C++ 高速日本語係り受け解析 J.DepP(ジョニーデップ)の Python binding のメモ
背景
LLM データセット(コーパス)構築のために, 多量の日本語データ(TB 以上)をフィルタリングしたい... 係り受け解析までしてある程度構文チェックなど.
KNP や GiNZA で一応係り受け解析できるけど遅すぎ...
人類史上最速(たぶん)の日本語係り受け解析 J.DepP がありました!
ありがとう吉永先生.
J.DepP を Python 対応しました!(ついでに Windows でも動くようにポータブル化など)
ソースコードめちゃ読みづらかった & posix 前提コードで辛かったよ...
でも頑張ってポータブル化して, Python binding 作りました!
インストール
pip で入るよ.
$ python -m pip install jdepp
Windows(ARM も!), Linux(ARM も!), macOS も全部バイナリあるからコンパイル不要で動く!
repo はこちら
使う
pip では(現状は)辞書まではインストールされないため, 別途辞書のダウンロード(or 学習)が必要です. とりま J.DepP デフォ設定で使われる KNBC https://hayashibe.jp/tr/corpus/knbc をコンパイルしましたので, こちらを使いましょう.
(ライセンスは KNBC が BSD なので, compile 済み辞書も BSD にしました)
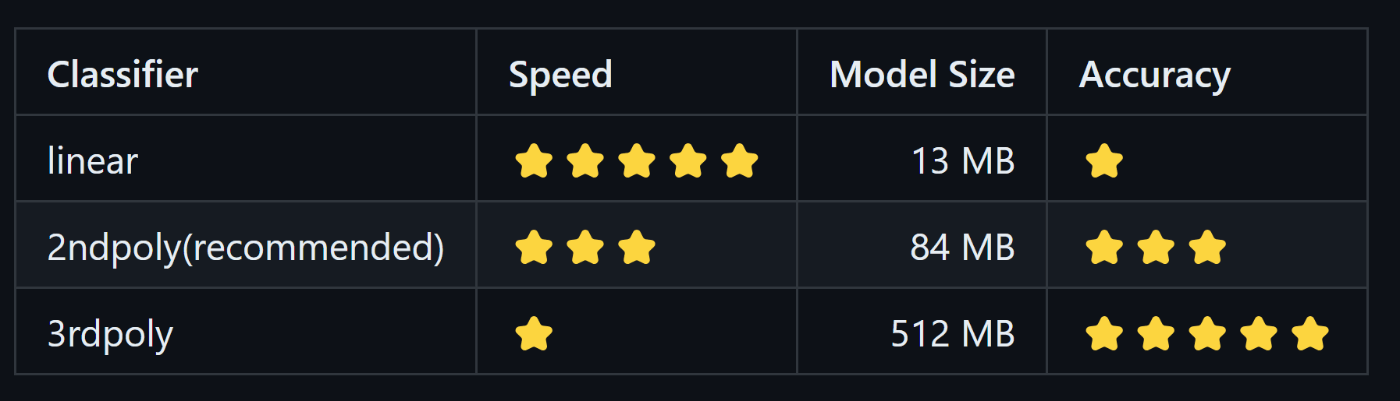
linear だと 吾輩は猫である。名前はまだない。 がうまく文節分解できませんでした.
2ndpoly(推奨) or 3rdpoly 利用しましょう.
入力は POS tagger(Part of Speech tagger, 品詞付与ツール)で形態素分解されたものが必要です.
フォーマットは MeCab 形式になります.
形態素解析(POS tagger)は Jagger python を使うとよいでしょう!
