクトが見えなくなるという問題を改善します。
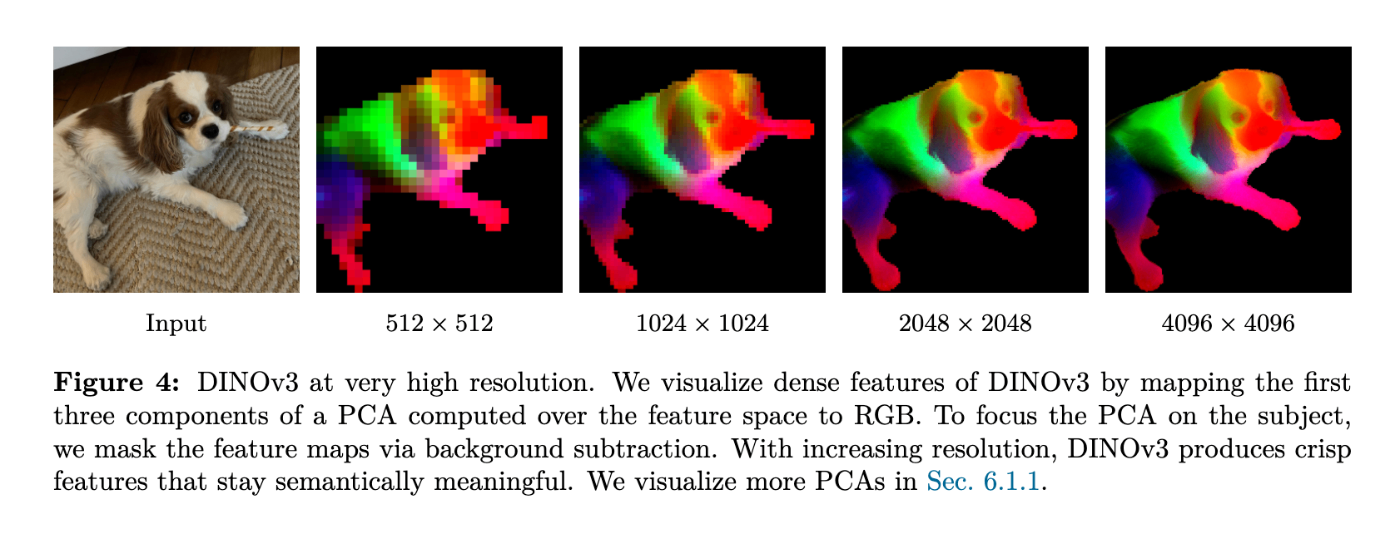
- これらの改善により、DINOv3は多様な解像度間で安定した高画質な密な特徴量マップをネイティブに提供できるようになりました。例えば、4096×4096のような非常に高い解像度でも高品質な特徴マップが得られ、視覚化によってその有効性が示されています。
これらの要素が組み合わさることで、DINOv3は従来の自己教師あり学習や弱教師あり学習の基盤モデルを大幅に上回る、優れた高解像度高密度特徴量を生成し、幅広い視覚タスクにおいて最先端の性能を発揮する汎用性の高い基盤モデルとしての地位を確立しています。むしろ、後続の研究での有用性や精度主張の方法は、このシリーズ論文を見習っている印象です。
多用途画像基盤モデル
多用途画像基盤モデル (Versatile Vision Foundation Models) とは、特定のタスクやドメインに特化することなく、多様な視覚タスクや画像分布に対して「そのまま(ファインチューニングなしで)」優れた性能を発揮する能力を持つモデルと記載されていました。これらのモデルは、現代のコンピュータービジョンにおいて中心的な構成要素となっており、単一の再利用可能なモデルを通じて、タスクやドメインを超えた広範な汎化を可能にします。まぁ、なんでも使えるってことが主張したいんでしょうね。
その重要性は以下の点に集約されます。
- タスクによらない性能:画像分類のような画像レベルのタスクから、セグメンテーションのようなピクセルレベルのタスクまで、あらゆるタスクにおいて、特別な調整なしで(ファインチューニングなしで)機能する視覚的特徴量を生成します。これにより、画像処理システムにおける画像の利用が大幅に簡素化されます。こちらは DINOv2 に記載してありました。
- 高品質で密な特徴量:画像内の詳細なセマンティクスや境界情報を含む、高解像度で密度の高い(ピクセル単位の)特徴量を生成します。これは、高精度な認識や予測を必要とする物体検知、セマンティックセグメンテーション、深度推定などのタスクにおいて特に強力です。
- スケーラビリティと効率性:手動のアノテーションが不要なため、大規模なデータセットとより大きなアーキテクチャへのモデルのスケーリングを可能にします。単一のモデルが複数のタスクに対応できるため、推論時(フォワードパス)の計算コストを大幅に削減できます。
基盤モデルの実現のために
DINOv3は、上記の多用途画像基盤モデルのビジョンを実現するための主要なマイルストーンとして位置づけられています。その実現は、先進的な自己教師あり学習技術、大規模なデータおよびモデルのスケーリング戦略、および特定の技術的貢献の組み合わせによって達成されています。
-
自己教師あり学習 (SSL) の改善
- DINOv3は、手動アノテーションの必要性を排除し、ラベルなしデータから学習する自己教師あり学習のアプローチを採用しています。
- DINOv2ではDINOとiBOTのヘッド重みを共有していましたが、DINOv3では大規模な学習において逆効果であることが判明し、DINOとiBOTのヘッド重みを分離しています。
- Sinkhorn-Knopp正規化をDINOおよびiBOTの教師側ソフトマックス・センタリングステップに導入し、バッチ正規化を改善しています。
-
データとモデルのスケーリング
- 大規模データセット「LVD-1689M」:DINOv3は、Instagramの公開投稿から収集されたウェブ画像を基に、階層型k-meansクラスタリングと検索ベースのキュレーションを組み合わせて構築された16.89億枚のキュレーション済みデータセット「LVD-1689M」を使用しています。これにより、幅広い視覚的概念を網羅し、モデルの汎化能力を高めます。
- 70億パラメータモデル:DINOv3は、DINOモデルを70億パラメータ規模にまで拡大することに成功しました。これにより、顕著な性能向上が達成されています。
- 知識蒸留によるモデルファミリー:大規模な70億パラメータモデルの知識は、より小さなViT-S、ViT-B、ViT-L、およびConvNeXtベースのアーキテクチャなどの「DINOv3ファミリー」モデルに蒸留されます。これにより、リソース制約の異なる様々な展開シナリオに対応できるスケーラブルなソリューションが提供されます。
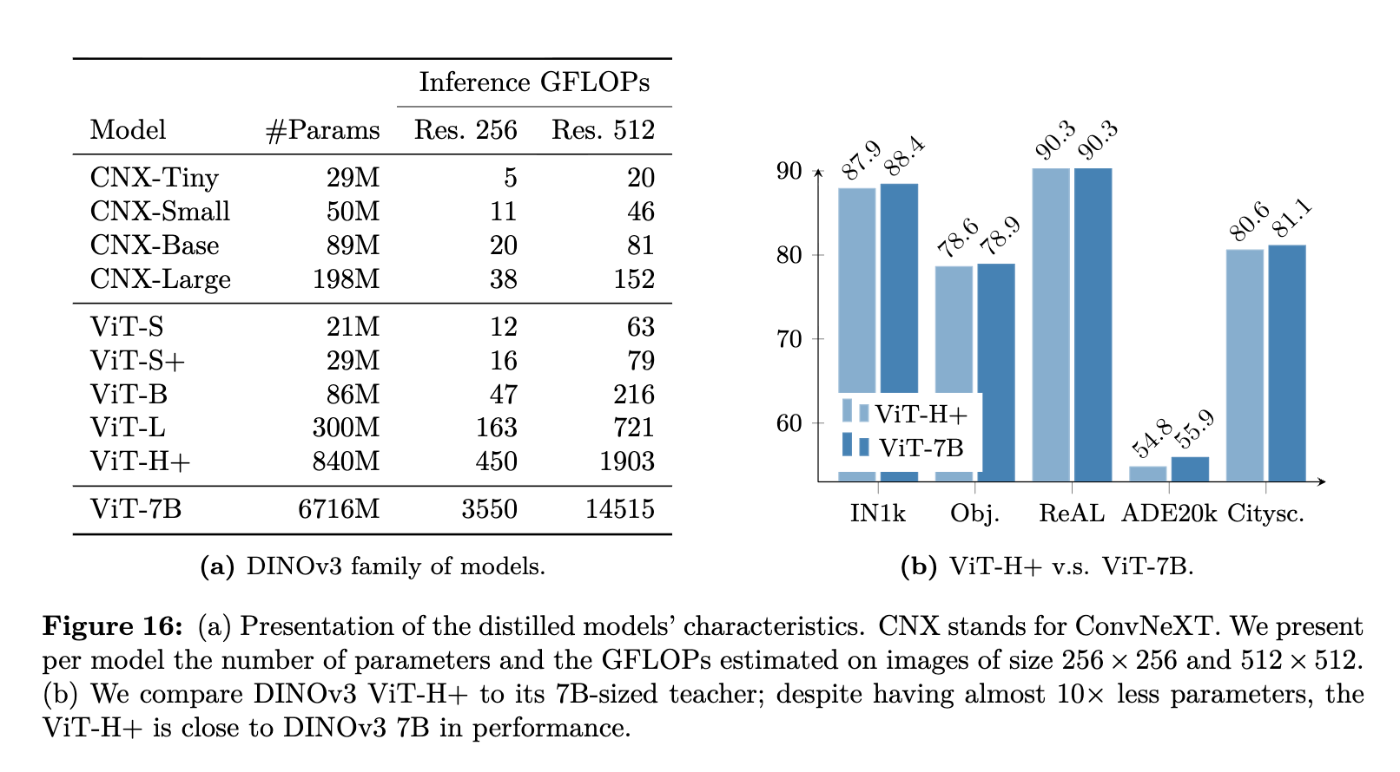
DINOv3 より
-
技術的貢献
- Gramアンカリング:長時間の学習スケジュール中に発生する密な特徴マップの劣化という未解決の問題に対処するための新しい手法です。これは、学生と教師のパッチ間のコサイン類似度が高くなるように正則化することで、密な表現の品質を向上させます。これによりiBOTの損失がより速く減少する効果も確認されています。
- 高解像度適応:事前学習の最後に画像の解像度を短期間増加させる(例:518×518ピクセル)ポストホック戦略です。これにより、セグメンテーションや検出のようなピクセルレベルのタスクにおいて、小さなオブジェクトが見えなくなる問題を改善し、多様な解像度間で安定した高画質な密な特徴マップをネイティブに提供できるようになります [266, Figure 3, Figure 4]。
- テキストアライメント (dino.txt):DINOv3モデルのCLSトークンと出力パッチをテキストにアライメントさせるためのポストホック戦略です。これにより、zero-shot分類やオープンボキャブラリセグメンテーションなどのタスクが可能になります。
ダウンストリームタスク
DINOv3は、これらの革新的なアプローチにより、幅広いビジョンタスクにおいて最先端の性能を発揮する多用途ビジョン基盤モデルとしての地位を確立しています。
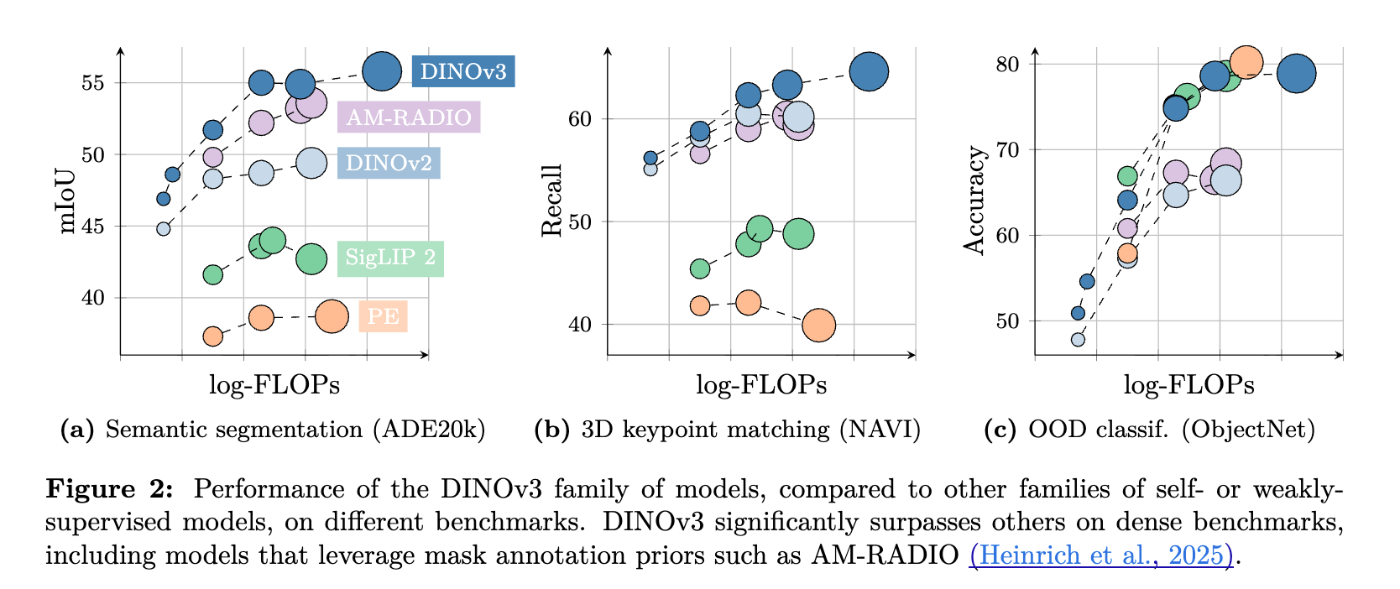
- 密な認識タスクの卓越した性能:セマンティックセグメンテーション (ADE20k, Cityscapes, PASCAL VOC)、深度推定 (NYUv2, KITTI) において、DINOv3は以前の自己教師あり学習モデルや弱教師あり学習モデルを大幅に上回る結果を示しています [280, 281, 296, 297, Table 3, Table 12]。例えば、ADE20kでは、SSLベースラインより6 mIoUポイント以上、WSLベースラインより13ポイント以上優れています。
- 物体検知:DINOv3バックボーンはフリーズされたままで、軽量な検出モデルをトレーニングするだけで、既存の最先端モデルを上回る性能を達成しています [287, 288, Table 10]。
- 3D理解:VGGTパイプラインの画像特徴抽出モデルとしてDINOv3を組み込むことで、カメラ姿勢推定、密なマルチビュー推定、および2ビューマッチングにおいて最先端の結果を達成しました [299, Table 13]。
- 動画タスク:動画セグメンテーション追跡や動画分類タスクでも高い性能を発揮します [284, 285, Table 5, Table 6]。
- 地理空間データ:DINOv3の学習レシピは汎用的であり、衛星画像のような異なるドメインにも適用可能です。衛星画像で事前学習されたDINOv3モデルは、樹高推定や多様な地理空間分類・セグメンテーションタスクにおいて最先端の性能を示します [308, 310, 311, 312, 314, Table 17, Table 19]。

