はじめに
システムゼウスの吉田です。
今回は LLM の自動評価をしたい方向けに、Amazon Bedrock の LLM as a Judge によるモデル評価(プレビュー)を簡単に体験してみます。
モデル評価ジョブの作成
前提条件
Anthropic Claude 3.5 Sonnet v1 のモデルアクセスをリクエスト済みであること。モデルアクセスのリクエスト手順は以下を参考にしてください。
手順
-
評価用データセットと評価結果を保存するための S3 バケットを作成
設定値はデフォルトのままで OK です。私はバケット名をevaluation-job-datasetにしています。 -
作成した S3 バケットに
input,outputフォルダを作成し、以下の JSON Lines ファイルをinputフォルダに保存。フォーマットは公式ドキュメントを参考にしています。{"prompt": "日本の首都は", "referenceResponse": "東京", "category": "Capital"} {"prompt": "日本料理と言えば", "referenceResponse": "寿司", "category": "Food"} {"prompt": "アメリカの首都は", "referenceResponse": "ワシントンD.C.", "category": "Capital"}ここまでの手順で S3 バケットの中身が以下のようになったことを確認してください。
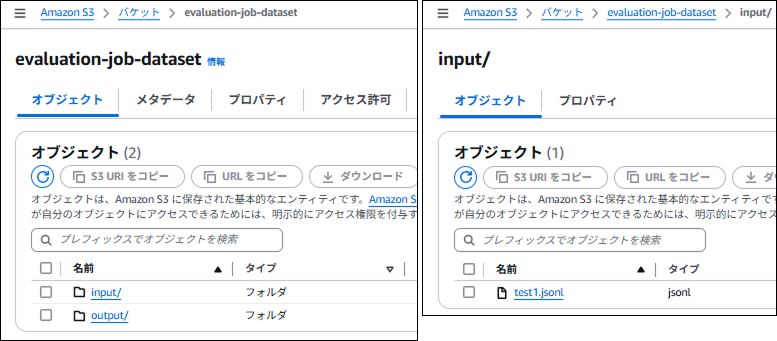
-
S3 バケットのアクセス許可から CORS 設定を追加
CORS 設定は公式ドキュメントを参考にしています。[ { "AllowedHeaders": ["*"], "AllowedMethods": ["GET", "PUT", "POST", "DELETE"], "AllowedOrigins": ["*"], "ExposeHeaders": ["Access-Control-Allow-Origin"] } ]CORS の説明は以下を参考にしてください:
以下の画像のようになっていれば OK です。

-
Amazon Bedrock の Evaluations を開き、Create ボタンから Model as a judge を選択
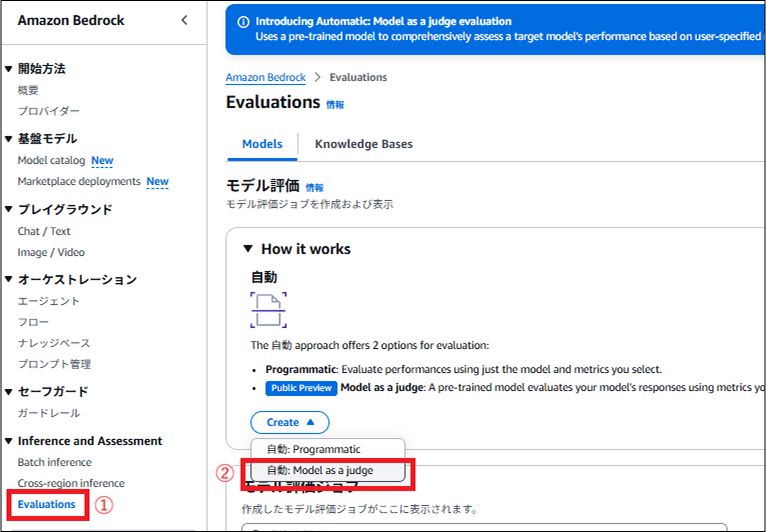
-
評価名に任意の評価名を入力し、"モデルを選択"から、Anthropic の Claude 3.5 Sonnet v1 を選択
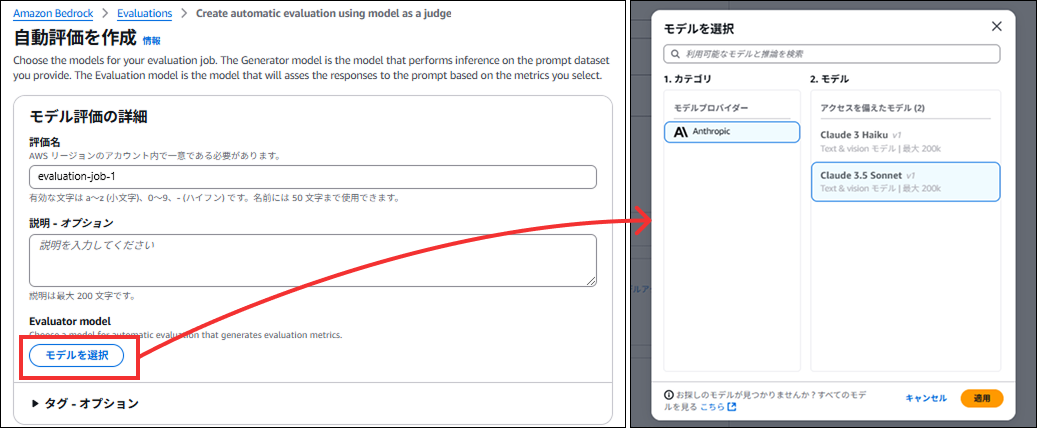
-
下にスクロールして、前手順と同様に、Generator model の"モデルを選択"から Anthropic の Claude 3.5 Sonnet v1 を選択