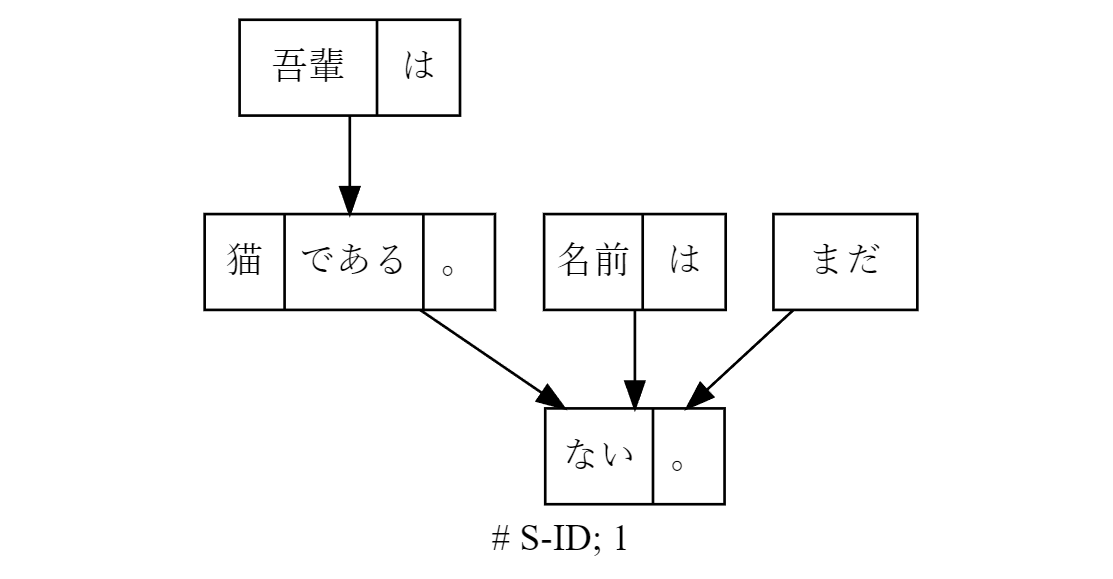
とりま tree 表現します!
print(jdepp.to_tree(str(sentence))
# S-ID: 1; J.DepP
0: 吾輩は━━┓
1: 猫である。━━┓
2: 名前は━━┫
3: まだ━━┫
4: ない。EOS
Voila~
to_dot で, graphviz 形式で出力もあるでよ!
print(jdepp.to_dot(str(sentence))
良き良き!
「猫である。」が「ない。」にかかっていますが, 本来だとセンテンス(文)単位の入力にしないとだめなので, まあここは愛嬌で.😸
きちんとやるには「吾輩は猫である。」と「名前はまだない。」の二つのセンテンスを入力にさせましょう.
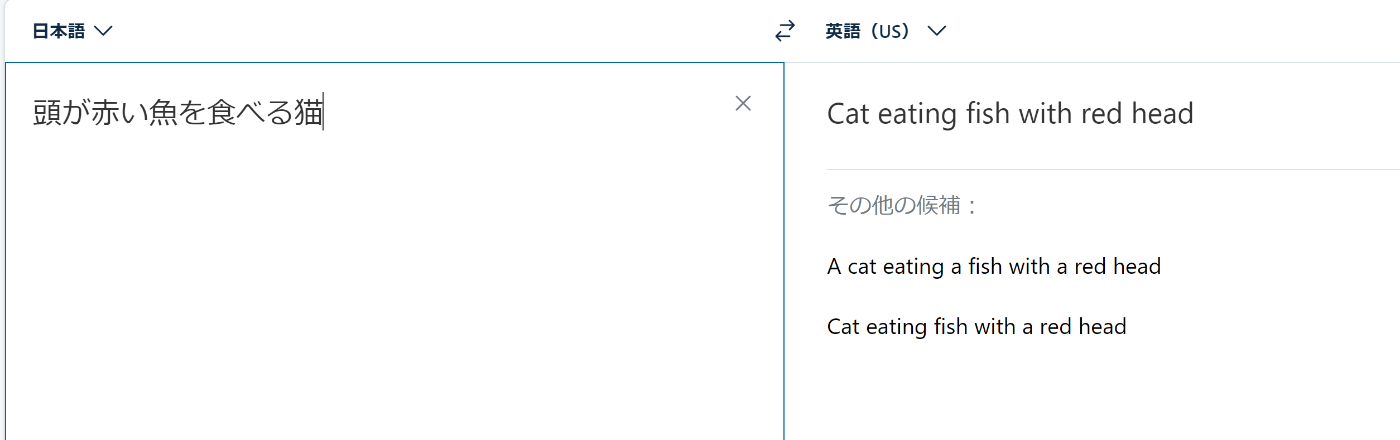
頭が赤い魚を食べる猫
係り受け解析の有名な(?)問題,
「頭が赤い魚を食べる猫」
を J.DepP で係り受け解析します!
