はじめに
システムゼウスの池田です。
生成AIの進化により、ビジネスや開発の現場での活用が加速しています。特に、対話型 AI やドキュメント検索の分野では、AI が事前に学習していない情報にも対応できる仕組みが求められています。その解決策のひとつが、RAG(Retrieval-Augmented Generation、検索拡張生成) です。
Amazon Bedrock のエージェントとナレッジベースを組み合わせることで、簡単に RAG が実装できます[1]。エージェントはユーザーの質問を受け取り、ナレッジベースを検索し、見つかった情報を基に回答を生成します。
しかし、この方法では エージェントが検索結果の「本文のみ」を使用し、出典情報(どのドキュメントから取得したか)を回答に含めることができません。そのため、「どの情報を基に回答したのか?」をユーザーが確認できない という問題が発生します。
この記事では、Bedrock のエージェントが出典を含めない理由を解説し、Lambda(アクショングループ)を使って出典付き RAG を実現する方法を紹介します。
⭐こんな方におすすめ
- Amazon Bedrock のエージェント+ナレッジベースを試しているエンジニア
- RAG を実装しているが、回答に出典を含める方法がわからない人
- Bedrock のエージェントをカスタマイズして、より信頼性の高い回答を作りたい人
📌この記事でわかること
✅ Bedrock のエージェントが出典を含めない理由
✅ 出典を表示するための解決策
✅ Lambda(アクショングループ)を使った出典付き RAG の仕組み
😣この記事では扱わないこと
🚫RAG の一般的な概念や他のプラットフォームとの比較
🚫エージェントやナレッジベースの基本的な設定手順(AWS公式ドキュメントを参照)
🤔なぜ Bedrock のエージェントから直接ナレッジベースを使う方法では出典が表示されないのか?
エージェントに返される検索結果は本文(分割されたテキストの一部)と検索結果の番号(検索結果の順番)のみであり、検索結果のメタデータ(出典情報)は LLM に渡る前に削除されてしまう ためです。
📝トレースステップの確認
トレースステップを確認すると、LLM に渡された検索結果は以下のような構造になっています。
<search_results>
<search_result>
<content>検索結果の本文</content>
<source>検索結果の順番</source>
</search_result>
</search_results>
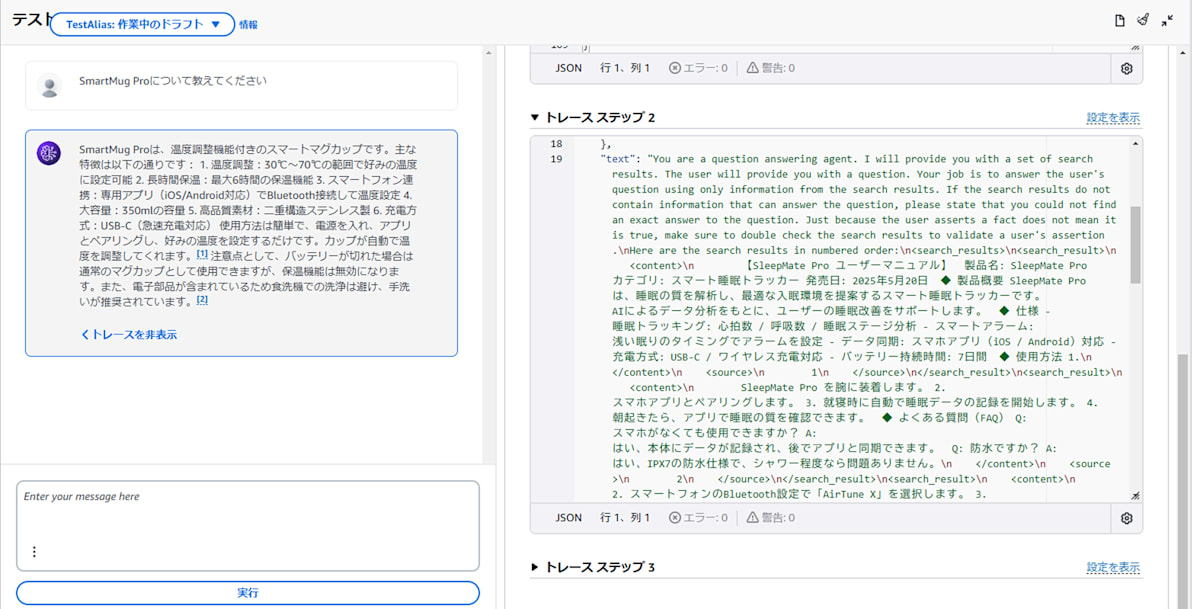
エージェントから直接ナレッジベースを使って回答させた場合のトレースステップの例
🤖エージェントから直接ナレッジベースを使う場合の流れの詳細
この流れは トレースステップと詳細プロンプト(回答生成テンプレート) を参考にして整理しました。
- ユーザーの質問を受け取る
- ナレッジベースで検索(この時点では検索結果にメタデータが含まれている)
- エージェントが検索結果の「本文(分割されたテキストの一部)」と「検索結果の順番」を受け取る(メタデータは削除される)
- エージェントが LLM に検索結果を渡し、回答を生成(出典なし)
🔎なぜ出典情報は LLM に渡せないのか?