DINOv3 より
- OCR集中型データセット:道路標識、ロゴ、製品分類など、文字認識を必要とするタスクにおいても、DINOv3はDINOv2や既存の弱教師ありモデルと比較して優れた性能を発揮します [377, 381, Table 25]。
上記の結果から、DINOv3が幅広いビジョンタスクにおいてファインチューニングなしで強力な性能を提供し、単一の基盤モデルで多様な実用アプリケーションをサポートする可能性を表しています。
SOTAの達成
各モデルが様々なビジョンタスクでSOTAを達成している点について詳しくみていきます。
DINOv3は、「汎用ビジョン基盤モデル」として、ゼロショットで幅広い設定において専門的な最先端モデルを凌駕する優れた性能を発揮することを目的としています。特に、以前の自己教師あり学習(SSL)および弱教師あり学習(WSL)の基盤モデルを大幅に上回る高品質な高解像度高密度特徴量を生成し、これにより様々なビジョンタスクでSOTAを達成しています。

https://ai.meta.com/dinov3/#applications E. aluating DINOv3's Performancより
-
密な認識タスク(Dense Prediction Tasks)での性能
-
セマンティックセグメンテーション:
- ADE20kデータセットにおいて、DINOv3は自己教師あり学習ベースラインを6 mIoUポイント以上、弱教師あり学習ベースラインを13ポイント以上上回る性能を示しています。また、SAMから蒸留されたPEspatialを6ポイント以上、AM-RADIOv2.5を約3ポイント上回ります [205, Table 3]。
- Cityscapesデータセットでは、81.1 mIoUという最高のmIoUを達成し、AM-RADIOv2.5を2.5ポイント、他の全てのバックボーンを少なくとも5.5ポイント上回っています。
- 軽量なデコーダーを組み合わせた場合、ADE20kで63.0 mIoUを達成し、ONE-PEACEと同等のSOTA性能を示しています [224, Table 11]。COCO-StuffとVOC 2012のデータセットでも、以前の全てのモデルを上回っています。
-
深度推定:
- NYUv2、KITTI、ETH3D、ScanNet、DIODEなどのデータセットで、相対深度推定において新たな最先端の性能を達成しています [227, Table 12]。これは、他のベースラインがバックボーンのファインチューニングを必要とするのに対し、DINOv3では凍結されたバックボーンを使用している点が特筆されます。
- SatLidar1M val、SatLidar1M test、Open-CanopyなどのベンチマークでMAEを削減し、新たなSOTAを確立しています [239, Table 17]。
-
3D理解(キーポイントマッチング、マルチビュー推定、ビューマッチング):
- 幾何学的対応において、DINOv3は他の全てのモデルを上回り、2番目に優れたDINOv2を4.3%のrecallで改善しています [206, Table 4]。セマンティック対応でも、DINOv2を2.6%、AM-RADIOを1.9%上回っています。
- マルチビュー推定(DTU)およびビューマッチング(ScanNet-1500)でもSOTAを達成しています。
-
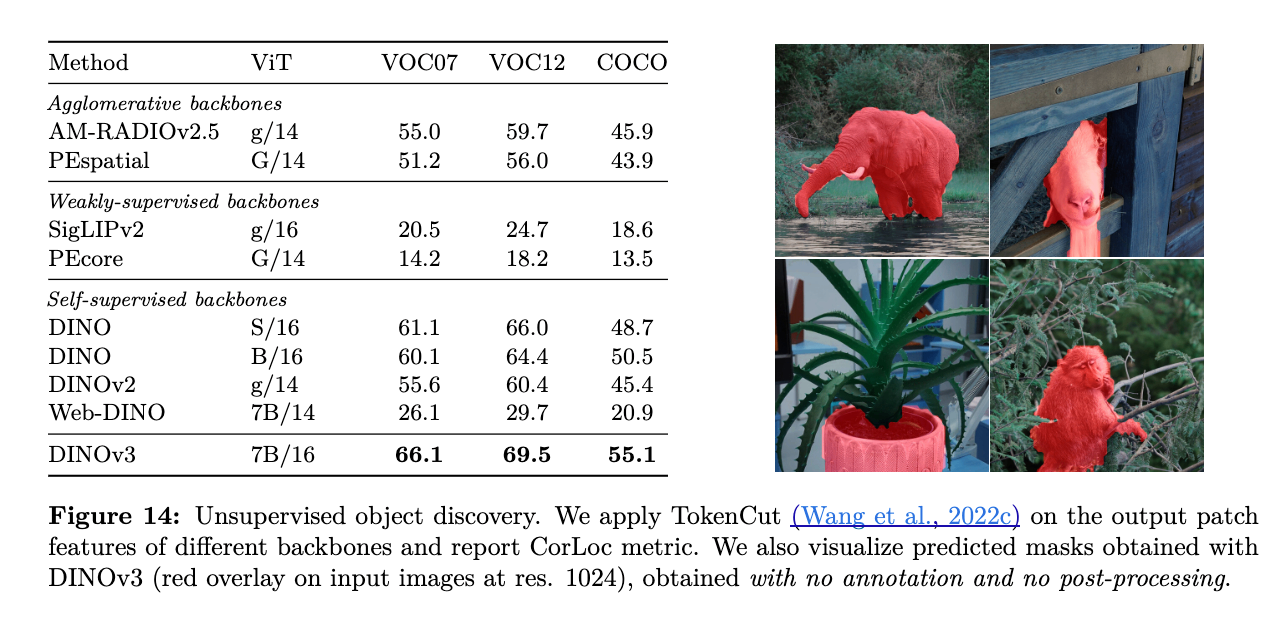
教師なしオブジェクト発見:
- VOC 2007、VOC 2012、COCO-20kデータセットにおいて、前身のDINOv2や他の自己教師あり学習、弱教師あり学習、アグロメレーティブなバックボーンを上回り、VOC 2007では5.9 CorLocの改善を達成しています [208, 209, Figure 14]。DINOv3の高密度特徴量が、セマンティックに強く、かつ局所化が正確であることを裏付けています。
-
動画セグメンテーション追跡:
- DAVIS 2017、YouTube-VOS、MOSEデータセットにおいて、DINOv3はこれまでの全ての自己教師あり学習バックボーンを大幅に上回り、弱教師あり学習モデルと比較しても競争力のある結果を示しています [211, Table 5]。