まず, POS tagging は以下
頭 名詞,普通名詞,*,*,頭,あたま,*
が 助詞,格助詞,*,*,が,が,*
赤い 形容詞,*,イ形容詞アウオ段,基本形,赤い,あかい,*
魚 名詞,普通名詞,*,*,魚,ぎょ,*
を 助詞,格助詞,*,*,を,を,*
食べる 動詞,*,母音動詞,基本形,食べる,たべる,*
猫 名詞,普通名詞,*,*,猫,ねこ,*
EOS
結果は以下
# S-ID: 1; J.DepP
* 0 1D
頭 名詞,普通名詞,*,*,頭,あたま,*
が 助詞,格助詞,*,*,が,が,*
* 1 2D
赤い 形容詞,*,イ形容詞アウオ段,基本形,赤い,あかい,*
* 2 3D
魚 名詞,普通名詞,*,*,魚,ぎょ,*
を 助詞,格助詞,*,*,を,を,*
* 3 4D
食べる 動詞,*,母音動詞,基本形,食べる,たべる,*
* 4 -1D
猫 名詞,普通名詞,*,*,猫,ねこ,*
EOS
# S-ID: 1; J.DepP
0: 頭が━━┓
1: 赤い━━┓
2: 魚を━━┓
3: 食べる━━┓
4: 猫EOS
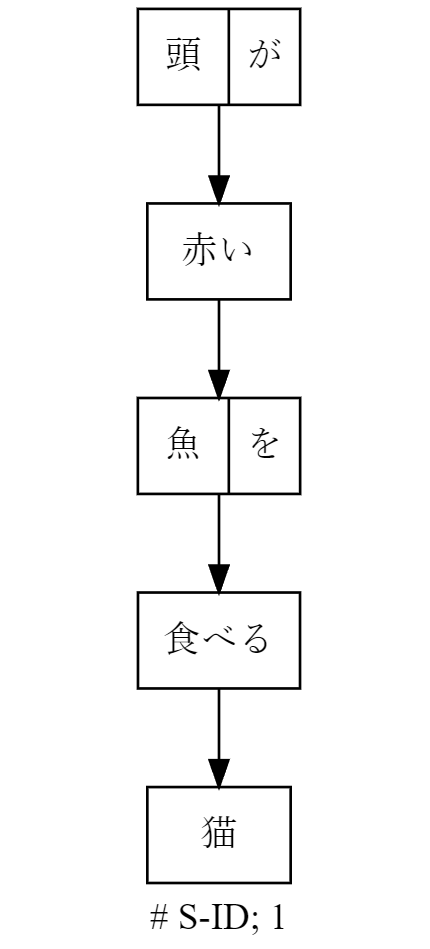
多くの日本語話者の解釈の仕方(前方一致ベース(?))であれば想定通りという感じですかね.
(「頭が赤い魚|を|食べる猫」を想定)
ただ, 「魚を」が文節になってしまったため, いくらか解釈のゆらぎはあります.
せっかくなので Stable diffusion で解説画像も作りました!
(対応する英語 "A cat eating a red-headed fish")

お魚さんは頭だけでなく全身赤になってしまったよ...
おまけ
Google 翻訳クン...?
