【QGIS実践】密度解析 QGIS のプラグイン (Density Analysis)
はじめに
2次元データによる密度解析
本記事では、地理空間における密度解析についてご紹介します。
特に QGIS のプラグインの Density Analysis を用いた実践やツールを簡単なサンプルデータで試す方法やその有用性についてまとめております。
また、専門的な具体例や、使用しない場合はどうのようなことを考慮すべきかなどを記載しています。
密度解析とは
Density Analysis の直訳は、密度解析に当たりますが、密度も分野によって色々です。さて、地理空間処理における密度解析とはなんでしょうか?
密度解析(density analysis)とは、地理空間上の各地点における「単位面積当たりの対象の集中度」を推定・可視化する手法です。点・線・面データを入力に、格子(ラスタ)上で密度を計算し、ヒートマップなどで表現します。その表現によってわかることや可視化から得られる示唆を得ることです。
具体例
じゃあ、どんなことができるでしょうか?
代表例は点密度(件/km²)や線密度(道路長/km²)、カーネル密度推定(KDE)による連続分布の推定です。検索半径(バンド幅)やセルサイズ、重み付けの設定が結果を左右し、境界効果への配慮が必要です。犯罪ホットスポット、交通量、商圏、生息域、医療アクセス評価などに活用が可能です。
密度解析のメリット
じゃあ、どういった良い事があるのでしょうか?
データ構造の重複が直感的な色や統計量の変化でわかることです。
これは可視化のみでソリューションに繋げることが可能です。
逆に、データ処理で都合のいいデータも作りやすいのです。
目的やニーズに合ったほんとーーーに効果的な可視化が求められます。
ツールの紹介
じゃあ、どんなツールを使えば密度解析が出来るの?
その回答が、QGIS プラグインのDensity Analysis になります。
事前知識
わかる人は飛ばしてください。イメージが湧くように用意してます。
以下では、統計処理でよく使う言葉を数式(必要に応じて)の順で定義します。

© kurumaru
カーネル(kernel)
要点:データ点の「近さ」に応じて重みを与える重み関数です。カーネル密度推定(KDE)やカーネル回帰で使います。図でいう、枠の処理です。
性質:非負・対称(
代表例
- ガウス:
K(u)=\frac{1}{\sqrt{2\pi}}e^{-u^2/2} - エパネチコフ:
K(u)=\tfrac{3}{4}(1-u^2)_+ (\cdot)_+ - 一様:
K(u)=\tfrac{1}{2}\mathbf{1}(|u|\le 1)
バンド幅(
(参考:KDE の数式)
1次元:
密度(density)
要点:連続確率変数の**確率密度関数(pdf)や、空間統計での点の強度(単位面積あたりの期待個数)**を指します。
確率的定義:区間
注意点
-
f(x) - ヒストグラムやKDEは密度の推定です。ビン幅やバンド幅により曲線の滑らかさ・高さが変わります。
- 空間統計では「密度=強度
\lambda(s) A \int_A \lambda(s)\,ds
ヒートマップ(heatmap)
要点:2次元格子状の値を色で表す可視化です。値の大小を色の濃淡や色相で表現します。
対象:相関行列、時系列×カテゴリの強度、2次元KDEの推定値、空間の発生密度など。
作り方の典型
- 座標平面をグリッド分割(または既存の行列データを使用)。
- 各セルに値(平均・合計・出現回数・KDE推定値など)を割り当て。
- カラーマップで色に変換して表示(カラーバーを付けて尺度を明示)。
注意点
- ビン(グリッド)サイズや補間で見え方が大きく変わります。
- 色スケール(線形・対数)とカラーマップ選択(順序尺度なら連続的、正負をまたぐなら発散型)が解釈性に重要です。
- コロプレス図はポリゴン単位の集計可視化、ヒートマップは格子(ラスタ)単位の値表示、という違いがあります。
用語まとめ
| 用語 | ひとことで | 主な出力 | 主要パラメータ | 典型用途 |
|---|---|---|---|---|
| カーネル | 近い点に大きい重みを与える重み関数 | 重み(関数値) |
バンド幅 |
KDE、カーネル回帰、スムージング |
| 密度 | 連続変数の確率密度/空間の強度 |
|
推定法(ヒストグラム・KDE)、帯域・ビン幅 | 分布把握、確率・発生強度の推定 |
| ヒートマップ | 2D格子値を色で表示 | 画像(色付き格子) | グリッド解像度、色スケール、補間 | 相関・頻度・2D密度の可視化でよく使用 |
QGIS 実践
とりあえず、やってみよう!
練習用データ
サンプルデータは以下の先日に公開した拙著の記事で生成したやまびこが発生する地点のポイントデータです。
シミュレーターによって生成する実装からデータも Github に格納してます。
その中で練習用データについてはこちらで取得することが可能です。
どんなデータかは時間ごとに 声 が進むのを叫んだ地点と跳ね返った地点の地理空間座標とその経路の位置座標や時間がセットになっているデータです。何かが起こっている頻度のデータとも考えることができます。ということは?密度解析??かなという感じです。
QGISで可視化していきましょう。

ベースマップ © 国土地理院写真
ベースマップについては、国土地理院の写真図を利用してます。QGISでの設定方法は MIERUNE さんのこちらの記事がわかりやすいですよ
QGISプラグイン
QGISのプラグインで、Density Analysis を選択してインストールしましょう。
QGIS プラグイン一覧
すると、画像の水色の枠で囲まれた何やらかっこよさそうなラスターのアイコンが追加されます。

QGIS の Density Analysis プラグイン
QGISプラグインのインストールの詳細についても MIERUNEさんが上手にまとめてくれています。
密度処理
1. Geohash density
まずは、Geohash density についてです。
ざっくりと決まったスケールの番号を選択することで密度のヒートマップを作成してくれます。
Geohash density > Styled geohash density map を使用していきます。