DINOv3 より
- DAVIS 2017、YouTube-VOS、MOSEデータセットにおいて、DINOv3はこれまでの全ての自己教師あり学習バックボーンを大幅に上回り、弱教師あり学習モデルと比較しても競争力のある結果を示しています [211, Table 5]。
-
セマンティックセグメンテーション:
-
グローバルタスク(分類)での性能
-
画像分類(OOD/ロバスト性):
- ImageNet-Rで+10%、-Sketchで+6%、ObjectNetで+13%と、DINOv2よりも大幅に性能を向上させています。
- ImageNet-Rと-Sketchでは、SigLIP 2やPEといった弱教師あり学習モデルと同等の結果を達成し、ImageNet-AとObjectNetではPEに肉薄し、SigLIPv2を上回っています。
- 最高のロバスト性(ImageNet-C) を達成しています。
-
ファイングレイン分類:
- DINOv3は、これまでの全てのSSL手法を上回り、弱教師あり学習モデルと比較しても競争力のある結果を示しています。特に、困難なiNaturalist21データセットで89.8%の最高精度を達成し、PEcore (87.0%) を上回っています [216, Table 8]。
-
インスタンス認識:
- OxfordとParisのランドマーク認識、Metの美術品データセット、AmsterTimeのストリートビュー画像マッチングといったベンチマークで、DINOv3は高い性能を達成しています [217, Table 9]。特にDINOv2と比較して、Oxford-Hで+41% mAP、弱教師あり学習モデルと比較しても+34% mAPと大幅な改善が見られます。
-
OCR集中型データセット:
- 道路標識、ロゴ、製品分類など、文字認識を必要とするタスクにおいて、DINOv3はDINOv2やPE-coreといった既存のモデルと比較して優れた性能を発揮します [281, Table 25]。
-
画像分類(OOD/ロバスト性):
-
ダウンストリームアプリケーション(軽量版の使用)
-
物体検知:
- 凍結されたDINOv3バックボーンの上に軽量な検出モデル(100Mパラメータ)を構築することで、COCOおよびCOCO-Oデータセットで最先端の性能を達成しています [220, 219, Table 10]。これは、より多くの訓練可能なパラメータを持つ既存のモデルをも上回る結果です。
-
セマンティックセグメンテーション:
- 凍結されたDINOv3モデルの上にデコーダーを訓練することで、ADE20kデータセットでONE-PEACEと同等の63.0 mIoUを達成し、SOTAに達しています [224, Table 11]。
-
物体検知:
-
地理空間・リモートセンシングデータ:
- DINOv3の学習レシピは汎用的であり、衛星画像のような異なるドメインにも効果的に適用可能です。
- DINOv3衛星モデルは、樹高推定タスクのSatLidar1M val、SatLidar1M test、Open-Canopyで新しいSOTAを確立しています [239, Table 17]。
- 凍結されたDINOv3衛星モデルとウェブモデルは、Earth observationタスクにおける15の分類、セグメンテーション、水平物体検知タスクのうち12タスクで新しいSOTAを達成しています [240, 242, 243, Table 18, Table 19]。これには、RGB入力と凍結バックボーンのみを使用しているにもかかわらず、マルチバンドやファインチューニングされたモデル(Prithvi-v2やDOFAなど)を凌駕する性能が含まれます。
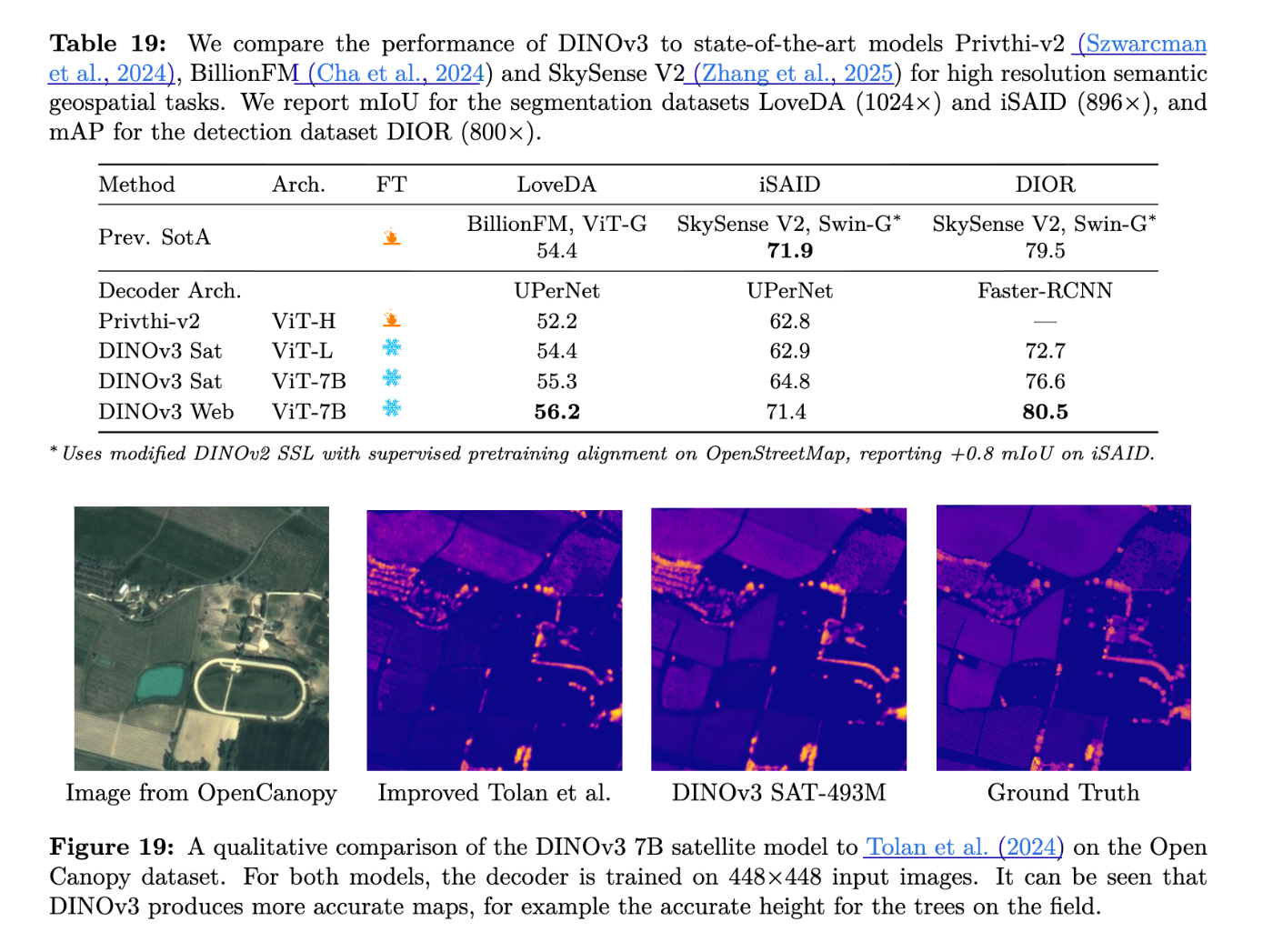
DINOv3 より
iBOTの効果
iBOTは、マスク画像モデリング(MIM)とオンライントークナイザーによる自己蒸留を用いた自己教師あり学習フレームワークであり、その特徴表現の優れた性能により、多くのダウンストリームタスクでSOTAを達成しています。
-
ImageNet分類:
- ImageNet-1Kで82.3%の線形プローブ精度と87.8%のファインチューニング精度を達成し、以前の最高結果を上回っています。ViT-L/16とImageNet-22Kの事前学習データを使用した場合、線形プローブ精度は82.3%に達し、以前のSOTAであるEsViTの81.3%を上回っています。
- k-NN評価でも、ViT-S/16で74.5%、ViT-B/16で76.1%、ViT-L/16で78.0%とSOTA性能を達成しています。
-
密なダウンストリームタスク:物体検知、インスタンスセグメンテーション、セマンティックセグメンテーションといったタスクで「主導的な結果」を達成しています。
- COCOの物体検知とインスタンスセグメンテーション:ViT-B/16を用いたiBOTは、APbで51.2、APmで44.2を達成し、以前の最高結果を大幅に上回っています [50, Table 6]。
- ADE20Kのセマンティックセグメンテーション:UPerNetを使用した場合、ViT-B/16を用いたiBOTは、以前の最高手法であるDINOを3.2 mIoU上回る性能を発揮しています [51, Table 6]。
- 教師なし学習:iBOTはNMIで32.8%を達成し、以前のSOTAを1.8%上回っています [49, Table 5]。
- ロバスト性:MIMによって学習されたパーツレベルのセマンティックパターンにより、iBOTは一般的な画像欠如に対する強力なロバスト性を示しています [35, 38, 55, Table 8]。
Grounding DINOにおけるSOTAの達成
Grounding DINOは、TransformerベースのDINO検出モデルと言語による事前学習を組み合わせることで、任意のオブジェクトをテキスト入力(カテゴリ名や参照表現)で検出できるモデルです。Kaggle などのコンペでも使用されたりしていますよね。
-
オープンセット物体検知:
- COCOゼロショット検出ベンチマークで52.5 APを達成し、新記録を樹立しています [88, 92, 102, Table 2]。
- ODinWゼロショットベンチマークでも、平均26.1 APで新記録を樹立しています [88, 92, 105, Table 4]。
- Grounding DINOは、GLIPやDINOを含むこれまでの全てのモデルをCOCOのゼロショット転送設定で上回っています [101, Table 2]。
-
参照物体検知(Referring Object Detection, REC):
- RefCOCO/+/gベンチマークにおいて、GLIPを上回る性能を示しています [108, 110, Table 5]。RECデータを学習に組み込みファインチューニングを行うことで、SOTAの性能を達成しています(例:RefCOCO valで90.56) [110, Table 5]。
-
ODinWベンチマーク(Few-ShotおよびFull-Shot):
- ODinWのfew-shotおよびfull-shot設定において、Grounding DINO TはDINOを上回る性能を示し、Swin-Tバックボーンで学習したGrounding DINOが、full-shot設定でSwin-LバックボーンのDINOを上回る結果を達成しています [107, Table 4]。
技術手法