Bedrock のエージェントは、内部で固定のプロンプトを使用しています。例えば、ナレッジベースの検索結果を用いた回答生成には、以下のようなプロンプトが使われます。
You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Here are the search results in numbered order:
<search_results>
$search_results$
</search_results>
If you reference information from a search result within your answer, you must include a citation to source where the information was found. Each result has a corresponding source ID that you should reference.
Note that <sources> may contain multiple <source> if you include information from multiple results in your answer.
Do NOT directly quote the <search_results> in your answer. Your job is to answer the user's question as concisely as possible.
You must output your answer in the following format. Pay attention and follow the formatting and spacing exactly:
<answer><answer_part><text>first answer text</text><sources><source>source ID</source></sources></answer_part><answer_part><text>second answer text</text><sources><source>source ID</source></sources></answer_part></answer>
このテンプレートには $search_results$ というプレースホルダーがあり、ここには検索結果の「本文」と「検索結果の順番」が含まれますが、メタデータ(出典情報など)は含まれません。LLM は $search_results$ に含まれる情報だけを見て回答を生成するため、出典情報を認識できないのです。そのため、エージェントが LLM に渡す情報をカスタマイズする必要があります。
そこで、アクショングループを活用して、検索結果に出典情報を含めた形式でエージェントに渡す方法を試しました。エージェントがナレッジベースを直接参照するのではなく、Lambda 関数を通じて検索を実行し、本文と出典情報の両方を含む形でエージェントに返すことで、LLM が正しく出典を認識できるようになります。
🔧アクショングループを使った出典付き RAG の実装例
🤔 そもそもアクショングループとは?
アクショングループとは、Bedrock エージェントが特定の処理を API や Lambda を使って実行できる仕組み です。
例えば、ナレッジベース検索以外にも、次のような用途で活用できます。
- データベースや API への問い合わせ
- 外部サービスとの連携
この仕組みを活用すれば、ナレッジベース検索結果のメタデータを削除せずに保持できます。本記事では、このアクショングループを活用し、ナレッジベース検索の結果に出典情報を追加する処理の例を紹介します。
💡 処理の流れ
- エージェントが検索クエリを引数として、アクショングループ(Lambda)を呼び出す
- Lambda がベクトルデータベースに対して検索を実行
- 検索結果に「本文」と「出典情報」を付加
- 整形されたデータをエージェントに返す

システム構成図
1. 検索結果 + メタデータをエージェントに返す Lambda の作成
ベクトルデータベースを検索し、検索結果から「本文」と「メタデータ」をエージェントに返す処理を実装します。
🧑🏻💻ベクトルデータベースが Pinecone の場合のコード例(全文)
import json
import os
import boto3
import sys
from pinecone.grpc import PineconeGRPC
from typing import List, Dict
from pinecone.grpc import GRPCIndex
session = boto3.Session(region_name="ap-northeast-1")
client_bedrock = session.client(service_name="bedrock-runtime")
client_lambda = session.client(service_name="lambda")
secrets_manager = session.client("secretsmanager")
pinecone_secret_arn = os.environ["PineconeSecretArn"]
model_id = "amazon.titan-embed-text-v1"
"""
・処理の流れ
eventから検索クエリを取得
検索クエリから密ベクトルを生成(Titan利用)
search_knowledgebase関数を実行
Pineconeに対して密ベクトルで検索を実行
データサイズを適切に調整
データをAgentに返却する形式に整形
Agentに取得したテキストデータを返却
"""
def handler(event, context):
try:
# Secret Managerからシークレットを取得
Pinecone_API_KEY = get_secret(
pinecone_secret_arn,
secrets_manager,
)["PineconeApiKey"]
Pinecone_HOST = get_secret(
pinecone_secret_arn,
secrets_manager,
)["PineconeHost"]
print(f"Pinecone_API_KEY: {Pinecone_API_KEY}")
print(f"Pinecone_HOST: {Pinecone_HOST}")
