はじめに
システムゼウスの池田です。
近年、生成AI の活用が広がり、様々な分野で導入が進んでいます。AI がテキストを生成したり、会話に応じたりする技術は急速に発展していますが、事前に学習したデータしか持たない ため、新しい情報を取り入れるのが難しいという課題もあります。
この問題を解決する手法のひとつが、AI が必要に応じて情報を検索し、その結果をもとに回答を生成する技術 です。この仕組みは、RAG(Retrieval-Augmented Generation、検索拡張生成)と呼ばれ、より柔軟で信頼性の高い AI を実現するために注目されています。
本記事では、Amazon Bedrock Agents と Pinecone を組み合わせて、RAG を構築する方法を紹介します。
本記事の内容
- Amazon Bedrock Agent × Pinecone を使った RAG の構築手順
- Pinecone を利用したナレッジベースの構築手順
- Agent がナレッジベースを検索して回答を生成する仕組み
⭐こんな方におすすめ
- Amazon Bedrock の Knowledge Bases や Agents を試してみたい人
- Pinecone を活用したナレッジベースの構築に興味がある人
💡 Amazon Bedrock の Knowledge Bases と Agents とは
Amazon Bedrock の Knowledge Bases とは、RAG で使用するナレッジベースを簡単に作成できる機能です。ナレッジベースとは、AI(LLM)の検索対象となる情報の蓄積場所のことです。ナレッジベースを用いることで、専門知識等のAI が知らないであろう知識を補完することや、AI に正確な情報を提供することができます。ナレッジベースをAgents(エージェント)と組み合わせることで、AI がユーザーの質問に応じてナレッジベースを検索し、適切な回答を生成できます。
本記事では、Pinecone をデータストアとして利用したナレッジベースを構築 します。 Pinecone はベクトル検索を行うデータベースであり、Amazon OpenSearch Serverless などと比べて低コストで運用できるため、今回のハンズオンでは Pinecone を採用しました。
🗂️ナレッジベースの作成
Pinecone と AWS コンソールを使用します。
1. 文書の配置
ナレッジベースとして使用したい文書をS3に配置します。S3 に任意の名前でバケットを作成し、txtファイルをアップロードします。
サンプルとして3つの架空の新製品マニュアルを用意しました。