ベースマップ © 国土地理院写真
ここで、スケールの番号 というのが地理空間的なタイルのサイズのことです。
以下の表のように番号が振られています。細かい設定をせずにざっくり密度マップを作成するときにおすすめです。
| ハッシュ長(レベル) | おおよその格子サイズ(東西 × 南北) |
|---|---|
| 1 | ≤ 5,000 km × 5,000 km |
| 2 | ≤ 1,250 km × 625 km |
| 3 | ≤ 156 km × 156 km |
| 4 | ≤ 39.1 km × 19.5 km |
| 5 | ≤ 4.89 km × 4.89 km |
| 6 | ≤ 1.22 km × 0.61 km |
| 7 | ≤ 153 m × 153 m |
| 8 | ≤ 38.2 m × 19.1 m |
| 9 | ≤ 4.77 m × 4.77 m |
| 10 | ≤ 1.19 m × 0.596 m |
| 11 | ≤ 149 mm × 149 mm |
| 12 | ≤ 37.2 mm × 18.6 mm |
補足情報:
- 最小値:1/最大値:12/デフォルト値:6
| パラメータ | 設定値 | 説明 |
|---|---|---|
| Input point vector layer | kasagadake_echoes [EPSG:4326] |
入力する点ベクタレイヤーです。座標参照系は WGS84(EPSG:4326)です。 |
| Grid extent (defaults to layer extent) [オプション] | 137.547625725, 137.594930501, 36.302570088, 36.333663896 [EPSG:4326] |
グリッド生成範囲を示す外接矩形です(minX, maxX, minY, maxY の順)。未指定時はレイヤ全体が使われます。 |
| Grid type | Hexagon | 生成するグリッドセルの形状です。六角形を使用します。 |
| Cell width in measurement units | 0.050000 | セルの横幅です。下記の単位で解釈されます(0.05 km)。 |
| Cell height in measurement units | 0.100000 | セルの縦幅です(0.1 km)。 |
| Measurement unit | Kilometers | セル寸法の単位です。キロメートルを使用します。 |
| Select color ramp | Reds | 出力ヒートマップのカラースキームです。赤系のグラデーションを使用します。 |
| Invert color ramp | オフ(未チェック) | カラースケールを反転するオプションです。今回は反転しません。 |
| 詳細パラメータ | -(未指定) | 追加の詳細設定です。今回は既定値のままです。 |
| Output density heatmap | 一時レイヤを作成 | 出力先です。QGIS の一時レイヤとして作成します。 |
| アルゴリズムの終了後、出力ファイルを開く | 有効(チェックあり) | 実行後に結果レイヤーを自動で開きます。 |
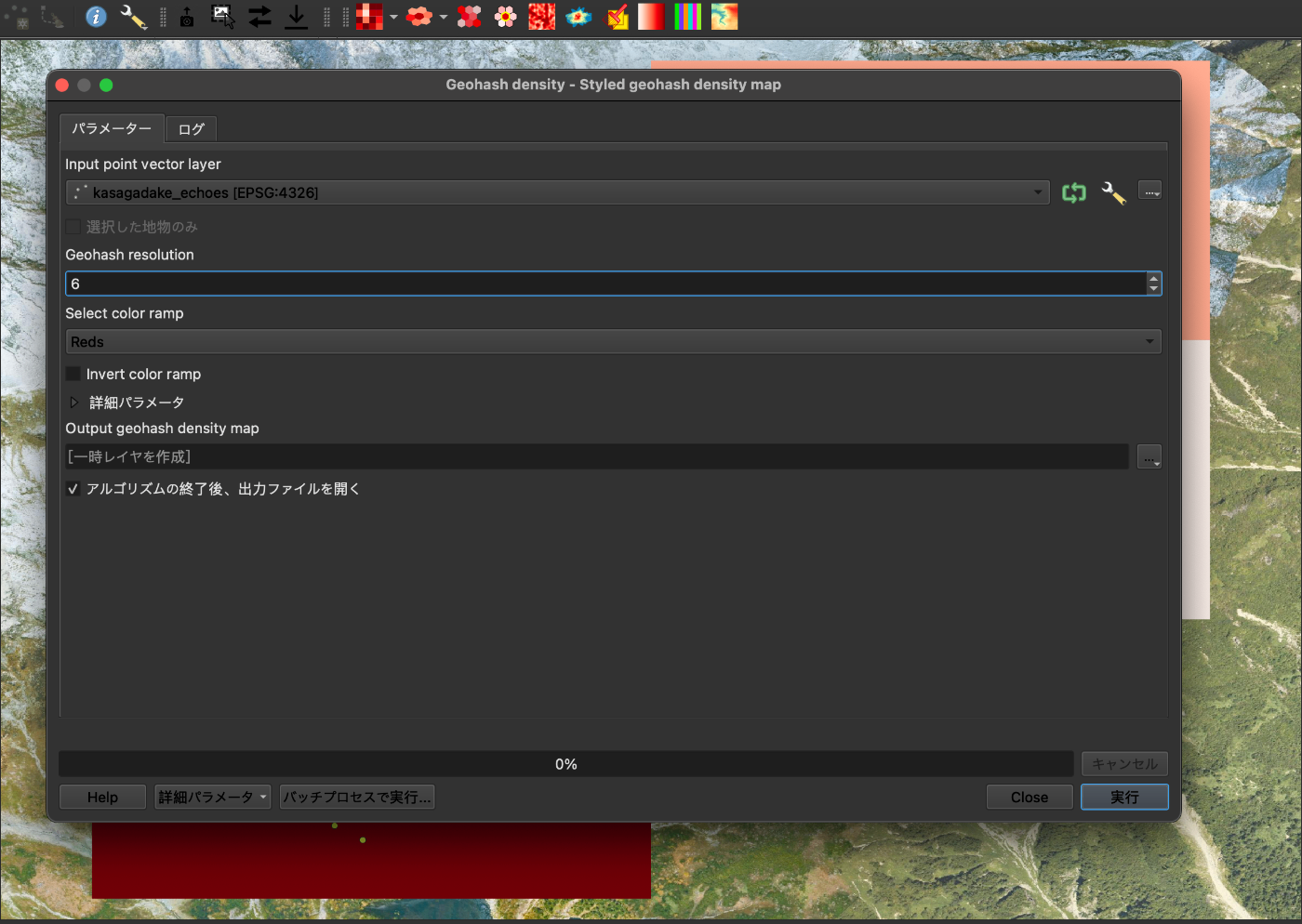
Styled geohash density map 設定画面
上記のような設定で、処理するファイルの指定と スケールの番号をデフォルトの 6 を使用してみます。

Styled geohash density map の処理結果 ベースマップ © 国土地理院写真
2. H3 density
H3 density > Styled H3 density map を使用していきます。
Styled H3 density map の選択 ベースマップ © 国土地理院写真
H3 はヘキサタイルを良しなにやってくれる言葉だと思ってもらえたらと思います。かっこいい6角形のタイルを生成してくれます。
H3 についても スケールの番号が以下の表のように番号が振られています。
| 解像度レベル | 平均六角形の辺長 |
|---|---|
| 0 | 1107.71 km |
| 1 | 418.68 km |
| 2 | 158.24 km |
| 3 | 59.81 km |
| 4 | 22.61 km |
| 5 | 8.54 km |
| 6 | 3.23 km |
| 7 | 1.22 km |
| 8 | 461.35 m |
| 9 | 174.38 m |
| 10 | 65.91 m |
| 11 | 24.91 m |
| 12 | 9.42 m |
| 13 | 3.56 m |
| 14 | 1.35 m |
| 15 | 0.51 m |
補足情報:
- 最小値:0/最大値:15/デフォルト値:9

Styled H3 density map の設定 ベースマップ © 国土地理院写真
上記のような設定で、処理するファイルの指定とスケールの番号をデフォルトの 9 を使用してみます。
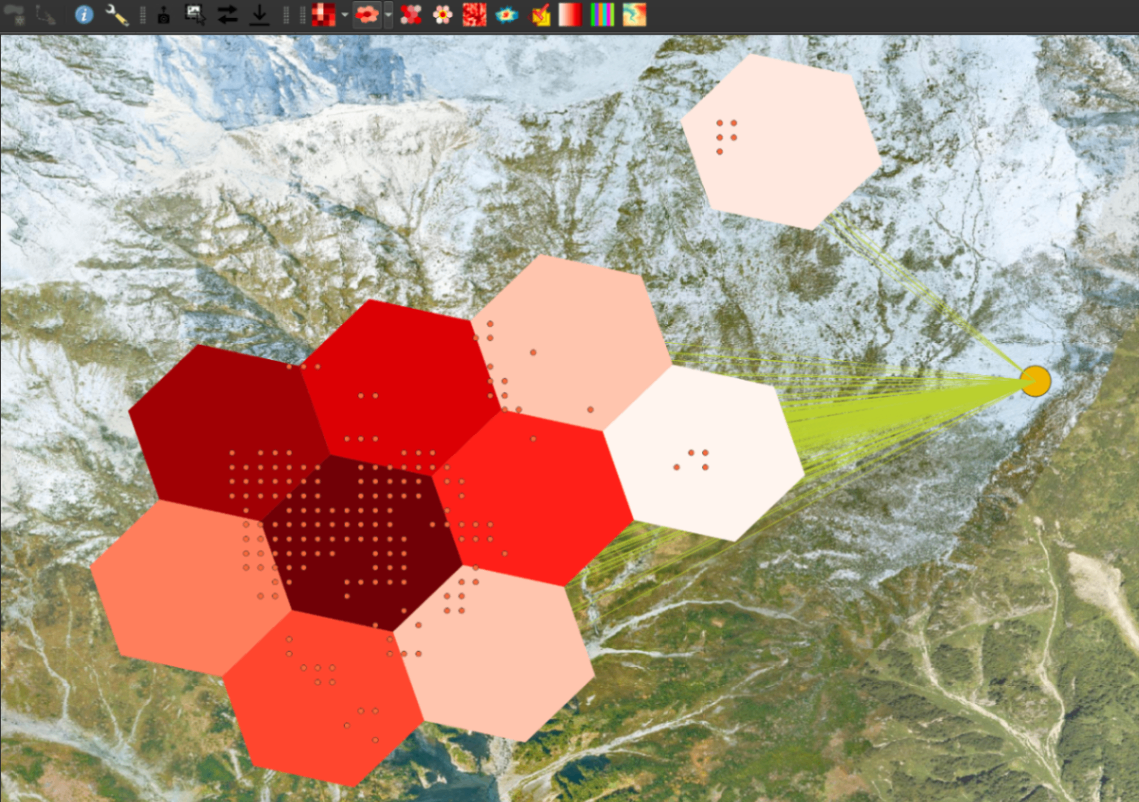
Styled H3 density map の処理結果 ベースマップ © 国土地理院写真
かっこいい6角形タイルの密度マップが作成できましたね!
使用時にエラーが出る方は、以下を試すといいかもしれません。
H3 のインストール
原因は、h3 ライブラリが QGIS の Python にインストールされていないからです。
著者が Mac なので Mac でのアプリケーションにからのパスになっています。適宜修正してください。
# 1) QGIS の Python 実行ファイルを変数に(通常版)
QGIS_PY="/Applications/QGIS.app/Contents/MacOS/bin/python3"
# もし LTR 版なら:
# QGIS_PY="/Applications/QGIS-LTR.app/Contents/MacOS/bin/python3"
# 2) ユーザープロファイルの Python パスを作成
USER_QGIS_PY="$HOME/Library/Application Support/QGIS/QGIS3/profiles/default/python"
mkdir -p "$USER_QGIS_PY"
# 3) pip を用意・更新
"$QGIS_PY" -m ensurepip --upgrade
"$QGIS_PY" -m pip install --upgrade pip
# 4) H3 v4 系をインストール(--target でユーザー側に配置)
"$QGIS_PY" -m pip install "h3>=4,<5" --upgrade --target "$USER_QGIS_PY"
H3 density > H3 density grid を使用して格子状のタイルも生成できます。

