Solafune 衛星画像の5倍超解像度化 (for OSS) コンペの Pytorch Lightning Baseline
皆さん年末はいかがお過ごしでしょうか? 私は今日まさに帰省している最中です!
そのちょうど良いタイミングで Solafuneにて 衛星画像の5倍超解像度化 (for OSS) のコンペが開催されたので新幹線内の移動時間の 3時間のRTAで baseline を作成したので共有します
このコンペの参加者が増えるとともに超解像が発展してくれることを願っています
cf. @solafune (https://solafune.com)コンテストの参加以外の目的とした利用及び商用利用は禁止されています。商用利用・その他当コンテスト以外で利用したい場合はお問い合わせください。(https://solafune.com)
概要
- 目的
- 利用ツールや論文
- 環境構築
- 分析共有
- 学習共有
- 提出までのフロー
目的
-
SwinIR(超解像のモデル)を利用してみたかったこと - 超解像のタスクの前処理や課題を知りたかったこと
利用ツールや論文
本記事では以下を利用しています。
- Framework: Pytorch Lightning
- Logging: Wandb
- Model: SwinIR
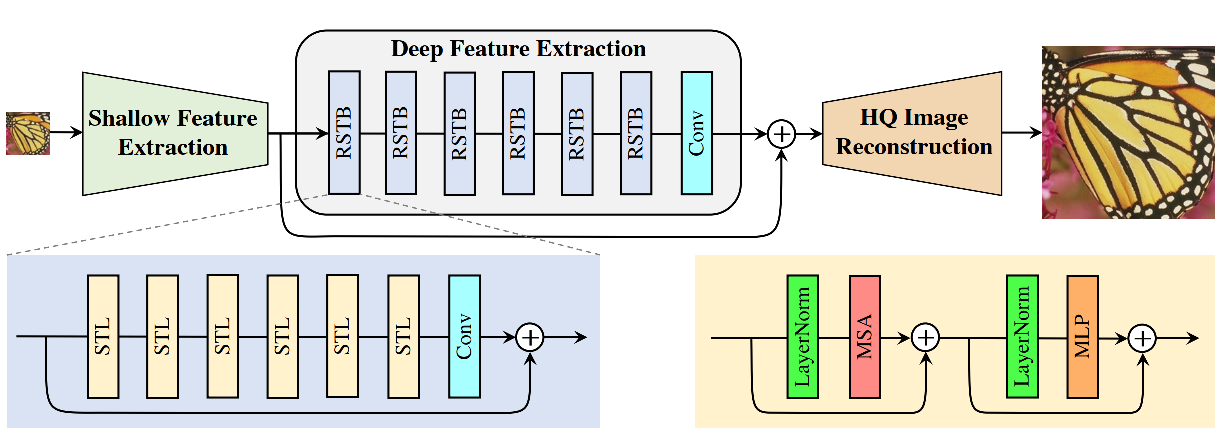
環境構築
正直 Docker化 などをしっかりするんですが今回は時間がないので requirements.txt だけですがお許しください
Python: 3.8
pip install -r env/requirements.txt
分析共有
データの準備
データは コンペから取得して以下のように配置します。
data
├── test
│ ├── *_high.tif
│ ├── *_low.tif
│ └── test.zip
├── train
│ ├── *_high.tif
│ ├── *_low.tif
│ └── train.zip
└── uploadsample
├── *_high.tif
├── *_low.tif
└── uploadsample.zip
EDA Notebook
なにはともあれどうゆうデータなのかを確認します。
コード詳細
@dataclass
class CFG(object):
# data
DATA_ROOT: str = '../../data'
ROOT_TRAIN: str = f'{DATA_ROOT}/train'
ROOT_TEST: str = f'{DATA_ROOT}/test'
ROOT_SAMPLE: str = f'{DATA_ROOT}/uploadsample'
# output
OUTPUT_DIR: str = f'output/001/'
cfg = Box({k:v for k, v in CFG().__dict__.items() if not '__' in k})
pprint(cfg)
にてデータへのパスを設定します。
IDX = 2
PATH_IMG = PATHS_HIGH_TRAIN[IDX]
fname = os.path.basename(PATH_IMG)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
img = tifffile.imread(PATH_IMG)
print(img.shape, img.dtype)
plt.figure(figsize=(8, 8), facecolor='white', dpi=80)
plt.title(f'FILE: {fname}')
plt.imshow(img)
plt.colorbar(shrink=0.85, aspect=30, orientation='vertical')
plt.savefig(f'{cfg.OUTPUT_DIR}sample_idx{IDX}_name{fname}.png')
plt.show();
衛星データを可視化します。
df = pd.DataFrame({
'path_high': PATHS_HIGH_TRAIN,
'path_low': PATHS_LOW_TRAIN
})
display(df.sample(4))
def load_image_info(row):
P_H = row.path_high
img_h = tifffile.imread(P_H)