DINOv3 より
DINOv3 での技術的な改善については以下の4つかな?と思ってます。Githubも実装もざっくりとは確認しましたが動作させて詳しくシェイプや数値変化までは追えていないです。
- Gramアンカリング (Gram Anchoring)
- マルチスチューデント蒸留 (Multi-Student Distillation)
- 高解像度適応(High-Resolution)
- テキストアライメント(Text Alignment)
では、順番に見ていきましょう。
Gramアンカリング (Gram Anchoring)
Gramアンカリング(Gram Anchoring) の導入は、DINOv3のような自己教師あり学習(SSL)基盤モデルが生成する高解像度高密度特徴量の品質と安定性を維持・向上させるための重要な手法です。これは、特に大規模モデルを長期間訓練する際に発生する、密な特徴マップの劣化という既知の未解決問題に対処するために導入されました。

DINOv3 より
戦略と目的
Gramアンカリングは、DINOv3が多用途画像基盤モデルとして、物体検知、セマンティックセグメンテーション、深度推定などのピクセルレベルの予測タスクにおいて優れた性能を発揮するためです。
その主な目的は以下の通りです。
- 密な特徴量マップの劣化の緩和:長時間の訓練スケジュール中に、高レベルのセマンティック理解を目的としたグローバルな目的と、ピクセルレベルの予測に必要な密な特徴の品質を維持する目的が衝突し、密な特徴表現が崩壊するという問題が発生します。Gramアンカリングは、この崩壊を効果的に緩和します。
- パッチレベルの一貫性の向上:特徴量自体に直接的な制約を課すのではなく、画像内のパッチ間の全てのペアワイズ内積(コサイン類似度)を計算した「Gram行列」に対して制約を課すことで、パッチレベルの特徴量の表現の一貫性をもたらしています。

DINOv3 Figure6 崩壊画像の例
メカニズム
Gramアンカリングは、以下の要素で構成されます。
フロベニウスノルムの定義は次の通りです:
- Gram行列の利用:この戦略は、画像内の各パッチから抽出された特徴量のペアワイズな内積の行列であるGram行列を操作します。これにより、個々の特徴ベクトルではなく、特徴間の類似性構造に注目します。
- Gram教師モデルの導入:学生モデルのGram行列を、Gram教師と呼ばれる以前のモデル(教師ネットワークの初期のイテレーション)のGram行列に近づけることを目的とします。Gram教師は、優れた密な特徴特性を示す訓練の初期段階のモデルから選択されます。
-
損失関数の定義:Gramアンカリングの損失関数
LGramは、学生モデルのL2正規化された局所特徴行列(XS)から計算されたGram行列と、Gram教師モデルのL2正規化された局所特徴行列(XG)から計算されたGram行列の間のフロベニウスノルムの二乗として定義されます。 -
適用と更新:
- この損失は、効率のためにグローバルクロップに対してのみ計算されます。DINOv3の訓練では、「画像ごとに2つのグローバルクロップ(256x256ピクセル)」 と「8つのローカルクロップ(112x112ピクセル)」が学生モデルによって見られるようにマルチクロップ戦略がとられています。
- 訓練の初期段階から適用することも可能ですが、DINOv3では通常、100万イテレーション後に開始されます。後半に崩壊するからですね。
- Gram教師は、主となるEMA(指数移動平均)教師と同一になるように、1万イテレーションごとに更新されます。
- 高解像度特徴の活用:Gram教師のために、通常解像度の2倍の解像度で画像をモデルに入力し、得られた特徴マップを目的のサイズにダウンスケールするというアプローチが採用されます。このダウンスケールされた高解像度特徴を使用することで、より滑らかで一貫性のあるパッチレベル表現が得られ、Gramアンカリングを通じて学生モデルにこの改善された一貫性を蒸留できてます。

導入後のロス関数は以下のようになります。
Github での Gram Loss の実装はここですね。
さらに、マルチクロップ戦略とグラムを合わせた設定は以下の部分です。
導入での影響
Gramアンカリングの導入は、DINOv3の訓練と性能に顕著な影響を与えています。
- 密な特徴マップの品質向上:長時間の訓練でも密な特徴マップがクリーンな状態を保ち、DINOv2よりも大幅に優れた密な特徴マップになってます。
- iBOT損失の加速的減少:Gram目的を適用すると、iBOT損失がより速く減少することが観察されます。これは、安定したGram教師によって導入される安定性がiBOTの目的にも良い影響を与えることを示唆しています。
- 密なタスク性能の向上:Gramアンカリングを組み込むことで、訓練の最初の1万イテレーションでADE20kのような密なタスクで顕著な改善が見られます。特に高解像度Gramアンカリングを適用することで、ADE20kでさらにmIoUの精度の追加効果が得られてます。
- 高解像度要素:DINOv3の訓練レシピにおける高解像度適応フェーズ(訓練終盤で画像解像度を一時的に高める戦略)においても、Gramアンカリングは必要な要素です。これがなければ、密な予測タスクにおけるモデルの性能が著しく低下することが判明しています。Gramアンカリングは、高解像度入力の複雑さに対処する際に、空間的な位置全体で一貫した堅牢な特徴相関を維持するようモデルを促します。
- RoPE(Rotary Positional Embeddings)との組み合わせ:DINOv3モデルはRoPEを採用しているため、追加の適応を必要とせずに様々な解像度の画像をシームレスに処理できます。これにより、Gramアンカリングにおいて高解像度入力からの特徴を利用する柔軟性が高まります。
このように、Gramアンカリングは、DINOv3が大規模なデータとモデルを用いて多様なビジョンタスクにおいて、特に密な予測を必要とするタスクで最先端の性能を達成するための基盤となる技術的貢献の一つとなっています。これは、画像内のグローバルな理解と局所的な詳細認識の両方を高いレベルで両立させるための鍵となっています。ロスの割合調整とかの嫌な課題も残ってそうです。
マルチスチューデント蒸留 (Multi-Student Distillation)
-
DINOv3ファミリーと蒸留:
知識蒸留または、蒸留(Knowledge Distillation, Distillation) とは性能を落とさずにモデル小型化・軽量化する技術です。DINOv3プロジェクト全体において、「蒸留」は重要な手法として位置づけられているみたいです。DINOv3は、70億パラメータという非常に大規模なモデルとして訓練されました。このような巨大なモデルは実行に多大なリソースを必要とするため、その知識をより小さなモデルへと圧縮するために蒸留が適用されます。その結果として、「DINOv3ファミリー」と呼ばれる、Vision Transformer (ViT) Small、Base、LargeやConvNeXtベースのアーキテクチャを含む複数のモデルバリアントが提供されています。
この蒸留プロセスにより、効率的で広く採用されているViT-Lモデルは、元の70億パラメータの教師モデルに近い性能を様々なタスクで達成することができます。 -
マルチスチューデントによるコスト改善
背景的には大規模教師モデル(Teacher)は推論コストが非常に高いため、従来の「教師1対学生1」の蒸留では効率が悪いです。これを解決するために、**複数の学生モデルを同時に学習させる「マルチ・スチューデント蒸留」**の仕組みが設計されています。
従来での方法(1教師1学生)では、GPUごとに教師推論(コスト:B/N × CT)と学生訓練(B/N × CS)を行います。提案法(マルチスチューデント蒸留) では、以下のような処理を順番にしているようです。
- 複数の学生をそれぞれGPUグループに割り当てる。
- 教師推論は全GPUで一度だけ実施(コスト固定:B/NT × CT per GPU)。
- 推論結果を all-gather通信(NCCL collective) で全学生に共有。
- 各学生は自分の担当GPU群で訓練を実施(コスト:B/NSi × CSi)。
利点としては、以下があります。NCCLの同期やらパラレルの実装面は大変そうですがね。。。
- 学生を追加しても、教師推論の総コストは増えない(固定)。新しい学生を加えても、増える計算はその学生自身の訓練分だけ。
- GPU数を学生ごとに調整し、イテレーション時間を揃えることで高速化。これにより、一度の蒸留プロセスで複数の学生モデルを効率的に得られる。
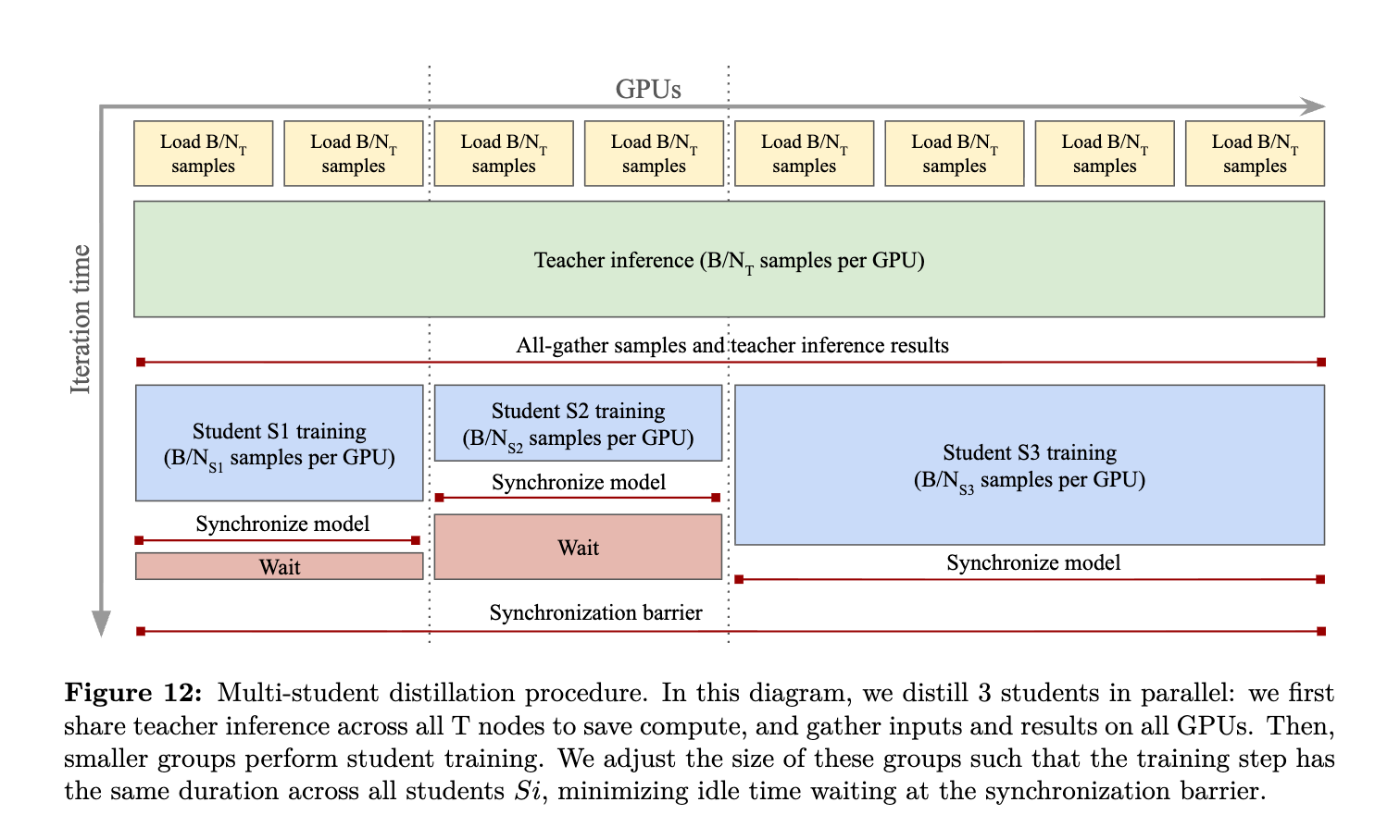
DINOv3 より -
用語と実装
「マルチスチューデント蒸留」という用語自体は、GitHubリポジトリのDINOv3のREADMEに「Multi-distillation」というセクションとして登場し、その下には--multi-distillationというコマンドライン引数を含む訓練スクリプトのテスト設定が示されています。
高解像度適応(High-Resolution)
DINOv3のような自己教師あり学習(SSL)基盤モデルが、特にピクセルレベルの予測を必要とするタスクにおいて、高品質で詳細な特徴量を安定して生成し、その性能を最大限に引き出すための重要な戦略です。これは、モデルの「柔軟性」を高めるための「ポストホック(事後)戦略」の一つとして位置づけられています。ポストホックって言葉も聞きなれないですが、基盤モデルは学習自体では新規性は無くなってきていて、学習したモデルってそれってどれくらい凄いの?どれくらい意味があるの?って問われているのが現在だと思っています。そこの価値を付与できた背景や説明の為にポストホックの戦略が述べられている気がします。ほんとは結構泥臭くやっていたんじゃないかと。
DINOv3 より
高解像度適応は、主に以下の目的のために導入されています。
- 密な予測タスクにおける性能向上:セマンティックセグメンテーションや物体検知などのピクセルレベルの下流タスクでは、入力画像の解像度が低いと小さなオブジェクトが認識できなくなるという問題があります。高解像度適応は、この問題を緩和し、モデルがより詳細な情報に基づいて予測を行えるようにします。
- 多様な解像度での安定した特徴生成:事前学習の終盤に高解像度での訓練を短期間行うことで、モデルは訓練中に見なかったより高い解像度の画像入力に対しても、安定した高品質な密な特徴マップをネイティブに提供できるようになります。DINOv3は4096×4096のような非常に高い解像度でも高品質な特徴マップが得られることが示されています。
- モデルの汎用性向上:様々な解像度で機能する能力は、DINOv3が「多用途ビジョン基盤モデル」として、多様なアプリケーションや展開するシナリオに対応するためです。