H3 density grid の選択 ベースマップ © 国土地理院写真
同じくスケールの番号をデフォルトの 9 で生成してみます。

H3 density grid の設定 ベースマップ © 国土地理院写真
かっこいいヘキサタイルのグリッドが完成です。
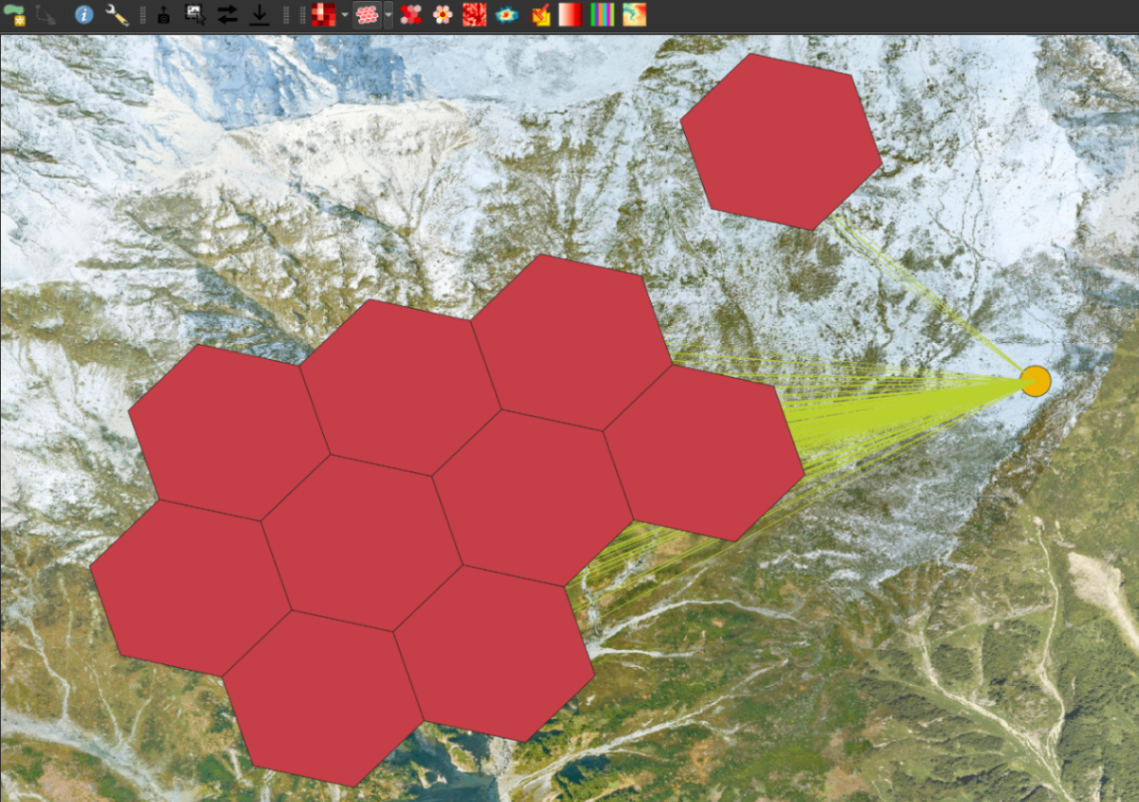
H3 density grid の処理結果 ベースマップ © 国土地理院写真
3. Styled density map
ここまでは、スケールの番号でいい感じにやってくれました。
しかし、いい感じにならなかったり、出力要件にスケールを細かく指定しないといけなかったりする場合は Styled density map を使用して細かく指定できます。

Styled density map の選択 ベースマップ © 国土地理院写真
設定するパラメータは上記のようになっています。
| パラメータ | 設定値 | 簡単な説明 |
|---|---|---|
| Input point vector layer | kasagadake_echoes [EPSG:4326] | ヒートマップの元となる点データのレイヤーを指定します。 |
| Grid extent (defaults to layer extent) [オプション] | 137.547625725, 137.594930501, 36.302570088, 36.333663896 [EPSG:4326] | グリッドを作成する範囲(西端, 東端, 南端, 北端)。未指定ならレイヤー範囲になります。 |
| Grid type | Hexagon | グリッドセルの形状です。六角形で集計します。 |
| Cell width in measurement units | 0.050000 | セルの横幅(選択した単位でのサイズ)です。 |
| Cell height in measurement units | 0.100000 | セルの高さ(選択した単位でのサイズ)です。 |
| Measurement unit | Kilometers | セル幅・高さの単位を指定します。 |
| Select color ramp | Reds | 出力の色階調(カラーマップ)を選びます。 |
| Invert color ramp | オフ | 色の低高(低値/高値)の対応を反転するかどうかです。 |
| Output density heatmap | 一時レイヤを作成(Temporary layer) | 出力先の指定です。プロジェクト内の一時レイヤとして作成します。 |
| アルゴリズムの終了後、出力ファイルを開く | オン | 処理完了後に結果を自動表示します。 |
Select color で様々な色で可視化することができます。 Grid type で四角形や六角形を選択できます。
特に出力する地理空間スケールを調整するパラメータ Cell width in measurement units と Cell height in measurement units は意識しましょう。

Styled density map の設定 ベースマップ © 国土地理院写真
ちょっと小さいヘキサタイルで可視化することができました。
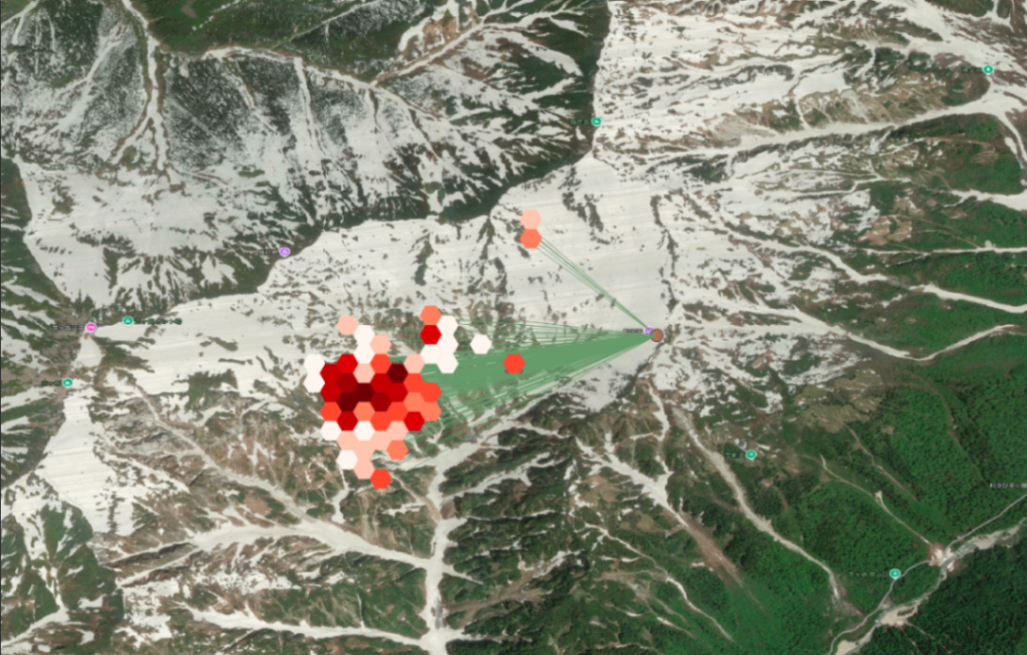
Styled density map の処理結果 ベースマップ © 国土地理院写真
4. Raster density
次に、密度解析のラスターデータを生成する Raster density です。ちょっと似ているようですが、ラスターデータのピクセルごとに完全に制御して指定したい時はこちらです。
Raster density > Stlyed heatmap (Kernel density estimation) を選択すると使用できます。