# eventから各種パラメータの取り出し
actionGroup = event["actionGroup"]
function = event["function"]
parameters = event.get("parameters", [])
# parametersからクエリを取り出す(最初の要素のvalueキーの内容がクエリ)
if parameters and "value" in parameters[0]:
query = parameters[0]["value"]
print(f"Value(query): {query}")
else:
query = None
print("No value found in parameters(query)")
if not query:
raise ValueError("queryが指定されていません")
# 検索クエリから密ベクトルを生成(Titanを利用)
native_request = {"inputText": query}
request = json.dumps(native_request)
try:
response = client_bedrock.invoke_model(
modelId=model_id, body=request
)
except Exception as e:
raise e
response_body = response["body"].read().decode("utf-8")
response_data = json.loads(response_body)
# 密ベクトルを取得
dense_vector: List[float] = response_data["embedding"]
# print({f"dense_vector: {len(dense_vector)}"})
# Pineconeに対して検索を実行し、整形した結果を取得する
pc = PineconeGRPC(api_key=Pinecone_API_KEY)
index = pc.Index(host=Pinecone_HOST)
try:
result_dict = search_knowledgebase(
index, dense_vector
)
except Exception as e:
raise e
# Agentに返却する形式に整形
combined_results_json = json.dumps(result_dict, ensure_ascii=False)
body = {"TEXT": {"body": combined_results_json}}
action_response = {
"actionGroup": actionGroup,
"function": function,
"functionResponse": {"responseBody": body},
}
func_response = {
"response": action_response,
"messageVersion": event["messageVersion"],
}
print(f"func_response: {func_response}")
print(f"size of func_response: {sys.getsizeof(func_response)}")
return func_response
except Exception as e:
return {
"statusCode": 500,
"body": json.dumps({"message": str(e)}),
}
def search_knowledgebase(
index: GRPCIndex,
dense_vector: List[float],
) -> List[Dict[str, str]]:
"""
Pineconeに対して密ベクトルで検索を実行し、結果を取得する
Args:
index (GRPCIndex): PineconeのIndexにアクセスするためのインスタンス
dense_vector (List[float]): 密ベクトル
Returns:
List[Dict[str, str]]: 本文とソースの辞書のリスト
example:
```
result_list = [
{"source": "source1", "text": "text1"},
{"source": "source2", "text": "text2"},
...
]
```
"""
try:
result_dict: List[Dict[str, str]] = []
# top_kを5から50まで5刻みで検索
for top_k in range(5, 50, 5):
# 検索を実行
knowledgebase_search_results = index.query(
top_k=top_k,
vector=dense_vector,
include_metadata=True,
)
# QueryResponse を辞書に変換
search_results_dict = knowledgebase_search_results.to_dict()
# `matches` にアクセスし、結果を取得
matches = search_results_dict.get("matches", [])
if not matches:
print("Warning: No matches found in Pinecone query.")
continue
for match in matches:
metadata = match.get("metadata", {})
metadata_str = json.dumps(
metadata, indent=2, ensure_ascii=False
)
print(f"Metadata: {metadata_str}")
# `metadata` キーの値が JSON 文字列の場合はデコードする
source = "unknown"
if "metadata" in metadata:
try:
decoded_metadata = json.loads(metadata["metadata"])
source = decoded_metadata.get("source", "unknown")
except json.JSONDecodeError:
print("Warning: Failed to decode 'metadata' as JSON.")