新製品マニュアルのサンプル
【AirTune X ユーザーマニュアル】
製品名: AirTune X
カテゴリ: ワイヤレスイヤホン
発売日: 2025年4月10日
◆ 製品概要
AirTune X は、AIが自動で音質を調整する次世代ワイヤレスイヤホンです。
環境音に合わせてリアルタイムで最適なイコライザー設定を行います。
◆ 仕様
- 接続方式: Bluetooth 5.3
- ノイズキャンセリング: アクティブノイズキャンセリング(ANC)搭載
- バッテリー持続時間: 10時間(ケース併用で最大30時間)
- 充電方式: ワイヤレス充電 / USB-C
- 防水性能: IPX5
◆ 使用方法
1. ケースからイヤホンを取り出し、ペアリングモードにします。
2. スマートフォンのBluetooth設定で「AirTune X」を選択します。
3. AIが環境音を分析し、自動で音質を調整します。
4. 音楽を楽しんだ後、ケースに収納すると自動で充電されます。
◆ よくある質問(FAQ)
Q: 片方だけ使うことはできますか?
A: はい、左右どちらか片方のみでも使用可能です。
Q: AI音質調整をオフにできますか?
A: はい、専用アプリで手動のイコライザー設定に切り替え可能です。
【SleepMate Pro ユーザーマニュアル】
製品名: SleepMate Pro
カテゴリ: スマート睡眠トラッカー
発売日: 2025年5月20日
◆ 製品概要
SleepMate Pro は、睡眠の質を解析し、最適な入眠環境を提案するスマート睡眠トラッカーです。
AIによるデータ分析をもとに、ユーザーの睡眠改善をサポートします。
◆ 仕様
- 睡眠トラッキング: 心拍数 / 呼吸数 / 睡眠ステージ分析
- スマートアラーム: 浅い眠りのタイミングでアラームを設定
- データ同期: スマホアプリ(iOS / Android)対応
- 充電方式: USB-C / ワイヤレス充電対応
- バッテリー持続時間: 7日間
◆ 使用方法
1. SleepMate Pro を腕に装着します。
2. スマホアプリとペアリングします。
3. 就寝時に自動で睡眠データの記録を開始します。
4. 朝起きたら、アプリで睡眠の質を確認できます。
◆ よくある質問(FAQ)
Q: スマホがなくても使用できますか?
A: はい、本体にデータが記録され、後でアプリと同期できます。
Q: 防水ですか?
A: はい、IPX7の防水仕様で、シャワー程度なら問題ありません。
【SmartMug Pro ユーザーマニュアル】
製品名: SmartMug Pro
カテゴリ: スマートマグカップ
発売日: 2025年3月1日
◆ 製品概要
SmartMug Pro は、温度調整機能付きのスマートマグカップです。
専用アプリを使って好みの温度に設定でき、最大6時間保温できます。
◆ 仕様
- 温度範囲: 30℃〜70℃
- バッテリー持続時間: 最大6時間(フル充電時)
- 充電方式: USB-C(急速充電対応)
- 容量: 350ml
- 素材: 二重構造ステンレス
◆ 使用方法
1. SmartMug Pro の電源を入れます。
2. スマホアプリ(iOS / Android)と Bluetooth でペアリングします。
3. アプリで好みの温度を設定します。
4. カップが自動で温度を調整します。
5. 使用後はUSB-Cケーブルで充電してください。
◆ よくある質問(FAQ)
Q: バッテリーが切れるとどうなりますか?
A: 通常のマグカップとして使用できますが、保温機能は無効になります。
Q: 食洗機で洗えますか?
A: いいえ、電子部品が含まれているため、手洗いを推奨します。
2. ベクトルデータベースの作成
Pineconeでベクトルデータベースを作成します。
アカウントを作成し、ログインしたのち、任意の名前でプロジェクト、インデックスを作成します。プロジェクト作成時にAPIキーが表示されるため、メモ帳などに控えておきます。
インデックスの設定では、 Dimensions を 1,536 [1]、Metric を dotproductにします。

インデックスの設定例
最後に、作成されたインデックスのHOSTのURLをコピーしておきます。

四角で囲われた部分がHOSTのURL
3. シークレットの作成
2.で作成したプロジェクトのAPIキーを保存するシークレットを作成します。
Secret Managerで「新しいシークレットを保存する」を選択し、シークレットのタイプは「その他」を選択します。キー/値のペアにはAPIキーを入力します(画像を参照)。任意の名前と説明を入力し、シークレットの作成を完了します。
最後に、作成したシークレットのARNをコピーしてメモ帳等に控えておきます。

シークレットの例
4. Knowledge Base の作成
コンソールで Amazon Bedrock を開き、左側のサイドバーから「オーケストレーション」の中の「ナレッジベース」を選択します。
その後、「ナレッジベースを作成」→「Knowledge Base with vector store」を選択し、新規作成します。ナレッジベースの詳細では、任意の名前でナレッジベース名を付け、データソースとしてAmazon S3を選択します。

データソースの設定では、任意の名前でデータソース名を付け、S3のURIには「S3を参照」を選択したのち、1.で文書を格納した場所を指定します。
埋め込みモデルには Titan Embeddings G1 - Textを選択します(アクセス権がない場合は基盤モデルからアクセスをリクエストしてください)。
ベクトルデータベースでは「作成したベクトルストアを選択」→「Pinecone」を選択し、規約に同意の元、チェックボックスにチェックを入れます。
エンドポイントURLには、2.で作成したPineconeのインデックス画面にある、HOSTのURLを入力します。
認証情報シークレットARNには、3.で作成したシークレットのARNを入力します。
メタデータフィールドマッピングには以下を指定します。
| 項目 | 指定する値 |
|---|---|
| テキストフィールド名 | text |
| Bedrockマネージドメタデータフィールド名 | metadata |
テキストフィールドは、文書をベクトルデータ化した場合のチャンク(文書が分割されたもの)が格納されるフィールドです。Bedrockマネージドメタデータフィールドは、Bedrock側で作成されたメタデータが格納されるフィールドです(文書更新があった場合の識別用のメタデータ等)。