h_H, w_H, _ = img_h.shape
dtype_h = img.dtype
P_L = row.path_low
img_l = tifffile.imread(P_L)
h_L, w_L, _ = img_l.shape
dtype_l = img.dtype
return h_H, w_H, dtype_h, \
img_h[:,:, 0].mean(), img_h[:,:, 0].std(), \
img_h[:,:, 1].mean(), img_h[:,:, 1].std(), \
img_h[:,:, 2].mean(), img_h[:,:, 2].std(), \
h_L, w_L, dtype_l,\
img_l[:,:, 0].mean(), img_l[:,:, 0].std(), \
img_l[:,:, 1].mean(), img_l[:,:, 1].std(), \
img_l[:,:, 2].mean(), img_l[:,:, 2].std()
meta_columns = [f'{reso}_{feat}' for reso in ['high', 'low'] for feat in
['hight', 'width', 'dtype',
'r_mean', 'r_std',
'g_mean', 'g_std',
'b_mean', 'b_std',
]]
tqdm.pandas()
df[meta_columns] = df.progress_apply(load_image_info, axis=1, result_type='expand')
統計量を取得します。
df.to_csv(f'{cfg.DATA_ROOT}/train.csv', index=False, header=True)
学習するための CSV を保存します。
さっそく統計量を確認します
for col in ['high_hight',
'high_width',
'high_dtype',
'low_hight',
'low_width',
'low_dtype',]:
plt.figure(figsize=(8, 8), facecolor='white', dpi=80)
sns.catplot(x=col, data=df, kind="count")
plt.savefig(f'{cfg.OUTPUT_DIR}countplot_C{col}.png')
plt.show();






これらを見ると、衛星データにしてはかなり統一されているデータセットになっているようです。
for stat in ['mean', 'std']:
for reso in ['high', 'low']:
plt.figure(figsize=(12, 6), facecolor='white', dpi=80)
for c in ['r', 'g', 'b']:
col = f'{reso}_{c}_{stat}'
sns.distplot(df[col], label=f'C:{c} Reso:{reso}', color=c, bins=100)
plt.savefig(f'{cfg.OUTPUT_DIR}countplot_{reso}_{stat}.png')
plt.show();
こちらで画像ピクセルの統計量を見てみましょう
衛星は dynamic range が多いですが綺麗に処理されているようです




人間はREDの波長が強く見えるのをプロバイダー側で補正しているせいか、定性的には同じに見えるが RED はほんの少し分布が違うようです。
for stat in ['mean', 'std']:
plt.figure(figsize=(12, 6), facecolor='white', dpi=80)
for c in ['r', 'g', 'b']:
col = f'{reso}_{c}_{stat}'
sns.jointplot(x=f'high_{c}_{stat}', y=f'low_{c}_{stat}', data=df, kind='hex', color=c)
plt.savefig(f'{cfg.OUTPUT_DIR}hexplot_{reso}_{stat}.png')
plt.show();
高解像と低解像の統計量の違いを見てみます


どの色も低解像と高解像では分散が低い場合は値が異なるようです
これがコンペの勝敗を分けるのか???