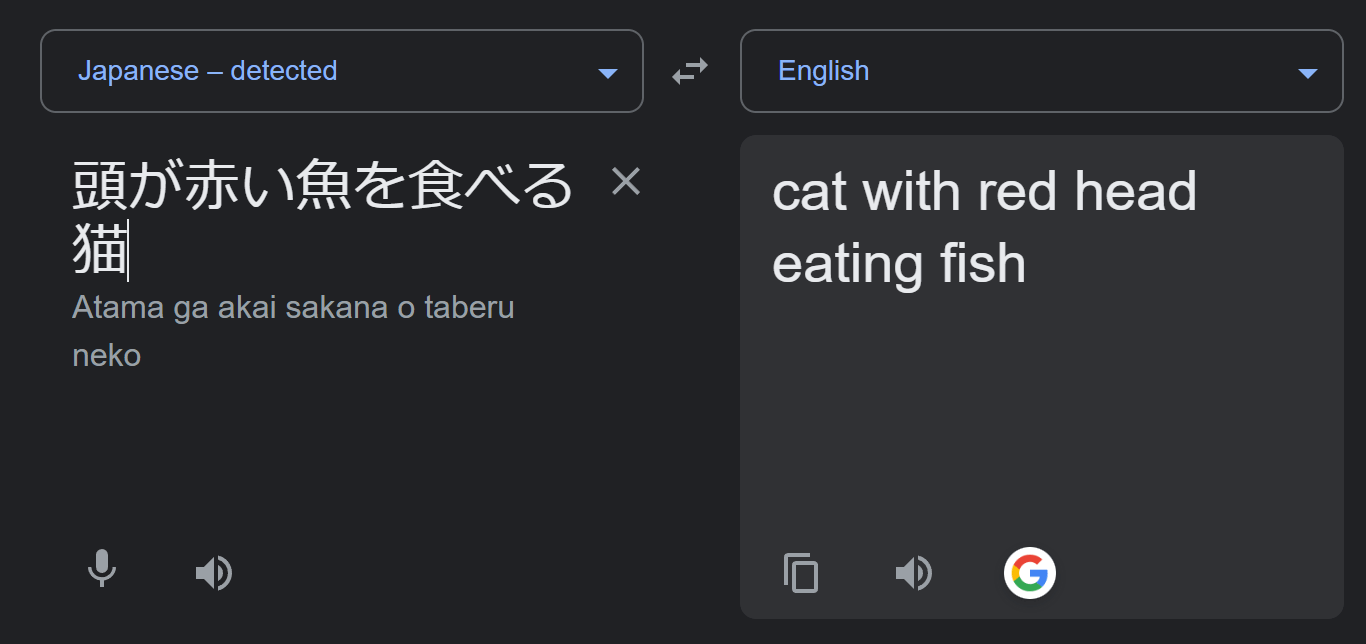
DeepL ちゃんは優秀そうね.
cat としてもなぜか女性になるときがある... 猫とは...?

みなさんも Stable diffusion で, 自分だけの「頭が赤い魚を食べる猫」画像, 生成してみてね.
係り受け解析を構成する情報
token
形態素解析での最小単位です.
吾輩, は などです.
- surface(表層形. 入力文章に表れているもの. 表立って見えているものだから surface(表面)ということなのかしらん?)
- feature(品詞情報とか, 変格活用の種類とか, ユーザ定義の情報など)
- フォーマットは形態素解析の辞書次第ですが, 今回はカンマ区切りの文字列です.
- tag: feature の各フィールドを切り出したもの.
文節
J.DepP では chunk として表現されています. chunk は複数の token を持ちます.
文節は, 吾輩は などです.
吾輩は は, これは2つの token [吾輩, は] で構成されています.
NLP の世界では chunk は, なんらかの基準でセンテンスを分割した, より一般的な概念のようです.
係り受け情報
文節(chunk)ごとに, 親や依存先の文節の情報(id)で表現されます.
あとは optional で確率など.
ここから必要に応じて, 木構造を作って可視化したりします.
ベンチマーク
jagger-python の時と同じように, wiki40b/ja を使いました.
POS tagger は jagger を利用しました.
wiki40b のテキストは, パラグラフ単位であるため, センテンス(文)への分解が必要です.
Wikipeadia 文章などはすでにいい感じにクリーニングされていると想定し(実際は途中でテキストが切れてるのとかあったけど...), ja_sentence_segmenter https://qiita.com/wwwcojp/items/3535985007aa4269009c で文分解を行いました.