Stlyed heatmap (Kernel density estimation) の選択 ベースマップ © 国土地理院写真
このような条件で指定していきます。
| パラメータ | 設定値 | 説明 |
|---|---|---|
| Input point layer | kasagadake_echoes [EPSG:4326] |
カーネル密度推定(KDE)の入力となるポイントレイヤーです。座標参照系は EPSG:4326 です。 |
| Cell/pixel dimension in measurement units | 0.050000 |
出力ラスタのピクセルサイズです。下の「Measurement unit」の単位で解釈されます(ここでは km 単位)。 |
| Kernel radius in measurement units | 0.050000 |
KDE のカーネル半径(スムージング半径)です。「Measurement unit」の単位で指定します。 |
| Measurement unit | Kilometers |
上記のピクセルサイズとカーネル半径に用いる計測単位です。 |
| Select color ramp | Rocket |
出力ヒートマップに適用するカラースキームです。 |
| Invert color ramp | チェックなし | カラースキームの明暗を反転するオプションです(未選択のため既定の向きで表示します)。 |
| Output kernel density heatmap | 一時ファイルに保存 | 出力の保存先です。QGIS の一時レイヤーとして作成します。 |
| アルゴリズムの終了後、出力ファイルを開く | チェックあり | 実行完了後に自動で結果レイヤーを開きます。 |
Cell/pixel dimension in measurement units がラスターデータの解像度の設定になります。
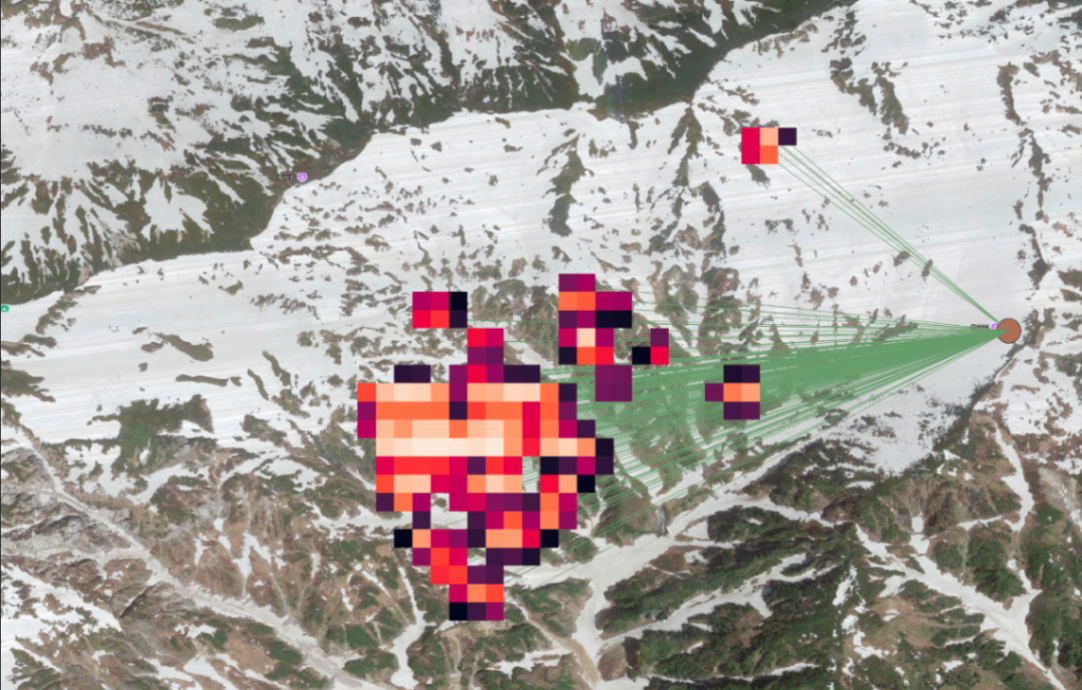
Stlyed heatmap (Kernel density estimation) の処理結果 ベースマップ © 国土地理院写真
このようなラスターデータが得られました。
さらに、点からの推定ではなくポリゴンの領域から密度出力をする場合は Raster density > Stlyed heatmap (Raster) を選択します。
Stlyed heatmap (Raster) の選択 ベースマップ © 国土地理院写真
また、同じ設定でいきます。

Stlyed heatmap (Raster) の設定 ベースマップ © 国土地理院写真
すると、声の LineString の領域についても密度ラスターが生成できました。
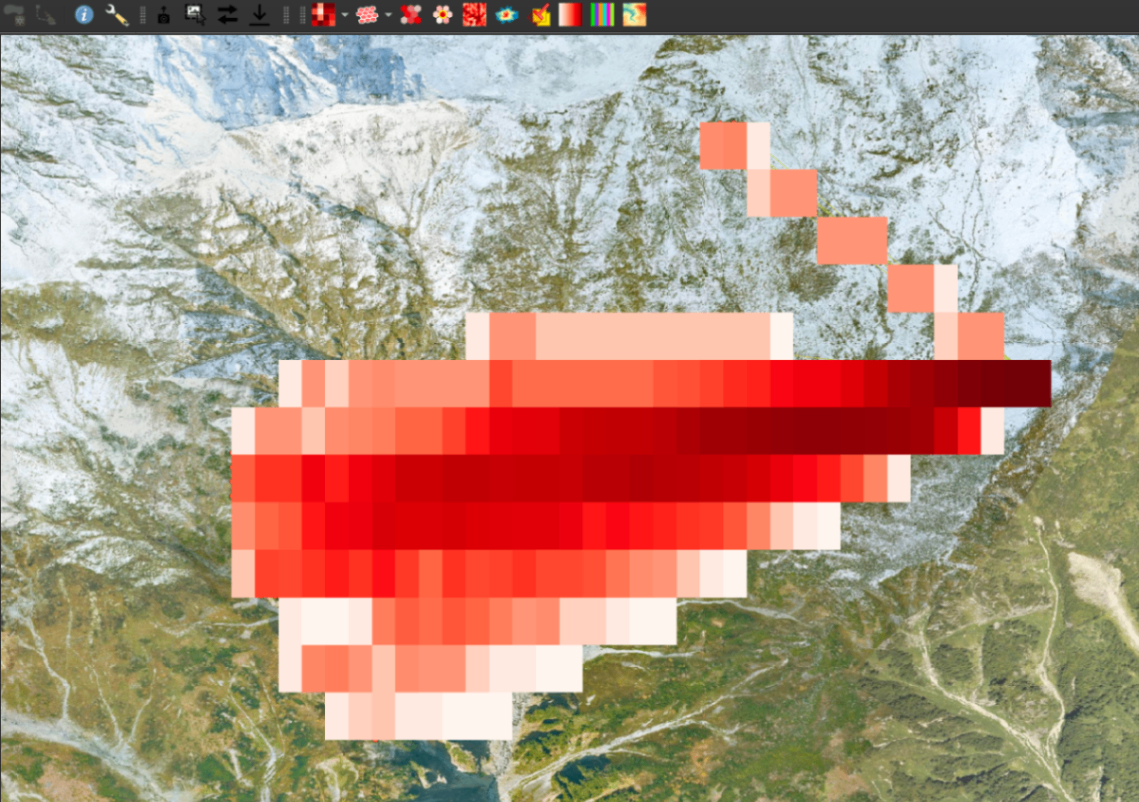
Stlyed heatmap (Raster) の処理結果 ベースマップ © 国土地理院写真
5. Style Change
残りはまとめる形にはなりますが、可視化する色や色の変化するスケーリングを調整することができます。

Style Change の選択 ベースマップ © 国土地理院写真
あれ?上記で気を付けて生成すればいいのでは?と思うかもしれませんが、途中で変えたくなるのです。
というか 可視化次第で新しい示唆を得られることが強み になります。データサイエンス全般で有効なデータを引き出す実力みたいなものですね。
必要に応じて QGIS のレイヤーで重ねたりすることで色を変えるとわかりやすい条件が見えてきたりします。
距離で色付けすると、