これらの結果の先として、衛星画像ドメインが現れた気がしています。
実現と関連技術
DINOv3における高解像度適応は、他の先進的な学習戦略と組み合わされて実現されています。
-
「ポストホック」戦略としての位置づけ:
DINOv3の訓練パイプラインでは、Gramアンカリングなどの主要な学習フェーズの後に、モデルの柔軟性をさらに高めるための最終段階として高解像度適応が適用されます。これは、訓練の最終段階で画像の解像度を一時的に高めて訓練することです。 -
具体的な訓練設定:
- 一般的な設定として、事前学習の終わりに画像の解像度を518×518ピクセルに増加させることが言及されています。
- DINOv3の衛星モデルの訓練では、初期の事前学習(100kイテレーション)とGramアンカリング(10kイテレーション)の後、8kステップで512ピクセル解像度での高解像度ファインチューニングが実施されます。
- GitHubのコードには、
dinov3_vit7b16_high_res_adapt.yamlという高解像度適応のための設定ファイルが存在します。
-
効率と計算コストの考慮:
高解像度での訓練は、時間とメモリを多く消費するため、短期間の訓練フェーズに限定されます。これにより、大規模なモデルでも現実的な時間でメリットを享受できます。 -
RoPE(Rotary Positional Embeddings)との相乗効果:
RoPE (Rotary Positional Embeddings) により、モデルは追加の適応を必要とせずに様々な解像度の画像をシームレスに処理する能力を持つことが関係あるように示されていますね。 -
Gramアンカリングとの連携:
高解像度適応のフェーズは、Gramアンカリング戦略と密接に関連しています。Gramアンカリングは、長時間の訓練中に発生する密な特徴マップの劣化を効果的に緩和し、高解像度入力の複雑さに対応する際に、空間的な位置全体で一貫した堅牢な特徴相関を維持するようモデルを促します。Gramアンカリングがないと、高解像度適応における密な予測タスクの性能が著しく低下することが示唆されています。また、高解像度Gramアンカリングは、ADE20kのようなタスクでさらに性能を向上させることが示されています。 -
他の基盤モデルとの類似性:
高解像度適応の考え方は、UniViT (Likhomanenko et al., 2021) や FlexiViT (Beyer et al., 2023) など、他のビジョンモデルでも同様の短期間の高解像度訓練ステップが採用されています。
DINOv3 より
テキストアライメント(Text Alignment)
さらにポストホック戦略として「テキストアライメント(Text Alignment)」もあります。
「テキストアライメント(Text Alignment)」とは、DINOv3のようなビジョン基盤モデルが生成する視覚的特徴量(画像の特徴)を、テキスト(自然言語)の意味空間に合わせるための戦略を指しているそうです。
目的としては、テキストアライメントの主な目的は、DINOv3モデルから得られる画像の特徴量(特にクラス(CLS)トークンや出力パッチ)と、テキストエンコーダによって生成されるテキストの特徴量を同じセマンティック空間にアライメントすることです。これにより、視覚情報と言語情報を相互に理解し、関連付けることが可能になります。
方法としては、アライメントはテキストエンコーダを訓練し、DINOv3の視覚的特徴量とテキストとの間で整合性を持たせることで実現されます。ソースでは、dino.txtというレシピ(手法)に従ってテキストエンコーダが訓練されると明記されています。
テキストアライメントが示す能力
テキストアライメントが成功すると、DINOv3は以下のようなファインチューニングなしで優れた性能を持つ多様なビジョンタスクに対応できるようになります。
-
ゼロショット分類(Zero-shot Classification):
- 事前学習時に特定のクラスのラベルを明示的に与えられなかった場合でも、テキスト記述に基づいて画像を分類する能力を指します。
- DINOv3は、ImageNet-1k、ImageNet-Adversarial、ImageNet-Rendition、ObjectNetといった標準的なベンチマークでCLIPプロトコルを用いたゼロショット分類精度が評価されています。
-
画像-テキスト検索(Image-text Retrieval):
- 画像クエリに基づいて関連するテキストを検索したり(Image-to-Text, I→T)、テキストクエリに基づいて関連する画像を検索したり(Text-to-Image, T→I)する能力です。
- COCO2017データセットでRecall@1という指標を用いて評価されています。
-
オープンボキャブラリーセグメンテーション(Open-vocabulary Segmentation):
- 事前に定義されていない任意のテキスト記述(例:「犬」や「建物」だけでなく、「赤い車輪の自転車」といった詳細な表現)に基づいて、画像内のオブジェクトをセグメンテーション(領域分割)する能力です。
- このパッチレベルのアライメントの品質は、ADE20kやCityscapesといった一般的なベンチマークでmIoU(mean Intersection over Union)という指標を用いて評価されています。
訓練データに関する注意点
DINOv3のテキストアライメントモデルの訓練には、論文で言及されているようにプライベートなデータセットが使用されました。しかし、公開目的でCocoCaptionsデータセットを使用する例の設定ファイル(dinov3/eval/text/configs/dinov3_vitl_text.yaml)が提供されています。これは、研究や今後の発展のために用意されているためでしょうかね。企業あるあるですが、出せない会社制約と公開したいメンバーの折衷案かな
最適化戦略
最適化戦略について注目して読むと面白かったです。主にDINOv3や関連する自己教師あり学習(SSL)基盤モデルが、高品質で汎用性の高い視覚的特徴量を効率的かつ安定して学習し、様々なダウンストリームタスクで優れた性能を達成するための一連の手法とアプローチが記載されていました。キャリブレーション的な感じですね。
キャリブレーション事項
DINOv3プロジェクトでは、以下の主要な最適化戦略が採用されています。
-
訓練の効率化と安定化技術:
- FlashAttention: メモリ使用量と速度を改善するために、DINOv2で導入されたカスタムバージョンのFlashAttention。
- ViTアーキテクチャの調整: 計算効率を最大化するために、ViT-gアーキテクチャの埋め込み次元やヘッドの数が調整されています。
- Sinkhorn-Knopp正規化: DINOv2の訓練では、DINOおよびiBOTの教師側ソフトマックス・センタリングステップに導入され、バッチ正規化を改善しています。
- ヘッド重みの分離/共有: DINOv3ではDINOとiBOTのヘッド重みを分離することで大規模学習での逆効果を防ぎ、iBOTでは[CLS]トークンとパッチトークンの投影ヘッドを共有することで画像中の解釈を促進しています。
- ソフトラベルの使用: iBOTでは、離散的なIDではなく、softmax後の連続的なトークン分布(ソフトラベル)を教師信号として使用することが、性能向上に重要であることが示されています。
- CenteringとSharpening: DINOとiBOTの両方で、教師ネットワークの出力分布を安定させるために、CenteringとSharpeningが適用されます。
- 予測比率: iBOTのマスク画像モデリングにおいて、マスクするパッチの予測比率を調整し、分散を加えることで性能が向上します。
-
データとモデルのスケーリング:
- 大規模データセットのキュレーション: DINOv3は、階層型k-meansクラスタリングと検索ベースのキュレーションを組み合わせたLVD-1689Mのような大規模で多様なデータセットで訓練されます。これにより、モデルが幅広い視覚的概念を学習し、汎化能力を高めます。
- モデルサイズの拡大: DINOモデルを70億パラメータ規模にまで拡大することで、顕著な性能向上が達成されたようです。なんでここまでデカくしたか、限界かはちょっとわからず
DINOv3 より
性能と評価について
DINOv3は、自己教師あり学習(SSL)で画像だけでなく地理空間データやテキストとの連携においてもその有効性が評価されています。性能については SOTA の部分で数値として分かりますが、定性的な評価や測定方法も記載されていました。