ナレッジベースの設定例
確認画面で設定が正しいことを確認し、「ナレッジベースを作成」をクリックするとナレッジベースの作成が完了します。
5. ナレッジベースの同期
ナレッジベースを同期し、Pinecone にデータを格納します。
データソースのチェックボックスを選択し、上側の同期ボタンをクリックします。

同期時の選択例
同期が完了すると Pinecone にベクトルデータが格納されるため、再読み込みして確認します。
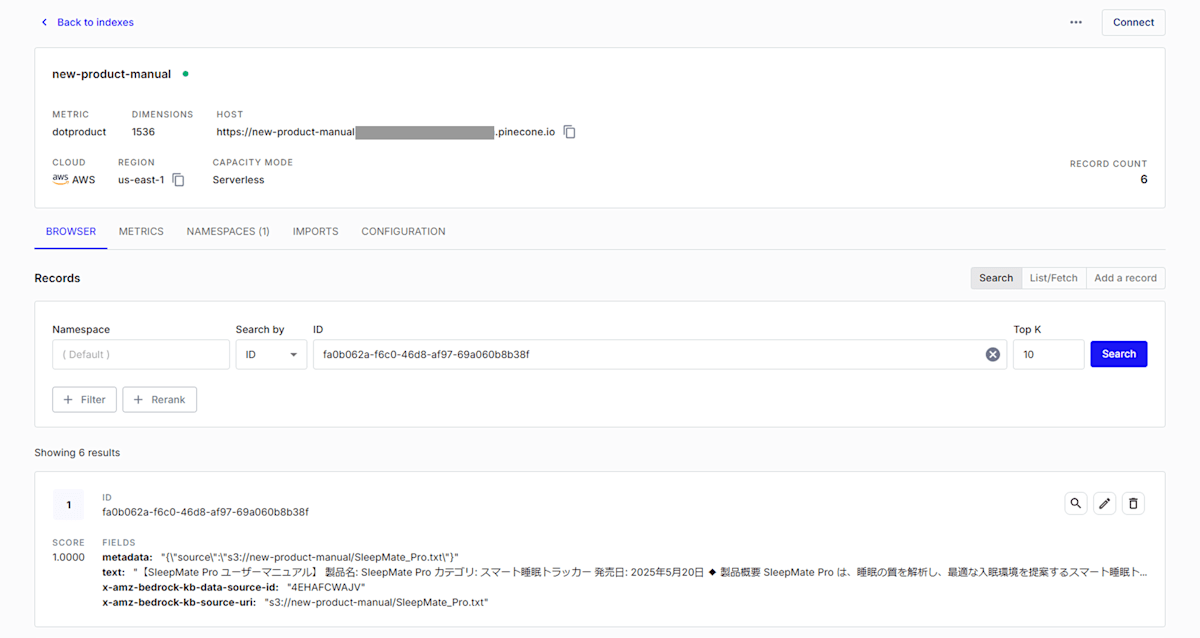
Pineconeにデータが格納される
レコード1つずつに4.で指定したフィールドに対して値が格納されていることが確認できます。
Valuesには埋め込みモデルが生成した密ベクトル[2]が格納されています。
textには密ベクトルのもとになったチャンク、metadataにはsourceとして対応する文書の場所が格納されています。
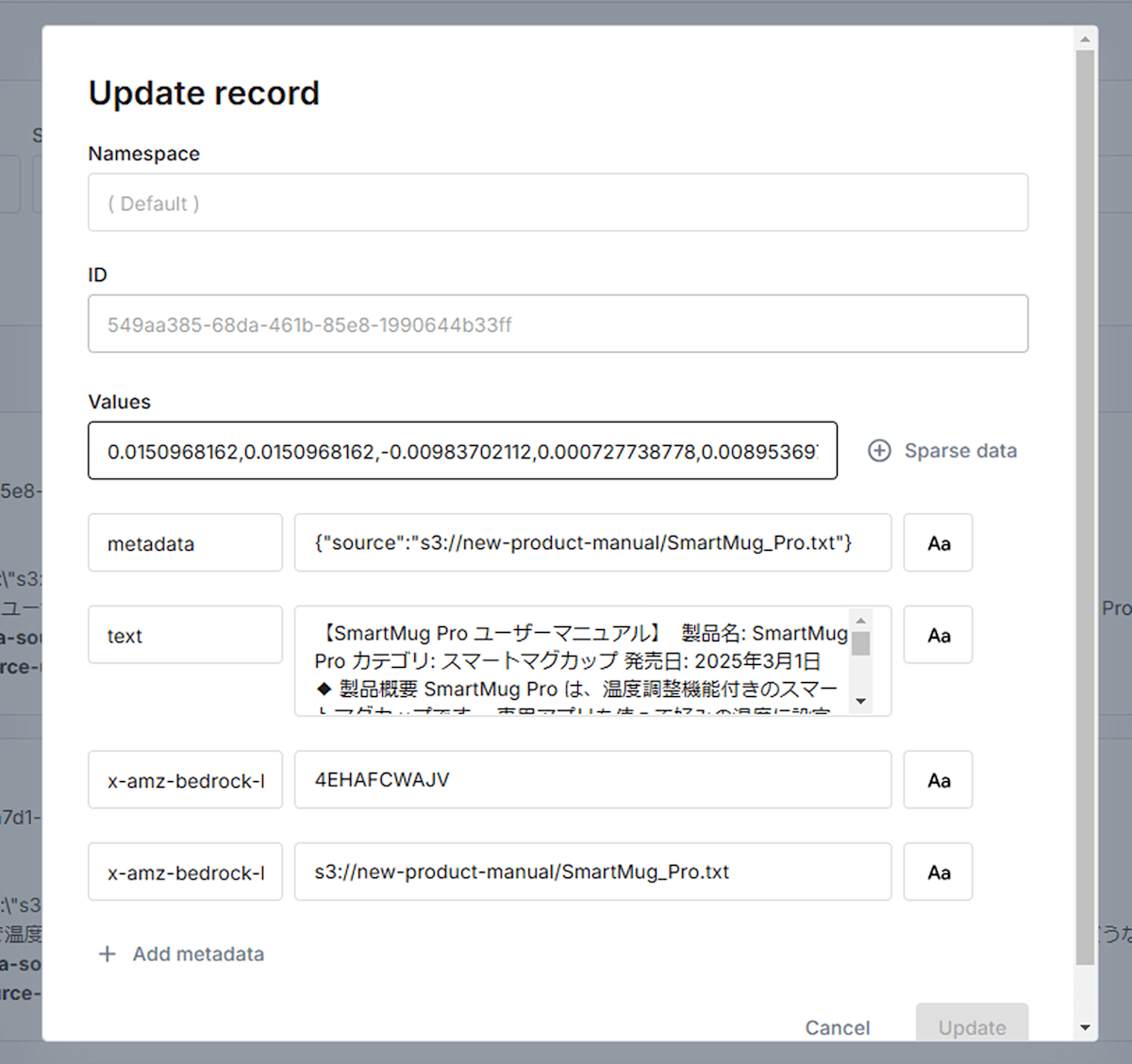
任意のレコードを選択すると表示される
🧪ナレッジベースをテスト
ナレッジベースの画面で、右側に表示されている「ナレッジベースをテスト」でS3に配置した文書に関する質問をして正しく回答できるか確認します。
「モデルを選択」で任意のモデルを選択し、チャットの入力欄に質問を入力して実行します(基盤モデルが選択できない場合は基盤モデルからアクセスをリクエストしてください)。