距離による色付け結果 ベースマップ © 国土地理院写真
クラスターで色付けすると、

クラスターによる色付け結果 ベースマップ © 国土地理院写真
声の経路の密度で可視化したりすると、

声の経路による色付け結果 ベースマップ © 国土地理院写真
このように対話的にカスタムできることが強みですね。
毎回、1から作成し直すと大変なんですわ〜
必要性
やまびこシリーズ続編の記事では、経路の全ての点でシミュレーションをしています。
すると、 GeoJSON では結構な量のデータになってしまい、QGIS画面操作ではとてもラグが生じてしまいます。
ここでたくさんのことに気がつきかされましたね。
- 必要な分だけ可視化しないといけないこと
- 必要なこと以外は主張のノイズ
- データ形式には向き不向きがある
今まではPCのパワームーブで解決してましたが、知識や技術があると結構簡単に解決できますね。
密度解析することで必要最低限のラスターデータ作成しておくことも大切だなと思いました。
さらに、ラスター化によって得られる有用性については以降でまとめてますのでそちらを確認頂ければ幸いです。
必要なところに必要な技術ですね〜
専門性が欲しい方へ
こんな基礎的な処理はつまらない方には、実際に使用しているユースケースや説明がある文献をまとめていますので次のステップのご参考になさってください。
Density Analysisプラグインが真価を発揮するシーン
一言で言うと (ユースケース) ですね。
頻度を扱うものが基本にはなります。以下のものは文献として見つかったのでこのような利用方法があるようです。
| 分野 | 典型シナリオ | 主なメリット | 参考事例 |
|---|---|---|---|
| 交通・道路安全 | 交通事故発生地点(ポイント)からジオハッシュ/H3メッシュ別の事故密度マップを作成し、危険区間を可視化 | メッシュごとの件数集計+自動スタイリング により、行政向け資料を迅速に作成 | カールトン大学によるOttawa市交通事故解析チュートリアル (Dges) |
| 犯罪ホットスポット解析 | 犯罪発生データを500 mグリッドで加重集計し、重点パトロール区域を抽出 | 加重フィールド対応 なので凶悪度・損害額などを考慮した犯罪密度を即時算出 | Chicago市犯罪データ例(LinkedIn) (LinkedIn) |
| 水害・環境ハザード | 洪水被害地点をラスタ化し、上流域の「潜在的洪水ホットスポット」を検出 | 多層ポイント対応 で年別・原因別のマップを一括生成でき、H3で高速 | シンガポール‐フラッシュフラッド予測論文 (CAADRIA 2024) |
| 生態・外来種モニタリング | 外来魚類の観測点をポリゴン密度マップに変換し、侵入経路を推定 | ポリゴン密度アルゴリズム により分布域境界をそのまま可視化 | ルーマニア内淡水域の外来魚研究 (Neobiota) |
| 公衆衛生・疫学 | COVID-19患者の所在地を時系列で密度モデリングし、変動を解析 | ヒートマップエクスプローラ が時間フィルタと相性◎ | Wastewater Surveillance報告書内の利用例 (SSRN) |
| 小売・都市計画 | 来店データや人口統計をH3セルで集計し、候補立地のポテンシャルを定量化 | セルサイズを単位系で直接指定 → km²/人など指標の統一が容易 | 「25 Best QGIS Plugins」ブログで紹介 (GIS Journal) |
Density Analysisを紹介している主な記事・チュートリアル
調べて分かったんですが、論文とかジャーナルにまで記載されてて結構びっくりしてます。
シンプルに身につけられるだけで武器ですね。
| # | タイトル | 媒体 | 公開年 | 概要 |
|---|---|---|---|---|
| 1 | Density Analysis — QGIS Python Plugins Repository | QGIS公式プラグインサイト | 2025 | 機能一覧・変更履歴・ダウンロード (QGISプラグイン) |
| 2 | QGIS Density Analysis Plugin (README) | GitHub(hamiltoncj) | 2025 | アルゴリズム詳細・H3導入方法 (GitHub) |
| 3 | Density Analysis – QGIS Plugins for Everyday | GISPlugins.com | 2022 | 主要機能と信頼性バッジの解説 (gisplugins.com) |
| 4 | Analysing Traffic Accidents Using QGIS – Heatmaps, Hotspot Analysis… | Carleton U. OSG Wiki | 2022 | Geohash & H3密度マップの手順 (Dges) |
| 5 | New Density Analysis Plugin released… | Reddit /r/gis | 2023 | リリース告知とユーザーレビュー (Reddit) |
| 6 | Crime Rate Distribution Map in Chicago (LinkedIn投稿) | 2024 | 500 m格子での犯罪密度可視化 (LinkedIn) | |
| 7 | CNN-based Flash Flood Hotspots in Singapore | CAADRIA 2024論文 | 2024 | Styled Heatmap手法による洪水リスク推定 (CAADRIA 2024) |
| 8 | Invasive Fish Species in Romanian Freshwater | NeoBiota誌 | 2024 | Styled Heatmapで外来魚ホットスポット解析 (Neobiota) |
| 9 | 25 Best QGIS Plugins Every User Must Know | The GIS Journal | 2025 | おすすめプラグイン中でKDE機能を高評価 (GIS Journal) |
| 10 | Spatial Density Analysis in QGIS (YouTube) | YouTube | 2023 | H3/Geohashアルゴリズムの実演 (YouTube) |
Density Analysisプラグインの概要と解説
概要
QGISの「Density Analysis」プラグインは、カーネル密度推定(KDE)を中心に、複数の空間インデックス手法を用いた密度ヒートマップを“ワンクリック”で生成できる拡張機能です。公式プラグインレポジトリでは2025年4月版が最新安定版として公開されており、従来のRasterヒートマップ生成に比べて (1) ジオハッシュ / H3セル / 任意ポリゴン の3系統に対応、(2) セルサイズをメートル・キロメートル・度など任意単位で指定、(3) 生成直後に自動でラスタ/ベクタのシンボルスタイルを適用 という操作効率の高さが特徴です。(QGISプラグイン)
著者の公式 Github は以下です。