評価プロトコルと測定方法
DINOv3の性能は、主に固定されたモデルの特徴量に基づき、様々な評価データセットを用いて測定しています。
-
線形プローブ(Linear Probing): 凍結されたDINOv3のバックボーンから抽出された特徴量の上に、線形分類モデルを訓練して性能を評価します。画像分類(ImageNet-1kとそのOODバリアント)、セマンティックセグメンテーション、深度推定などで用いられます。

DINOv3 より - k-NN分類(k-Nearest Neighbor Classification): ImageNet-1kなどのデータセットで、特徴量の品質を評価するために、凍結された表現に対してk-NN分類モデルを使用してます。
- 非パラメトリックアプローチ: 特徴量間の直接的な類似性に基づいてタスクを実行する評価です。3D対応推定、教師なしオブジェクト発見、動画セグメンテーション追跡などに適用されます。
- アテンティブプローブ(Attentive Probing): 動画分類のような複雑なタスクで、DINOv3のパッチ特徴量の上に浅いTransformerベースの分類モデルを訓練して評価します。
-
ダウンストリームデコーダーとの組み合わせ: 物体検知(Plain-DETR)、セマンティックセグメンテーション(Mask2Former)、深度推定(Depth Anything v2)、3D理解(VGGT)などのタスクでは、DINOv3のバックボーンを凍結したまま、その上に特化した軽量なデコーダーを訓練して、より複雑なシステムとしての性能が評価されてます。
DINOv3 より - 定性的可視化: PCA(主成分分析)を用いた特徴マップの可視化により、DINOv3の生成する密な特徴量が、他のモデルと比較してよりシャープでノイズが少なく、意味的に一貫していることが示されています。