全体ペア分布図

学習共有
Baseline Notebook
学習から提出までの手順を記載しています
コード詳細
Import
import os
import warnings
import random
from pprint import pprint
import copy
from typing import List, Tuple
from glob import glob
import json
import csv
import gc
from dataclasses import dataclass
from joblib import Parallel, delayed
from tqdm import tqdm
import numpy as np
import pandas as pd
from box import Box
import matplotlib.pyplot as plt
from skimage.metrics import structural_similarity as ssim
import tifffile
from sklearn.model_selection import StratifiedKFold, KFold
import torch
import torch.optim as optim
import torch.nn as nn
from torch import Tensor
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
import albumentations as A
from albumentations.pytorch import ToTensorV2
from timm import create_model
from pytorch_lightning import Trainer
from pytorch_lightning.utilities.seed import seed_everything
from pytorch_lightning import callbacks
from pytorch_lightning.callbacks import RichProgressBar, TQDMProgressBar
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks.progress.rich_progress import RichProgressBarTheme
from pytorch_lightning.callbacks.progress import ProgressBarBase
from pytorch_lightning.loggers import TensorBoardLogger, WandbLogger
from pytorch_lightning import LightningDataModule, LightningModule
import wandb
wandb.login(key='****')
warnings.filterwarnings("ignore")
torch.autograd.set_detect_anomaly(True)
pd.options.display.max_colwidth = 250
pd.options.display.max_rows = 30
# インライン表示
%matplotlib inline
Config
from typing import List, Set, Dict, Any
class CFG(object):
# basic
debug: bool = False
debug_sample: int = 128
folds: int = 4
seed: int = 417
eps: float = 1e-12
outdir: str = 'output/'
# data
DATA_ROOT: str = f'../../data/'
preprocess: Dict[str, int] = {
"input_size": 130,
"upscale": 5,
"output_size": 650
}
# train
epoch: int = 40
trainer: Dict[str, Any] = {
'gpus': 1,
'accumulate_grad_batches': 1,
'fast_dev_run': False,
'num_sanity_val_steps': 0,
'resume_from_checkpoint': None,
'check_val_every_n_epoch': 2,
'val_check_interval': 1.0,
# 'precision' : 16,
'gradient_clip_val': 25.,
'gradient_clip_algorithm': "value"
}
optimizer: Dict[str, Any] = {
'name': 'optim.AdamW',
'params': {
'lr': 1e-3,
},
}
scheduler: Dict[str, Any] = {
'name': 'optim.lr_scheduler.CosineAnnealingWarmRestarts',
'params':{
'T_0': 20,
'eta_min': 1e-5,
}
}
model: Dict[str, Any] = {
# config: https://github.com/JingyunLiang/SwinIR/blob/main/main_test_swinir.py
"swinir": {
'upscale': preprocess['upscale'],
'img_size': (-1, -1),
'window_size': 7,
'img_range': 255.,
'depths': [6, 6, 6, 6, 6, 6],
'embed_dim': 60,
'num_heads': [6, 6, 6, 6, 6, 6],
'mlp_ratio': 2,
'upsampler': 'pixelshuffledirect', # nearest+conv, pixelshuffledirect, pixelshuffle
'resi_connection': '1conv',
}
}
train_loader: Dict[str, Any] = {
'batch_size': 16,
'shuffle': True,
'num_workers': 16,
'pin_memory': False,
'drop_last': True,
}
val_loader :Dict[str, Any]= {
'batch_size': 16,
'shuffle': False,
'num_workers': 16,
'pin_memory': False,
'drop_last': False
}
info = ''
# model info
info += f'SwinIR_W{model["swinir"]["window_size"]}D{len(model["swinir"]["depths"])}'
info += f'E{model["swinir"]["embed_dim"]}H{len(model["swinir"]["num_heads"])}Unc'
# train info
info += f'_{optimizer["name"].split(".")[1]}{optimizer["params"]["lr"]}{scheduler["params"]["eta_min"]}_E{epoch}_fl-tr'