こんな感じの入力データになります. 13 GB になりました.
Threadripper 1950X(16 cores)で測定しました.
入力 IO 時間は考慮せず, 出力 IO は /dev/null にして測定しました.
2ndpoly, シングルプロセス
J.DepP: Total 707.1916859149933 secs(8776040 sentences. 0.08058209464804095 ms per sentence))
877 万センテンスで, 12 分ほどでした.
によれば Intel MacBook Air(2011) で 1.1 万 ~ 1.5 万センテンス/秒らしいので, Python 版が同じくらいの処理量ですね. CPU 性能と Python オーバヘッドを考えると, pure C++ と比較したら 4~5 倍遅いという感じでしょうかね.
3rdpoly, シングルプロセス
J.DepP: Total 1807.7386209964752 secs(8776040 sentences. 0.2059856861405002 ms per sentence))
2ndpoly の 2.4 倍遅いくらいです. 辞書サイズは 2ndpoly の 7 倍くらいあるので,
速度は以外といい感じでしょうか...
(C++ <-> Python のオーバヘッドが大きくて 2ndpoly の性能が冴えないだけかもであるが)
メモリが十分ある環境(32 GB or more)では, 3rdpoly で最高精度がよさそうです.
2ndpoly, マルチプロセッシング(16 processes)
Python multiprocess で batch 処理で計測しました.
ちなみに J.DepP は C++ マルチスレッド対応していないため(内部ステート管理がスレッド考慮していない), Jagger のときとは異なり, C++ 側では非スレッド実行しています.
J.DepP: Total 138.754736661911 secs(8776040 sentences. 0.015810631749845146 ms per sentence))
future オブジェクト作ったり解放したりで結構コストかかるようで, 20 秒くらいはそれらに取られました. 正味 2 分くらいな感じでしょうか. シングルプロセスに対して 6 倍.
メモリ消費は 50 GB くらい.
3rdpoly, マルチプロセッシング(16 processes)
J.DepP: Total 333.11721110343933 secs(8776040 sentences. 0.037957576663670556 ms per sentence))
こちらもだいたいシングルプロセスの 6 倍くらいです.
メモリ消費は 2ndpoly + 2~3 GB で 53 GB くらいでした.
1GB 元データが形態素解析と係り受け解析(3rdpoly で最高精度)でおよそ 8 分くらいと想定すると, 1 CPU で 1 日 180 GB(~= 60 G 日本語文字数) 処理できます. 1 週間で 1 TB 処理できるのであれば, LLM 向けコーパス構築に係り受け解析を取り込むのは実用的にできそうですね.
さらなる高みへ...
POS tagger の組み込み
現状ですと入力データを作るのに POS tagger(形態素解析ツール)に依存しています.
高速形態素解析 Jagger の Python binding のメモ
せっかくなので Jagger(の C++ コア) を J.DepP に組み込んで, 一括ぺろっと扱えるようにしたいですね.
頻出文節の抽出
(係り受け情報を考慮して複数の)文節ワードの出現回数をカウントすることで,
web 文章にある,「続きを読む」みたいな頻出して不要なワードを除去するのに役立ちます.
文章が正しいか, 構文解析, etc
形態素解析と係り受け解析しただけでは, 文章の構造がある程度わかるだけで,
実際に正しい文章なのかや, この文章は日本語構文ルールのこれに該当! みたいなのはわかりません.
ここらへんはぺろっと判定をやってくれるライブラリは無いようです...
形態素解析と係り受け解析(+ 必要に応じてさらなる解析)の情報から, いろいろ頑張るしかなさそうです...
係り受け解析の次のステップとして, 照応解析(coreference resolution)がありますが, こちらは C++ で爆速なのはまだないようです.
文境界判定
J.DepP への入力は, センテンス(文)単位である必要があります.
web 文章だと句点がなかったり, 途中で改行されていたりと境界判定が難しいです.