DINOv3 より
評価が示唆すること
これらの評価結果は、DINOv3が、単に高性能なモデルであるだけでなく、自己教師あり学習の進化を通じて、極めて汎用性が高く、ロバストで、実用的なビジョン基盤モデルとして使えることを強く主張していますね。教師あり学習にだいぶ近い精度を叩き出していて、生半可な機械学習モデルやデータセットを用意するだけの企業だともう勝てなくなってきています。AIエンジニアもモデルを作成できる人間ではなく、モデルを操作できるだけの仕事になる可能性も大いにありです。言語領域はそんな感じにもうなちゃってますからね。
関連論文
ついでに調べたというか言葉が分からず、調べざるを得なかった単語や関連論文などです。
DINOv3は、単一のモデルで多様なタスクやドメインに汎用的に対応する「多用途ビジョン基盤モデル」を確立することを目指しており、その開発プロセスにおいて、広範な関連研究が考慮されています。
DINOv3の基盤論文
- DINO (Caron et al., 2021): DINOv3の名称の由来であり、自己蒸留(self-distillation)を用いた視覚Transformerの自己教師あり学習における先駆的な研究です。DINOは、グローバルビューに焦点を当て、画像レベルの目的関数を通じて、オブジェクトのセマンティックなセグメンテーション情報を含む特徴量を学習する能力を証明。
- iBOT (Zhou et al., 2021): DINOv3の訓練レシピに統合されている Masked Image Modeling (MIM) の代表的なモデルです。iBOTは、マスクされたパッチトークンを用いたパッチレベルの目的関数に焦点を当て、高レベルの視覚的セマンティクスを学習し、画像内の内部構造をモデル化する上で優位性を持つことを証明。
- DINOv2 (Oquab et al., 2024): DINOv3の直接の前身であり、大規模なキュレーションデータと改善された訓練レシピにより、SSLモデルの性能を弱教師あり学習(WSL)モデルのレベルにまで引き上げました。DINOv3は、DINOv2の成功の上に築かれ、Gramアンカリングなどの新技術でDINOv2の課題(密な特徴マップの劣化など)を克服しています。
自己教師あり学習 (SSL) 弱教師あり学習 (WSL)
DINOv3は、その性能を評価する際に、様々なSSLおよびWSLモデルと直接比較されていました。
- SSLモデル: MoCov3, SwAV, BYOL, EsViT, MAE (Masked Autoencoders), Web-DINO (DINOの大規模スケーリング版), Franca, V-JEPA 2 (動画理解に特化したSSLモデル)。
- WSLモデル: CLIP (Radford et al., 2021), SigLIP 2 (Tschannen et al., 2025), PEcore (Perception Encoder Core) (Bolya et al., 2025), AM-RADIOv2.5 (Heinrich et al., 2025), PEspatial (SAM 2から蒸留されたモデル), EVA-CLIP (Sun et al., 2024)。
- 集約型(Agglomerative)モデル: SAM (Segment Anything Model) (Kirillov et al., 2023)。
着想を得た研究
- マスク画像モデリング (MIM): 自然言語処理(NLP)におけるマスク言語モデリング(MLM)の成功に触発され、Vision Transformer (ViT) のためのMIMの可能性を探求した研究です。iBOTはこの概念を具体化し、DINOv3にその要素が取り入れられています。
- 自己蒸留: DINOで提案された自己蒸留の概念は、DINOv3でも学生ネットワークと教師ネットワークのパラダイムとして引き続き活用されています。
- 高解像度特徴マップの生成: Fu et al. (2024) などの研究がViTから高解像度特徴マップを生成する手法を探求しているのに対し、DINOv3はこれらのモデルと比較して、ネイティブに高品質な密な特徴マップを安定して提供できることを強調しています。
- RoPE (Rotary Positional Embeddings): DINOv3は、RoPEをカスタムバリアント(axial RoPE、RoPE-box jittering)で採用しており、Heo et al. (2024) などの位置埋め込みに関する研究と関連しています。
特定のタスクにおける関連研究
DINOv3は、特定のコンピュータービジョンシステムに組み込まれることで、それらのタスクのSOTAを向上させています。
- 物体検知: Plain-DETR (Lin et al., 2023b), DETR (Carion et al., 2020), Faster R-CNN (Ren et al., 2017), DINO (Zhang et al., 2022), DyHead (Dai et al., 2021)。
- セマンティックセグメンテーション: ViT-Adapter (Chen et al., 2022), Mask2Former (Cheng et al., 2022), UPerNet (Xiao et al., 2018), ADE20k (Zhou et al., 2017)。
- 深度推定: DPT (Dense Prediction Transformer) (Ranftl et al., 2021), Depth Anything V2 (DAv2) (Yang et al., 2024b), MiDaS (Ranftl et al., 2020), LeReS (Yin et al., 2021), Omnidata (Eftekhar et al., 2021), Marigold (Ke et al., 2025)。
- 3D処理: Visual Geometry Grounded Transformer (VGGT) (Wang et al., 2025), Probe3D (Banani et al., 2024)。
- 動画タスク: V-JEPA 2 (Assran et al., 2025), Jabri et al. (2020) の非パラメトリック手法。
-
テキストアライメント:
dino.txt(Jose et al., 2025) と呼ばれる手法。これはDINOv2 Meets Textとも呼ばれ、CLIP (Radford et al., 2021) のプロトコルに沿ったゼロショット分類や、オープンボキャブラリーセグメンテーションに利用されます。Grounding DINOも、DINOに言語による事前学習を組み合わせたオープンセット物体検知モデルであり、GLIP (Li et al., 2021) やOV-DETR (Zareian et al., 2021) などの関連研究を比較対象としています。 - 地理空間データ: Tolan et al. (2024), Prithvi-v2 (Szwarcman et al., 2024), DOFA (Xiong et al., 2024), BillionFM (Cha et al., 2024), SkySense V2 (Zhang et al., 2025)。MAXAR のデータが使用されていたのが気になるなるなる!
スケーリングとデータキュレーション
- 大規模言語モデル (LLMs): DINOv3は、LLMがモデル容量をスケーリングすることで、優れた「emergent properties」を発揮した成功から着想を得てるみたいです。
- 自動データキュレーション: Vo et al. (2024) の研究成果を活用し、訓練データセットをキュレーションしています。
- データセット: ImageNet-1k, ImageNet-22k, LVD-1689M, Objects365, COCO-Stuff, Hypersim, SatLidar, Open-Canopy, SAT-493M, DIOR, LoveDA。
倫理面
ちょっと読んでいて皮肉で面白かったことなので記載しますね。
環境への影響(カーボンフットプリント)です。大規模なAIモデルの訓練には、多大なエネルギー消費とそれに伴う温室効果ガス排出が伴います。DINOv3モデル(ViT-7B)の訓練にかかる潜在的な炭素排出量について具体的に言及されており、1回の完全な事前学習に47 MWhの電力が必要であり、これは平均的な電気自動車で240,000 km走行するのに必要なエネルギーにほぼ相当し、18トン CO2(炭素排出量) に相当すると報告されています。これは、AI研究開発における持続可能性という重要な倫理的課題を浮き彫りにしています。
脆弱性としては、ディープラーニングモデル、特にGrounding DINOのようなモデルは、敵対的攻撃(adversarial attacks)に対する脆弱性を抱えています。悪用の可能性としては、モデルが持つ**オープンセット物体検出能力が「違法な目的で悪用される可能性」**があるというリスクが指摘されています。これは、強力な汎用AI技術が、意図しない方法で使用されることへの懸念を示しています。まぁ、科学はどれも使い方次第ですから
実装
実装に関しては、以下の Github で DINOv3 ラインセンス(Metaの特別なやつっぽい)で公開されています。
環境構築
環境構築に関しては、以下の2点が条件になっているみたいです。今後に拡張されるかもしれませんが
- Torch Version
2.7以上 - Linux OS
アナコンダ系のPythonライブラリマネージャーであれば、環境定義ファイル conda.yamlできると思いますが、公式では minimamba を使用することが推奨されています。mamba の小型の Python パッケージマネージャーらしい。
以下を見ると、Python Version 3.11 で pip で torch や torchvision, torchmetrics を入れている、、、
事前学習モデル
事前学習済みのモデルをかなり提供されています。
公式の README.md の転記にはなります。
直接取得
直接モデルを取得する場合はリンクから取得してみてください。
モデル ViT Webデータセット (LVD-1689M):
| Model | Parameters | PretrainingDataset | Download |
|---|---|---|---|
| ViT-S/16 distilled | 21M | LVD-1689M | link |
| ViT-S+/16 distilled | 29M | LVD-1689M | link |
| ViT-B/16 distilled | 86M | LVD-1689M | link |
| ViT-L/16 distilled | 300M | LVD-1689M | link |
| ViT-H+/16 distilled | 840M | LVD-1689M | link |
| ViT-7B/16 | 6,716M | LVD-1689M | link |
モデル ConvNeXt Webデータセッ(LVD-1689M):
| Model | Parameters | PretrainingDataset | Download |
|---|---|---|---|
| ConvNeXt Tiny | 29M | LVD-1689M | link |
| ConvNeXt Small | 50M | LVD-1689M | link |
| ConvNeXt Base | 89M | LVD-1689M | link |
| ConvNeXt Large | 198M | LVD-1689M | link |
モデル ViT 衛星画像 (SAT-493M):
| Model | Parameters | PretrainingDataset | Download |
|---|---|---|---|
| ViT-L/16 distilled | 300M | SAT-493M | link |
| ViT-7B/16 | 6,716M | SAT-493M | link |
PyTorch Hub から取得
最近は便利になったもので Python コード上で torch.hub.load() でモデルリンクからも取得が可能です。
import torch
REPO_DIR = <PATH/TO/A/LOCAL/DIRECTORY/WHERE/THE/DINOV3/REPO/WAS/CLONED>
# DINOv3 ViT models pretrained on web images
dinov3_vits16 = torch.hub.load(REPO_DIR, 'dinov3_vits16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vits16plus = torch.hub.load(REPO_DIR, 'dinov3_vits16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitb16 = torch.hub.load(REPO_DIR, 'dinov3_vitb16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vith16plus = torch.hub.load(REPO_DIR, 'dinov3_vith16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
# DINOv3 ConvNeXt models pretrained on web images
dinov3_convnext_tiny = torch.hub.load(REPO_DIR, 'dinov3_convnext_tiny', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_small = torch.hub.load(REPO_DIR, 'dinov3_convnext_small', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_base = torch.hub.load(REPO_DIR, 'dinov3_convnext_base', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_large = torch.hub.load(REPO_DIR, 'dinov3_convnext_large', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
# DINOv3 ViT models pretrained on satellite imagery
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
以下のファイルで公開モデルをリンクさせているようです。
Hugging Face Transformers からの取得
Hugging Face Hub の DINOv3 コレクションというのが用意されていて、そこからダウンロードも可能です。
from transformers import pipeline
from transformers.image_utils import load_image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = load_image(url)
feature_extractor = pipeline(
model="facebook/dinov3-convnext-tiny-pretrain-lvd1689m",
task="image-feature-extraction",
)
features = feature_extractor(image)
import torch
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = load_image(url)
pretrained_model_name = "facebook/dinov3-convnext-tiny-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(
pretrained_model_name,
device_map="auto",
)
inputs = processor(images=image, return_tensors="pt").to(model.device)
with torch.inference_mode():
outputs = model(**inputs)
pooled_output = outputs.pooler_output
print("Pooled output shape:", pooled_output.shape)
pretrained_model_name を以下から選択します
facebook/dinov3-vits16-pretrain-lvd1689mfacebook/dinov3-vits16plus-pretrain-lvd1689mfacebook/dinov3-vitb16-pretrain-lvd1689mfacebook/dinov3-vitl16-pretrain-lvd1689mfacebook/dinov3-vith16plus-pretrain-lvd1689mfacebook/dinov3-vit7b16-pretrain-lvd1689mfacebook/dinov3-convnext-base-pretrain-lvd1689mfacebook/dinov3-convnext-large-pretrain-lvd1689mfacebook/dinov3-convnext-small-pretrain-lvd1689mfacebook/dinov3-convnext-tiny-pretrain-lvd1689mfacebook/dinov3-vitl16-pretrain-sat493mfacebook/dinov3-vit7b16-pretrain-sat493m
前処理
よくあるんですが、モデルだけ公開されているが入力が8bit(0 ~ 255)なのか、0~1(float) なのかわからないことが多いんですがご丁寧に前処理についても記載されています。
Webデータセットの前処理
import torchvision
from torchvision.transforms import v2
def make_transform(resize_size: int = 224):
to_tensor = v2.ToImage()
resize = v2.Resize((resize_size, resize_size), antialias=True)
to_float = v2.ToDtype(torch.float32, scale=True)
normalize = v2.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return v2.Compose([to_tensor, resize, to_float, normalize])
衛星画像データセットの前処理
import torchvision
from torchvision.transforms import v2
def make_transform(resize_size: int = 224):
to_tensor = v2.ToImage()
resize = v2.Resize((resize_size, resize_size), antialias=True)
to_float = v2.ToDtype(torch.float32, scale=True)
normalize = v2.Normalize(
mean=(0.430, 0.411, 0.296),
std=(0.213, 0.156, 0.143),
)
return v2.Compose([to_tensor, resize, to_float, normalize])
使用例
最小動作としての例も用意されていました。それぞれの処理ごとに実装があります。
画像分類
DINOv3 の基盤モデルに分類ヘッドをつけて、イメージネット(Image Net)での学習をしたモデルの場合は以下です。
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | ImageNet | link |
PyTorch Hub でのモデル取得の実装例:
import torch
# DINOv3
dinov3_vit7b16_lc = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_lc', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
深度推定(距離推定)
DINOv3 の基盤モデルに回帰ヘッドをつけて、SYNTHMIXデータセットでの学習をしたモデルの場合は以下です。
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | SYNTHMIX | link |
depther = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_dd', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
出力までの Python 実装も用意されています。
from PIL import Image
import torch
from torchvision.transforms import v2
import matplotlib.pyplot as plt
from matplotlib import colormaps
def get_img():
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
return image
def make_transform(resize_size: int | list[int] = 768):
to_tensor = v2.ToImage()
resize = v2.Resize((resize_size, resize_size), antialias=True)
to_float = v2.ToDtype(torch.float32, scale=True)
normalize = v2.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return v2.Compose([to_tensor, resize, to_float, normalize])
depther = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_dd', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
img_size = 1024
img = get_img()
transform = make_transform(img_size)
with torch.inference_mode():
with torch.autocast('cuda', dtype=torch.bfloat16):
batch_img = transform(img)[None]
batch_img = batch_img
depths = depther(batch_img)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.axis("off")
plt.subplot(122)
plt.imshow(depths[0,0].cpu(), cmap=colormaps["Spectral"])
plt.axis("off")
物体検知
物体検知モデルについての例は以下です。物体検知と言えばの Microsoft COCO での事前学習です。
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | COCO2017 | link |
detector = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_de', source="local", weights=<DETECTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
セグメンテーション
ピクセルごとに分類ヘッドをつけて、ADE20K で事前学習をしたセグメンテーションモデルについては以下です。
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | ADE20K | link |
segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
セグメンテーションモデルでの実装例は以下です。
import sys
sys.path.append(REPO_DIR)
from PIL import Image
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from matplotlib import colormaps
from functools import partial
from dinov3.eval.segmentation.inference import make_inference
def get_img():
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
return image
def make_transform(resize_size: int | list[int] = 768):
to_tensor = v2.ToImage()
resize = v2.Resize((resize_size, resize_size), antialias=True)
to_float = v2.ToDtype(torch.float32, scale=True)
normalize = v2.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return v2.Compose([to_tensor, resize, to_float, normalize])
segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
img_size = 896
img = get_img()
transform = make_transform(img_size)
with torch.inference_mode():
with torch.autocast('cuda', dtype=torch.bfloat16):
batch_img = transform(img)[None]
pred_vit7b = segmentor(batch_img) # raw predictions
# actual segmentation map
segmentation_map_vit7b = make_inference(
batch_img,
segmentor,
inference_mode="slide",
decoder_head_type="m2f",
rescale_to=(img.size[-1], img.size[-2]),
n_output_channels=150,
crop_size=(img_size, img_size),
stride=(img_size, img_size),
output_activation=partial(torch.nn.functional.softmax, dim=1),
).argmax(dim=1, keepdim=True)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.axis("off")
plt.subplot(122)
plt.imshow(segmentation_map_vit7b[0,0].cpu(), cmap=colormaps["Spectral"])
plt.axis("off")
ゼロショットタスク
dino.txtを使用したゼロショットでの認識モデルです。
| Backbone | Download |
|---|---|
| ViT-L/16 distilled | link,vocabulary,vocabulary license |
import torch
# DINOv3
dinov3_vitl16_dinotxt_tet1280d20h24l, tokenizer = torch.hub.load(REPO_DIR, 'dinov3_vitl16_dinotxt_tet1280d20h24l', weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
ノートブックのチュートリアル
Colab でのノートブックが提供されていて、DINOv3 をいじって見たい人はこれから始めると良さそうです。
- パッチ特徴のPCA: DINOv3 のパッチ特徴量を PCA でオブジェクトに対して表示する実装(論文にある虹色の可視化)
- [Google Colab で実行]
DINOv3 Github より
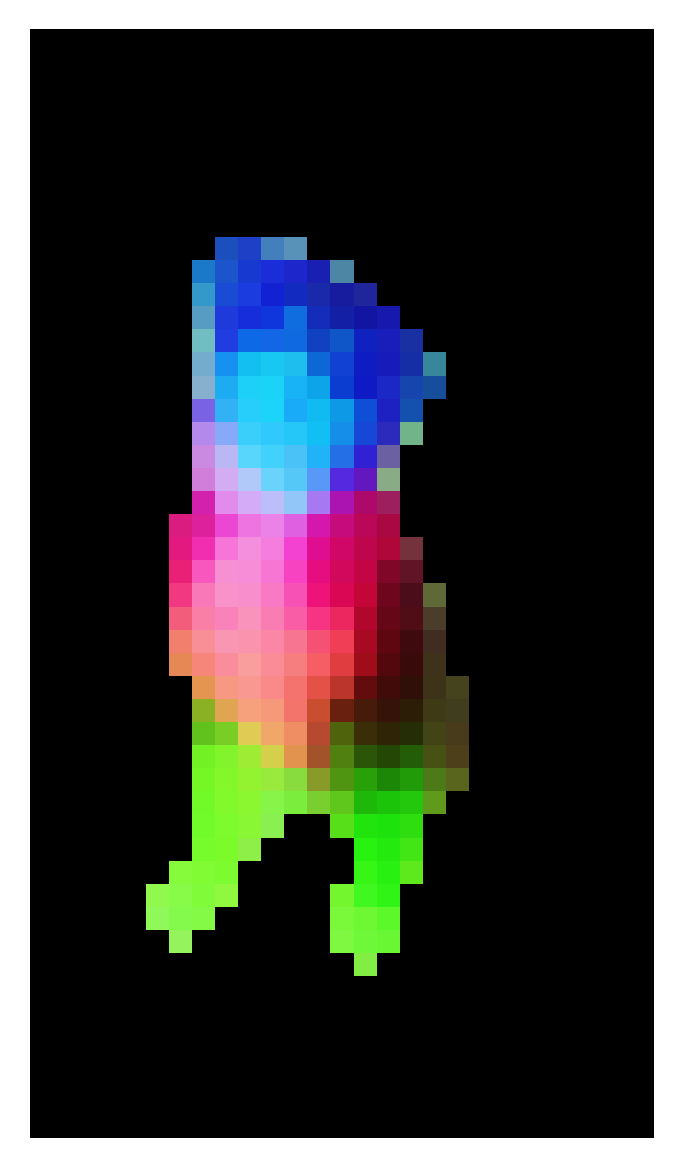
DINOv3 Github より
- セグメンテーション: DINOv3 の特徴量に基づいて線形分類のセグメンテーションモデルを学習
- [Google Colab で実行]