https://github.com/hamiltoncj/qgis-densityanalysis-plugin/#readme より
アルゴリズム構成
- Heatmap (Kernel Density Estimation) 拡張版 – QGIS標準KDEをラップし、ピクセルサイズや検索半径をセル単位で一括変更しつつ、処理後に適切なカラーランプ(線形・対数・自然階級など)を自動設定します。
- Geohash Density Map – 任意精度のGeohashセルを生成し、各セル内ポイント数を集計。大陸規模データでも分解能を段階的に調整できるため、広域×粗格子 → 詳細×細格子 のマルチスケール分析が容易です。
- H3 Density Map – Uber社がOSS公開した Hexagonal Hierarchical Geospatial Index (H3) を用いた六角形メッシュ集計。Pythonライブラリ h3 を事前導入すると、数百万点規模でも秒オーダーで集計が完了します。表面積がセルごとに均等であるため、極域を含む全球解析でも歪みが生じにくい利点があります。
- Polygon Density Map – ポリゴンレイヤ(例:行政区画)に含まれるポイントをそのまま合算し、値を属性列へ書き込み。重ね合わせ解析と組み合わせることで、人口統計×犯罪発生率 のような複合指標マップを瞬時に生成できます。
- スタイル関連ユーティリティ – QMLファイルやコピー済みスタイルを選択レイヤに一括ペーストする機能、ランダムスタイル・グラデーション生成など、視覚化作業をテンプレート化。(GitHub)
有効な効果
公式やWeb記事から有効なシーンだなと思ったところをいくつか記載してます。
- 時間短縮 – 従来の「Heatmap (KDE) → ラスタ保存 → 手動でシンボロジ設定」の3手順が1クリックに集約。バッチ処理やモデルビルダーでも呼び出せるため、日次・週次レポート作成が自動化できます。
- 高解像かつ歪みの少ないメッシュ – H3採用により高緯度域でもセル面積が安定し、北欧~極域の事故密度、南極観測基地の気象異常点 など球面座標系での比較が精度向上。
- ユビキタスな単位系指定 – CRSに依存せず “300 m” “0.5°” “10 km” など分析目的に合わせてセルを定義できるため、都市計画=m単位、全球気候=度単位 のハイブリッド解析が容易。
- 加重フィールド対応 – 指数化されたリスクスコアや売上高などを重みとして利用できるため、単純件数ではなく重要度に応じた密度 を可視化できます。
- ポリゴン集計の一体化 – ラスタ出力だけでなくベクタポリゴン密度を直接生成でき、行政区別のホットスポットランキング をそのままテーブル化できる点が報告書向けに有用。
- スタイル一括コピー – 色覚バリアフリー配色や社内ブランドカラーをQML登録し、使い回す運用が定着。視認性の向上と制作コストの削減を同時に実現します。
まとめ
Density Analysisプラグインは、従来のQGIS標準KDE機能を「誰でも・高速に・美しく」使えるよう進化させたツールです。Geohash・H3メッシュの採用により広域データでも計算負荷を抑えつつ均質なセル統計を実現できます。
「解析→スタイル→共有」という一連の作業を劇的に短縮し、意思決定サイクルを加速する点が最大の効果と言えるでしょう。
ラスター化するメリット
密度解析をすることでタイルのラスターデータを自然と制作することになります。さて、このラスタライズの恩恵についても理解しておくと、理論的な部分だけではない実務的なアイデアも得られることがあります。(著者の私は恥ずかしながら、処理した後のデータを確認して初めて気がつきました、、、、、)
ベクターデータ(点・線・ポリゴン)をラスターデータ(グリッド化されたピクセル情報)に変換するメリットは、単なる形式変換ではなく処理速度、データ互換性、解析手法の選択肢を大きく広げることにあります。
以下では、それぞれの数値例や利用シーンとともに整理します。
1. 大規模解析時の処理速度向上
| 項目 | ベクター | ラスター化後 | 効果 |
|---|---|---|---|
| 処理単位 | 不規則なジオメトリを逐次判定 | 等間隔のピクセルに対する行列演算 | 演算が一括ベクトル化可能 |
| 例 | 100万件のポリゴンを重ね合わせて領域判定 | 1m解像度の1000×1000ピクセルの2D配列を NumPy演算 | 数十倍の高速化(NumPy, GPU可) |
| 利用シーン | 土地利用分類、ハザードマップとの重ね合わせ、視域解析 | 都市全域の一括バッファ処理やマスク処理 |
COG (Cloud Optimaized GeoTIFF) のようにピラミッドデータを活用できるのも処理速度向上に繋がります。
2. データ量の最適化・軽量化
-
ベクター:座標列や属性を持つため、高精度形状の保持にはデータ量が増大(例:河川のポリラインが数十万頂点)
-
ラスター:解像度を落とすことでファイルサイズをコントロール可能
- 例)10GBの詳細ポリゴン → 1m解像度ラスタ:数百MBに縮小可能
- GeoTIFF + 圧縮(LZW, DEFLATE)でさらに削減・画像圧縮の知見が使える
-
利用シーン:Web配信(XYZタイル化)やモバイルGIS表示で軽量化が必要なとき
3. 空間解析アルゴリズムとの親和性
-
多くの**地形解析・空間統計手法(Slope, NDVI, Kernel Density, Cost Distance, Viewshed)**はラスターベース
-
ベクター形式では直接適用できない処理でも、ラスタ化すれば可能
-
例:
- 樹木分布ポリゴン → ラスタ化 → 樹冠率ヒートマップ
- インフラ位置(点) → ラスタ化 → 距離減衰モデル
4. 並列処理・GPU処理の容易さ
-
ラスターは単なる配列として扱えるため、NumPy, CuPy, PyTorchなどの並列・GPU処理が直接可能
-
例:
- 1000枚のタイルに対するNDVI計算をCUDAで高速化
- Pythonで
numpy.where(mask, a, b)のように数百万画素を一括処理
これ結構見落としがちなんですが、PCにはグラフィック処理用のプロセッサーがついてることが多く、単純に画面に表示されるのが早い恩恵があるんですよ。
5. 空間一致・重ね合わせの簡略化
-
ベクター同士の重ね合わせはジオメトリ演算(交差判定)が必要 → 計算コストが高い
-
ラスタ同士なら単純なピクセル単位の論理演算(AND, OR)で高速化可能
-
例:
- 「森林 AND 傾斜30度以上」の地域抽出 →
forest_raster & slope_raster > 30
- 「森林 AND 傾斜30度以上」の地域抽出 →
-
-
災害時の迅速マッピング(洪水域 × 人口分布 × 避難施設)などで有効
ジオメトリが1つ目でもエラー起きると全部表示されなくなりますからね。あれ、どうにかならんのかね?以下で記事で地道で探すしか、、、、
6. 不規則形状の数値モデル化
-
ベクターは形状そのものだが、ラスタ化すると「数値の場」に変換でき、
機械学習や数値解析に直接入力可能 -
例:
- 土地利用ポリゴン → クラスIDラスタ → CNNやU-Netの入力画像・特徴量生成
- 水域の境界 → 0/1マスクラスタ → 流体シミュレーションの境界条件
7. データ共有と標準化
-
WebGISやゲームエンジン、AIモデルはラスタ形式に対応していることが多い
-
例:
- Cesium, Mapbox → タイル(PNG/JPEG/GeoTIFF)を直接使用
- Deep Learningモデル → 入力は画像配列
まとめ(メリット一覧)
- 高速化:配列演算で大規模解析を効率化
- 容量調整:解像度選択でデータサイズを制御
- 解析互換性:ラスタ専用手法が利用可能
- 並列/GPU処理:数値配列として最適化
- 単純化された重ね合わせ:ピクセル単位論理演算
- 数値モデル化:MLやシミュレーションに直接投入可能
- 互換性・配信性:WebGISやAIモデルへの橋渡し
覚えられないですわ〜、体感した方が早いわ〜
だからどんどん技術にふれるエンジニア強いんでしょうかね
でもなんとなく、主にまとめると2種類で
- 次の解析に繋げる特徴量
- データの最適化
そのどちらかをしたい時に思い出すといいですね。
もしツールを使わなかったら?
例えば、ツールがなくて手でシコシコ頑張る場合はどのような処理が必要でしょうか?
必要な観点やこのような範囲の決め方などが自然と処理出来るのようになることで楽になってるのかが見えてくると思います。
GDALでベクター→ラスタを作るときの“どこで迷いがちか”“何を決めるべきか”を、設定パラメータの意味・難易度・落とし穴・用途別プリセットの形でまとめます。CLI(gdal_rasterize)とPython API(gdal.Rasterize*)の対応も載せます。
まず最初に決める2点(一番重要)
- グリッド定義(解像度・範囲・原点)
-
-tr(ピクセルサイズ)、-te(範囲)、-tap(解像度にスナップ) - 既存ラスタに合わせるなら、そのラスタをテンプレとして先に作成し、そこへ焼き込み(band更新)するのが安全。
- 何を焼くか(値の決め方)
- 全画素同一:
-burn 1など - 属性から:
-a class_id - Z値(3D):
-3d - バンドごとに別の値:
-b 1 -burn 100 -b 2 -burn 50 ...
主なオプションと複雑さ
A. 出力グリッド・データ型・NoData
-
解像度:
-tr Xres Yres(例:-tr 10 10)
難易度:中。解析スケールと容量に直結(10m → 1km²で1万px)。 -
範囲:
-te xmin ymin xmax ymax
難易度:中。座標系に注意。必要なら-te_srs EPSG:XXXXで解釈系を指定。 -
ピクセル境界スナップ:
-tap
難易度:中。複数データを重ねるなら必須級。ピクセル境界が一致します。 -
サイズ直指定:
-ts width height
難易度:中。解像度より幅×高さで固定したいとき。 -
データ型:
-ot Byte|UInt16|Int16|UInt32|Float32...
難易度:低。クラスIDはByte/UInt16、連続値はFloat32が定番。 -
NoData:
-a_nodata 255など
難易度:低。論理演算やマスクで効くので必ず設定推奨。
B. 値の焼き付け方式
-
固定値:
-burn 1
難易度:低。マスク/存在フラグに最適。 -
属性値:
-a field_name
難易度:中。フィールド型と-otの整合、欠損処理に注意。 -
Z値(3Dジオメトリ):
-3d
難易度:中~高。データ側がZを持つ必要。 -
反転(外側を焼く):
-i
難易度:中。マスク作成に便利だが直感と逆になるのでミス注意。 -
加算モード:
-add
難易度:中。重複形状の重み合算や密度的カウントに便利(初期化-init 0を忘れず)。
C. 形状カバレッジの解釈
-
All touched:
-at
難易度:中。触れたピクセル全部を塗る → 面積過大寄り、粗解像度で顕著。
精度が必要なら非-at(中心点判定)+高解像度が無難。 -
フィルタリング:
-where "expr"/-sql "SELECT ..."/-dialect
難易度:中。レイヤ内サブセットやJOIN込みの前処理を1コマンドで。
D. 出力ファイル設定(容量・I/O)
-
フォーマット:
-of GTiff(普通はこれ) -
作成オプション:
-co- 例:
-co COMPRESS=DEFLATE -co PREDICTOR=2 -co TILED=YES -co BIGTIFF=IF_SAFER
難易度:中。容量と読み書き速度に直結。可視化/配信ならタイル化はほぼ必須。
- 例:
-
初期値:
-init 0(書かないところを0で満たす等)
難易度:低。-add利用時は必須級。
E. マルチバンド・優先順位・パフォーマンス
-
バンド指定:
-b 1 -b 2 ...+-burnを複数回
難易度:中。RGBや複数クラス同時書き込みに。 -
上書き/追記:既存ラスタへ焼き込むか、新規作成か
難易度:中。既存のテンプレに追記が安定(アライメント事故が起きにくい)。 -
スレッド:
-multi(環境による)
難易度:低~中。I/Oボトルネックだと効きが薄い。大きなポリゴン多数で威力。
CLI例(典型3パターン)
1) ポリゴンをクラスIDで焼いてカテゴリラスタに
gdal_rasterize \
-a class_id \
-ot UInt16 -a_nodata 0 \
-tr 10 10 -te 135.0 34.0 136.0 35.0 -tap \
-co COMPRESS=DEFLATE -co PREDICTOR=2 -co TILED=YES \
landuse.gpkg landuse_10m.tif
- 解像度10m、NoData=0、クラスIDをそのまま書く。Web配信や解析の基礎に。
2) 線をマスク化
gdal_rasterize \
-burn 1 -at \
-ot Byte -a_nodata 0 \