回答の「ソースの詳細を表示」を選択すると、参考にした文書の詳細が表示されます。
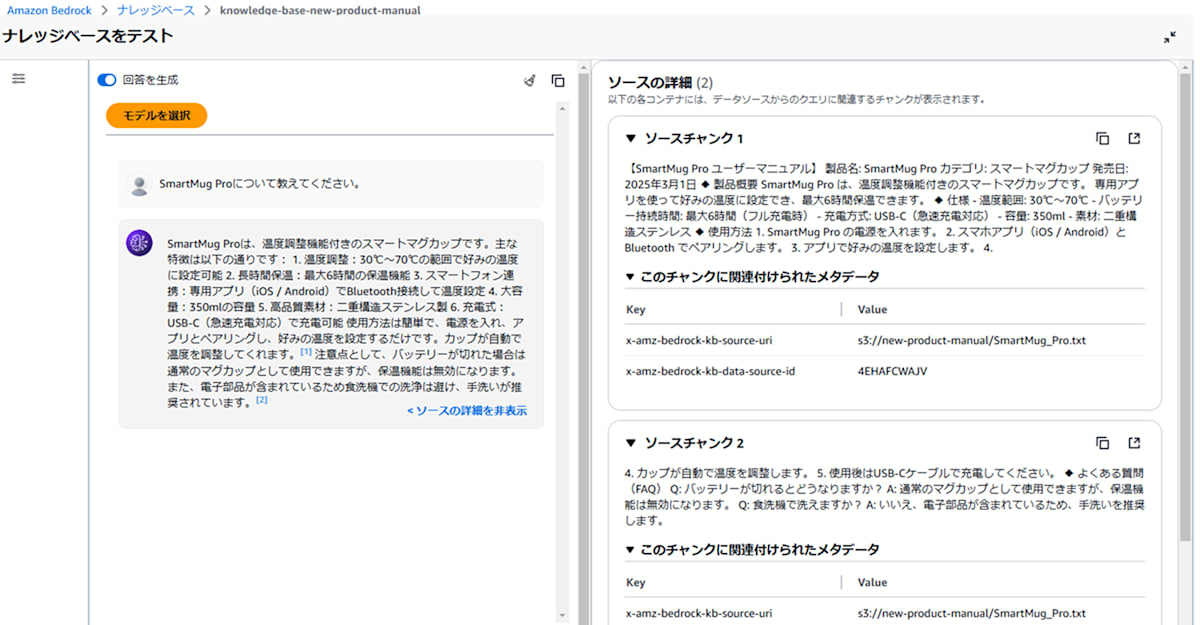
回答のもととなったチャンクとチャンクのメタデータ
今回は独自のメタデータを作成していないため、bedrockが作成したメタデータのみ格納されています。
🤖ナレッジベースをエージェントで使用する
作成したナレッジベースをエージェントで使えるようにします。
1. エージェントの作成
コンソールで Amazon Bedrock を開き、左側のサイドバーから「オーケストレーション」の中の「エージェント」を選択します。「エージェントを作成」を選択して、エージェントを任意の名前で新規作成し、「保存」をクリックして保存します。