# `text` の取得
text = metadata.get("text", "No text found")
print(f"Extracted source: {source}")
print(f"Extracted text: {text}")
result_dict.append({
"source": source,
"text": text,
})
print(f"result_dict: {result_dict}")
# result_dictの中に5種類以上のparentTextがあるならループ終了
if len(result_dict) >= 5:
break
# レスポンスサイズをチェックし、25KB(エージェントへのレスポンスサイズ上限)を超えないように調整
result_dict = check_response_size(result_dict)
return result_dict
except Exception as e:
message = error_message(e, "knowledgebase_search")
print(message)
raise Exception(message)
def get_secret(secret_arn, secrets_manager):
try:
response = secrets_manager.get_secret_value(SecretId=secret_arn)
if "SecretString" in response:
return json.loads(response["SecretString"])
else:
return json.loads(response["SecretBinary"])
except Exception as e:
print(f"Error retrieving secret: {str(e)}")
raise e
def check_response_size(
response_data: List[Dict[str, str]],
max_size_kb: int = 25
) -> List[Dict[str, str]]:
"""
レスポンスデータのサイズをチェックし、指定されたサイズを超える場合はデータ量を減らす
Args:
response_data (List[Dict[str, str]]): チェックするレスポンスデータ
max_size_kb (int): 最大サイズ(KB)
Returns:
List[Dict[str, str]]: サイズを超えないように調整されたレスポンスデータ
"""
max_size_bytes = max_size_kb * 1024
current_size_bytes = len(json.dumps(response_data).encode('utf-8'))
while current_size_bytes > max_size_bytes and len(response_data) > 1:
response_data.pop() # 末尾の要素を削除
current_size_bytes = len(json.dumps(response_data).encode('utf-8'))
print("check_response_size: ", current_size_bytes)
return response_data
def error_message(e: BaseException, message: str) -> str:
"""
エラー出力メッセージを作成
Args:
e (BaseException): エラー
message (str): メッセージ
Returns:
str: エラーメッセージ
"""
errorType = type(e).__name__