-tr 2 2 -tap \
-co COMPRESS=DEFLATE -co TILED=YES \
roads.gpkg roads_mask_2m.tif
-
-atで接触ピクセルを全塗り(表示用マスク向き)。解析用途なら解像度を細かく。
3) 既存ラスタのグリッドに“加算”で焼く(重複件数カウント)
# まずテンプレラスタ(解像度・範囲一致)を用意し初期化
gdal_create -of GTiff -ot UInt16 -outsize 10000 10000 template.tif
gdal_edit.py template.tif -a_srs EPSG:XXXX -a_ullr xmin ymax xmax ymin
gdal_translate template.tif counts.tif -co COMPRESS=DEFLATE -co TILED=YES
gdal_rasterize -add -burn 1 -init 0 points.gpkg counts.tif
- ポイントを重ねてヒートマップの元(カウントラスタ)に。
Python(GDAL)での最小実装
from osgeo import gdal, ogr, osr
# 1) 既存ラスタを作る(テンプレとして)
driver = gdal.GetDriverByName('GTiff')
dst = driver.Create('out.tif', xsize, ysize, 1, gdal.GDT_Byte,
options=['COMPRESS=DEFLATE', 'TILED=YES'])
gt = (xmin, pixel_size, 0, ymax, 0, -pixel_size) # geotransform
dst.SetGeoTransform(gt)
srs = osr.SpatialReference()
srs.ImportFromEPSG(XXXX)
dst.SetProjection(srs.ExportToWkt())
dst.GetRasterBand(1).SetNoDataValue(0)
dst.GetRasterBand(1).Fill(0) # init
# 2) ベクターを開いてレイヤ取得
src = ogr.Open('vector.gpkg')
layer = src.GetLayer('layer_name')
# 3) 属性から焼く(固定値なら options={'burnValues':[1]} など)
gdal.RasterizeLayer(dst, [1], layer,
options=['ATTRIBUTE=class_id', 'ALL_TOUCHED=TRUE'])
dst.FlushCache(); dst = None
ありがちな落とし穴(と回避策)
-
グリッド不一致:後工程で重ねたらズレる → 既存ラスタへ“焼き込み”か、
-tapでスナップ。 -
座標系の取り違え:
-teの単位を勘違い →-te_srs EPSG:XXXXを活用。 -
-atで面積過大:粗い解像度だと特に顕著 → 解像度を上げる/オフにする。 -
属性型ミスマッチ:
-a+-ot不整合 → クラスIDは整数型、連続値は浮動小数。 -
巨大出力でI/O地獄:
-co TILED=YES+圧縮、ブロックサイズ(BLOCKXSIZE/BLOCKYSIZE)最適化。 -
重複形状の合成:上書きか加算か →
-addか、先に dissolve/merge。
用途別プリセット(サクッと使える指針)
| 用途 | 代表設定 | ポイント |
|---|---|---|
| 解析用クラスマップ(土地利用/規制区分) | -a class -ot UInt16 -a_nodata 0 -tr 10 10 -tap -co COMPRESS=DEFLATE -co TILED=YES |
一貫したグリッド・NoData必須 |
| 存在マスク(水域・道路可視化) |
-burn 1 -ot Byte -a_nodata 0 -tr 2 2 -tap -co COMPRESS=DEFLATE(見栄え重視なら-at) |
精度重視なら-atは慎重に |
| 密度・カウント(ポイント重なり数) | 事前に0初期化→-add -burn 1
|
バンド型はUInt16/UInt32
|
| 重み合算(属性ウェイト) | 0初期化→-add -a weight
|
欠損値の扱いに注意 |
| Z焼き込み(3Dライン等) | -3d -ot Float32 |
ソースのZが必須 |
密度についての処理
一般的な統計処理を実装しなければなりません。
カーネルが決まったらそれらを統計処理していく流れになります。
Python のようにデータ処理が簡潔な言語でもまぁまぁ書かなければならない印象です。
Python の事前実装
実装内容は以下です。
- ライブラリインポート
- サンプルデータの用意
- 統計処理の関数定義
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 乱数の再現性
np.random.seed(42)
# -----------------------------
# サンプル生成(1次元・2次元)
# -----------------------------
def sample_1d(n=100, centers=(-2.0, 2.0), stds=(0.6, 0.6), weights=(0.5, 0.5)):
c1, c2 = centers
s1, s2 = stds
w1, w2 = weights
n1 = int(n * w1)
n2 = n - n1
x1 = np.random.normal(c1, s1, n1)
x2 = np.random.normal(c2, s2, n2)
return np.concatenate([x1, x2])
def sample_2d(n=100, centers=((-2.0, -2.0), (2.0, 2.0)), stds=(0.8, 0.8), weights=(0.5, 0.5)):
(c1x, c1y), (c2x, c2y) = centers
s1, s2 = stds
w1, w2 = weights
n1 = int(n * w1)
n2 = n - n1
x1 = np.random.normal(c1x, s1, n1)
y1 = np.random.normal(c1y, s1, n1)
x2 = np.random.normal(c2x, s2, n2)
y2 = np.random.normal(c2y, s2, n2)
return np.column_stack([np.concatenate([x1, x2]), np.concatenate([y1, y2])])
# -----------------------------
# KDE 実装(NumPyのみ・ガウス核)
# -----------------------------
def silverman_bandwidth_1d(x):
"""Silverman's rule of thumb for 1D."""
x = np.asarray(x)
n = x.size
if n < 2:
return 1.0
std = np.std(x, ddof=1)
# IQR を利用してロバスト化(標準的な補助統計)
q75, q25 = np.percentile(x, [75 ,25])
iqr = q75 - q25
sigma = min(std, iqr / 1.349) if iqr > 0 else std
h = 1.06 * sigma * n ** (-1/5)
if not np.isfinite(h) or h <= 0:
h = 1.0
return h
def kde_1d(x, grid=None, bandwidth=None, gridsize=400, padding=3.0):
x = np.asarray(x).ravel()
n = x.size
if bandwidth is None:
bandwidth = silverman_bandwidth_1d(x)
if grid is None:
xmin = x.min() - padding * bandwidth
xmax = x.max() + padding * bandwidth
grid = np.linspace(xmin, xmax, gridsize)
diffs = (grid[None, :] - x[:, None]) / bandwidth
density = (np.exp(-0.5 * diffs**2)).sum(axis=0)
density *= 1.0 / (n * bandwidth * np.sqrt(2.0 * np.pi))
return grid, density, bandwidth
def scott_factor(n, d):
"""Scott's rule factor n^(-1/(d+4))"""
return n ** (-1.0 / (d + 4.0))
def kde_2d(X, bandwidth=None, gridsize=200, padding=3.0):
"""
2次元の等方/各軸独立な帯域幅でのガウス核KDE。
bandwidth: None -> Scott's rule(各軸の標準偏差 × n^(-1/(d+4)))
float -> 各軸同一の等方バンド幅
(hx, hy) -> 各軸別バンド幅
"""
X = np.asarray(X)
assert X.ndim == 2 and X.shape[1] == 2, "X must be (n,2)"
n = X.shape[0]
d = 2
stds = X.std(axis=0, ddof=1)
factor = scott_factor(n, d)
if bandwidth is None:
h = stds * factor
else:
if np.isscalar(bandwidth):
h = np.array([float(bandwidth), float(bandwidth)])
else:
h = np.array(bandwidth, dtype=float)
if h.size != 2:
raise ValueError("bandwidth must be scalar or length-2 iterable")
h[h <= 0] = 1.0 # 安全対策
# グリッド作成
xmin = X[:,0].min() - padding * h[0]
xmax = X[:,0].max() + padding * h[0]
ymin = X[:,1].min() - padding * h[1]
ymax = X[:,1].max() + padding * h[1]
gx = np.linspace(xmin, xmax, gridsize)
gy = np.linspace(ymin, ymax, gridsize)
XX, YY = np.meshgrid(gx, gy, indexing="xy")
# ベクトル化して密度を計算
points = np.column_stack([XX.ravel(), YY.ravel()]) # (M,2)
dx = (points[:, 0][None, :] - X[:, 0][:, None]) / h[0] # (n, M)
dy = (points[:, 1][None, :] - X[:, 1][:, None]) / h[1] # (n, M)
exparg = -0.5 * (dx * dx + dy * dy)
z = np.exp(exparg).sum(axis=0)
z *= 1.0 / (n * (2.0 * np.pi) * (h[0] * h[1]))
Z = z.reshape(gridsize, gridsize)
return gx, gy, Z, h
# 1次元サンプルとKDE
x = sample_1d(n=100, centers=(-2.0, 2.0), stds=(0.6, 0.6), weights=(0.5, 0.5))
grid, dens, h1d = kde_1d(x)
plt.figure(figsize=(16, 5), dpi=100, facecolor="white", edgecolor="black")
plt.hist(x, bins=30, density=True, alpha=0.5, color="blue", edgecolor="black", label="ヒストグラム")
plt.plot(grid, dens, color="red", lw=2, label="KDE")
plt.title(f"1次元 KDE(Silverman 帯域幅 ≈ {h1d:.3f})")
plt.xlabel("x")
plt.ylabel("density")
plt.legend()
plt.tight_layout()
plt.savefig("kde_1d.png", dpi=150)
plt.show()