これを自動で判定するには..., bunkai https://zenn.dev/syoyo/articles/99c7528863ed5f とか spaCy + ja_ginza_electra などありますが, 遅すぎるので, J.DepP の結果を使う手もあるでしょう.
一応 J.DepP で文節単位には分解できているので, それぞれの文節でここに改行をいれるかどうか, を何かしら判定(機械学習なり, ルールベースなり)すればいけるか.
- J.DepP で係り受け解析する
- 係り受け解析結果をもとに文境界判定する(センテンス単位に分割)
- 再度 J.DepP に流してより正確な係り受け解析をする
という手順になるでしょうか...
パラグラフへの分解
同様. なにやら頑張ってやるしかない.
猫が歩道橋を横切っていった.
それは三毛猫だった.
みたいに「それ」が指す先を求めるなどして文の依存関係である程度のまとまりを求める処理が必要. 「それ」が指す先の解決などは照応解析と呼ばれているようです. J.DepP には照応解析は入っていないので, とりあえずは KNP や GiNZA を使うしか無さそう.
とはいえ KNP はやっぱり遅いらしい.
あとは機械学習で一括して推定させてしまう wtpsplit https://github.com/bminixhofer/wtpsplit を使う手もあるかもしれません(wtpsplit はデフォのモデルだと日本語全く処理できないので, 自前で学習必要)
自前辞書の構築
KNBC は比較的小規模らしいのと, web 系文章にはあまり適さなそうなので, 自前で辞書を構築したほうがよいでしょう.
Wikipedia なり OSCAR などから自前で辞書を構築する.
コーパス構築には, GiNZA の ja_ginza_electra を使うのがよいだろう.
train については, C++ でスタンドアロンでビルドできるようにしていますので(Windows でもコンパイルできる!)とりあえずはそちらを使ってみましょう
Known issues
入力は必ず EOS\n で終わっている必要があります.
半角カッコ('(', ')')や quote('"')がうまく扱われません.
jagger 側(形態素解析の辞書)の問題になりますが, 半角カッコは
( 名詞,普通名詞,*,*,*.*,*
(1659 名詞,数詞,*,*,*,*,*
年 接尾辞,名詞性名詞助数辞,*,*,年,ねん,*
) 名詞,数詞,*,*,*.*,*
のような感じになり, 他の名詞にくっついたりしたり, あと品詞情報に開きか閉じかが無いです.
半角カッコは可能であれば全角カッコに変換してみましょう.
'"' はカッコ開きか閉じかはわからないので, 係り受け処理する前にうまくカッコに置き換えて係り受け解析する必要があるでしょう.
形態素解析ともからんできますが, 点(・)があると, たとえば バスキン・ロビンス が
バスキン 名詞,数詞,*,*,*,*,*
・ 特殊,記号,*,*,・,・,*
ロビンス 名詞,普通名詞,*,*,ロビンス,ロビンス,自動獲得:Wikipedia Wikipedia多義
と二つの名詞 + "・" になって, 係り受け解析がおかしくなるときがあります.
"・" の前後がカタカナ名詞のときはくっつける, とするとよいでしょうか?
たとえば,
現 名詞,普通名詞,*,*,現,げん,*
・ 特殊,記号,*,*,・,・,*
東京 名詞,地名,*,*,東京,とうきょう,*
大学 名詞,普通名詞,*,*,大学,だいがく,*
工学部 名詞,普通名詞,*,*,工学部,こうがくぶ,*
の場合だと, ・で区切って「現」「東京大学工学部」としたいでしょうから...
係り受けの確率
J.DepP C++ オリジナルでは -v(verbose) にマイナス値を入れないと計算してくれないので注意です!
Python 版はデフォで確率求めるようにしました.
ただ, 最後の文節にかかるものはすべて係り受けの確率がゼロになってしまっています.