# logging
project: str = "Solafune-SR-2023"
runname: str = "A6000"
group: str = f'A6000_V1_IMG{preprocess["input_size"]}_{info}_B{train_loader["batch_size"]}'
notebook: str = '001_baseline.ipynb'
# post info
augmentation: str = ''
fold: int = -1
if debug:
epoch = 10
group = 'DEBUG'
# box
cfg = Box({k:v for k, v in dict(vars(CFG)).items() if '__' not in k})
# 乱数のシードを設定
seed_everything(cfg.seed)
torch.manual_seed(cfg.seed)
np.random.seed(cfg.seed)
random.seed(cfg.seed)
pprint(cfg)
は各自環境で設定して実験してみてください
基本的には
-
DATA_ROOT: データの場所 -
outdir: 出力先 -
modelSwinIR のモデル構造 - それ以外は 学習方法やログの設定
のようになっています。
Augmentation
# augmentation
tf_dict = {
'train': A.Compose(
[
# A.CoarseDropout(max_holes=4, max_height=4, max_width=4,
# min_holes=None, min_height=None, min_width=None,
# fill_value=0.15, mask_fill_value=0.0, always_apply=False, p=0.25),
# A.ElasticTransform(alpha=1, sigma=50, alpha_affine=50, interpolation=1,
# border_mode=4, value=None, mask_value=None, always_apply=False,
# approximate=False, same_dxdy=False, p=0.25),
# A.GridDistortion(num_steps=5, distort_limit=0.4, interpolation=1,
# border_mode=4, value=None, mask_value=None, always_apply=False, p=0.25),
# A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=15, interpolation=1,
# border_mode=4, value=0.01, mask_value=0.0, shift_limit_x=None, shift_limit_y=None,
# p=0.5),
# A.OneOf([
# # A.GaussNoise(var_limit=(1e-3, 8e-1), mean=0.15, p=0.5),
# A.Blur(blur_limit=9, p=0.25),
# A.RandomBrightnessContrast(brightness_limit=0.1, contrast_limit=0.1, brightness_by_max=True, p=0.5),
# ], p=0.9),
A.Transpose(p=0.25),
A.Flip(p=0.5),
# A.HueSaturationValue (hue_shift_limit=5, sat_shift_limit=10, val_shift_limit=5, p=0.5),
# A.Rotate(limit=30, p=0.5),
# A.Resize(cfg.preprocess.input_size, cfg.preprocess.input_size),
# A.Normalize(mean=(0.485), std=(0.229)),
ToTensorV2(),
]
),
'val': A.Compose(
[
# A.Resize(cfg.preprocess.input_size, cfg.preprocess.input_size),
# A.Normalize(mean=(0.485), std=(0.229)),
ToTensorV2(),
]
),
}
tf_dict['test'] = tf_dict['val']
cfg.augmentation = str(tf_dict).replace('\n', '').replace(' ', '')
cfg.augmentation
Augmentation の設定です。
デフォルトは収束速度を意識して
Flip-
Transpose
の幾何的な変形のみです。
DataSet
class SolafuneSR2023Dataset(Dataset):
def __init__(self,
df,
phase: str='train',
is_path: bool=False,
):
""" pytorch dataset for Solafune Super Resolution 2023 data. """
self.df = df
self.phase = phase
self.is_path = is_path
self.transform = tf_dict[self.phase]
def __len__(self):
return len(self.df)
def __getitem__(self, index):
row = self.df.iloc[index]
img_l = tifffile.imread(row.path_low)
if self.phase == 'test':
img = self.transform(image=img_l)["image"]
in_pad = torch.zeros((3, *cfg.model.swinir.img_size), dtype=torch.float32)
in_pad[:, :cfg.preprocess.input_size, :cfg.preprocess.input_size] = img
return in_pad, row.path_low
else:
img_h = tifffile.imread(row.path_high)
# augmentation
transformed = self.transform(image=img_l, mask=img_h)
img = transformed["image"]
mask = transformed["mask"].permute(2, 0, 1)
# padding
in_pad = torch.zeros((3, *cfg.model.swinir.img_size), dtype=torch.float32)
in_pad[:, :cfg.preprocess.input_size, :cfg.preprocess.input_size] = img
if self.is_path:
return in_pad, mask, row.path_low
return in_pad, mask
class SolafuneSR2023Module(LightningDataModule):
def __init__(
self,
df_train,
df_val,
cfg,
):