1次元データによる密度推定
X = sample_2d(n=100, centers=((-2.0, -2.0), (2.0, 2.0)), stds=(0.8, 0.8), weights=(0.5, 0.5))
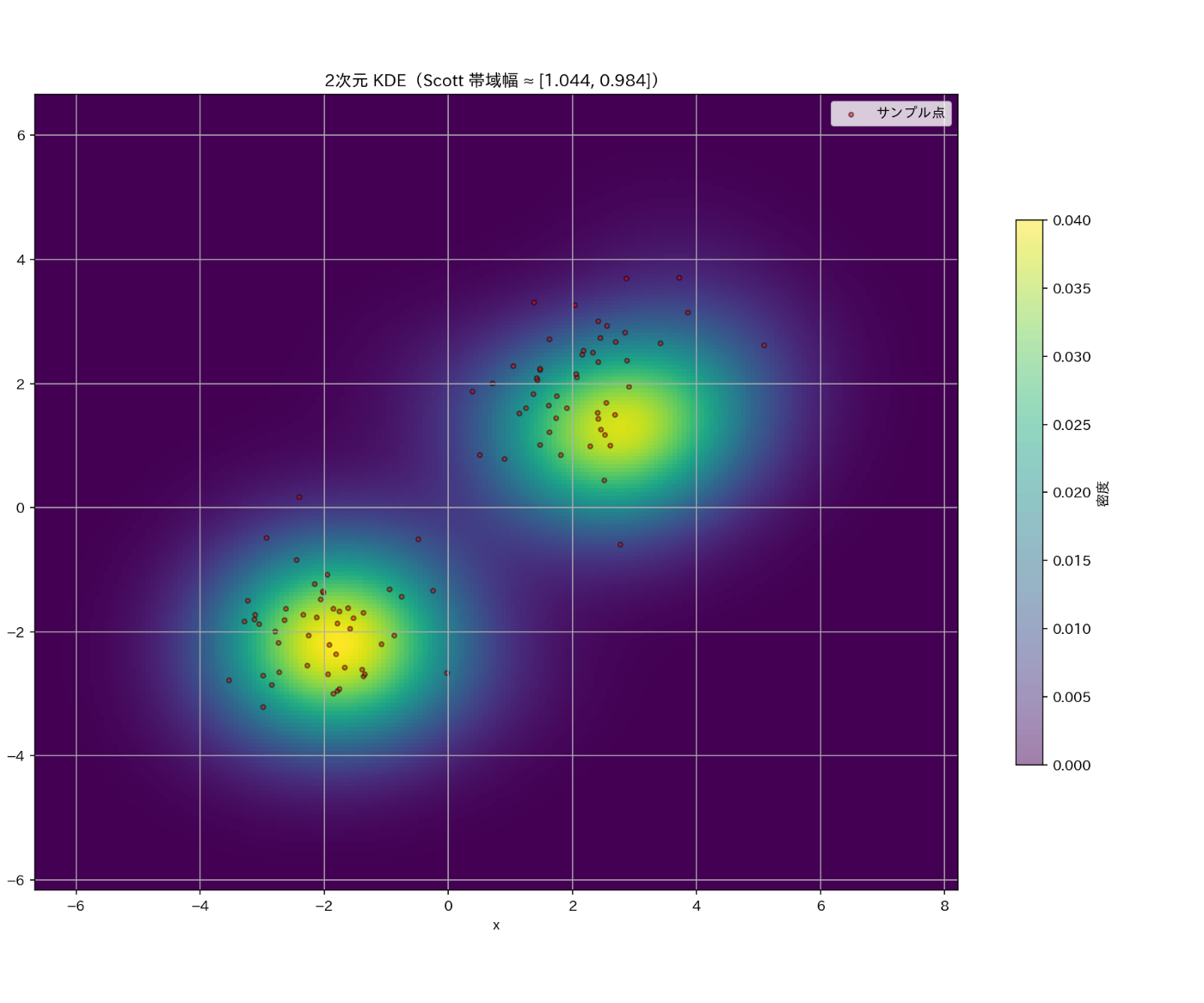
gx, gy, Z, h2d = kde_2d(X, bandwidth=None, gridsize=200)
plt.figure(figsize=(12, 10), dpi=100, facecolor="white", edgecolor="black")
extent = [gx.min(), gx.max(), gy.min(), gy.max()]
plt.imshow(Z.T, origin="lower", extent=extent, aspect="equal")
plt.scatter(X[:,0], X[:,1], s=10, c="red", edgecolor="black", alpha=0.5, label="サンプル点")
plt.title(f"2次元 KDE(Scott 帯域幅 ≈ [{h2d[0]:.3f}, {h2d[1]:.3f}])")
plt.xlabel("x")
plt.ylabel("y")
plt.tight_layout()
plt.legend()
plt.colorbar(label="密度", shrink=0.6)
plt.grid()
plt.clim(0, Z.max() * 0.8) # カラ
plt.savefig("kde_2d.png", dpi=150)
plt.show()
2次元データによる密度推定
ツールなし処理のまとめ
- 最重要は“グリッド定義”と“焼く値の決め方”。ここが固まれば残りはチューニング。
- 表示・解析・配信のどれを優先するかで、
-atや圧縮・タイル設定が変わります。 - 大規模な反復処理があるなら、**テンプレラスタ+追記(焼き込み)**の運用が事故らず高速。
- 統計処理のパイプライン
ここまで考えないと行けないのを GUIでサクッとできちゃうのがいいところです。
逆に〜、これらをゴリゴリ実装することで次の解析やアプリケーションを発展させることは可能そうですね!
きっかけ
堀池諒さんの投稿がきっかけで興味を持ちました。
統計処理や可視化だけの意味しかなくね?って思っていたのが浅はかでした。
技術・ビジネス的な効果がソリューションにあることに気づいてから色々調べてました。
雑に絡んですいません。
さいごに
密度解析について長くなっちゃいましたがいかがだったでしょうか?
見せ方って結構大事で、他者への共有、説明、認識合わせには必須の能力だと思ってます。それによって、科研費、顧客の印象、ステークホルダー操作などに差ができちゃいますからね〜
とわいえ、根本的な中身の処理も実装できる理解や技術力も当然必要です。
最近、勉強すればするほどなんも知らんなぁって感じ (ぴえん)
宣伝
日頃はこのようなZennの個人記事を書いています。
そして、宙畑にもよく寄稿しています。
また、来年には QGISの衛星画像解析の書籍を出版いたします。
自己紹介
普段は宇宙領域でテックリードをしております。X(旧Twitter)アカウントでは、宇宙領域や機械学習などの科学やコンペなどについて発言することが多いです。
SAR解析をよくやっていますが、画像系AI、地理空間や衛星データ、点群データ、3Dデータに関心があります。勉強している人は好きなので楽しく絡んでくれると嬉しいです。
SAR解析者への道シリーズ もよろしくお願いします!

衛星データ解析として、宙畑のライターもしています。
お仕事はとても忙しいのでご相談やご提案くらいでしたら可能です。
Discussion