# S-ID: 1; J.DepP
* 0 1D@0.790926
1990 名詞,普通名詞,*,*,*,*,* B@0.000000
年 接尾辞,名詞性名詞助数辞,*,*,年,ねん,* I@0.001246
から 助詞,格助詞,*,*,から,から,* I@0.000006
* 1 5D@0.000000
4 名詞,普通名詞,*,*,*.*,* B@0.999292
年間 接尾辞,名詞性名詞助数辞,*,*,年間,ねんかん,* I@0.000559
、 特殊,読点,*,*,、,、,* I@0.000003
* 2 4D@0.552995
松任 名詞,普通名詞,*,*,松任,松任,自動獲得:テキスト B@0.999331
谷 名詞,普通名詞,*,*,谷,たに,* I@0.034988
由 名詞,普通名詞,*,*,由,よし,代表表記:由/よし 漢字読み:訓 カテゴリ:抽象物 I@0.072666
* 3 4D@0.869157
実の 連体詞,*,*,*,実の,じつの,代表表記:実の/じつの B@0.673955
* 4 5D@0.000000
コーラス 名詞,普通名詞,*,*,コーラス,こーらす,代表表記:コーラス/こーらす カテゴリ:抽象物 ドメイン:文化・芸術 B@0.994520
を 助詞,格助詞,*,*,を,を,* I@0.000001
* 5 -1D@0.000000
務めた 動詞,*,母音動詞,タ形,務める,つとめた,* B@0.999938
。 特殊,句点,*,*,。,。,* I@0.000174
EOS
x -> 5D(と最後の文節)の確率(@ の値)が 0.0 になっています.
また, B@や I@ は chunk の始まりの確率などを表していますが, 最初の文節の B もゼロになってしまっています.
1990 名詞,普通名詞,*,*,*,*,* B@0.000000
さらに最初の文節が最後の文節にかかる場合(0 -> nD, where n is the number of chunks)も確率はゼロになります.
こちらについては jdepp のバグそうであるが... 一応 parseLinear で常にゼロ初期化している https://github.com/lighttransport/jdepp-python/blob/4b624dec8d5b88d1c6f21ebc45fe46aa809adf12/jdepp/pdep.cc#L281 のを見直すといくらか想定する結果にはなるが, 正しい動作かは不明.
とりあえずは最初の文節以外では確率がゼロでなければ利用する... という運用になるでしょうか.
TODO
-
高速な C++ 照応解析ライブラリほしい(自分でつくらにゃダメ?)
- 機械学習使わない版は CRF(Conditional Random Field)とか使っていたりなので, J.DepP のやり方を拡張してできたりもするやも?
- Jagger を組み込む
- マルチスレッド対応する
- セキュリティやエラー対策を改善する
Discussion
というプログラムをGoogle Colaboratoryで試してみたのですけど
まではちゃんと出力されるのですが、その直後の
import jdeppのところでというエラーでコケてしまうのです。私(安岡孝一)個人としては
jdepp-0.1.6-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whlを疑ってるのですけど…。安岡先生!🙏
ありがとうございます.
該当 symbol は template specialization でmanylinux2014(gcc10) だとうまく扱えていないようですね.
調べてみます
日本語係り受け解析器J.DepPをgoogle colabで動かすというページを読んでいたら、clang++でコンパイルするよう指示があったので、ちょっと改造してみました。
jdepp-0.1.6.tar.gzをclang++でコンパイルするよう仕向けたら、Google Colaboratoryでもちゃんと動作して、以下の結果が得られました。「望遠鏡で」が「泳ぐ」に係ってるのが、ちょっとツライのですが、それでも、このやり方なら何とか動作するようです。
直しました. v0.1.7( or
pip install -U jdepp)利用ください.元の C++ オリジナルで動かしても係り受け結果は同様でした(python binding 版固有の問題ではない).
knbc では限界ありますので, Universal Dependencies 対応版も一応入っているので, 辞書をうまく学習したらいい感じになると思います.
あとは, きちんと読点いれて, 「望遠鏡で、泳ぐ彼女を見た。」にすれば...
jagger と jdepp(+ 日本語 Universal Dependencies) 利用し, 高速で高精度な日本語 coreference resolution 開発期待しております!
対応ありがとうございます。さっそくqiitaの記事を書いておきました。