エージェントの作成例
2. ナレッジベースの追加
右上の「エージェントビルダーで編集」を選択し、エージェントの編集画面に入ります。
「ナレッジベース」の上側の「Add」をクリックし、追加するナレッジベースを指定します。
先ほど作成したナレッジベースを選択し、エージェント向けの指示を入力し、「Add」をクリックして追加を完了します。
エージェント向けの指示では、ナレッジベースの情報をもとに回答する場合は出典を表示するように指示しておきます。

3. エージェントへの指示の追加
最後に、「エージェントの詳細」の「エージェント向けの指示」に指示を追加します。
ナレッジベースの情報を参照した場合、出典を表示するように指示します。
あなたは新製品のマニュアルを参照して回答するチャットボットです。
一般的な内容について質問された場合は、回答できないとユーザーに伝えてください。
マニュアルを参照した場合は、マニュアルのファイル名を出典として回答の最後につけてください。
編集が完了したら、「保存して終了」をクリックします。

🧪エージェントをテスト
エージェントの概要画面の右側にある「テスト」を使用してエージェントがナレッジベースを使用できるかを確認します。
「テスト」にある「準備」をクリックし、テスト環境を最新の状態にします。
エージェントに、S3に配置した文書に関する質問をして、正しい回答が返ってくることを確認します。