DINOv3 Github より
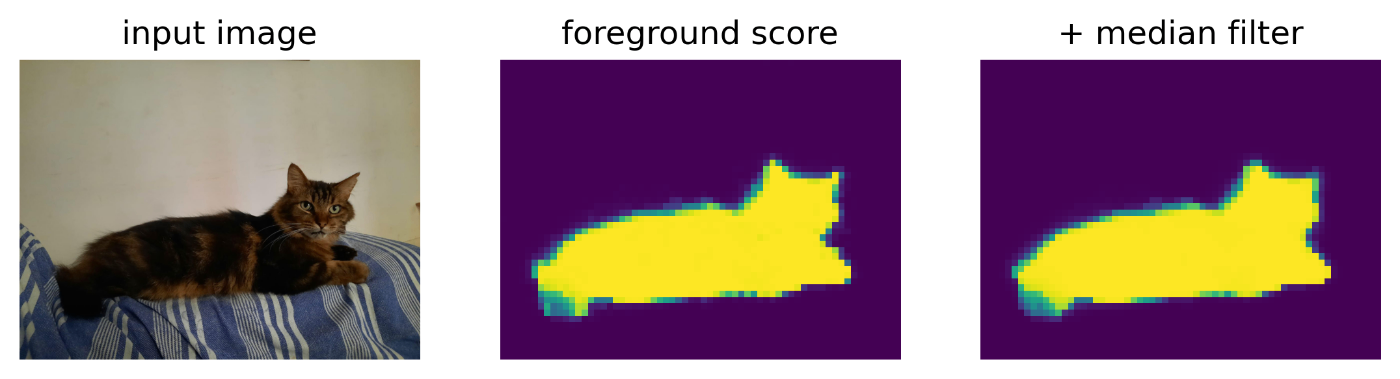
DINOv3 Github より
- 特徴量マッチング: DINOv3 の特徴に基づいて、2枚の異なる画像上のオブジェクトパッチをマッチング
- [Google Colab で実行]

DINOv3 Github より
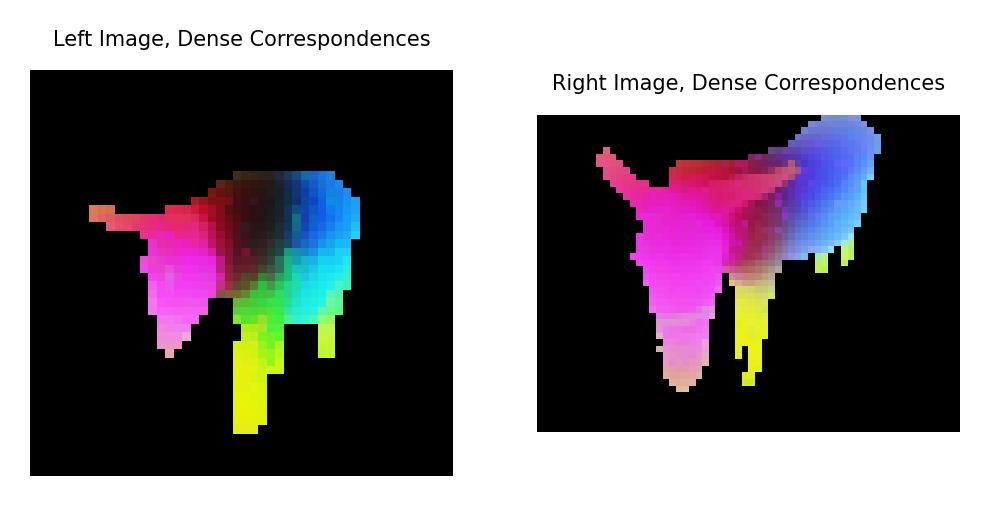
DINOv3 Github より

DINOv3 Github より
- セグメンテーショントラッキング: DINOv3 の特徴を用いた非パラメトリックな手法による動画セグメンテーショントラッキング
- [Google Colab で実行]
発展
DINOv3 の発展系?というか利用した論文やツールも続々と登場するでしょう。
過去の流れでは、DINOv2 でも医療系のデータでも効果性が証明されて利用が促進されています。
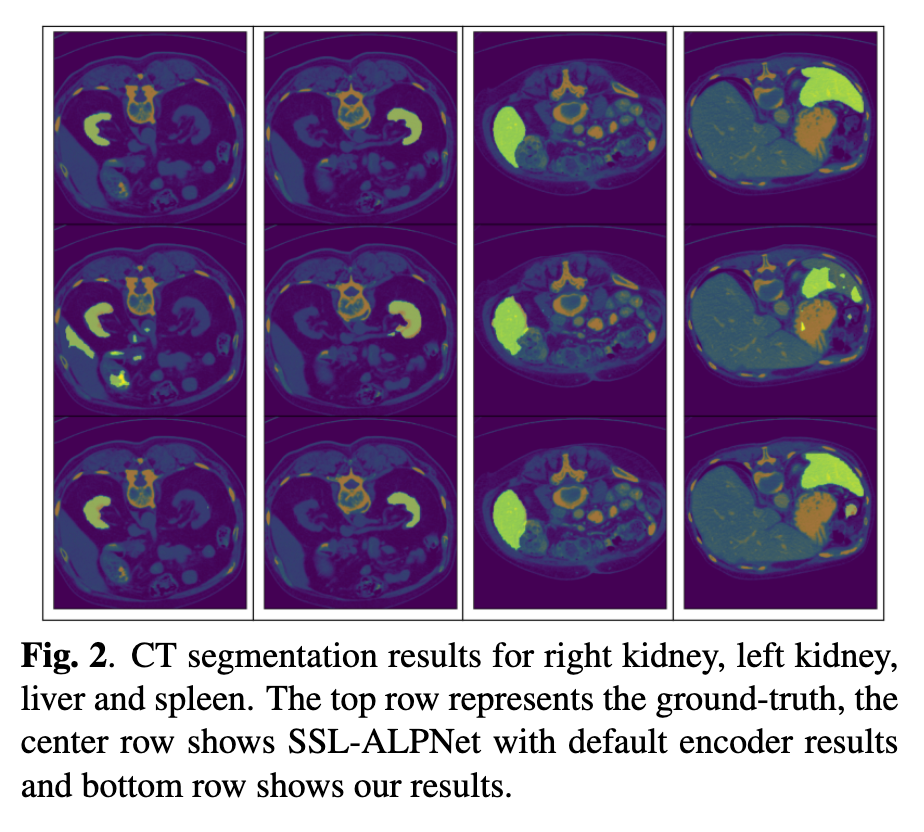
DINOv2 based Self Supervised Learning For Few Shot Medical Image Segmentation より
今回の DINOv3 で追加された衛星画像ドメインにも波及するだろうと考えています。
GeoAI のようなライブラリでは DINOv3 での分類がもう対応していたりします。
Colab Notebook ではこちらです。
GroundDINOのように関連した新しい提案も続々と登場しそうです。
業務であったり、コンペにおいても活用の幅が増えるでしょう。
開拓されるのは大変うれしいですが、積極的におっていかないといけないのはしんどくもある、、、
さいごに
ちょうど読みたかった論文だったのでしっかりとお勉強しました。
読んでみると、過去のDINOや関連する基盤モデルの一般的な手法も調べざるを得ず、大変でした。しかしながら、ざっくりと基礎から今のトレンドや最新の取り組みまで追いつけて良かったです。
もし皆さんのお勉強の足しにでもなれば幸いです。書いてみて見直すと、調べてどんどん後から追記しながら記載したので繰り返しの説明になっているところはお許しください。
反響
X で頂戴したコメントについて掲載させていただきます。ありがとうございます。
宣伝
日頃はこのようなZennの個人記事を書いています。
そして、宙畑にもよく寄稿しています。
今年はSAR衛星解析入門の書籍を出版します。
また、来年には QGISの衛星画像解析の書籍を出版いたします。
自己紹介
普段は宇宙領域でテックリードをしております。X(旧Twitter)アカウントでは、宇宙領域や機械学習などの科学やコンペなどについて発言することが多いです。
SAR解析をよくやっていますが、画像系AI、地理空間や衛星データ、点群データ、3Dデータに関心があります。勉強している人は好きなので楽しく絡んでくれると嬉しいです。
SAR解析者への道シリーズ もよろしくお願いします!

衛星データ解析として、宙畑のライターもしています。
お仕事はとても忙しいのでご相談やご提案くらいでしたら可能です。
Discussion