""" pytorch lightning datamodeule for Solafune Super Resolution 2023 data. """
super().__init__()
self.df_train = df_train
self.df_val = df_val
self._cfg = cfg
def train_dataloader(self):
dataset = SolafuneSR2023Dataset(self.df_train, phase='train')
return DataLoader(dataset, **self._cfg.train_loader)
def val_dataloader(self):
dataset = SolafuneSR2023Dataset(self.df_val, phase='val')
return DataLoader(dataset, **self._cfg.val_loader)
学習、推論ループのです。
Loss は ssim を直接最適化しています。
以下の記事を参考にしました。
model
class SRModel(LightningModule):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.__build_model()
self.ssim_max = 0.0
self.mse = nn.MSELoss()
self.mae = nn.L1Loss()
self.criterion = SSIMpixLoss()
def __build_model(self):
self.backbone = SwinIR(**self.cfg.model.swinir)
def forward(self, x):
f = self.backbone(x)
f = f[:, :, :self.cfg.preprocess.output_size, :self.cfg.preprocess.output_size] # batch, channel, height, width
f = torch.clamp(f, min=0.0, max=255.0)
return f
def training_step(self, batch, batch_idx):
return self.__share_step(batch, 'train')
def validation_step(self, batch, batch_idx):
return self.__share_step(batch, 'val')
def __share_step(self, batch, mode):
imgs_l, imgs_h = batch
imgs_l, imgs_h = imgs_l.float(), imgs_h.float()
preds_h = self.forward(imgs_l)
loss = self.criterion(preds_h ,imgs_h, as_loss=True)
# mertics
ssim_map = self.criterion(preds_h ,imgs_h, as_loss=False).detach()
ssim = ssim_map.mean().cpu()
mse = self.mse(preds_h ,imgs_h).detach().cpu()
mae = self.mae(preds_h ,imgs_h).detach().cpu()
return {'loss': loss, 'mae': mse, 'mse': mae, 'ssim': ssim }
def training_epoch_end(self, outputs):
self.__share_epoch_end(outputs, 'train')
def validation_epoch_end(self, outputs):
self.__share_epoch_end(outputs, 'val')
def __share_epoch_end(self, outputs, mode):
ssims, maes, mses, losses = [], [], [], []
for out in outputs:
ssim, mae, mse, loss = out['ssim'], out['mse'], out['mae'], out['loss'].detach().cpu()
losses.append(loss)
maes.append(mae)
mses.append(mse)
ssims.append(ssim)
losses = np.mean(losses)
ssims = np.mean(ssims)
mses = np.mean(mses)
maes = np.mean(maes)
self.log(f'{mode}/loss', losses)
self.log(f'{mode}/ssim', ssims)
self.log(f'{mode}/mse', mses)
self.log(f'{mode}/mae', maes)
if mode == 'val':
if self.ssim_max < ssim:
self.ssim_max = ssims
# logging val max ssim
self.log(f'{mode}/ssim_max', self.ssim_max)
def configure_optimizers(self):
optimizer = eval(self.cfg.optimizer.name)(
self.parameters(), **self.cfg.optimizer.params
)
scheduler = eval(self.cfg.scheduler.name)(
optimizer,
**self.cfg.scheduler.params
)
return [optimizer], [scheduler]
SwinIR は 以下から import しています
コード自体は Gihubから拝借しています。
Pytorch Lightning では上記のように学習パイプライン自体の書き方が決まっているので自由度は減りますが、共有したり、ログ管理がとても楽になります。
Fold
n_fold = np.zeros(len(df))
skf = KFold(n_splits=cfg.folds, shuffle=True, random_state=cfg.seed)
for fold, (_, val_idx) in enumerate(skf.split(range(len(df)))):
n_fold[val_idx] = fold
df["fold"] = n_fold.astype(np.uint16)
display(df.head(6))
こちらで学習と検証のファイル管理をします。
Visualize
sample_dataloader = SolafuneSR2023Module(df, df, cfg).val_dataloader()
imgs_l, imgs_h = next(iter(sample_dataloader))
print(imgs_l.shape, imgs_h.shape)
num = 16
plt.figure(figsize=(16, 10), facecolor='white')
plt.title('Vizualuze High Resolution')
for it, image in enumerate(imgs_h[:num]):
plt.subplot(4, 4, it+1)