回答の内容は正しいものの、エージェントへの指示に含めていた出典情報が表示されませんでした。
😈課題
Amazon Bedrock の Knowledge Bases と Agents を使用すると簡単に RAG が実装できました。しかし、課題として、エージェントが回答の出典を表示しない という問題が発生しました。
🤔なぜ出典が必要なのか?
- 文書が大量にある場合、どの情報を参照して回答を生成したのか分からない
- 似た内容の文書が複数あると、どの文書が元になっているか特定しづらい
例えば、出典が明示されないと、明示される場合と比較して一次情報を調べにくく、回答の信憑性が低くなります。
😣なぜ出典が出せなかったのか?
Agent の仕様によるものです。
実際に回答の最後にある 「トレースを表示」をクリックし、エージェントの動きを見てみましょう。
トレースステップを見ると、エージェントに出典を表示するよう指示していたにもかかわらず、「エージェント向けの指示」が反映されていない ことが分かります。
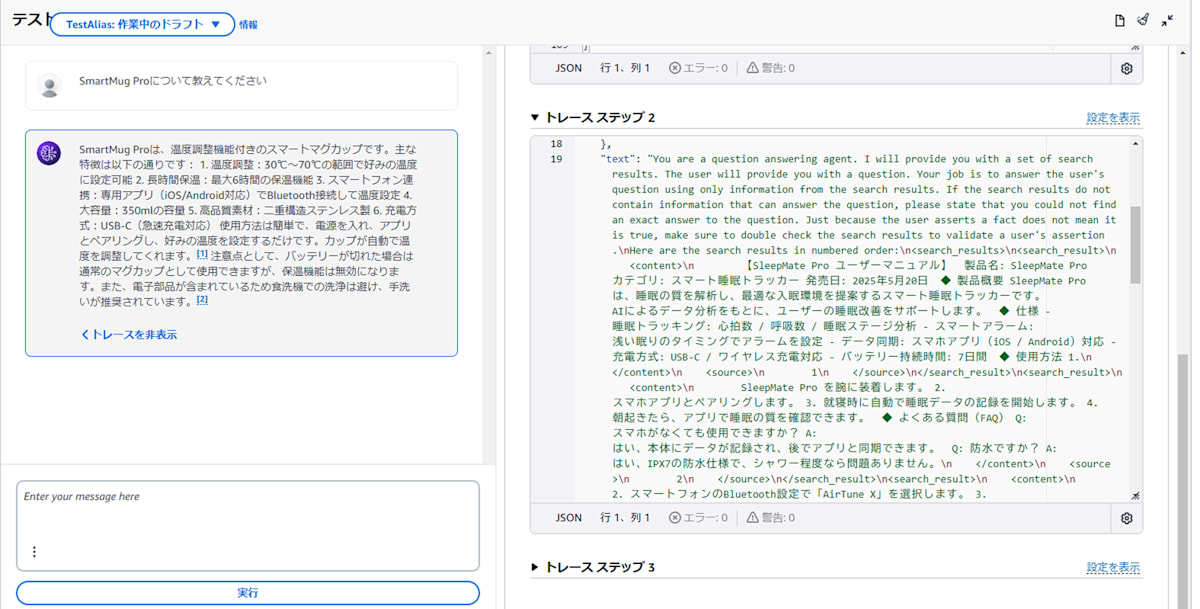
エージェント向けの指示がトレース内のプロンプトに含まれるべきだが、含まれていない
これは、エージェントがナレッジベースを単なるデータストアとして扱い、検索結果の本文のみを LLM に渡している ためです。
本来であれば、検索結果には メタデータ(タイトルやURL)も含まれるはずですが、エージェントにナレッジベースを直接繋いだ場合、それを無視してしまう仕様になっています。つまり、ナレッジベースの検索結果がエージェントの処理を介さず、そのままLLMに送られているため、エージェント向けの指示が適用されず、出典なしの回答になってしまうという問題が発生しています。
📝まとめ
Amazon Bedrock の Knowledge Bases と Agents を使用すると、簡単に RAG が実装できました。しかし、エージェントに直接ナレッジベースから回答させた場合、仕様により出典情報を回答に含めることができませんでした。文書が大量になった場合や、似た文書が多い場合、どの文書・文章をもとに回答しているのかを特定するのが難しくなります。
この問題を解決するために、次回の記事では アクショングループを活用した出典情報の表示 を実装してみます。具体的には、検索結果のメタデータ(タイトル・URL)を取得し、エージェントに「出典付きの回答を生成する」よう指示する方法を試します。興味のある方は、ぜひ続編もチェックしてみてください。
免責事項
作者または著作権者は、契約行為、不法行為、またはそれ以外であろうと、ソフトウェアに起因または関連し、あるいはソフトウェアの使用またはその他の扱いによって生じる一切の請求、損害、その他の義務について何らの責任も負わないものとします。

アプリケーションの受託開発が主事業です。クラウドやIoT関連の開発を得意としています。 「やってもいないことをデキると言わない」をモットーに、ここではエンジニアが現場で得た知見や、実際に実験した内容などを発信します。
Discussion