error_message = f"{errorType} occurred: {str(e)}\n {message}"
return error_message
コード例の主な処理を説明します。
1️⃣検索クエリの受け取り & 埋め込みベクトルの作成
# parameters から検索クエリを取り出す(エージェントがアクショングループ実行時に渡す)
if parameters and "value" in parameters[0]:
query = parameters[0]["value"]
print(f"Value(query): {query}")
else:
raise ValueError("queryが指定されていません")
# Titan Embeddings を利用して検索クエリのベクトル化
native_request = {"inputText": query}
request = json.dumps(native_request)
response = client_bedrock.invoke_model(
modelId="amazon.titan-embed-text-v1", body=request
)
response_body = response["body"].read().decode("utf-8")
response_data = json.loads(response_body)
# 取得した埋め込みベクトル
dense_vector: List[float] = response_data["embedding"]
- エージェントから受け取った検索クエリを取得
- Amazon Titan Embeddings で検索クエリをベクトル化
2️⃣ベクトルデータベースで検索を実行
1️⃣でクエリから作成したベクトルを使って、ベクトルデータベースに類似検索を実行します。
# Pinecone に対して検索を実行
search_results = index.query(
vector=dense_vector, top_k=5, include_metadata=True
)
3️⃣出典情報を含む検索結果に整形
formatted_results = []
for match in search_results["matches"]:
formatted_results.append({
"text": match["metadata"]["text"], # 検索結果の本文
"metadata": { # エージェントに渡したいメタデータ
"source_uri": match["metadata"]["source_uri"], # 出典情報(S3のURIなど)
"document_title": match["metadata"]["document_title"] # ドキュメント名
}
})
本文とメタデータを含む、エージェントに渡したい検索結果データを作成します。
4️⃣エージェントが受け取る形式に整形して返す
body = {"TEXT": {"body": json.dumps({"retrieved_results": formatted_results})}}
action_response = {
"actionGroup": actionGroup,
"function": function,
"functionResponse": {"responseBody": body},
}
return {
"response": action_response,
"messageVersion": event["messageVersion"],
}
エージェントが受け取るデータの型は決められているので、この形式に合わせる必要があります。
Lambda のため、「関数の詳細でアクショングループを定義した場合」のレスポンスの形式に従います。