plt.imshow(image.permute(1, 2, 0).numpy().astype(np.uint8))
plt.axis('off')
plt.savefig(f'{cfg.outdir}visualization_high.png')
plt.show();
plt.figure(figsize=(16, 10), facecolor='white')
plt.title('Vizualuze Low Resolution')
for it, image in enumerate(imgs_l[:num]):
plt.subplot(4, 4, it+1)
plt.imshow(image.permute(1, 2, 0).numpy().astype(np.uint8))
plt.axis('off')
plt.savefig(f'{cfg.outdir}visualization_low.png')
plt.show();
こちらにて処理ループの動作確認と可視化を行っています。
Train
for fold in range(cfg.folds):
print('■'*30, f"fold: {fold}", '■'*30)
# train val split
train_df = df[df['fold'] != fold].reset_index(drop=True)
val_df = df[df['fold'] == fold].reset_index(drop=True)
print(f'[num sample] train: {len(train_df)} val:{len(val_df)}')
assert len(train_df) > 0 and len(val_df) > 0, f'[Num Sample] train: {len(train_df)} val:{len(val_df)}'
datamodule = SolafuneSR2023Module(train_df, val_df, cfg)
model = SRModel(cfg)
# metrics
logging_dir = f"output/{cfg.group}/{cfg.runname}_fold{fold}"
loss_checkpoint = callbacks.ModelCheckpoint(
dirpath=logging_dir ,
filename="loss",
monitor="val/loss",
save_top_k=1,
mode="min",
save_last=True,
)
# logger
tb_logger = TensorBoardLogger(logging_dir)
wandb_logger = WandbLogger(
name=f'{cfg.runname}-fold{fold}',
group=cfg.group,
project=cfg.project,
config=cfg,
tags=[f'fold{fold}', 'A6000', 'SwinIR'],
)
lr_monitor = callbacks.LearningRateMonitor()
earystopping = EarlyStopping(monitor="val/loss")
progress_bar = RichProgressBar(
theme=RichProgressBarTheme(
description="green_yellow",
progress_bar="green1",
progress_bar_finished="green1",
progress_bar_pulse="#6206E0",
batch_progress="green_yellow",
time="grey82",
processing_speed="grey82",
metrics="grey82",
)
)
tddm_callbacks = TQDMProgressBar(refresh_rate=1)
# rich: https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.callbacks.RichProgressBar.html#pytorch_lightning.callbacks.RichProgressBar
# trainer
trainer = Trainer(
logger=[tb_logger,wandb_logger],
max_epochs=cfg.epoch,
# callbacks=[lr_monitor, loss_checkpoint, earystopping, progress_bar],
callbacks=[lr_monitor, loss_checkpoint, tddm_callbacks],
**cfg.trainer,
)
trainer.fit(model, datamodule=datamodule)
# save
df.to_csv(f'{logging_dir}/fold.csv', index=False)
cfg.to_json(f'{logging_dir}/cfg.json', indent=4)
wandb.save(cfg.notebook)
wandb.finish()
break
実際にモデルを学習させる部分です。
Pandas の DataFrame で基本的に学習データを管理してその情報に基づいて Fold ごとに記録や管理をしています。
1時間ほどしかなかったので学習は途中やめですが、精度指標の推移を見ていきます。
精度指標はコンペの SSIM ですが同時にモデルの観測のために MSE(2乗誤差), MAE(絶対値差)を記録しています。
Learning Rate

Train




Validation





学習中の SSIM を見ると低いですが後ほど、ライブラリーで計算する SSIM はそれなりに高いので安心してください
Validation
val_df = df[df['fold'] == fold].reset_index(drop=True)
val_ds = SolafuneSR2023Dataset(val_df, is_path=True, phase='val')
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
if SAVE:
SAVE_DIR = f'{logging_dir}/eval/'
os.makedirs(SAVE_DIR, exist_ok=True)
FNAMES, PATHS, SCORES, = [], [], []
for (image, labels, paths) in tqdm(val_dl, leave=False):
image = image.to(device)
with torch.no_grad():
logits = model(image)
preds = torch.round(logits, decimals=0)
preds = preds.cpu().numpy().transpose(0, 2, 3, 1).astype(np.uint8)
labels = labels.numpy().transpose(0, 2, 3, 1)
# per batch
for i in range(preds.shape[0]):
img_h = labels[i]
pred_h = preds[i]
path = paths[i]
ssim_score = ssim(img_h, pred_h, multichannel=True)
PATHS.append(path)
SCORES.append(ssim_score)