-
下にスクロールして、メトリクスをすべて選択

-
データセットや IAM ロールを設定し、"作成"ボタンを押下
- プロンプトデータセットの S3URI は input フォルダに入れた
.jsonlファイルを指定 - 評価結果の S3URI は output フォルダを指定
- IAM ロールは Create and use a new service role を選択
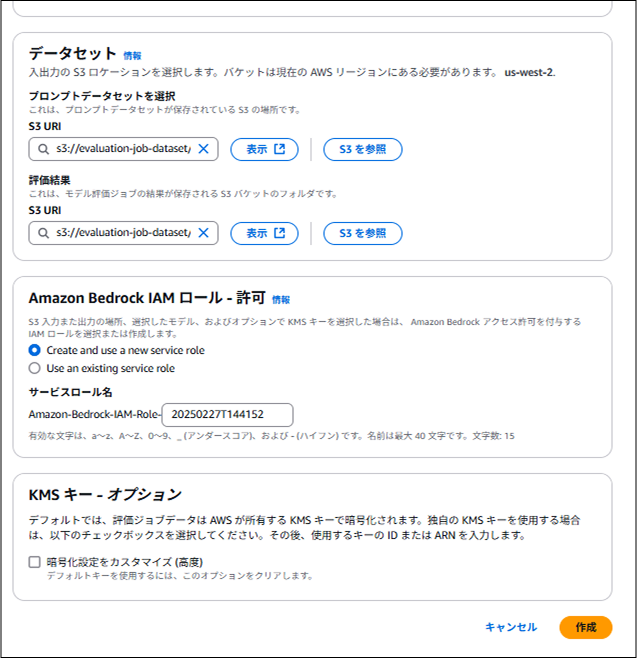
- プロンプトデータセットの S3URI は input フォルダに入れた
-
モデル評価ジョブに今作成したジョブが追加されたことを確認
ステータスが完了済みになると、評価結果を確認できます。(※ステータスが完了済みになるまで約 30 分ほどかかります。)

評価結果の確認方法
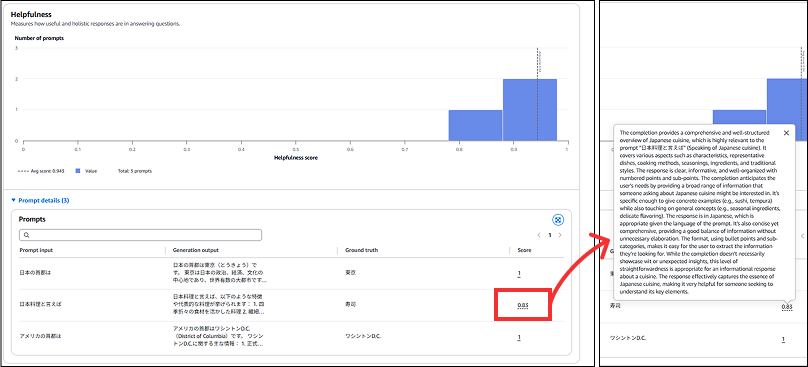
ステータスが完了済みになると、以下のような評価の概要を閲覧できます。

下にスクロールすると、各メトリクスの評価結果を確認できます。Prompt details を開き Score を押下すると、LLM がその Score にした理由を閲覧できます。
まとめ
LLM as a Judge のモデル評価ジョブをうまく使えば精度確認のサイクルが早くなり、精度向上の効率が上がりそうだなと感じました。いつか Bedrock の LLM as a Judge 以外でもモデルの自動評価を試してみたいです。

アプリケーションの受託開発が主事業です。クラウドやIoT関連の開発を得意としています。 「やってもいないことをデキると言わない」をモットーに、ここではエンジニアが現場で得た知見や、実際に実験した内容などを発信します。
Discussion