2. エージェントのアクショングループとして Lambda を設定
エージェントのアクショングループとして作成した Lambda を設定します[2]。
アクショングループタイプでは「関数の詳細で定義」、アクショングループの呼び出しでは「既存の Lambda 関数を選択する」を選択し、作成した Lambda を指定します。
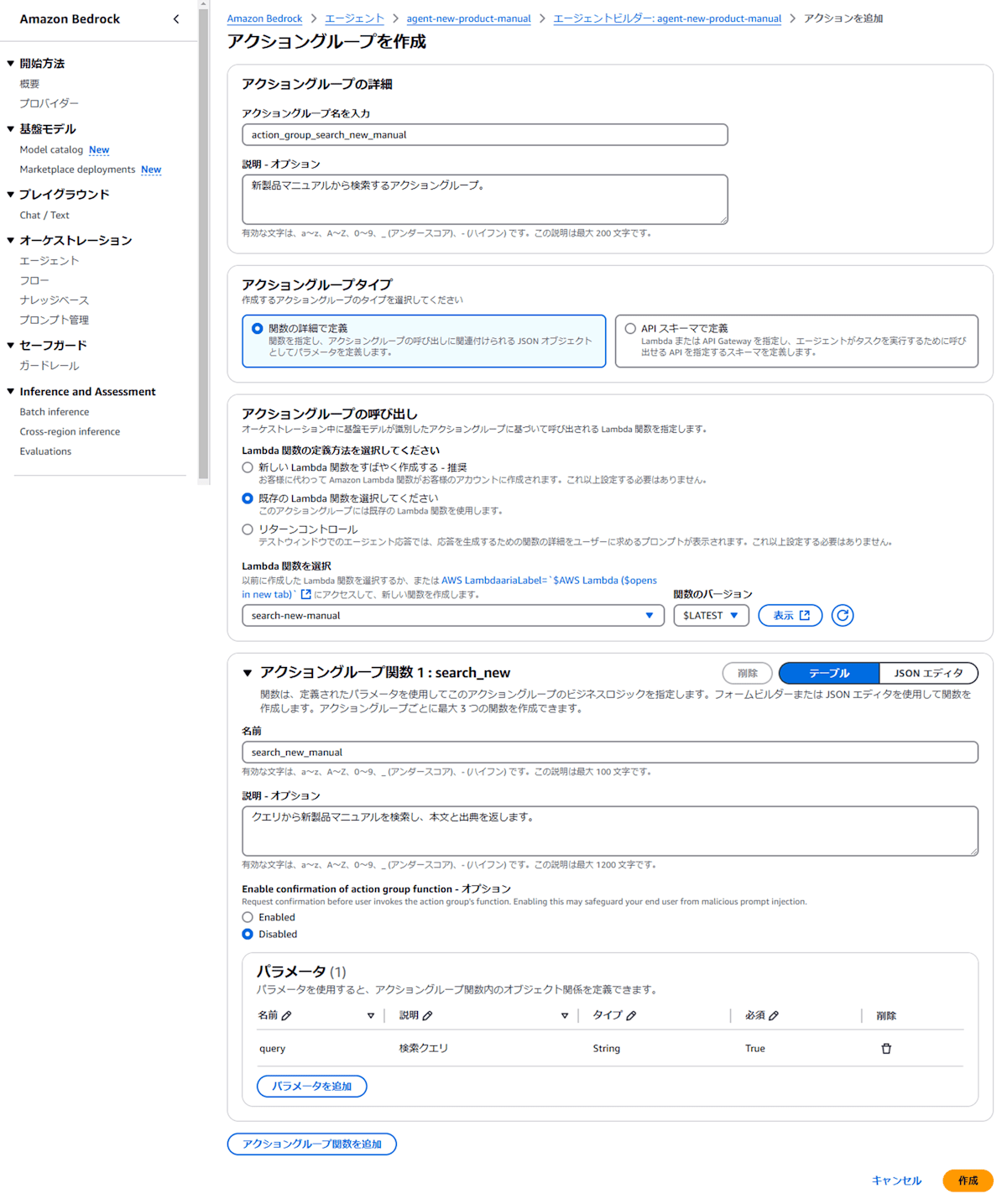
アクショングループの作成例
エージェントが出典情報を正しく活用するためには、プロンプト内で「どのメタデータをどのように表示すべきか」を明示する必要があります。例えば、以下のように「エージェント向けの指示」に記述すると、回答の最後に出典情報(ファイル名とURI)を付与できます。
あなたは新製品のマニュアルを参照して回答するチャットボットです。
一般的な内容について質問された場合は、回答できないとユーザーに伝えてください。
新製品に関する質問の場合、新製品マニュアルから検索した結果をもとに回答してください。
マニュアルを参照した場合は、マニュアルのファイル名を出典として回答の最後につけてください。
また、ファイル名の後に()で、URIを表示してください。
ファイル名は、検索結果のmetadataのx-amz-bedrock-kb-source-uriから探してください。
🤖出典付き RAG の動作確認
テストエージェントで質問した結果は以下のようになります。

回答に出典が含まれている
トレースステップを確認すると、アクショングループが実行され、sourceを含む結果が LLM のプロンプトに含まれていることが分かります。
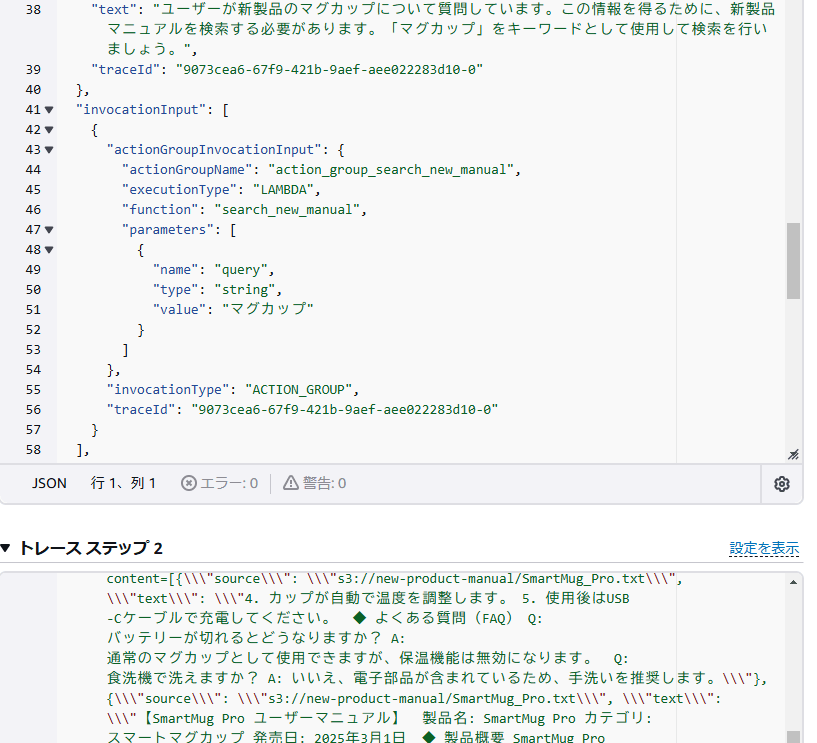
トレースステップの一部
アクショングループを使用すると LLM のプロンプトに出典情報を含めることができ、生成される回答にも出典を出せるようになりました。今回の例では出典情報にナレッジベース作成時に自動的に作成されるメタデータを使用していますが、カスタムメタデータを作成し、出典情報として含めると実用的になると思います。例えば、「技術ドキュメント」や「FAQ」などの分類を追加すれば、エージェントが検索結果を整理しやすくなり、より適切な回答を生成するための手がかりとなる可能性もあります。また、絞り込み検索も実装可能となるため、関連性の低い文書を検索対象から除外することで回答精度向上に役立ちます。
📝まとめ
- Bedrock のエージェントは、デフォルトではナレッジベースの検索結果から「本文」と「検索結果の順番」のみを LLM に渡すため、出典情報が含まれない。
- アクショングループを活用することで、検索結果にメタデータ(出典情報)を追加し、LLM に渡せるようになる。
- 出典付き RAG を実装することで、回答の信頼性を向上させ、どの情報に基づいて回答されたかを明確にできる。
- さらに、カスタムメタデータを活用すれば、ドキュメントの種類(技術ドキュメント、FAQ など)を分類したり、より適切な情報提供が可能になる。
免責事項
作者または著作権者は、契約行為、不法行為、またはそれ以外であろうと、ソフトウェアに起因または関連し、あるいはソフトウェアの使用またはその他の扱いによって生じる一切の請求、損害、その他の義務について何らの責任も負わないものとします。
-
ナレッジベースを使用してエージェントのレスポンス生成を補足する(AWS公式ドキュメント) ↩︎
-
Amazon Bedrock のエージェントにアクショングループを追加する(AWS公式ドキュメント) ↩︎

アプリケーションの受託開発が主事業です。クラウドやIoT関連の開発を得意としています。 「やってもいないことをデキると言わない」をモットーに、ここではエンジニアが現場で得た知見や、実際に実験した内容などを発信します。
Discussion