FNAME = os.path.basename(path).replace("_low.tif", "_answer.tif")
FNAMES.append(FNAME)
if SAVE:
tifffile.imwrite(f'{SAVE_DIR}/{FNAME}', pred_h)
df_preds = pd.DataFrame()
df_preds['file_name'] = FNAMES
df_preds['score'] = SCORES
df_preds['path'] = PATHS
ssim_mean = np.mean(SCORES)
PATH_PRED = f'{logging_dir}/predict_fold{fold}_ssim{ssim_mean:3f}.csv'
df_preds.to_csv(PATH_PRED, index=False)
print(F'>>> csv: {PATH_PRED}')
display(df_preds.head())
OOF での検証データで推論を行い、SSIM のCVスコアを計算します。
ここでの SSIM は from skimage.metrics import structural_similarity を使用しています。
def visualize_scores(scores, metrics_name='ssim'):
# 分布とヒストグラムの可視化
x = range(len(scores))
m = np.mean(scores)
fig = plt.figure(figsize=(24, 16), facecolor='white')
ax = fig.add_subplot(2, 1, 1)
ax.hist(scores, bins=30, histtype='barstacked', ec='black') # ヒストグラムをプロット
ax.set_title('Histgram') # 図のタイトル
ax.set_xlabel('index') # x軸のラベル
ax.set_ylabel('Frequency') # y軸のラベル
ax = fig.add_subplot(2, 1, 2)
ax.scatter(x=x, y=scores) # 散布図をプロット
ax.plot([0, len(scores)-1],[m, m], "red", linestyle='dashed', label='ssim mean')
ax.set_title('Scatter') # 図のタイトル
ax.set_xlabel('index') # x軸のラベル
ax.set_ylabel('score') # y軸のラベル
ax.grid(True) # グリッド線を表示
plt.legend()
plt.savefig(f'{logging_dir}/histgram-scatter_{metrics_name}.png')
plt.show();
visualize_scores(SCORES)
精度を可視化してみます。
赤の横点線が平均なので CV:LB 比較はこちらを参考にしたら良いと思います。
SSIM だけ見ると分散がかなり激しいので苦手なデータをどう改善していくかが課題になるのでしょうかね

Inference Submit
test_ds = SolafuneSR2023Dataset(test_df, phase='test')
test_dl = DataLoader(test_ds, batch_size=batch_size, shuffle=False)
SAVE_DIR = f'{logging_dir}/submit/'
os.makedirs(SAVE_DIR, exist_ok=True)
FNAMES, PATHS, SCORES, = [], [], []
for image, paths in tqdm(test_dl, leave=False):
image = image.to(device)
with torch.no_grad():
logits = model(image)
preds = torch.round(logits, decimals=0)
preds = preds.cpu().numpy().transpose(0, 2, 3, 1).astype(np.uint8)
# per batch
for i in range(preds.shape[0]):
pred_h = preds[i]
path = paths[i]
PATHS.append(path)
SCORES.append(ssim_score)
FNAME = os.path.basename(path).replace("_low.tif", "_answer.tif")
FNAMES.append(FNAME)
tifffile.imwrite(f'{SAVE_DIR}/{FNAME}', pred_h)
df_preds = pd.DataFrame()
df_preds['file_name'] = FNAMES
df_preds['path'] = PATHS
PATH_PRED = f'{logging_dir}/submit_fold{fold}.csv'
df_preds.to_csv(PATH_PRED, index=False)
print(F'>>> csv: {PATH_PRED}')
display(df_preds.head(8))
提出のための推論を行います。
PATH_ZIP = f'{logging_dir}/submit.zip'
PATH_SUBMITS = f'{SAVE_DIR}*.tif'
print(PATH_ZIP, PATH_SUBMITS)
!zip -j {PATH_ZIP} {PATH_SUBMITS}
提出ファイルの作成です。
提出してみたスコア的には 3/4 のデータで簡単に 0.72 くらいでます。
4Fold 全てとと モデルサイズ次第ではまだまだ上がると思います。
勝つなら 0.8 くらいは出さないと厳しいのかな?
生成物としては以下です。
├── cfg.json # 学習の設定
├── eval # 推論した検証データ
├── fold.csv # fold の情報を加えた DataFrame の情報
├── histgram-scatter_ssim.png # 検証精度の可視化画像
├── last.ckpt # 最終時の学習モデル
├── lightning_logs # Tensorboard のファイル
│ └── version_0
│ ├── events.out.tfevents.1672464114.ss
│ └── hparams.yaml
├── loss.ckpt # SSIM loss が一番低いモデル
├── predict_fold0_ssim0.732467.csv # 検証データのそれぞれの SSIM の値
├── submit # 提出ファイルの画像
├── submit.zip # 提出ファイル
└── submit_fold0.csv # 提出ファイルの情報
全コードや NoteBook は Githubです
長かったですね。お疲れ様です。
Zenn で初めて記事を書きますが予想以上に疲れました。先人方々の素晴らしさに感動します。
少しでも皆さんの参考になればと思います!
最後になりますが、私も宇宙領域で活躍できるモデル開発をしています。
Deep Learnigや CV分野で スパコン、HPC(GPU) を使った開発や特許開拓など,,,
そのようなお仕事お待ちしていると共に同じようにお仕事できるお仲間ができたら嬉しいです。
Discussion